这几年,NVIDIA的皮衣越来越亮眼,但玩家们的心情却越来越复杂。原因大家都很清楚:游戏显卡的战场,正从一个纯粹的硬件竞赛,逐渐演变成一场软件和算法的较量。

前段时间发布的DLSS 5技术就充满了争议。它号称实现了全动态神经渲染,但在实际游戏中,那种“AI重构”带来的画面失真感,让不少追求原汁原味的玩家感到不满。

就在大家认为NVIDIA又在用AI画饼时,他们在GTC 2026上再次掏出了新宝贝:神经纹理压缩,简称NTC。这个技术的核心目标很直接:让你的显卡,尤其是显存有限的型号,能再战几年。

它是如何实现的?要理解NTC,我们先得看看当前游戏面临的显存困境。如今,2K分辨率(2560 x 1440)已成为玩家的主流选择,而现代3A游戏的贴图纹理又愈发精细,导致显存占用如同坐上火箭般飙升。
在传统的图形渲染流程中,纹理调用机制就像一个高效的搬运工。游戏中的每一张贴图,都会被预先压缩并切割成无数个4x4像素的小方块(通常是BCn格式),然后存储在显卡的GPU显存中。当需要渲染某个像素时,GPU会根据3D模型的UV坐标,精准定位到显存中对应的纹理块,再通过专门的硬件单元解压,最终得到颜色信息。
这种方式虽然快速直接,但本质上是一种“暴力存储”。即便是一面毫无细节的灰墙,你也不得不存储成千上万个几乎相同的灰色方块。宝贵的显存,就这样被大量重复或冗余的“原材料”所占据。
NTC的技术核心,正是要打破这种模式。它不再单纯地存储原始像素数据,而是将纹理信息交给一个经过训练的、极其轻量级的人工智能神经网络来处理。
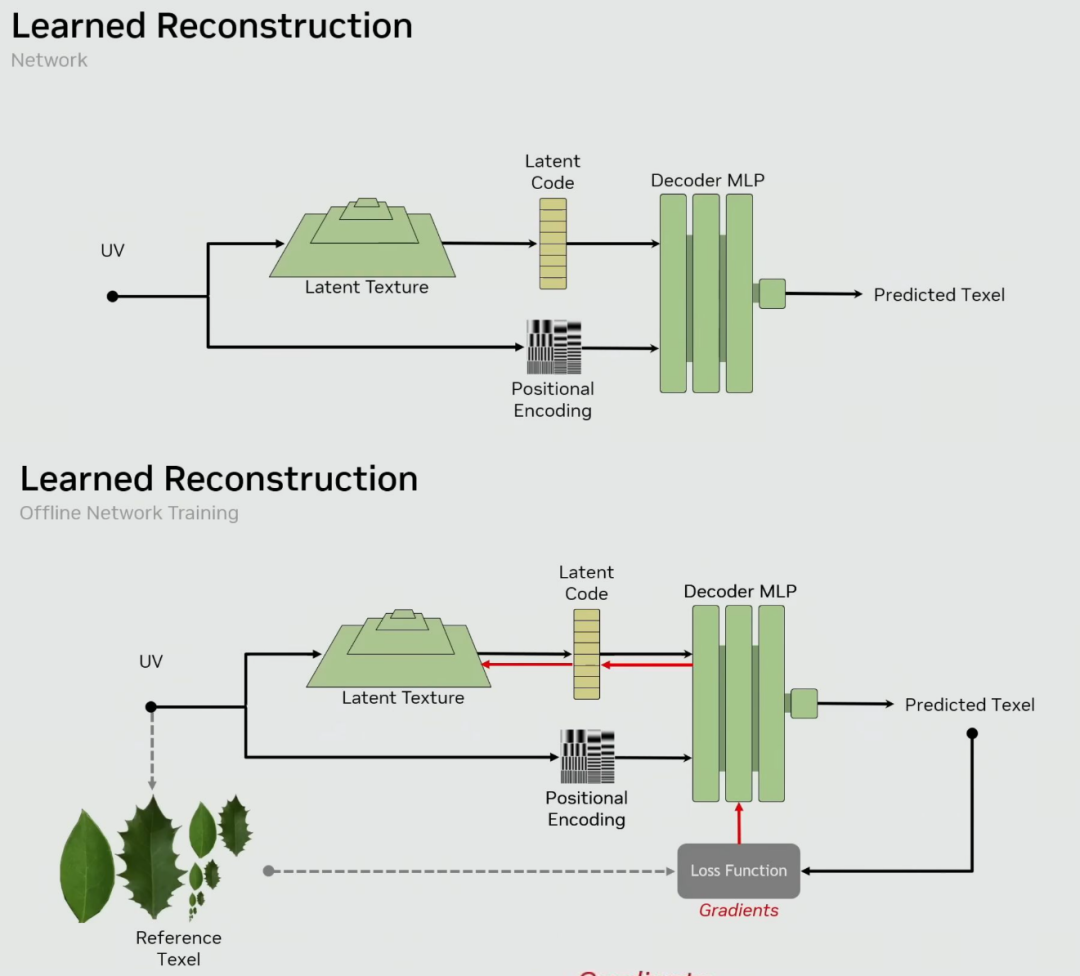
当游戏运行时,GPU不再需要从显存中“搬运”庞大的纹理贴图。取而代之的是,这个内置于GPU中的微型AI引擎,能够根据输入的坐标信息,实时“计算”并重建出纹理应有的样子。整个过程是确定性的,这意味着对于相同的输入,它总能输出完全一致的结果,确保了画面的稳定性。


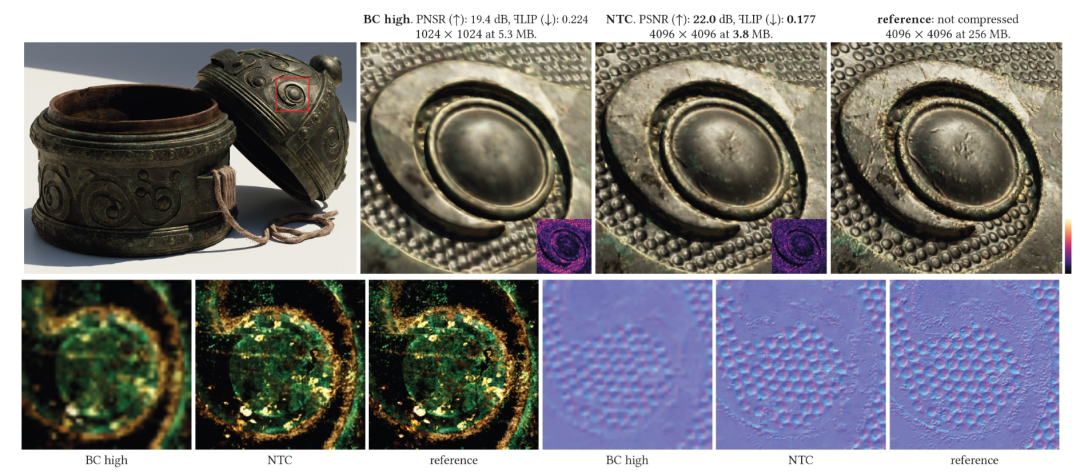
那么,这项技术的实际效果究竟有多惊人呢?根据NVIDIA的演示,在一个名为“Tuscan Villa”的场景中,使用传统的BCn纹理压缩方案需要消耗高达 6.5GB 的显存。而开启NTC后,显存占用瞬间暴跌至 970MB,降幅达到了惊人的 85%!

最关键的是,在实现如此巨大压缩比的同时,画面质量几乎没有任何肉眼可见的损失。在某些情况下,由于AI的智能处理,物体的边缘甚至可能比传统压缩方式显得更加锐利。

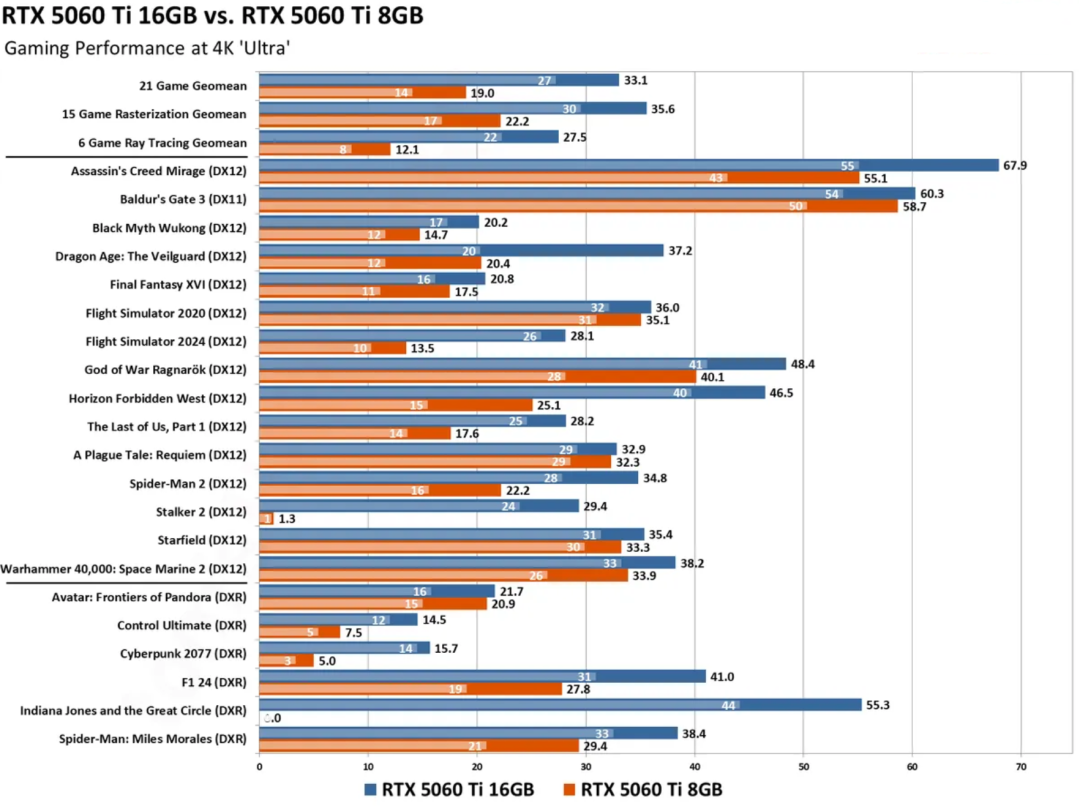
这在实际游戏中有多大意义?我们来看看RTX 5060 Ti 8GB和16GB版本的游戏表现差距就知道了。在2K分辨率、最高画质下,16GB版本凭借不会爆显存的巨大优势,其平均光追性能比8GB版本高出近40%。
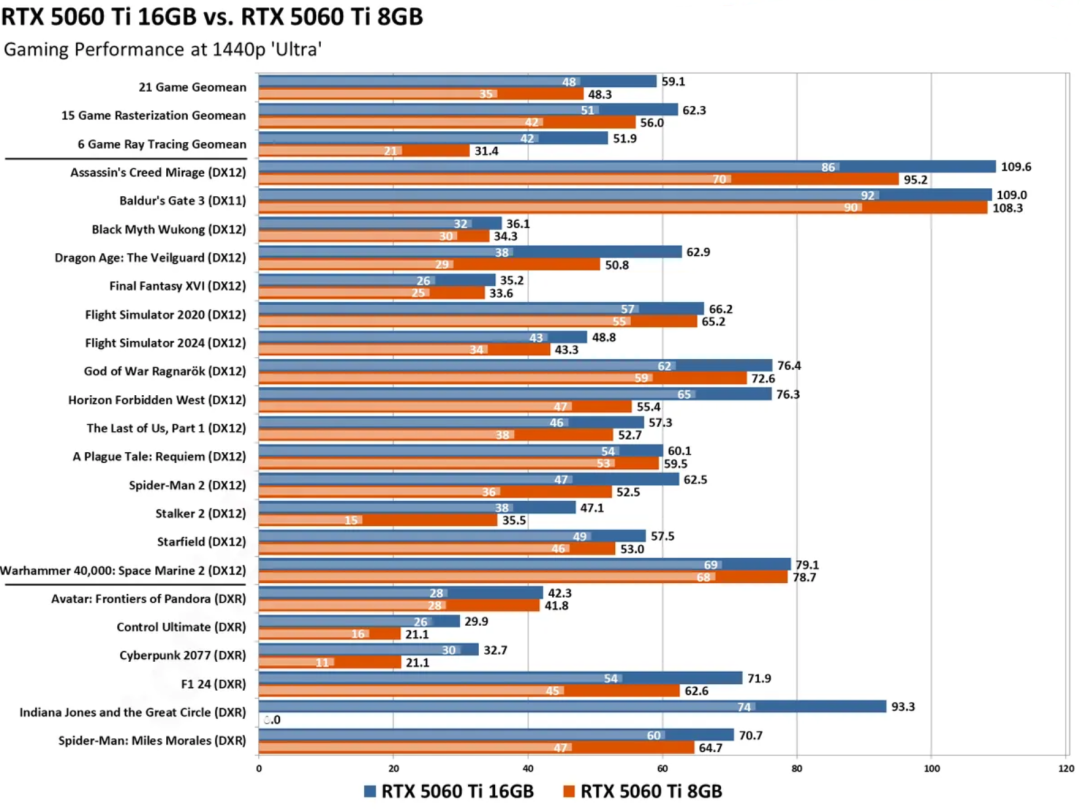
在4K分辨率下,这种由显存容量带来的性能鸿沟会变得更加明显。
而如果NTC技术得以普及,那么前段时间被广泛讨论的“8GB显存显卡死亡斩杀线”将不复存在——既然一个6.5GB显存需求的场景能被压缩到不足1GB,那么8GB显存简直堪称“海量”。更有甚者,NVIDIA声称这项技术最终能带来4倍的渲染分辨率提升,这为未来更高分辨率游戏的普及铺平了道路。
看到这里,可能有读者会问:条件是什么?

答案是肯定的。NTC技术及其底层所依赖的微软DirectX Cooperative Vectors(协作向量)技术,要求显卡必须支持Shader Model 6.0或更高版本。
翻译成更通俗的说法就是,从GTX 10系列(Pascal架构)开始的显卡,理论上都具备了运行NTC代码的“入场券”。然而,NTC本质上依然是一种AI计算,因此它也高度依赖显卡中Tensor Core(张量核心)的算力。这意味着,对于拥有更强AI算力的RTX 40、50系列显卡,可以近乎无损地享受这项红利;而对于RTX 20、30系列显卡,虽然也能支持,但可能需要耗费相当一部分计算性能才能实现相同效果。

但无论如何,与更具争议性的DLSS 5.0相比,NTC技术更像是将AI能力用在了提升基础图形渲染效率的“正道”上。它直击了当前游戏画面升级与硬件成本之间的矛盾核心。对于这项技术,想了解更多前沿图形技术和人工智能在游戏领域的应用,可以关注云栈社区的相关讨论。
不过,这项技术具体何时能够落地到消费级显卡和游戏中,NVIDIA尚未给出明确时间表。我们只能希望这张饼不要画得太久。毕竟,去年发布的Reflex 2技术,至今也还未真正与玩家见面。

 发表于 2026-4-7 04:35:45
|
查看: 151|
回复: 0
发表于 2026-4-7 04:35:45
|
查看: 151|
回复: 0
