摘要
本文介绍了一种创新的量化因子构造方法论,它深度融合了自然进化思想与深度学习技术。该方法从数据清洗、特征自动化生成、基于遗传算法的因子挖掘,到利用长短期记忆网络(LSTM)进行收益预测,构建了一套完整的自动化流程。相较于依赖专家经验的传统方法,这套流程能更有效地捕捉市场中的非线性规律,在提升策略收益与控制风险方面展现出显著潜力。
关键词:遗传算法,LSTM
引言
在量化交易策略的构建中,有效因子的挖掘与构造是提升模型预测准确性和策略稳健性的核心。传统方法往往受限于研究者的主观经验,难以穷尽复杂市场中的非线性关系与隐含信息。近年来,机器学习与智能优化算法的飞速发展,为因子构造的自动化与智能化开辟了新路径。本文将详细阐述一种融合了自动特征生成、遗传算法优化以及LSTM时序预测的综合解决方案,旨在为量化策略带来可持续的超额收益。
方法论
3.1 数据预处理与特征构造
- 原始数据预处理:数据质量是模型效果的基石。通过对原始价格、成交量等数据进行缺失值处理、异常值检测和时间序列对齐,确保后续计算的准确性。处理后的量价数据示例如下:
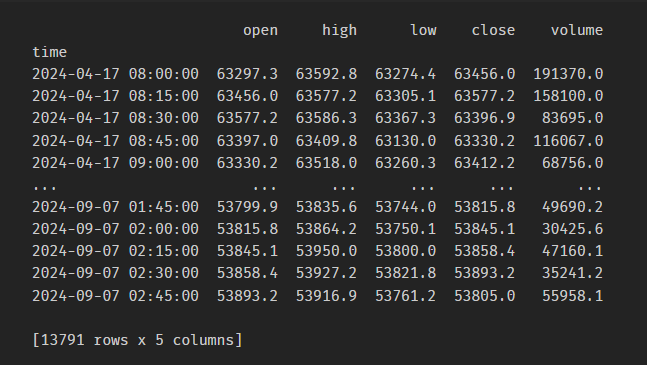
- 基本特征构造:基于处理后的数据,计算一系列基础技术指标,如不同周期的收益率、简单移动平均线(SMA)、指数移动平均线(EMA)以及极值差额平滑等,作为模型的初始特征池。
feature_columns = ['open', 'high', 'low', 'close', 'volume']
df[feature_columns] = df[feature_columns].astype(float)
for column in feature_columns:
for period in [1, 6, 12, 24, 48, 96]:
# 涨跌幅
df[f'{column}_{period}_return'] = df[column].pct_change(period)
if period >= 6:
# 简单移动平均线
df[f'{column}_{period}_sma'] = talib.SMA(df[column], timeperiod=period)
# 指数移动平均线
df[f'{column}_{period}_ema'] = talib.EMA(df[column], timeperiod=period)
# 极值差额平滑
df[f'{column}_{period}_maxin_range'] = uniform_filter1d(df[column].rolling(window=period).apply(lambda x: x.max() - x.min()).fillna(0), size=period)
df['target'] = (df['close'].shift(-target_shift) - df['close']) / df['close']
- 衍生特征生成:借鉴基因编程的思想,通过预设一组数学运算符(加、减、乘、除、对数、指数、三角函数等),自动组合生成大量候选特征公式。这个过程模拟了自然界“进化”的机制,旨在寻找最能刻画数据内在结构的数学表达式。
gplearn 库使用指定的数学运算集合(function_set)和原始特征来生成新的衍生特征,其核心规则包括:
-
操作符集(function_set)
包括基本算术操作(add, sub, mul, div)、数学函数(sqrt, log, abs, neg, inv, max, min)和三角函数(sin, cos, tan)。这些操作符用于构建复杂的数学表达式。
-
树形结构
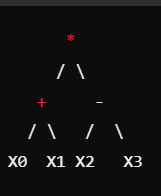
在遗传算法中,每个数学公式被表示为一棵树。根节点是操作符,子节点是输入特征或其他操作符。
例如,表达式 (X0 + X1) * (X2 - X3) 可以表示为以下树形结构:
- 适应度函数
每个衍生特征的生成都伴随着适应度评估,gplearn 根据回归任务的目标值(如最小化均方误差MSE)来评估每个特征公式的效果。适应度高的公式被保留并用于下一代进化。
使用 gplearn 构建衍生特征的核心代码如下:
# 使用 gplearn 构建衍生特征
function_set = ['add', 'sub', 'mul', 'div', 'sqrt', 'log', 'abs', 'neg', 'inv', 'max', 'min', 'sin', 'cos', 'tan']
gp = SymbolicTransformer(generations=50, population_size=5000,
hall_of_fame=200, n_components=20,
function_set=function_set,
parsimony_coefficient=0.01,
max_samples=0.9, random_state=0, n_jobs=-1)
gp.fit(extended_features, y)
X_gp = gp.transform(extended_features)
# 获取并过滤衍生特征公式
gp_formulas = [program for program in gp._programs[0] if program is not None]
这段代码利用 gplearn 库的 SymbolicTransformer 进行符号回归,通过遗传算法从数据中自动挖掘有用的特征组合。关键参数如进化代数(generations)、种群大小(population_size)、保留最优解数量(hall_of_fame)和复杂度惩罚(parsimony_coefficient)共同控制着特征搜索的广度、深度与简洁性。
- 特征筛选与合并:自动生成的衍生特征可能存在过高的复杂性或冗余,因此需要通过设定复杂度限制进行初步筛选,并将有效的衍生特征与基本特征合并,构建一个信息密度更高、维度更丰富的特征集合。最终得到的部分衍生特征公式示例如下:
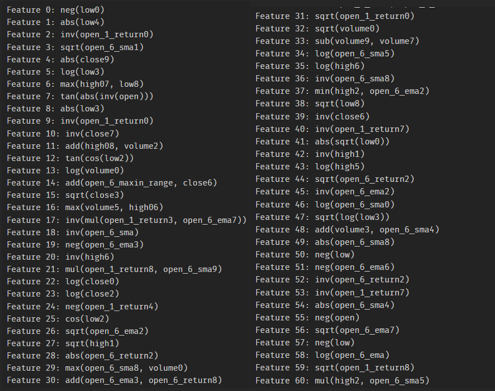
3.2 遗传算法因子挖掘
遗传算法是一种模拟生物进化过程的全局优化算法,其核心思想包括:
- 个体编码:将每个特征子集(即一个因子组合)编码为一个二进制串个体。
- 适应度函数:用于评价个体的优劣,例如使用线性模型在测试集上的R²分数。
- 选择、交叉与变异:模拟自然选择、基因重组和基因突变,通过迭代进化寻找最优特征组合。
以下是通过 deap 库实现遗传算法进行因子挖掘的核心函数:
def genetic_algorithm_factor_mining(df, X_all, y, gp_formulas):
# 定义适应度函数
def evaluate(individual):
selected_features = [i for i, bit in enumerate(individual) if bit == 1]
if len(selected_features) == 0:
return -np.inf,
X_selected = X_all[:, selected_features]
X_train, X_test, y_train, y_test = train_test_split(X_selected, y, test_size=0.2, random_state=42)
model = LinearRegression()
model.fit(X_train, y_train)
return model.score(X_test, y_test),
# 初始化遗传算法工具箱
creator.create("FitnessMax", base.Fitness, weights=(1.0,))
creator.create("Individual", list, fitness=creator.FitnessMax)
toolbox = base.Toolbox()
toolbox.register("attr_bool", np.random.randint, 0, 2)
toolbox.register("individual", tools.initRepeat, creator.Individual, toolbox.attr_bool, n=len(X_all[0]))
toolbox.register("population", tools.initRepeat, list, toolbox.individual)
toolbox.register("evaluate", evaluate)
toolbox.register("mate", tools.cxTwoPoint)
toolbox.register("mutate", tools.mutFlipBit, indpb=0.05)
toolbox.register("select", tools.selTournament, tournsize=3)
# 设置遗传算法参数
population = toolbox.population(n=300)
n_generations = 40
crossover_prob = 0.7
mutation_prob = 0.2
# 运行遗传算法
algorithms.eaSimple(population, toolbox, cxpb=crossover_prob, mutpb=mutation_prob, ngen=n_generations, verbose=False)
# 获取最优个体
best_individual = tools.selBest(population, k=1)[0]
selected_features = [i for i, bit in enumerate(best_individual) if bit == 1]
return selected_features
该函数主要步骤为:定义基于模型预测性能的适应度函数 -> 初始化种群及遗传操作(选择、交叉、变异)-> 迭代进化 -> 输出最优特征索引。经过遗传算法挖掘后,得到的最优特征组合及其对应的原始因子名称示例如下:
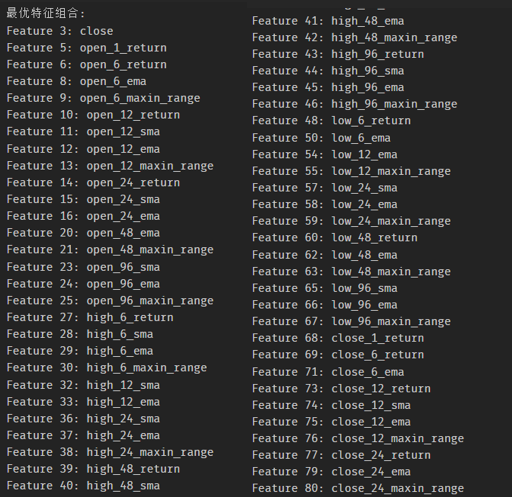

3.3 LSTM 模型训练与预测
LSTM(长短期记忆网络)是一种特殊的循环神经网络,通过门控机制(输入门、遗忘门、输出门)有效捕捉时序数据中的长期依赖关系,解决了传统RNN的梯度消失问题,非常适用于金融时间序列的收益率预测。
以下是使用 PyTorch 定义和训练 LSTM 模型的核心代码:
# 定义 LSTM 模型类
class LSTMModel(nn.Module):
def __init__(self, input_size, hidden_size, output_size):
super(LSTMModel, self).__init__()
self.hidden_size = hidden_size
self.lstm = nn.LSTM(input_size, hidden_size, batch_first=True)
self.fc = nn.Linear(hidden_size, output_size)
def forward(self, x):
lstm_out, _ = self.lstm(x)
output = self.fc(lstm_out[:, -1, :]) # 只使用最后一个时间步的输出
return output
# 训练 LSTM 模型的函数
def train_lstm_model(X_train, y_train, hidden_size=50, num_epochs=100, learning_rate=0.001):
input_size = X_train.shape[2]
output_size = 1
model = LSTMModel(input_size, hidden_size, output_size)
criterion = nn.MSELoss()
optimizer = optim.Adam(model.parameters(), lr=learning_rate)
for epoch in range(num_epochs):
optimizer.zero_grad()
outputs = model(X_train)
loss = criterion(outputs, y_train)
loss.backward()
optimizer.step()
if (epoch+1) % 10 == 0:
print(f'Epoch [{epoch+1}/{num_epochs}], Loss: {loss.item():.4f}')
return model
# 预测 LSTM 模型的函数
def predict_lstm_model(model, X):
model.eval()
with torch.no_grad():
outputs = model(X)
return outputs.numpy()
# 修改后的 evaluate_factors 函数,集成了 LSTM 模型的训练和预测
def LSTM_evaluate_factors(df, target_shift=16):
# 准备数据和构建特征
df, X_all, y, gp_formulas = prepare_and_construct_features(df, target_shift=target_shift)
print("数据和构建特征完成")
# 使用遗传算法进行因子挖掘
selected_features = genetic_algorithm_factor_mining(df, X_all, y, gp_formulas)
print("最优特征组合:", selected_features)
# 打印具体的因子名称
feature_names = ['open', 'high', 'low', 'close', 'volume'] + [f'gp_{i}' for i in range(X_all.shape[1] - len(['open', 'high', 'low', 'close', 'volume']))]
selected_feature_names = [feature_names[i] for i in selected_features]
print("选择的具体因子:", selected_feature_names)
# 构建包含最优特征的训练集和测试集
X_selected = X_all[:, selected_features]
train_size = int(len(df) * 0.8)
X_train, X_test = X_selected[:train_size], X_selected[train_size:]
y_train, y_test = y[:train_size], y[train_size:]
# 归一化
scaler_X = StandardScaler()
X_train = scaler_X.fit_transform(X_train)
X_test = scaler_X.transform(X_test)
scaler_y = StandardScaler()
y_train = scaler_y.fit_transform(y_train.values.reshape(-1, 1))
y_test = scaler_y.transform(y_test.values.reshape(-1, 1))
# 将数据转换为适合 LSTM 的形状
X_train = torch.tensor(X_train, dtype=torch.float32).view(-1, 1, X_train.shape[1])
X_test = torch.tensor(X_test, dtype=torch.float32).view(-1, 1, X_test.shape[1])
y_train = torch.tensor(y_train, dtype=torch.float32).view(-1, 1)
y_test = torch.tensor(y_test, dtype=torch.float32).view(-1, 1)
print("数据准备工作完成,LSTM 模型开始训练:")
# 训练 LSTM 模型
lstm_model = train_lstm_model(X_train, y_train)
# 预测未来收益率
lstm_y_pred = predict_lstm_model(lstm_model, X_test)
lstm_y_pred = scaler_y.inverse_transform(lstm_y_pred)
# 计算策略收益
lstm_predicted_returns = pd.Series(lstm_y_pred.flatten(), index=df.index[train_size:])
lstm_df_test = df.iloc[train_size:].copy()
lstm_df_test['pos'] = np.where(lstm_predicted_returns > 0, 1, -1)
print("LSTM 模型训练完成,线性回归 模型开始训练:")
return lstm_df_test
实验与讨论
在实际应用中,我们将上述三个模块串联,对某标的的历史量价数据进行自动化处理:
- 数据准备与特征构造:获取历史数据,调用
prepare_and_construct_features 函数生成基础及衍生特征。
- 遗传算法因子挖掘:利用
genetic_algorithm_factor_mining 函数搜索最优特征子集。
- LSTM 模型预测:将最优特征输入
LSTM_evaluate_factors 函数训练模型,预测收益并计算策略表现。
实验结果显示,通过进化思想自动构造的因子能更有效地捕捉市场的非线性特征,LSTM模型的时序预测能力也优于传统线性模型,整套流程为量化策略研发提供了高度自动化且有效的新思路。下图为模型训练过程中的损失曲线及策略收益表现:
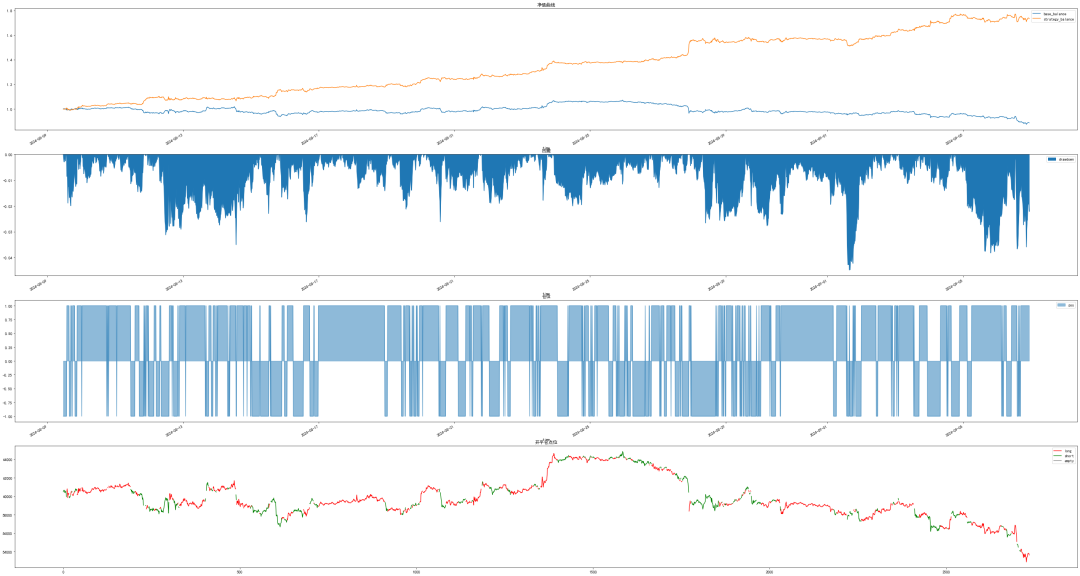
策略关键绩效指标(KPIs)如下:
| 指标 |
变量名 |
数值 |
| 最大回撤 |
MaxDrawDown |
-4.48% |
| 收益率 |
return |
73.48% |
| 年化收益率 |
yearReturn |
957.8587% |
| 收益/最大回撤比率 |
return/maxdrawdown |
16.3843 |
| 夏普比率 |
sharpe_ratio |
1.0733 |
风险提示:在任何情况下,本报告中的信息或所表述的意见均不构成对任何人的投资建议。
参考资料
- Mitchell, M. (1996). An Introduction to Genetic Algorithms. MIT Press.
- gplearn 库官方文档:https://gplearn.readthedocs.io/
- Hochreiter, S. & Schmidhuber, J. (1997). Long Short-Term Memory. Neural Computation, 9(8), 1735-1780.
希望这篇关于利用遗传算法和LSTM进行自动化因子挖掘的实践分享,能为你构建量化交易模型提供新的启发。如果你对Python在量化金融或机器学习中的应用有更多兴趣,欢迎到云栈社区与更多开发者交流探讨。
 发表于 2026-4-8 05:36:31
|
查看: 183|
回复: 0
发表于 2026-4-8 05:36:31
|
查看: 183|
回复: 0
