Redis 的有序集合(Zset)在底层由两种数据结构实现:listpack 和 skiplist(跳表)。这是一种典型的空间与时间权衡策略。当集合内元素数量较少或元素值较小时,Redis 使用 listpack 这种紧凑型结构以节省内存;当数据量超过特定阈值时,则转换为 skiplist 来提升查询效率。这个转换的临界点由 zset-max-listpack-value 和 zset-max-listpack-entries 这两个配置参数共同决定。
Skiplist:用空间换取时间的典范
skiplist 是一种典型的“以空间换时间”的数据结构解决方案。它的核心优势在于数据检索性能优异,时间复杂度为 O(logN)。当然,其代价是更高的空间复杂度 O(N),以及在更新数据时维护索引会带来相对更高的开销。因此,跳表特别适合数据量较大且读多写少的应用场景。巧的是,Redis 本身的设计正是为了应对此类场景。至于“数据量较大”的具体标准,则如前所述,由配置参数控制。
跳表的结构定义
首先,我们来看跳表节点的结构 zskiplistNode:
typedef struct zskiplistNode {
sds ele; // 成员对象(字符串)
double score; // 分值(用于排序)
struct zskiplistNode *backward; // 后退指针(双向链表)
struct zskiplistLevel {
struct zskiplistNode *forward; // 前进指针
unsigned long span; // 跨度(到下一个节点的距离)
} level[]; // 层级数组(柔性数组)
} zskiplistNode;
跳跃表节点 zskiplistNode 字段说明
| 字段名 |
类型 |
含义 |
ele |
sds |
存储的元素值(SDS 字符串) |
score |
double |
元素的分值,用于排序 |
backward |
struct zskiplistNode* |
后退指针,指向前一个节点(实现双向链表) |
level[] |
zskiplistLevel |
层级数组(柔性数组),大小在创建节点时随机确定(1-32) |
level[i].forward |
struct zskiplistNode* |
该层级的前进指针,指向下一个节点 |
level[i].span |
unsigned long |
该层级的跨度,表示从当前节点到 forward 指向节点的距离(节点数) |
紧接着是跳表的整体管理结构 zskiplist:
typedef struct zskiplist {
struct zskiplistNode *header; // 头节点(不存储实际数据)
struct zskiplistNode *tail; // 尾节点
unsigned long length; // 节点数量
int level; // 最大层数
} zskiplist;
跳跃表 zskiplist 字段说明
| 字段名 |
类型 |
含义 |
header |
zskiplistNode* |
头节点指针(不存储实际数据,固定32层) |
tail |
zskiplistNode* |
尾节点指针 |
length |
unsigned long |
跳跃表中实际存储的元素数量 |
level |
int |
当前跳跃表的最大层数(所有节点中的最高层级) |
一个跳表的整体逻辑结构可以理解为下图所示(图中也展示了与 redisObject 的关联关系):
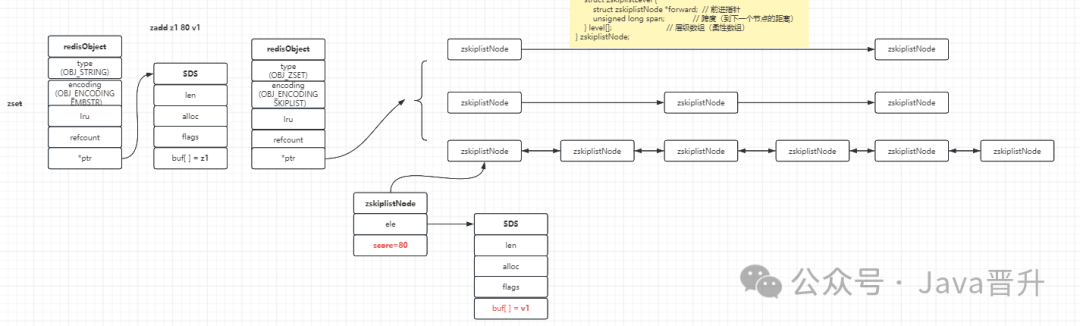
核心特性
-
多层索引结构
- 每个节点的层数是随机生成的(范围1-32),遵循幂次定律。这意味着:
- L0层(最底层):100% 的节点都有。
- L1层:约50% 的节点拥有。
- L2层:约25% 的节点拥有。
- Ln层:约
1/2ⁿ 概率的节点拥有。
- 高层级的节点构成了快速查找的“高速公路”,而低层级则保持了完整的数据结构序列。
-
有序存储
- 所有元素按照
score 分值进行升序排列。
- 当多个元素的
score 分值相同时,则会按照成员对象 ele 的字典序进行排列,确保了确定性的顺序。
简单来说,当你在 Redis 中使用 ZADD 命令时,Redis 会根据当前元素的数量和大小,智能地选择在内存中使用 listpack 还是 skiplist 来存储你的 Zset,以此来平衡内存使用率和操作性能。理解这两种底层结构及其切换机制,有助于我们在进行性能调优和容量规划时做出更准确的判断。 |  发表于 2026-4-8 05:04:25
|
查看: 161|
回复: 0
发表于 2026-4-8 05:04:25
|
查看: 161|
回复: 0
