容器的优势
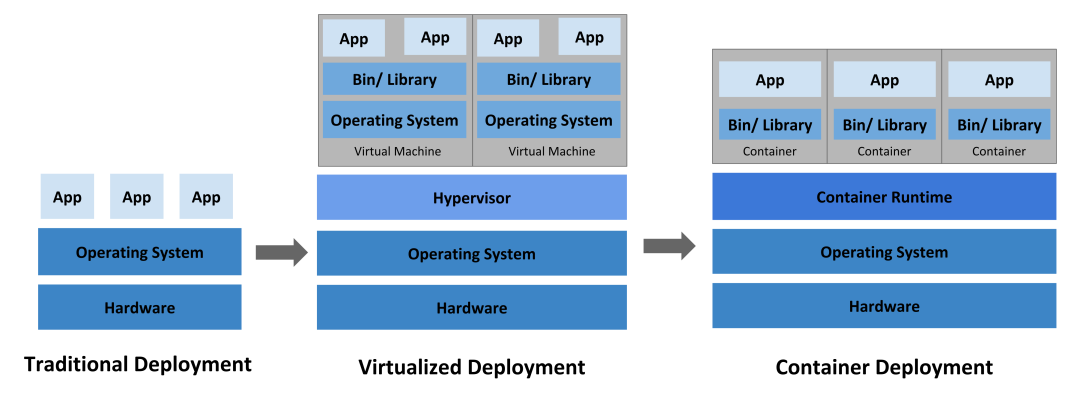
在传统部署模式中,应用直接运行在物理服务器上。如果一个应用占用了过多资源,其他应用的性能就可能受到影响。
到了虚拟化部署时代,我们可以在单个物理服务器的CPU上运行多个虚拟机(VM)。每个VM都是一台完整的计算机,在虚拟化硬件之上运行所有组件,包括操作系统。这样一来,不同的应用能够在VM之间安全隔离运行,从而更好地利用物理服务器的资源。
容器与VM类似,也拥有自己的文件系统、CPU、内存和进程空间等。但容器的关键区别在于,它们共享宿主机的操作系统内核。因此,容器通常被视为一种轻量级的操作系统层面的虚拟化技术。
相比于VM,这种轻量级的特性使得容器更契合云原生模式的实践。
容器的本质

我们说容器是一种轻量级的操作系统层面的虚拟化技术。这里的“操作系统层面”是重点,它意味着容器本质上是利用操作系统自身提供的功能来实现虚拟化。
容器技术的代表之作Docker,就是一个基于Linux操作系统,使用Go语言编写,并调用了Linux内核功能的虚拟化工具。
为了更好地理解容器的本质,我们不妨深入看看它具体使用了哪些Linux内核技术,以及在Go中如何调用它们。
1、NameSpace
NameSpace(命名空间)是Linux内核一个强大的特性,可用于实现进程间的资源隔离。
由于容器之间共享OS内核,对于操作系统而言,容器实质上就是进程。多个容器运行,对应着操作系统内运行着多个进程。
当进程运行在自己独立的命名空间时,命名空间的资源隔离机制能确保进程之间互不干扰,每个进程都以为自己身处一个独立的操作系统环境中。这样的进程,我们就可以称之为“容器”。
回到资源隔离上,从Linux内核5.6版本开始,已经提供了8种NameSpace,它们分别用于隔离不同类型的资源(Docker主要使用了前6种)。
| 命名空间 |
系统调用参数 |
作用 |
| Mount (mnt) |
CLONE_NEWNS |
文件目录挂载隔离。用于隔离各个进程看到的挂载点视图 |
| Process ID (pid) |
CLONE_NEWPID |
进程ID隔离。使每个命名空间都有自己的初始化进程,PID为1,作为所有进程的父进程 |
| Network (net) |
CLONE_NEWNET |
网络隔离。使每个net命名空间有独立的网络设备,IP地址,路由表,/proc/net目录等网络资源 |
| Interprocess Communication (ipc) |
CLONE_NEWIPC |
进程IPC通信隔离。让只有相同IPC命名空间的进程之间才可以共享内存、信号量、消息队列通信 |
| UTS |
CLONE_NEWUTS |
主机名或域名隔离。使其在网络上可以被视作一个独立的节点而非主机上的一个进程 |
| User ID (user) |
CLONE_NEWUSER |
用户UID和组GID隔离。例如每个命名空间都可以有自己的root用户 |
| Control group (cgroup) Namespace |
CLONE_NEWCGROUP |
Cgroup信息隔离。用于隐藏进程所属的控制组的身份,使命名空间中的cgroup视图始终以根形式来呈现,保障安全 |
| Time Namespace |
CLONE_NEWTIME |
系统时间隔离。允许不同进程查看到不同的系统时间 |
NameSpace的详细描述可以查看Linux man手册中的NAMESPACES章节。手册中还描述了几个与进程相关的NameSpace API系统调用函数。
clone()
int clone(int (*fn)(void *), void *stack, int flags, void *arg, ...
/* pid_t *parent_tid, void *tls, pid_t *child_tid */ );
clone() 用于创建新进程。通过传入一个或多个系统调用参数(flags参数),可以创建出不同类型的NameSpace,并且子进程也会成为这些NameSpace的成员。
setns()
int setns(int fd, int nstype);
setns() 用于将进程加入到一个现有的NameSpace中。其中fd为文件描述符,引用/proc/[pid]/ns/目录里对应的文件;nstype代表NameSpace类型。
unshare()
int unshare(int flags);
unshare() 用于将进程移出原本的NameSpace,并加入到新创建的NameSpace中。同样是通过传入flags参数来创建新的NameSpace。
ioctl()
int ioctl(int fd, unsigned long request, ...);
ioctl() 用于发现有关NameSpace的信息。
上面的系统调用函数,我们可以直接用C语言调用,从而创建出各种类型的NameSpace。对于Go语言而言,其标准库内部已经封装好了这些操作,我们可以更方便地直接使用,降低心智负担。
先来看一个简单的小工具(源自Containers From Scratch • Liz Rice • GOTO 2018):
package main
import (
"os"
"os/exec"
)
func main() {
switch os.Args[1] {
case "run":
run()
default:
panic("help")
}
}
func run() {
cmd := exec.Command(os.Args[2], os.Args[3:]...)
cmd.Stdin = os.Stdin
cmd.Stdout = os.Stdout
cmd.Stderr = os.Stderr
must(cmd.Run())
}
func must(err error) {
if err != nil {
panic(err)
}
}
这个程序接收用户命令行传递的参数,并使用exec.Command运行。例如,当我们执行 go run main.go run echo hello 时,会创建出main进程,main进程内执行echo hello命令创建出一个新的echo进程,最后随着echo进程执行完毕,main进程也随之结束退出。
[root@host go]# go run main.go run echo hello
hello
[root@host go]#
但是上面创建的进程太快退出了,不便于我们观察。如果让main进程启动一个bash进程会怎样呢?
为了直观对比,我们先看看当前会话的进程信息。
[root@host go]# ps
PID TTY TIME CMD
1115 pts/0 00:00:00 bash
1205 pts/0 00:00:00 ps
[root@host go]# echo $$
1115
[root@host go]#
当前我们正处于PID 1115的bash会话进程中。继续下一步操作:
[root@host go]# go run main.go run /bin/bash
[root@host go]# ps
PID TTY TIME CMD
1115 pts/0 00:00:00 bash
1207 pts/0 00:00:00 go
1225 pts/0 00:00:00 main
1228 pts/0 00:00:00 bash
1240 pts/0 00:00:00 ps
[root@host go]# echo $$
1228
[root@host go]# exit
exit
[root@host go]# ps
PID TTY TIME CMD
1115 pts/0 00:00:00 bash
1241 pts/0 00:00:00 ps
[root@host go]# echo $$
1115
[root@host go]#
在执行go run main.go run /bin/bash后,我们的会话被切换到了PID 1228的bash进程中,而main进程也还在运行着(当前所处的bash进程是main进程的子进程,main进程必须存活才能维持bash进程的运行)。当执行exit退出当前bash进程后,main进程随之结束,并回到原始的PID 1115的bash会话进程。
我们说过,容器的实质是进程。现在你可以把main进程当作是“Docker”工具,把main进程启动的bash进程,当作一个“容器”。这里的“Docker”创建并启动了一个“容器”。
为什么打了双引号?因为在这个bash进程中,我们可以随意使用操作系统的资源,并没有做任何资源隔离。
要想实现资源隔离,其实很简单。在run()函数中增加SysProcAttr配置,先从最简单的UTS隔离开始,传入对应的CLONE_NEWUTS系统调用参数,并通过syscall.Sethostname设置主机名:
func run() {
cmd := exec.Command(os.Args[2], os.Args[3:]...)
cmd.Stdin = os.Stdin
cmd.Stdout = os.Stdout
cmd.Stderr = os.Stderr
cmd.SysProcAttr = &syscall.SysProcAttr{
Cloneflags: syscall.CLONE_NEWUTS,
}
must(syscall.Sethostname([]byte("mycontainer")))
must(cmd.Run())
}
这段代码看似没问题,但仔细想想:syscall.Sethostname这一行到底是哪个进程在执行?是main进程还是main进程创建的子进程?
显然,子进程都还没Run起来呢!现在调用肯定是main进程在执行。但main进程没有进行资源隔离,这就相当于直接更改宿主机的主机名了。
子进程还没启动,不能更改主机名;等子进程启动后,又会进入阻塞状态,无法再通过代码方式更改其内部的主机名。有什么解决办法呢?
看来只能请出/proc/self/exe这个神器了。
在Linux 2.2内核版本之后,/proc/[pid]/exe是对应pid进程的二进制文件的符号链接,包含着被执行命令的实际路径名。如果打开这个文件,就相当于打开了对应的二进制文件,甚至可以通过重新执行/proc/[pid]/exe来重新运行一个对应于pid的二进制文件的进程。
对于/proc/self,当进程访问这个神奇的符号链接时,可以解析到进程自己的/proc/[pid]目录。
合起来就是,当进程访问/proc/self/exe时,可以运行一个对应进程自身的二进制文件。
这有什么用?继续看下面的代码:
package main
import (
"os"
"os/exec"
"syscall"
)
func main() {
switch os.Args[1] {
case "run":
run()
case "child":
child()
default:
panic("help")
}
}
func run() {
cmd := exec.Command("/proc/self/exe", append([]string{"child"}, os.Args[2:]...)...)
cmd.Stdin = os.Stdin
cmd.Stdout = os.Stdout
cmd.Stderr = os.Stderr
cmd.SysProcAttr = &syscall.SysProcAttr{
Cloneflags: syscall.CLONE_NEWUTS,
}
must(cmd.Run())
}
func child() {
must(syscall.Sethostname([]byte("mycontainer")))
cmd := exec.Command(os.Args[2], os.Args[3:]...)
cmd.Stdin = os.Stdin
cmd.Stdout = os.Stdout
cmd.Stderr = os.Stderr
must(cmd.Run())
}
func must(err error) {
if err != nil {
panic(err)
}
}
在run()函数中,我们不再直接运行用户传递的命令行参数,而是运行/proc/self/exe,并传入child参数和用户传递的命令行参数。
当执行go run main.go run echo hello时,会创建出main进程,main进程内执行/proc/self/exe child echo hello命令创建出一个新的exe进程。关键就在于这个exe进程:我们已经为其配置了CLONE_NEWUTS系统调用参数进行UTS隔离。也就是说,exe进程可以拥有和main进程不同的主机名,彼此互不干扰。
进程访问/proc/self/exe代表着运行对应进程自身的二进制文件。因此,按照exe进程的启动参数,会执行child()函数。在child()函数内,首先调用syscall.Sethostname更改主机名(此时是exe进程执行的,不会影响到main进程),接着和最初的run()函数一样,再次使用exec.Command运行用户命令行传递的参数。
总结一下:main进程创建了exe进程(exe进程已进行UTS隔离,其更改主机名不会影响main进程),接着exe进程内执行echo hello命令创建出一个新的echo进程。最后随着echo进程执行完毕,exe进程结束,exe进程结束后,main进程再结束退出。
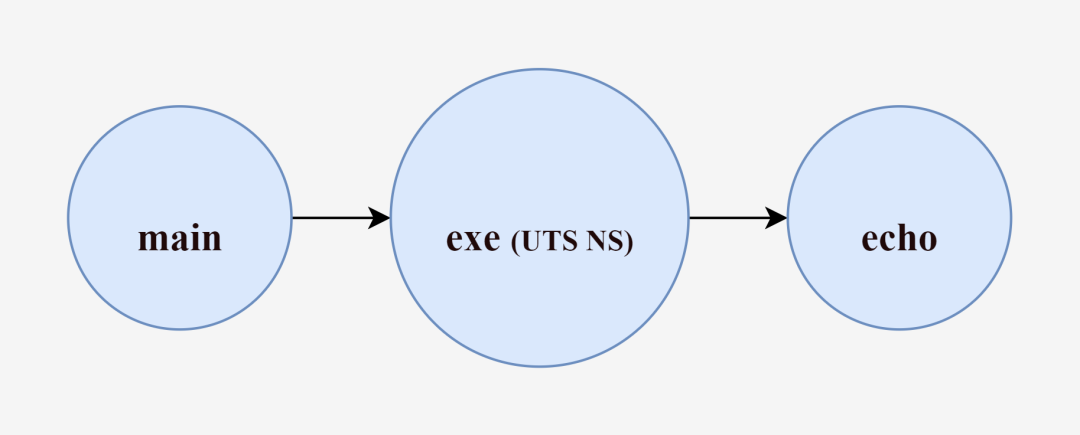
那么,经过exe这个“中间商”创建出来的echo进程,和之前由main进程直接创建的echo进程有何不同呢?
我们知道,创建exe进程的同时我们传递了CLONE_NEWUTS标识符,创建了一个UTS NameSpace。Go内部帮我们封装了系统调用函数clone()的调用。由clone()函数创建出的进程,其子进程也将会成为这些NameSpace的成员。所以默认情况下(创建新进程时未指定其他系统调用参数),由exe进程创建出的echo进程会继承exe进程的资源。echo进程将拥有和exe进程相同的主机名,并且同样与main进程互不干扰。
因此,借助“中间商”exe进程,echo进程成功实现了与宿主机(main进程)的资源隔离,拥有了不同的主机名。
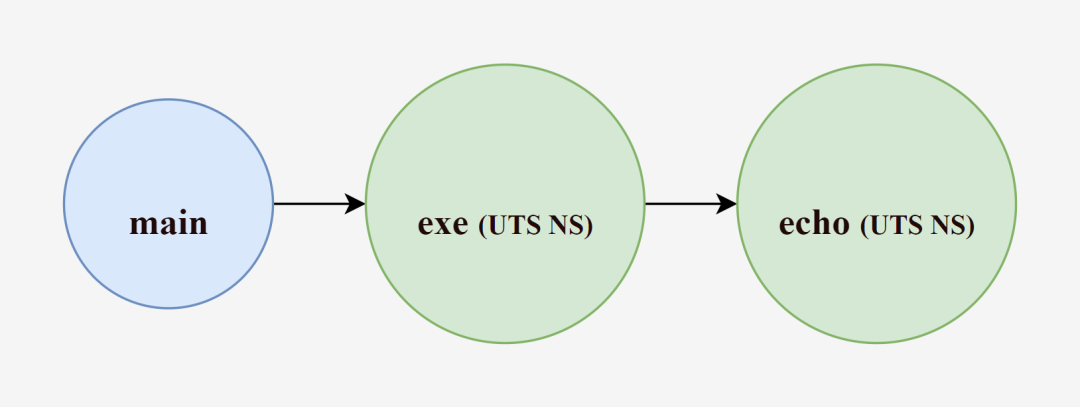
再次通过启动/bin/bash来验证主机名是否已成功隔离:
[root@host go]# hostname
host
[root@host go]# go run main.go run /bin/bash
[root@mycontainer go]# hostname
mycontainer
[root@mycontainer go]# ps
PID TTY TIME CMD
1115 pts/0 00:00:00 bash
1250 pts/0 00:00:00 go
1268 pts/0 00:00:00 main
1271 pts/0 00:00:00 exe
1275 pts/0 00:00:00 bash
1287 pts/0 00:00:00 ps
[root@mycontainer go]# exit
exit
[root@host go]# hostname
host
[root@host go]#
当执行go run main.go run /bin/bash时,我们也可以在另一个ssh会话中,使用ps afx查看关于该bash会话进程的层次信息:
[root@host ~]# ps afx
......
1113 ? Ss 0:00 \_ sshd: root@pts/0
1115 pts/0 Ss 0:00 | \_ -bash
1250 pts/0 Sl 0:00 | \_ go run main.go run /bin/bash
1268 pts/0 Sl 0:00 | \_ /tmp/go-build2476789953/b001/exe/main run /bin/bash
1271 pts/0 Sl 0:00 | \_ /proc/self/exe child /bin/bash
1275 pts/0 S+ 0:00 | \_ /bin/bash
......
以此类推,要新增资源隔离,只需继续传递指定的系统调用参数即可:
package main
import (
"fmt"
"os"
"os/exec"
"syscall"
)
func main() {
switch os.Args[1] {
case "run":
run()
case "child":
child()
default:
panic("help")
}
}
func run() {
fmt.Println("[main]", "pid:", os.Getpid())
cmd := exec.Command("/proc/self/exe", append([]string{"child"}, os.Args[2:]...)...)
cmd.Stdin = os.Stdin
cmd.Stdout = os.Stdout
cmd.Stderr = os.Stderr
cmd.SysProcAttr = &syscall.SysProcAttr{
Cloneflags: syscall.CLONE_NEWUTS |
syscall.CLONE_NEWPID |
syscall.CLONE_NEWNS,
Unshareflags: syscall.CLONE_NEWNS,
}
must(cmd.Run())
}
func child() {
fmt.Println("[exe]", "pid:", os.Getpid())
must(syscall.Sethostname([]byte("mycontainer")))
must(os.Chdir("/"))
must(syscall.Mount("proc", "proc", "proc", 0, ""))
cmd := exec.Command(os.Args[2], os.Args[3:]...)
cmd.Stdin = os.Stdin
cmd.Stdout = os.Stdout
cmd.Stderr = os.Stderr
must(cmd.Run())
must(syscall.Unmount("proc", 0))
}
func must(err error) {
if err != nil {
panic(err)
}
}
Cloneflags参数新增了CLONE_NEWPID和CLONE_NEWNS,分别用于隔离进程PID和文件目录挂载点视图。Unshareflags: syscall.CLONE_NEWNS则是用于禁用挂载传播(如果不设置该参数,container内的挂载会共享到host,挂载传播不在本文探讨范围内)。
当我们创建PID Namespace时,exe进程及其子进程的pid已经与main进程隔离了,这一点可以通过打印os.Getpid()结果或执行echo $$命令验证。但此时还不能使用ps命令查看,因为ps和top等命令会读取/proc目录的内容,所以我们才引入了Mount Namespace,并在exe进程中挂载/proc目录。
Mount Namespace是Linux第一个实现的NameSpace,其系统调用参数是CLONE_NEWNS(New Namespace),因为当时并未意识到之后还会新增这么多NameSpace类型。
[root@host go]# ps
PID TTY TIME CMD
1115 pts/0 00:00:00 bash
3792 pts/0 00:00:00 ps
[root@host go]# echo $$
1115
[root@host go]# go run main.go run /bin/bash
[main] pid: 3811
[exe] pid: 1
[root@mycontainer /]# ps
PID TTY TIME CMD
1 pts/0 00:00:00 exe
4 pts/0 00:00:00 bash
15 pts/0 00:00:00 ps
[root@mycontainer /]# echo $$
4
[root@mycontainer /]# exit
exit
[root@host go]#
此时,exe作为初始化进程,pid为1,并创建出了pid为4的bash子进程,而且已经看不到main进程了。
剩下的IPC、NET、USER等NameSpace就不在本文一一展示了。
2、Cgroups
借助NameSpace技术可以为进程隔离出独立的空间,成功实现最简容器。但是,如何限制这些空间的物理资源开销(CPU、内存、存储、I/O等)呢?这就需要利用Cgroups技术了。
限制容器的资源使用是一个非常重要的功能。如果一个容器可以毫无节制地使用服务器资源,那就又回到了传统模式下应用直接运行在物理服务器上的弊端。这是容器化技术不能接受的。
Cgroups的全称是Control groups(控制组),最早由Google的工程师在2006年发起,一开始叫做进程容器(process containers)。2007年,因为在Linux内核中“容器”一词有多重含义,为避免混乱,被重命名为cgroup,并被合并到2.6.24版本的内核中。
Android也凭借这个技术,为每个APP分配不同的cgroup,将每个APP进行隔离,而不会影响其他APP环境。
Cgroups是对进程分组管理的一种机制,提供对一组进程及其子进程的资源限制、控制和统计的能力。它为每种可以控制的资源定义了一个subsystem(子系统)进行统一接口管理,因此subsystem也被称为资源控制器(resource controllers)。
几个主要的subsystem如下(Cgroups V1):
| 子系统 |
作用 |
| cpu |
限制进程的cpu使用率 |
| cpuacct |
统计进程的cpu使用情况 |
| cpuset |
在多核机器上为进程分配单独的cpu节点或者内存节点(仅限NUMA架构) |
| memory |
限制进程的memory使用量 |
| blkio |
控制进程对块设备(例如硬盘)io的访问 |
| devices |
控制进程对设备的访问 |
| net_cls |
标记进程的网络数据包,以便可以使用tc模块(traffic control)对数据包进行限流、监控等控制 |
| net_prio |
控制进程产生的网络流量的优先级 |
| freezer |
挂起或者恢复进程 |
| pids |
限制cgroup的进程数量 |
| 更多子系统参考Linux man cgroups文档 |
https://man7.org/linux/man-pages/man7/cgroups.7.html |
借助Cgroups机制,可以将一组进程(task group)和一组subsystem关联起来,达到控制进程对应关联资源的能力。如图所示:
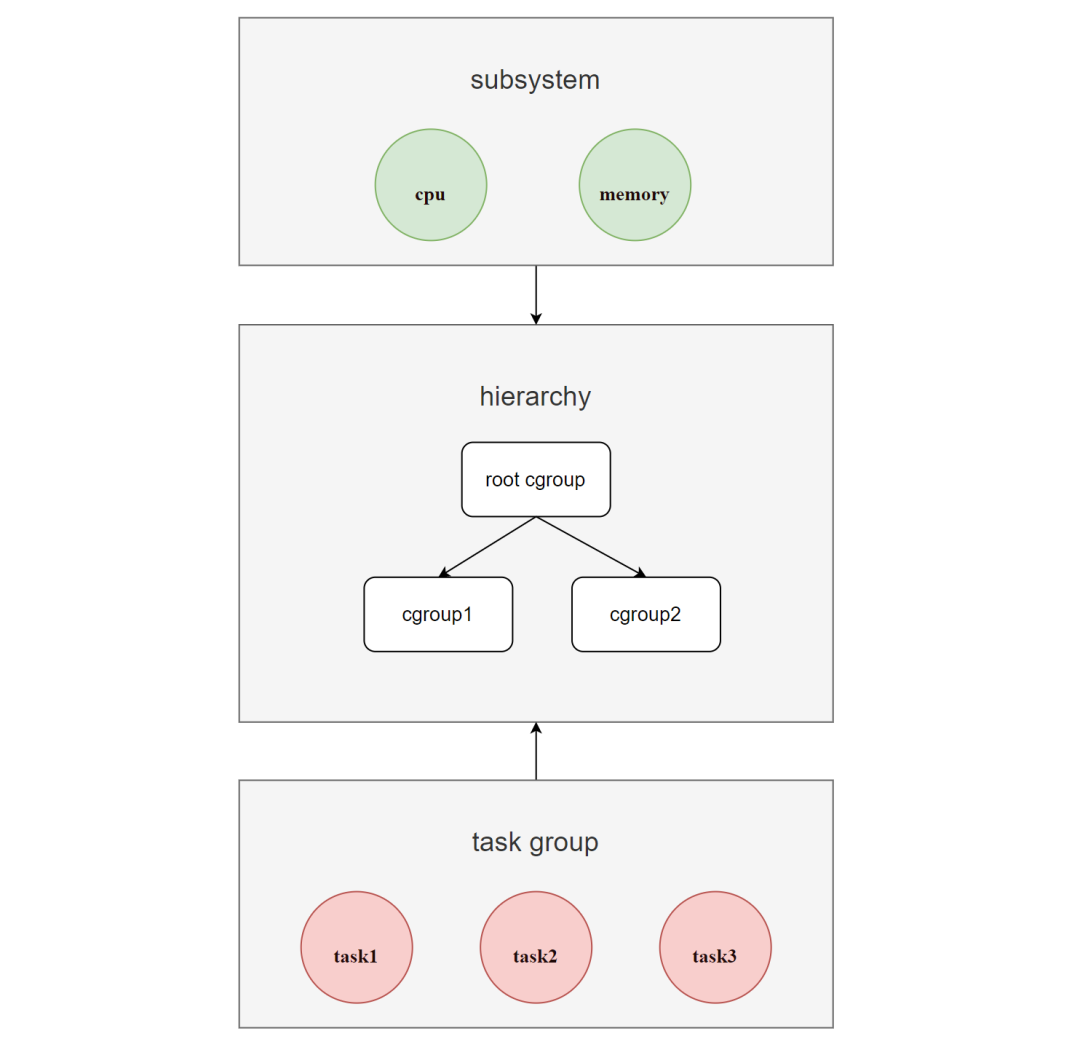
Cgroups的层级结构称为hierarchy(即cgroup树),是一棵树,由cgroup节点组成。
系统可以有多个hierarchy。当创建新的hierarchy时,系统所有的进程都会加入到这个hierarchy默认创建的root cgroup根节点中。在树中,子节点可以继承父节点的属性。
对于同一个hierarchy,进程只能存在于其中一个cgroup节点中。如果把一个进程添加到同一个hierarchy中的另一个cgroup节点,则会从第一个cgroup节点中移除。
hierarchy可以附加一个或多个subsystem来拥有对应资源(如cpu和memory)的管理权。其中每一个cgroup节点都可以设置不同的资源限制权重,而进程(task)则绑定在cgroup节点中,并且其子进程也会默认绑定到父进程所在的cgroup节点中。
基于Cgroups的这些运作原理,可以得出:如果想限制某些进程的内存资源,就可以先创建一个hierarchy,并为其挂载memory subsystem,然后在这个hierarchy中创建一个cgroup节点,在这个节点中,将需要控制的进程pid和控制属性写入即可。
接下来我们就来实践一下。
Linux一切皆文件。
在Linux内核中,为了让Cgroups的配置更直观,使用了目录的层级关系来模拟hierarchy,以此通过虚拟的树状文件系统的方式暴露给用户调用。
创建一个hierarchy并为其挂载memory subsystem这一步我们可以跳过,因为系统已经默认为每个subsystem创建了一个默认的hierarchy,我们可以直接使用。
例如,memory subsystem默认的hierarchy就在/sys/fs/cgroup/memory目录。
[root@host go]# mount | grep memory
cgroup on /sys/fs/cgroup/memory type cgroup (rw,nosuid,nodev,noexec,relatime,memory)
[root@host go]# cd /sys/fs/cgroup/memory
[root@host memory]# pwd
/sys/fs/cgroup/memory
[root@host memory]#
只要在这个hierarchy目录下创建一个文件夹,就相当于创建了一个cgroup节点:
[root@host memory]# mkdir hello
[root@host memory]# cd hello/
[root@host hello]# ls
cgroup.clone_children memory.kmem.slabinfo memory.memsw.failcnt memory.soft_limit_in_bytes
cgroup.event_control memory.kmem.tcp.failcnt memory.memsw.limit_in_bytes memory.stat
cgroup.procs memory.kmem.tcp.limit_in_bytes memory.memsw.max_usage_in_bytes memory.swappiness
memory.failcnt memory.kmem.tcp.max_usage_in_bytes memory.memsw.usage_in_bytes memory.usage_in_bytes
memory.force_empty memory.kmem.tcp.usage_in_bytes memory.move_charge_at_immigrate memory.use_hierarchy
memory.kmem.failcnt memory.kmem.usage_in_bytes memory.numa_stat notify_on_release
memory.kmem.limit_in_bytes memory.limit_in_bytes memory.oom_control tasks
memory.kmem.max_usage_in_bytes memory.max_usage_in_bytes memory.pressure_level
[root@host hello]#
其中我们创建的hello文件夹内的所有文件都是系统自动创建的。常用的几个文件功能如下:
| 文件名 |
功能 |
| tasks |
cgroup中运行的进程(PID)列表。将PID写入一个cgroup的tasks文件,可将此进程移至该cgroup |
| cgroup.procs |
cgroup中运行的线程群组列表(TGID)。将TGID写入cgroup的cgroup.procs文件,可将此线程组群移至该cgroup |
| cgroup.event_control |
event_fd()的接口。允许cgroup的变更状态通知被发送 |
| notify_on_release |
用于自动移除空cgroup。默认为禁用状态(0)。设定为启用状态(1)时,当cgroup不再包含任何任务时(即,cgroup的tasks文件包含PID,而PID被移除,致使文件变空),kernel会执行release_agent文件(仅在root cgroup出现)的内容,并且提供通向被清空cgroup的相关路径(与root cgroup相关)作为参数 |
| memory.usage_in_bytes |
显示cgroup中进程当前所用的内存总量(以字节为单位) |
| memory.memsw.usage_in_bytes |
显示cgroup中进程当前所用的内存量和swap空间总和(以字节为单位) |
| memory.max_usage_in_bytes |
显示cgroup中进程所用的最大内存量(以字节为单位) |
| memory.memsw.max_usage_in_bytes |
显示cgroup中进程的最大内存用量和最大swap空间用量(以字节为单位) |
| memory.limit_in_bytes |
设定用户内存(包括文件缓存)的最大用量 |
| memory.memsw.limit_in_bytes |
设定内存与swap用量之和的最大值 |
| memory.failcnt |
显示内存达到memory.limit_in_bytes设定的限制值的次数 |
| memory.memsw.failcnt |
显示内存和swap空间总和达到memory.memsw.limit_in_bytes设定的限制值的次数 |
| memory.oom_control |
可以为cgroup启用或者禁用“内存不足”(Out of Memory,OOM)终止程序。默认为启用状态(0),尝试消耗超过其允许内存的任务会被OOM终止程序立即终止。设定为禁用状态(1)时,尝试使用超过其允许内存的任务会被暂停,直到有额外内存可用。 |
| 更多文件的功能说明可以查看kernel文档中的cgroup-v1/memory |
https://www.kernel.org/doc/Documentation/cgroup-v1/memory.txt |
在这个hello cgroup节点中,我们想限制某些进程的内存资源,只需将对应的进程pid写入到tasks文件,并把内存最大用量设定到memory.limit_in_bytes文件即可。
[root@host hello]# cat memory.oom_control
oom_kill_disable 0
under_oom 0
[root@host hello]# cat memory.failcnt
0
[root@host hello]# echo 100M > memory.limit_in_bytes
[root@host hello]# cat memory.limit_in_bytes
104857600
[root@host hello]#
hello cgroup节点默认启用了OOM终止程序,因此,当有进程尝试使用超过可用内存时会被立即终止。查询memory.failcnt可知,目前还没有进程内存达到过设定的最大内存限制值。
我们已经设定了hello cgroup节点可使用的最大内存为100M。此时新启动一个bash会话进程并将其移入到hello cgroup节点中:
[root@host hello]# /bin/bash
[root@host hello]# echo $$
4123
[root@host hello]# cat tasks
[root@host hello]# echo $$ > tasks
[root@host hello]# cat tasks
4123
4135
[root@host hello]# cat memory.usage_in_bytes
196608
[root@host hello]#
后续在此会话进程所创建的子进程都会自动加入到该hello cgroup节点中(例如pid 4135就是由于执行cat命令而创建的新进程,被系统自动加入到了tasks文件中)。
继续使用memtester工具来测试100M的最大内存限制是否生效:
[root@host hello]# memtester 50M 1
memtester version 4.5.1 (64-bit)
Copyright (C) 2001-2020 Charles Cazabon.
Licensed under the GNU General Public License version 2 (only).
pagesize is 4096
pagesizemask is 0xfffffffffffff000
want 50MB (52428800 bytes)
got 50MB (52428800 bytes), trying mlock ...locked.
Loop 1/1:
Stuck Address : ok
Random Value : ok
Compare XOR : ok
Compare SUB : ok
Compare MUL : ok
Compare DIV : ok
Compare OR : ok
Compare AND : ok
Sequential Increment: ok
Solid Bits : ok
Block Sequential : ok
Checkerboard : ok
Bit Spread : ok
Bit Flip : ok
Walking Ones : ok
Walking Zeroes : ok
8-bit Writes : ok
16-bit Writes : ok
Done.
[root@host hello]# memtester 100M 1
memtester version 4.5.1 (64-bit)
Copyright (C) 2001-2020 Charles Cazabon.
Licensed under the GNU General Public License version 2 (only).
pagesize is 4096
pagesizemask is 0xfffffffffffff000
want 100MB (104857600 bytes)
got 100MB (104857600 bytes), trying mlock ...over system/pre-process limit, reducing...
got 99MB (104853504 bytes), trying mlock ...over system/pre-process limit, reducing...
got 99MB (104849408 bytes), trying mlock ...over system/pre-process limit, reducing...
......
[root@host hello]# cat memory.failcnt
1434
[root@host hello]#
可以看到当memtester尝试申请100M内存时,失败了。而memory.failcnt报告显示内存达到memory.limit_in_bytes设定的限制值(100M)的次数为1434次。
如果想要删除cgroup节点,也只需要删除对应的文件夹即可。
[root@host hello]# exit
exit
[root@host hello]# cd ../
[root@host memory]# rmdir hello/
[root@host memory]#
经过上面对Cgroups的使用和实践,可以将其应用到我们之前的Go程序中:
package main
import (
"fmt"
"io/ioutil"
"os"
"os/exec"
"path/filepath"
"strconv"
"syscall"
)
func main() {
switch os.Args[1] {
case "run":
run()
case "child":
child()
default:
panic("help")
}
}
func run() {
fmt.Println("[main]", "pid:", os.Getpid())
cmd := exec.Command("/proc/self/exe", append([]string{"child"}, os.Args[2:]...)...)
cmd.Stdin = os.Stdin
cmd.Stdout = os.Stdout
cmd.Stderr = os.Stderr
cmd.SysProcAttr = &syscall.SysProcAttr{
Cloneflags: syscall.CLONE_NEWUTS |
syscall.CLONE_NEWPID |
syscall.CLONE_NEWNS,
Unshareflags: syscall.CLONE_NEWNS,
}
must(cmd.Run())
}
func child() {
fmt.Println("[exe]", "pid:", os.Getpid())
cg()
must(syscall.Sethostname([]byte("mycontainer")))
must(os.Chdir("/"))
must(syscall.Mount("proc", "proc", "proc", 0, ""))
cmd := exec.Command(os.Args[2], os.Args[3:]...)
cmd.Stdin = os.Stdin
cmd.Stdout = os.Stdout
cmd.Stderr = os.Stderr
must(cmd.Run())
must(syscall.Unmount("proc", 0))
}
func cg() {
mycontainer_memory_cgroups := "/sys/fs/cgroup/memory/mycontainer"
os.Mkdir(mycontainer_memory_cgroups, 0755)
must(ioutil.WriteFile(filepath.Join(mycontainer_memory_cgroups, "memory.limit_in_bytes"), []byte("100M"), 0700))
must(ioutil.WriteFile(filepath.Join(mycontainer_memory_cgroups, "notify_on_release"), []byte("1"), 0700))
must(ioutil.WriteFile(filepath.Join(mycontainer_memory_cgroups, "tasks"), []byte(strconv.Itoa(os.Getpid())), 0700))
}
func must(err error) {
if err != nil {
panic(err)
}
}
我们在exe进程添加了对cg()函数的调用。代码相对简单,和我们的实践流程几乎一致,区别只在于为notify_on_release文件设定为1值,使得当我们的exe进程退出后,可以自动移除所创建的cgroup。
[root@host go]# go run main.go run /bin/bash
[main] pid: 4693
[exe] pid: 1
[root@mycontainer /]# ps
PID TTY TIME CMD
1 pts/2 00:00:00 exe
4 pts/2 00:00:00 bash
15 pts/2 00:00:00 ps
[root@mycontainer /]# cat /sys/fs/cgroup/memory/mycontainer/tasks
1
4
16
[root@mycontainer /]# cat /sys/fs/cgroup/memory/mycontainer/notify_on_release
1
[root@mycontainer /]# cat /sys/fs/cgroup/memory/mycontainer/memory.limit_in_bytes
104857600
[root@mycontainer /]#
使用memtester测试,结果预期一致:
[root@mycontainer /]# memtester 100M 1
memtester version 4.5.1 (64-bit)
Copyright (C) 2001-2020 Charles Cazabon.
Licensed under the GNU General Public License version 2 (only).
pagesize is 4096
pagesizemask is 0xfffffffffffff000
want 100MB (104857600 bytes)
got 100MB (104857600 bytes), trying mlock ...over system/pre-process limit, reducing...
got 99MB (104853504 bytes), trying mlock ...over system/pre-process limit, reducing...
got 99MB (104849408 bytes), trying mlock ...over system/pre-process limit, reducing...
......
[root@mycontainer /]# exit
exit
[root@host go]#
同样篇幅问题,剩下的subsystem也不在本文一一展示了。
其实到这里,我们已经通过NameSpace技术为进程隔离出自己单独的空间,并使用Cgroups技术限制和监控这些空间的资源开销。这种特殊的进程就是容器的本质。可以说,我们本篇文章的目的已达成,可以结束了。
但是,除了利用NameSpace和Cgroups来实现容器(container),在Docker中还使用到了一个Linux内核技术:UnionFS来实现镜像(images)功能。
鉴于本篇文章的主旨——使用Go和Linux Kernel技术探究容器化原理的主要技术点是NameSpace和Cgroups。镜像的实现技术UnionFS属于加餐内容,可自行选择是否需要消化。
3、UnionFS
UnionFS全称Union File System(联合文件系统),在2004年由纽约州立大学石溪分校开发,是为Linux、FreeBSD和NetBSD操作系统设计的一种分层、轻量级并且高性能的文件系统。它可以把多个目录内容联合挂载到同一个目录下,而目录的物理位置是分开的,并且对文件系统的修改是类似于git的commit一样作为一次提交来一层层叠加的。
在Docker中,镜像相当于是容器的模板,一个镜像可以衍生出多个容器。镜像利用UnionFS技术来实现,就可以利用其分层的特性来进行镜像的继承。基于基础镜像,制作出各种具体的应用镜像,不同容器就可以直接共享基础的文件系统层,同时再加上自己独有的改动层,大大提高了存储的效率。
以该Dockerfile为例:
FROM ubuntu:18.04
LABEL org.opencontainers.image.authors="org@example.com"
COPY . /app
RUN make /app
RUN rm -r $HOME/.cache
CMD python /app/app.py
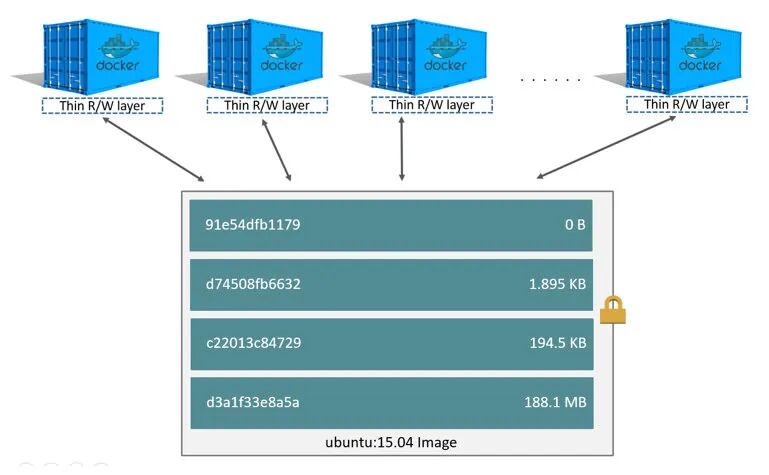
镜像的每一层都可以代表Dockerfile中的一条指令,并且除了最后一层之外的每一层都是只读的。
在该Dockerfile中包含了多个命令,如果命令修改了文件系统就会创建一个层(利用UnionFS的原理)。
首先FROM语句从ubuntu:18.04镜像创建一个层【1】。LABEL命令仅修改镜像的元数据,不会生成新镜像层。接着COPY命令会把当前目录中的文件添加到镜像中的/app目录下,在层【1】的基础上生成了层【2】。
第一个RUN命令使用make构建应用程序,并将结果写入新层【3】。第二个RUN命令删除缓存目录,并将结果写入新层【4】。最后,CMD指令指定在容器内运行什么命令,只修改了镜像的元数据,也不会产生镜像层。
这【4】个层(layer)相互堆叠在一起就是一个镜像。当创建一个新容器时,会在镜像层(image layers)上面再添加一个新的可写层,称为容器层(container layer)。对正在运行的容器所做的所有更改,例如写入新文件、修改现有文件和删除文件,都会写入到这个可写容器层。
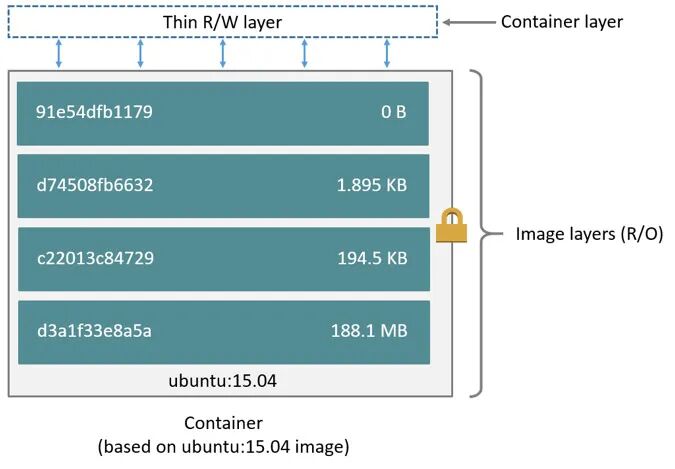
对于相同的镜像层,每一个容器都会有自己的可写容器层,并且所有的变化都存储在这个容器层中。所以多个容器可以共享对同一个底层镜像的访问,并且拥有自己的数据状态。而当容器被删除时,其可写容器层也会被删除。如果用户需要持久化容器里的数据,就需要使用Volume挂载到宿主机目录。
看完Docker镜像的运作原理,让我们回到其实现技术UnionFS本身。
目前Docker支持的UnionFS有以下几种类型:
| 联合文件系统 |
存储驱动 |
说明 |
| OverlayFS |
overlay2 |
当前所有受支持的Linux发行版的首选存储驱动程序,并且不需要任何额外的配置 |
| OverlayFS |
fuse-overlayfs |
仅在不提供对rootless支持的主机上运行Rootless Docker时才首选 |
| Btrfs 和 ZFS |
btrfs 和 zfs |
允许使用高级选项,例如创建快照,但需要更多的维护和设置 |
| VFS |
vfs |
旨在用于测试目的,以及无法使用写时复制文件系统的情况下使用。此存储驱动程序性能较差,一般不建议用于生产用途 |
| AUFS |
aufs |
Docker 18.06和更早版本的首选存储驱动程序。但是在没有overlay2驱动的机器上仍然会使用aufs作为Docker的默认驱动 |
| Device Mapper |
devicemapper |
RHEL(旧内核版本不支持overlay2,最新版本已支持)的Docker Engine的默认存储驱动,有两种配置模式:loop-lvm(零配置但性能差)和direct-lvm(生产环境推荐) |
| OverlayFS |
overlay |
推荐使用overlay2存储驱动 |
在尽可能的情况下,推荐使用OverlayFS的overlay2存储驱动,这也是当前Docker默认的存储驱动(以前是AUFS的aufs)。
可查看Docker使用了哪种存储驱动:
[root@host ~]# docker -v
Docker version 20.10.15, build fd82621
[root@host ~]# docker info | grep Storage
Storage Driver: overlay2
[root@host ~]#
OverlayFS是一个类似于AUFS的、面向Linux的现代联合文件系统,在2014年被合并到Linux内核(version 3.18)中,相比AUFS其速度更快且实现更简单。overlay2(Linux内核version 4.0或以上)则是其推荐的驱动程序。
overlay2由四个结构组成,其中:
- lowerdir:表示较为底层的目录,对应Docker中的只读镜像层。
- upperdir:表示较为上层的目录,对应Docker中的可写容器层。
- workdir:表示工作层(中间层)的目录,在使用过程中对用户不可见。
- merged:所有目录合并后的联合挂载点,给用户暴露的统一目录视图,对应Docker中用户实际看到的容器内的目录视图。
这是在Docker文档中关于overlay的架构图,但是对于overlay2也同样可以适用:
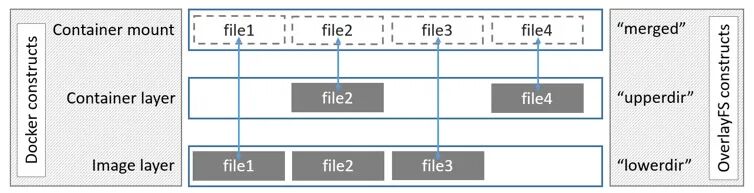
其中lowerdir所对应的镜像层(Image layer),实际上是可以有很多层的,图中只画了一层。
细心的小伙伴可能会发现,图中并没有出现workdir,它究竟是如何工作的呢?
我们可以从读写的视角来理解。对于读的情况:
- 文件在upperdir,直接读取。
- 文件不在upperdir,从lowerdir读取,会产生非常小的性能开销。
- 文件同时存在upperdir和lowerdir中,从upperdir读取(upperdir中的文件隐藏了lowerdir中的同名文件)。
对于写的情况:
- 创建一个新文件,文件在upperdir和lowerdir中都不存在,则直接在upperdir创建。
- 修改文件,如果该文件在upperdir中存在,则直接修改。
- 修改文件,如果该文件在upperdir中不存在,将执行copy_up操作,把文件从lowerdir复制到upperdir,后续对该文件的写入操作将对已经复制到upperdir的副本文件进行操作。这就是写时复制(copy-on-write)。
- 删除文件,如果文件只在upperdir存在,则直接删除。
- 删除文件,如果文件只在lowerdir存在,会在upperdir中创建一个同名的空白文件(whiteout file),lowerdir中的文件不会被删除,因为它们是只读的,但whiteout file会阻止它们继续显示。
- 删除文件,如果文件在upperdir和lowerdir中都存在,则先将upperdir中的文件删除,再创建一个同名的空白文件(whiteout file)。
- 删除目录和删除文件是一致的,会在upperdir中创建一个同名的不透明的目录(opaque directory),和whiteout file原理一样,opaque directory会阻止用户继续访问,即便lowerdir内的目录仍然存在。
说了半天,好像还是没有讲到workdir的作用。但其实workdir的作用不可忽视。想象一下,在删除文件(或目录)的场景下(文件或目录在upperdir和lowerdir中都存在),对于lowerdir而言,倒没什么,毕竟只读,不需要理会。但是对于upperdir来讲就不同了:在upperdir中,我们要先删除对应的文件,然后才可以创建同名的whiteout file。如何保证这两步必须都执行?这就涉及到了原子性操作。
workdir就是用来进行一些中间操作的,其中就包括了原子性保证。在上面的问题中,完全可以先在workdir创建一个同名的whiteout file,然后再在upperdir上执行两步操作,成功之后,再删除掉workdir中的whiteout file即可。
而当修改文件时,workdir也在充当着中间层的作用:当对upperdir里面的副本进行修改时,会先放到workdir,然后再从workdir移到upperdir里面去。
理解完overlay2运作原理,接下来正式进入到演示环节。
首先可以来看看在Docker中启动了一个容器后,其挂载点是怎样的:
[root@host ~]# mount | grep overlay
[root@host ~]# docker run -d -it ubuntu:18.04 /bin/bash
cb25841054d9f037ec5cf4c24a97a05f771b43a358dd89b40346ca3ab0e5eaf4
[root@host ~]# mount | grep overlay
overlay on /var/lib/docker/overlay2/56bbb1dbdd636984e4891db7850939490ece5bc7a3f3361d75b1341f0fb30b85/merged type overlay (rw,relatime,lowerdir=/var/lib/docker/overlay2/l/OOPFROHUDK727Z5QKNPWG5FBWV:/var/lib/docker/overlay2/l/6TWQL4UC7XYLZWZBKPS6F4IKLF,upperdir=/var/lib/docker/overlay2/56bbb1dbdd636984e4891db7850939490ece5bc7a3f3361d75b1341f0fb30b85/diff,workdir=/var/lib/docker/overlay2/56bbb1dbdd636984e4891db7850939490ece5bc7a3f3361d75b1341f0fb30b85/work)
[root@host ~]# ll /var/lib/docker/overlay2/56bbb1dbdd636984e4891db7850939490ece5bc7a3f3361d75b1341f0fb30b85/merged
total 76
drwxr-xr-x 2 root root 4096 Apr 28 08:04 bin
drwxr-xr-x 2 root root 4096 Apr 24 2018 boot
drwxr-xr-x 1 root root 4096 May 10 11:17 dev
drwxr-xr-x 1 root root 4096 May 10 11:17 etc
drwxr-xr-x 2 root root 4096 Apr 24 2018 home
drwxr-xr-x 8 root root 4096 May 23 2017 lib
drwxr-xr-x 2 root root 4096 Apr 28 08:03 lib64
drwxr-xr-x 2 root root 4096 Apr 28 08:03 media
drwxr-xr-x 2 root root 4096 Apr 28 08:03 mnt
drwxr-xr-x 2 root root 4096 Apr 28 08:03 opt
drwxr-xr-x 2 root root 4096 Apr 24 2018 proc
drwx------ 2 root root 4096 Apr 28 08:04 root
drwxr-xr-x 5 root root 4096 Apr 28 08:04 run
drwxr-xr-x 2 root root 4096 Apr 28 08:04 sbin
drwxr-xr-x 2 root root 4096 Apr 28 08:03 srv
drwxr-xr-x 2 root root 4096 Apr 28 08:03 sys
drwxrwxrwt 2 root root 4096 Apr 28 08:04 tmp
drwxr-xr-x 10 root root 4096 Apr 28 08:03 usr
drwxr-xr-x 11 root root 4096 Apr 28 08:04 var
[root@host ~]#
可以看到,挂载后的merged目录包括了lowerdir、upperdir、workdir目录,而merged目录实际上就是容器内用户看到的目录视图。
回到技术本身,我们可以自己来尝试一下如何使用mount的overlay挂载选项:

首先创建好lowerdir(创建了2个)、upperdir、workdir、merged目录,并为lowerdir和upperdir目录写入一些文件:
[root@host ~]# mkdir test_overlay
[root@host ~]# cd test_overlay/
[root@host test_overlay]# mkdir lower1
[root@host test_overlay]# mkdir lower2
[root@host test_overlay]# mkdir upper
[root@host test_overlay]# mkdir work
[root@host test_overlay]# mkdir merged
[root@host test_overlay]# echo 'lower1-file1' > lower1/file1.txt
[root@host test_overlay]# echo 'lower2-file2' > lower2/file2.txt
[root@host test_overlay]# echo 'upper-file3' > upper/file3.txt
[root@host test_overlay]# tree
.
|-- lower1
| `-- file1.txt
|-- lower2
| `-- file2.txt
|-- merged
|-- upper
| `-- file3.txt
`-- work
5 directories, 3 files
[root@host test_overlay]#
使用mount命令的overlay选项模式进行挂载:
[root@host test_overlay]# mount -t overlay overlay -olowerdir=lower1:lower2,upperdir=upper,workdir=work merged
[root@host test_overlay]# mount | grep overlay
......
overlay on /root/test_overlay/merged type overlay (rw,relatime,lowerdir=lower1:lower2,upperdir=upper,workdir=work)
[root@host test_overlay]#
此时进入merged目录就可以看到所有文件了:
[root@host test_overlay]# cd merged/
[root@host merged]# ls
file1.txt file2.txt file3.txt
[root@host merged]#
我们尝试修改lowerdir目录内的文件:
[root@host merged]# echo 'lower1-file1-hello' > file1.txt
[root@host merged]# cat file1.txt
lower1-file1-hello
[root@host merged]# cat /root/test_overlay/lower1/file1.txt
lower1-file1
[root@host merged]# ls /root/test_overlay/upper/
file1.txt file3.txt
[root@host merged]# cat /root/test_overlay/upper/file1.txt
lower1-file1-hello
[root@host merged]#
和之前我们所说的一致:当修改lowerdir内的文件时,会执行copy_up操作,把文件从lowerdir复制到upperdir,后续对该文件的写入操作将对已经复制到upperdir的副本文件进行操作。
其他的读写情况,大家可以自行尝试。
总结
其实容器的底层原理并不难。本质上,容器就是一个特殊的进程,特殊在为其创建了NameSpace隔离运行环境,并用Cgroups为其控制了资源开销。这些都是站在Linux操作系统的肩膀上实现的,包括Docker的镜像实现也是利用了UnionFS的分层联合技术。
我们甚至可以说,几乎所有应用的本质都是上层调下层,下层支撑着上层。深入理解这些底层技术,不仅能帮助我们更好地使用容器工具,还能在遇到问题时进行有效排查和优化。云栈社区提供了丰富的技术资源和交流平台,是开发者深入学习和分享经验的理想场所。
参考资料
[1] Linux man 手册中的 NAMESPACES: https://man7.org/linux/man-pages/man7/namespaces.7.html
[2] 源自 Containers From Scratch • Liz Rice • GOTO 2018: https://www.youtube.com/watch?v=8fi7uSYlOdc
[3] Linux man cgroups: https://man7.org/linux/man-pages/man7/cgroups.7.html
[4] cgroup-v1/memory: https://www.kernel.org/doc/Documentation/cgroup-v1/memory.txt
[5] memtester: https://pyropus.ca./software/memtester/
[6] 以该 Dockerfile 为例: https://docs.docker.com/storage/storagedriver/
[7] overlay 的架构图: https://docs.docker.com/storage/storagedriver/overlayfs-driver/#how-the-overlay-driver-works
[8] mount 的 overlay 挂载选项: https://man7.org/linux/man-pages/man8/mount.8.html
 发表于 2026-4-8 03:10:50
|
查看: 166|
回复: 0
发表于 2026-4-8 03:10:50
|
查看: 166|
回复: 0
