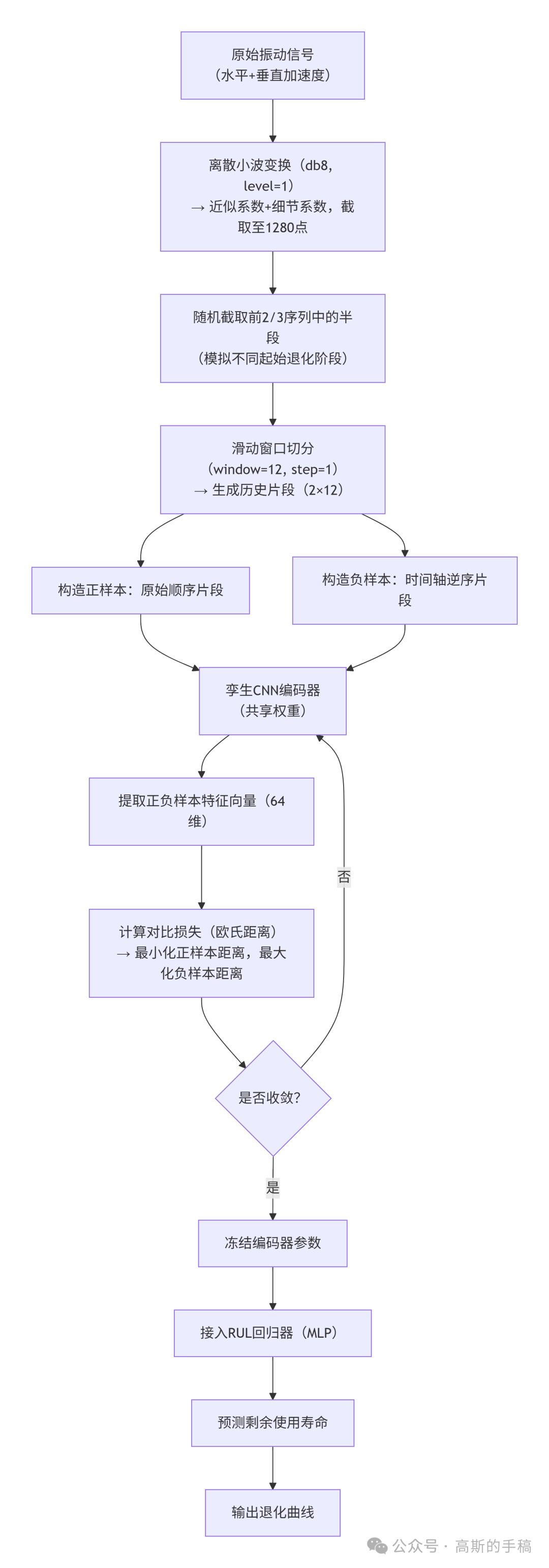
提出了一种基于对比自监督学习框架的滚动轴承剩余寿命预测方法。该方法的核心在于利用轴承全寿命周期振动信号,通过巧妙的样本构造方式,让模型自行学习退化过程中的不变性特征。
具体流程是:将时间顺序片段作为正样本,其时间轴逆序片段作为负样本,构建正负样本对。随后,使用共享权重的孪生卷积神经网络提取信号的时频域特征,并采用基于欧氏距离的对比损失函数训练编码器。这一过程旨在让编码器学习到与设备退化趋势一致的鲁棒表征,而无需大量人工标注的寿命标签。
在预训练完成后,冻结编码器的参数,在其顶层接入一个简单的多层感知机回归器,用于最终预测轴承的剩余使用寿命。这种“预训练+微调”的两阶段策略,能够在无标签或仅有少量标签的条件下,实现高精度的退化趋势跟踪与寿命预测。
算法步骤
数据加载与预处理
读取IEEE PHM 2012轴承数据集的振动信号文件(包含水平与垂直两通道加速度数据)。将每个CSV文件中的两列加速度数据展平为时序向量,并转换为PyTorch张量存入GPU,为后续处理做准备。
离散小波变换
对每个原始振动信号采用“db8”小波进行单层分解,提取近似系数(低频部分)与细节系数(高频部分)。然后,分别截取两者的前半部分(长度固定为1280点),并堆叠成形状为(2, 1280)的二维特征图,完成从时域到时频域的转换。
滑动窗口切分与样本对构造
这是构造自监督任务的关键一步。首先,在每个小波系数序列的时间轴上,随机截取其前三分之二长度中的一段。接着,以窗口大小12、步长1进行滑动窗口采样,得到一系列历史片段(形状2×12),这些片段被定义为正样本。
为了构建负样本,只需将每个正样本片段的时间轴进行逆序排列即可。这种“顺序 vs. 逆序”的对比,为模型提供了明确的自监督学习信号,使其能够区分正常的退化演变过程。
对比预训练(前置任务)
构建一个孪生CNN编码器,其结构为三层一维卷积层,后接全局平均池化层和全连接层,最终输出64维的特征向量。使用欧氏距离对比损失函数在该编码器上训练,目标是最小化正样本对特征之间的距离,同时最大化负样本对特征之间的距离,从而让编码器学到有判别力的特征。
RUL回归微调
预训练完成后,冻结CNN编码器的所有权重参数。将编码器输出的64维特征向量作为输入,训练一个简单的回归器(例如几层全连接层),直接预测当前输入片段所对应的剩余寿命百分比,完成从特征到具体寿命值的映射。
模型评估与部署
在模型未见过的轴承测试数据上,将连续的滑动窗口输入到训练好的完整模型(编码器+回归器)中,得到一条连续的RUL预测曲线。将这条预测曲线与真实的设备退化曲线进行对比,即可验证方法的有效性与预测精度。
核心代码实现
以下是该方法几个关键模块的PyTorch实现代码。
小波变换模块
此函数负责对原始振动信号进行离散小波变换,并截取固定长度的系数。
# ===================== 2. 小波变换模块 =====================
def apply_wavelet_transform_paper(data_dict, wavelet="db8", level=1, trunc_length=1280):
"""
对原始振动信号进行离散小波变换(DWT),提取近似系数和细节系数,并截取固定长度
参数:
data_dict: 原始振动信号字典
wavelet: 小波基类型(论文使用db8)
level: 分解层数(固定为1)
trunc_length: 截取长度(论文使用1280)
返回:
wavelet_dict: 字典,键为轴承名,值为处理后的小波系数张量列表(形状(2, trunc_length))
"""
wavelet_dict = {}
for bearing, signals in data_dict.items():
print(f"\n🔄 正在对 {bearing} 进行小波变换")
wavelet_dict[bearing] = []
for signal_tensor in signals:
# 将张量移到CPU转为numpy数组(pywt需要numpy输入)
signal_np = signal_tensor.cpu().numpy()
# 单层离散小波分解
coeffs = pywt.wavedec(signal_np, wavelet, level=level)
approx_coeffs = coeffs[0] # 低频近似系数
detail_coeffs = coeffs[1] # 高频细节系数
# 截取前半部分(论文操作:取一半频谱)
trunc_approx = approx_coeffs[:trunc_length]
trunc_detail = detail_coeffs[:trunc_length]
# 堆叠为 (2, trunc_length) 形状,并转回原设备
wavelet_processed = torch.tensor([trunc_approx, trunc_detail],
dtype=torch.float32,
device=signal_tensor.device)
wavelet_dict[bearing].append(wavelet_processed)
return wavelet_dict
滑动窗口切分与正负样本构造模块
该函数实现了数据增强、滑动窗口切分以及正负样本对的构造。
# ===================== 3. 滑动窗口切分与正负样本构造模块 =====================
def sliding_window_segmentation_fixed(data_dict, window_size=12, step_size=1):
"""
对小波系数序列进行滑动窗口切分,并构造正负样本对
正样本:原始顺序的窗口片段
负样本:同一片段时间轴逆序
参数:
data_dict: 小波变换后的数据字典
window_size: 窗口长度(论文使用12)
step_size: 滑动步长(论文使用1)
返回:
positive_samples: 字典,键为轴承名,值为正样本张量列表(每个形状(2, window_size))
negative_samples: 字典,值为负样本张量列表
"""
positive_samples = {}
negative_samples = {}
for bearing, signals in data_dict.items():
print(f"\n🔄 正在对 {bearing} 进行滑动窗口切分")
positive_samples[bearing] = []
negative_samples[bearing] = []
for signal_tensor in signals:
# 转为numpy,形状为 (2, 1280)
sequence = signal_tensor.cpu().numpy()
seq_length = sequence.shape[1] # 时间轴长度
# 随机截取前三分之二中的半段序列(论文中的数据增强操作)
cut_length = int(2/3 * seq_length) # 前2/3总长度
# 在[0, cut_length - 0.5*cut_length]范围内随机起始点
random_start = random.randint(0, cut_length - int(0.5 * cut_length))
# 截取半段(长度约为原长的1/3)
truncated_sequence = sequence[:, random_start:random_start + int(0.5 * cut_length)]
# 在截断后的序列上滑动窗口
num_segments = (truncated_sequence.shape[1] - window_size) // step_size + 1
for i in range(num_segments):
start = i * step_size
end = start + window_size
segment = truncated_sequence[:, start:end] # 正样本片段 (2, window_size)
positive_samples[bearing].append(
torch.tensor(segment, dtype=torch.float32, device=signal_tensor.device)
)
# 负样本:时间轴逆序(必须copy,否则是视图)
segment_reversed = np.flip(segment, axis=1).copy()
negative_samples[bearing].append(
torch.tensor(segment_reversed, dtype=torch.float32, device=signal_tensor.device)
)
return positive_samples, negative_samples
孪生CNN编码器模块
这是特征提取的核心网络,采用共享权重的孪生结构。
# ===================== 4. 孪生CNN编码器模块 =====================
class SiameseCNN(nn.Module):
"""用于提取特征的一维卷积神经网络(共享权重)"""
def __init__(self):
super(SiameseCNN, self).__init__()
# 输入形状: (batch, channels=2, time=12)
self.conv1 = nn.Conv1d(in_channels=2, out_channels=64, kernel_size=3, padding=1)
self.conv2 = nn.Conv1d(in_channels=64, out_channels=128, kernel_size=3, padding=1)
self.conv3 = nn.Conv1d(in_channels=128, out_channels=256, kernel_size=3, padding=1)
self.global_pool = nn.AdaptiveAvgPool1d(1) # 全局平均池化,输出 (batch, 256, 1)
self.fc1 = nn.Linear(256, 128)
self.fc2 = nn.Linear(128, 64) # 最终特征维度64
def forward(self, x):
x = F.relu(self.conv1(x))
x = F.relu(self.conv2(x))
x = F.relu(self.conv3(x))
x = self.global_pool(x).squeeze(-1) # (batch, 256)
x = F.relu(self.fc1(x))
x = self.fc2(x) # (batch, 64)
return x
对比损失函数模块
定义了用于预训练的对比损失,驱动正负样本特征的分离。
# ===================== 5. 对比损失函数模块 =====================
class ContrastiveLoss(nn.Module):
"""基于欧氏距离的对比损失,鼓励正样本对靠近、负样本对远离(简化版)"""
def __init__(self, margin=1.0):
super(ContrastiveLoss, self).__init__()
self.margin = margin
def forward(self, positive_features, negative_features):
# 计算正负样本特征向量之间的欧氏距离
distance = F.pairwise_distance(positive_features, negative_features)
# 仅使用正项损失(原代码为平方和,未使用margin项)
loss = torch.mean(torch.pow(distance, 2))
return loss
预训练数据采样模块
用于从所有轴承数据中随机抽取指定数量的样本对,组成预训练批次。
# ===================== 6. 预训练数据采样模块 =====================
def sample_pretext_data(positive_samples, negative_samples, target_size):
"""
从所有轴承的正负样本中随机抽取指定数量的样本对
参数:
positive_samples, negative_samples: 滑动窗口输出字典
target_size: 目标总样本数(正负各一半)
返回:
selected_positive, selected_negative: 随机抽取的样本列表
"""
all_positive = []
all_negative = []
for bearing in positive_samples.keys():
all_positive.extend(positive_samples[bearing])
all_negative.extend(negative_samples[bearing])
selected_positive = random.sample(all_positive, target_size // 2)
selected_negative = random.sample(all_negative, target_size // 2)
return selected_positive, selected_negative
总结
以上便是基于孪生卷积网络和时频对比自监督学习的滚动轴承剩余寿命预测的核心思路与关键代码实现。这种方法巧妙地将无监督的对比学习思想引入到故障预测领域,减少了对昂贵标注数据的依赖。通过离散小波变换、创新的正负样本构造以及两阶段的训练策略,模型能够从振动信号中自动捕捉与设备健康退化密切相关的深层特征。
对于工业领域的预测性维护应用而言,这种具有“退化不变性”学习能力的模型,展现出良好的实用潜力。如果你对深度学习在时序预测或设备健康管理中的应用有更多想法,欢迎到云栈社区交流探讨。
 发表于 2026-4-7 05:40:14
|
查看: 170|
回复: 0
发表于 2026-4-7 05:40:14
|
查看: 170|
回复: 0
