背景
在实现云开发机这类对磁盘空间有精确限制需求的场景时,我们遇到了一个技术难题:如何按照用户购买的大小来限制其系统盘的容量?问题根源在于,当前主流的容器运行时 containerd 并不原生支持为 overlayfs 文件系统设置 Quota(磁盘配额)。相比之下,Docker 通过 --storage-opt 参数可以轻松实现:
docker run -d --storage-opt size=1G docker.m.daocloud.io/library/ubuntu:22.04 sleep 100000
在 Kubernetes 生态中,我们曾临时采用在 Pod 的 resource 中设置 ephemeral-storage 请求和限制的方案,但这个方案存在明显缺陷:
- 它会驱动
kubelet 定期扫描和计算容器实际使用的磁盘容量,这个过程涉及大量文件读取,无疑会增加系统负载。
- 更关键的是,一旦发现用量超限,它会直接删除对应的
Pod。这在云开发机场景下是完全不可接受的,因为这会导致用户的工作环境被意外重建,数据丢失,体验极差。
为了解决这个痛点,我进行了深入调研并最终实现了一个解决方案。本文将分享其核心实现思路。基于此思路,我开发了一个插件,能够在以 containerd 为容器运行时的 Kubernetes 集群中,为容器根目录设置精确的磁盘配额。
值得一提的是,Containerd 社区早在 issue #759 中就讨论过此功能,但至今仍未落地。
原理
既然 Docker 已经实现了此功能,我们自然可以借鉴其思路。Docker 的 --storage-opt size=1G 参数目前仅在使用 overlayfs 存储驱动并结合 xfs 文件系统时才生效。这是因为 xfs 文件系统提供了一种强大的 Quota(配额)功能,可以对用户(User)、用户组(Group)或项目(Project)三个维度进行限制。Docker 采用的正是 Project(项目) 维度的配额。
XFS Quota
XFS 的 Project Quota 特性允许我们为一个目录树分配一个唯一的 Project ID,并为此 ID 设置一个写入数据块的总量上限。这完美契合了我们“限制特定目录及其子目录总数据量”的需求,比针对用户或用户组的限制更加灵活和精准。
要启用 Project Quota,必须在挂载文件系统时添加对应的挂载选项。对于 XFS,启用 Project Quota 的选项是 pquota。如果需要对根目录 / 启用,则必须将其作为内核启动参数 rootflags=pquota 传递,以确保根文件系统在初始挂载时就具备该能力。
对于其他数据盘,可以在 /etc/fstab 或 mount 命令中直接指定 prjquota 选项。挂载后,可以通过 cat /proc/mounts 命令来验证,正确的挂载信息中应包含 prjquota 字段。

确认文件系统支持后,下一步就是为目标目录设置 Project ID 并配置限额。假设我们要限制 /data/xfs_prjquota 目录:
mkdir -p /data/xfs_prjquota
# 为目录设置 Project ID 为 101
xfs_quota -x -c 'project -s -p /data/xfs_prjquota 101' /
# 为 Project ID 101 设置硬限制为 100MB
xfs_quota -x -c 'limit -p bhard=100m 101' /
现在,尝试向该目录写入超过 100MB 的数据:
$ dd if=/dev/zero of=/data/xfs_prjquota/test.file bs=10MB count=20
dd: error writing '/data/xfs_prjquota/test.file': No space left on device
10241+0 records in
10240+0 records out
104857600 bytes (100 MB, 100 MiB) copied, 0.357122 s, 294 MB/s
# ls -l /tmp/xfs_prjquota/test.file
-rw-r--r-- 1 root root 104857600 Oct 31 10:00 /data/xfs_prjquota/test.file
可以看到,写入在达到 100MB 限额后被阻止,并返回“设备空间不足”的错误,最终文件大小恰好是 100MB。
其核心机制如下:
- 为目标目录(
inode)打上一个唯一的 Project ID。此后,在该目录下创建的所有新文件和子目录都会自动继承这个 ID。
- 在 XFS 文件系统层面,为该 Project ID 设置一个数据块写入的硬性限制。
- 文件系统会实时统计所有携带此 Project ID 的文件所占用的数据块总和,并与预设的限制值比较。一旦总和达到上限,文件系统便会拒绝新的数据写入。
Docker 的实现原理
Docker 正是利用上述 XFS Project Quota 来限制容器的 OverlayFS 层(即可写层)的大小。当我们执行 docker run --storage-opt size=1G 时,Docker 会为容器的 OverlayFS 目录(通常位于 /var/lib/docker/overlay2/<container_id>/)设置一个 Project ID 和对应的配额。该目录下的 diff(对应 upperdir)、work 和 merged 子目录共享这个配额限制。
Containerd 的实现挑战与方案
分析完 Docker 的原理,我们能否照搬到 Containerd 上呢?答案是:原理相通,但实现细节有异,不能直接生搬硬套。
根本区别在于两者 OverlayFS 的目录结构组织方式不同。先来看一下两者的 mount 信息:
Docker 的 OverlayFS 挂载信息:
overlay on /data/docker/overlay2/5b9dd809334119df85ba53ac9ba5153383ded441f768b63f4002196bdfdbd883/merged type overlay (rw,relatime,lowerdir=... ,upperdir=/data/docker/overlay2/5b9dd809334119df85ba53ac9ba5153383ded441f768b63f4002196bdfdbd883/diff,workdir=/data/docker/overlay2/5b9dd809334119df85ba53ac9ba5153383ded441f768b63f4002196bdfdbd883/work)
Containerd 的 OverlayFS 挂载信息:
overlay on /data/run/containerd/io.containerd.runtime.v2.task/k8s.io/f7beb33b46942103d75c9305f704ae90757866fc034018252fc2f9620451340e/rootfs type overlay (rw,relatime,lowerdir=/data/containerd/io.containerd.snapshotter.v1.overlayfs/snapshots/68/fs,upperdir=/data/containerd/io.containerd.snapshotter.v1.overlayfs/snapshots/124/fs,workdir=/data/containerd/io.containerd.snapshotter.v1.overlayfs/snapshots/124/work)
为了更清晰地对比,我们梳理一下关键目录的对应关系:
|
docker 目录 |
containerd 目录 |
| merged |
/data/docker/overlay2/<docker_id> |
/data/run/containerd/io.containerd.runtime.v2.task/k8s.io/<task_id> |
| workdir |
/data/docker/overlay2/<docker_id> |
/data/containerd/io.containerd.snapshotter.v1.overlayfs/snapshots/<snapshot_id> |
| upperdir |
/data/docker/overlay2/<docker_id> |
/data/containerd/io.containerd.snapshotter.v1.overlayfs/snapshots/<snapshot_id> |
关键区别:
- Docker:容器的
merged, workdir, upperdir 这三个关键目录都位于同一个父目录下。因此,Docker 只需要对这个唯一的父目录设置 Project Quota 即可同时限制所有相关层。
- Containerd:
upperdir 和 workdir 位于 snapshotter 管理的目录中(如 snapshots/124/fs 和 snapshots/124/work),而 merged 目录则位于完全不同的运行时任务目录中。它们是分离的。
这个差异导致我们无法像 Docker 那样只对一个目录操作。在 Containerd 中实现配额,必须同时为 upperdir 所在的快照目录和 merged 所在的运行时根目录设置相同的 Project ID 和配额。如果它们不属于同一个 Project ID,容器内执行文件操作(如移动、重命名)时就极有可能触发 Invalid cross-device link 错误,因为文件系统会误认为跨设备操作。
实现与验证工具
在实现过程中,xfs_quota 和 xfs_db 工具是验证和调试的利器。这里列举几个关键命令:
-
查看所有 Project 的使用情况:
$ xfs_quota -x -c "report -h -p" /data
Project quota on /data (/dev/sdb1)
Blocks
Project ID Used Soft Hard Warn/Grace
---------- ---------------------------------
#0 2.8G 0 0 00 [------]
#2 12K 0 0 00 [------]
-
清除某个 Project 的配额限制:
$ xfs_quota -x -c "limit -p bhard=0 bsoft=0 2" /data
-
查询文件或目录的 Project ID(需要先获取其 inode 号):
$ stat /data/containerd
File: /data/containerd
...
Inode: 1033 Links: 13
...
# 使用 inode 号查询 projid
$ xfs_db -xr -c 'inode 1033' -c p /dev/sdb1
core.projid_lo = 0
core.projid_hi = 0
最终效果
基于以上分析,我实现了一个 containerd 插件,它无需修改 containerd 源码,即可在 overlayfs + xfs 的环境下,为每个容器动态设置磁盘配额。其核心是在容器创建时,将对应的 upperdir 目录和 merged 目录关联到同一个新的 Project ID,并施加配额限制。
下图展示了在设置了 1GB 配额的容器内进行磁盘写入测试的效果。当使用 dd 命令尝试写入 1.2GB 数据时,在写入约 979MB 后因空间不足而失败,此时使用 df -h 查看,容器根文件系统的使用量被精确限制在配额范围内。
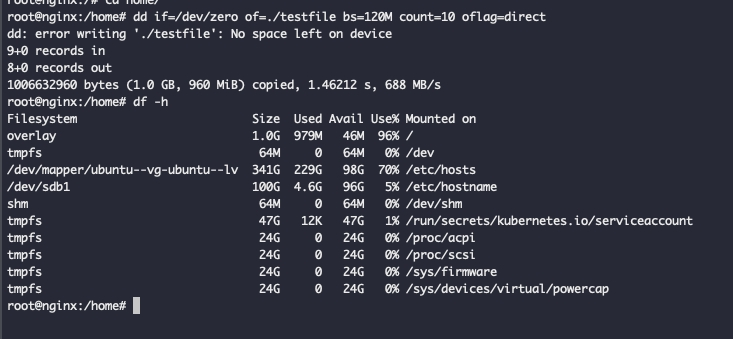
这种基于文件系统底层能力的配额方案,相比 Kubernetes 的 ephemeral-storage 限制,具有精度高、实时性强、无性能损耗、不会导致 Pod 被驱逐等巨大优势,非常适合云开发机、托管服务等对稳定性有严苛要求的场景。如果你在容器存储管理和 DevOps 实践中遇到类似问题,欢迎在 云栈社区 的运维与云原生板块与我们深入探讨。
 发表于 2026-4-8 05:06:53
|
查看: 146|
回复: 0
发表于 2026-4-8 05:06:53
|
查看: 146|
回复: 0
