Google 前不久发布的 Gemma 4 E4B-it 是一款支持文字、图片、音频三模态的开源模型,有效参数 4.5B。理论上,RTX 4060 的 8GB 显存配合 4-bit 量化就能跑起来。
听起来很简单,对吧?我花了一整天才把它跑顺。两条主流路线都走了一遍——HuggingFace Transformers 和 llama.cpp——前后一共踩了 8 个典型的坑。这篇文章把每个坑的报错、根因和解决方案都完整记录下来,你照着做可以避开所有弯路。
先贴一下测试环境配置:
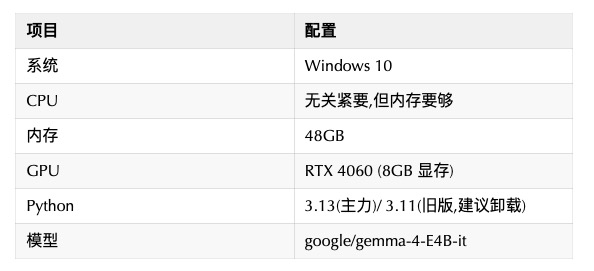
两种部署路线的核心对比在文末,咱们先把坑讲透。
这条路使用原始的 SafeTensors 权重,配合 bitsandbytes 做 4-bit 量化,适合后续进行微调和研究。但需要留意的坑比 llama.cpp 要多。
坑 1:不量化裸跑,Windows 页面文件直接爆了
一开始想法很单纯:模型原生精度是 bfloat16,总共 16GB,我 48GB 物理内存绰绰有余,让 accelerate 自动把放不下的层 offload 到 CPU 不就行了?
model = AutoModelForImageTextToText.from_pretrained(
MODEL_PATH,
torch_dtype=torch.bfloat16,
device_map="auto",
)
accelerate 确实开始尝试 offload 了,但在用 safetensors 做内存映射打开那 16GB 权重文件时,程序直接崩溃了:
OSError: [WinError 1455] 页面文件太小,无法完成操作 (os error 1455)
原因:Windows 系统默认的虚拟内存(页面文件)通常只有 4GB 左右,要内存映射一个 16GB 的大文件根本不够用。
解法:需要双管齐下。
第一,把 Windows 页面文件大小从默认的 4GB 调整到 16-32GB(可以搜索“Windows 调整页面文件大小”,跟着系统设置操作,需要重启生效)。也可以用 PowerShell 快速设置:
$pf = Get-CimInstance -ClassName Win32_PageFileSetting -Filter "Name='C:\\pagefile.sys'"
$pf | Set-CimInstance -Property @{InitialSize=16384; MaximumSize=32768}
第二,也是最根本的,别再尝试裸跑 bfloat16 精度,直接上 4-bit 量化:
from transformers import BitsAndBytesConfig
quantization_config = BitsAndBytesConfig(
load_in_4bit=True,
bnb_4bit_quant_type="nf4",
bnb_4bit_compute_dtype=torch.bfloat16,
)
这样一来,模型大小会从 16GB 压缩到大约 5GB,显存立刻变得够用。
坑 2:加载 4 分半钟,最后被自己的 print 语句搞崩了
加上量化配置后,模型终于开始加载了。等了足足 4 分 29 秒,进度条走完,然后——程序又崩了。
AttributeError: 'Gemma4ForConditionalGeneration' object has no attribute 'hf_device_map'
错误堆栈只有两层:我的 print 调用,和 PyTorch 底层的 nn.Module.__getattr__ 兜底实现。模型其实已经加载完成了,是我自己的打印语句把它“弄崩”的。
原因:在新版 transformers 中,hf_device_map 这个属性并非一直存在,它只在真正触发多设备分派(比如跨 GPU-CPU offload)时才会被挂载到模型对象上。这次虽然量化了,但 accelerate 可能没有生成这个属性,直接访问就抛出了 AttributeError。
解法:使用 getattr 进行安全访问,并用统计模型参数分布的方式作为备用方案。
from collections import Counter
device_map = getattr(model, "hf_device_map", None)
if device_map:
print(f"设备分布: {device_map}")
else:
devices = Counter(str(p.device) for p in model.parameters())
print(f"参数设备统计: {dict(devices)}")
坑 3:配好了 4-bit 量化,结果模型全跑在 CPU 上
这是整个过程里最离谱的一个坑。
修复了坑 2 之后,脚本能跑通了,参数分布也打印了出来,结果却是:
参数设备统计: {'cpu': 1160}
1160 个参数张量,全部在 CPU 上,一个都没加载到 GPU。
接着我尝试运行推理,等了 30 秒毫无动静,只能 Ctrl+C 中断。
原因:当使用 device_map="auto" 将决策权交给 accelerate 时,它对 offload buffer 的计算非常保守。启动时其实打印过一条警告:
Current model requires 6192 bytes of buffer for offloaded layers, which seems does not fit any GPU's remaining memory.
accelerate 自己都在报警,但它不会主动推翻 auto 模式下的决策——它觉得显存“不够”,就直接放弃使用 GPU,把整个模型都甩给了 CPU。
解法:强制指定 device_map,不再让 auto 模式做决策。
# ❌ auto 模式可能把整个模型都丢给 CPU
device_map="auto"
# ✅ 强制将所有模块放到 GPU 0 上
device_map={"": 0}
修改之后重新运行,加载时间从 4 分 29 秒骤降到 14 秒,参数分布变成了:
参数设备统计: {'cuda:0': 1160}
加载速度提升了约 19 倍。这才是 4-bit 量化模型应有的表现。
坑 4:多模态 processor 要求 content 必须是列表
修复了 device_map 问题,跑第一个测试时,又出错了:
TypeError: string indices must be integers, not ‘str'
错误堆栈指向 processor.apply_chat_template 这一行。
原因:新版 transformers 中,为多模态模型设计的 processor 要求消息字典里的 content 字段必须是列表结构,不再接受简单的字符串。这是为了适配多模态输入(比如同时传入图片和文字)。
解法:修改消息的格式。
# ❌ 旧格式(纯文本模型可用,多模态模型不行)
{"role": "user", "content": "你好"}
# ✅ 新格式(多模态 processor 要求)
{"role": "user", "content": [{"type": "text", "text": "你好"}]}
如果需要输入图片,格式如下:
{"role": "user", "content": [
{"type": "image", "image": image_obj},
{"type": "text", "text": "描述这张图"}
]}
改完后,Transformers 这条路线终于全线跑通。完整可用的脚本在文末的附录中。
路线 B:llama.cpp
llama.cpp 路线使用 GGUF 量化模型(例如 Q4_K_M,约 4.9GB),命令行比 Transformers 简单得多。但它有自己独特的坑——不是代码层面的,而是对话模板(chat template)层面的。
坑 5:使用 --chat-template gemma 输出火星文
官方文档和大部分教程都会这么写命令:
llama-cli.exe -m “gemma-4-E4B-it-Q4_K_M.gguf” -ngl 99 -c 4096 --chat-template gemma
启动正常,加载成功。输入“你好,请用中文介绍一下你自己”后,模型开始输出:
gggggemmaggggemmaggsettingsgsettingsgsettingsgsettings...
满屏的“gemmagsettings”,并且以 6.9 tokens/s 的速度“认真”地停不下来。
原因:--chat-template gemma 这个参数对应的是 Gemma 1/2 的旧对话格式,与 Gemma 4 的 chat template 完全不匹配。特殊 token 被错误地拼接,导致模型输出乱码。
坑 6:换成 --chat-template gemma3 也不行
我以为换成 gemma3 模板就对了:
llama-cli.exe … --chat-template gemma3
输出依然是乱码,只是从 gemmagsettings 变成了 gemma3gemma-gemma-。
原因:当前版本的 llama.cpp(测试版本为 build b8660)内置的模板库里,根本没有适配 Gemma 4 的模板。所以你指定任何名称都是错的。
坑 7:正确解法是使用 -cnv 参数
真正的解法是:不要指定 --chat-template,转而使用 -cnv 参数,让 llama.cpp 从 GGUF 文件内部的元数据(metadata)里读取模型自带的原厂 chat template。
llama-cli.exe `
-m “E:\meihong\llma\models\gemma-4-E4B-it-Q4_K_M.gguf” `
-ngl 99 `
-c 4096 `
-cnv
GGUF 文件里其实封装了正确的 Jinja 模板,只是 llama.cpp 的命令行默认不会自动启用它。加上 -cnv(conversation mode)参数后,它会优先读取 GGUF 文件内置的模板,输出立刻恢复正常。
启动兼容 OpenAI 格式的 API 服务器时同理:
llama-server.exe `
-m “E:\meihong\llma\models\gemma-4-E4B-it-Q4_K_M.gguf” `
-ngl 99 `
-c 4096 `
--port 8080
同样,不要加 --chat-template gemma 参数。
坑 8:hf-mirror 镜像对 XetHub 存储无效
这个坑严格来说是在部署之前就踩到的——发生在下载模型的时候。
正常思路:国内访问 HuggingFace 慢,设个镜像环境变量就好了。
$env:HF_ENDPOINT = “https://hf-mirror.com”
hf download google/gemma-4-E4B-it --local-dir E:\meihong\hf_cache\gemma-4-E4B-it
结果下载了一会儿就开始反复超时。抓包发现,实际流量根本没走镜像,而是在请求 cas-bridge.xethub.hf.co——这是 HuggingFace 新采用的 XetHub CAS 存储,服务器在美国,普通镜像无法代理。
原因:HuggingFace 正在逐步把大模型文件迁移到 XetHub 存储系统。环境变量里的 HF_ENDPOINT 只影响 API 元数据的请求,不影响实际通过 XetHub 协议的文件下载。
解法:强制禁用 XetHub,让下载回退到传统的 Git LFS 方式(这样镜像才能生效)。
$env:HF_ENDPOINT = “https://hf-mirror.com”
$env:HF_HUB_DISABLE_XET = “1”
$env:HF_HUB_ENABLE_HF_TRANSFER = “0”
hf download google/gemma-4-E4B-it --local-dir E:\meihong\hf_cache\gemma-4-E4B-it
即使这样,下载 16GB 的模型仍然可能反复超时。我最后写了一个自动重试的 PowerShell 脚本,重试了 17 次才下载完成:
# download_gemma4.ps1
$env:HF_ENDPOINT = “https://hf-mirror.com”
$env:HF_HUB_DISABLE_XET = “1”
$retry = 0
while ($retry -lt 50) {
$retry++
Write-Host “--- Attempt $retry ---“
& hf.exe download google/gemma-4-E4B-it `
--local-dir E:\meihong\hf_cache\gemma-4-E4B-it --max-workers 1
if ($LASTEXITCODE -eq 0) { Write-Host “Done!”; break }
Start-Sleep -Seconds 5
}
hf download 命令自带断点续传功能,中断后再启动会从上次位置继续,所以反复重试不会浪费已下载的流量。
两种部署方式对比
8 个坑全部解决后,两条路线都能稳定运行。日常该如何选择?
| 维度 |
Transformers |
llama.cpp |
| 模型格式 |
SafeTensors (16GB 原始) |
GGUF Q4_K_M (约 4.9GB) |
| 加载时间 |
14 秒 (修复后) |
秒级 |
| 生成速度 |
不稳定,取决于具体配置 |
稳定在 6.9 tok/s 左右 |
| 显存占用 |
~5GB |
~4.7GB |
| 输出质量 |
原生精度 (经4-bit量化) |
Q4_K_M 量化精度 |
| 启动命令复杂度 |
高 (需编写Python脚本) |
低 (一行命令) |
| 多模态输入 |
原生支持 (图片+文字) |
需要特定分支 (如llama-gemma3-cli) |
| 微调/训练 |
支持 |
不支持 |
| 踩坑数量 |
4 个 |
3 个 (+ 1 个下载) |
结论:
- 如果要日常使用(聊天、本地 API 服务、小工具集成),推荐选择 llama.cpp。命令简单,速度稳定,显存占用低。唯一要牢记的就是使用
-cnv 参数,而不是 --chat-template gemma。
- 如果要进行研究、微调或集成到现有 Python 项目中,才使用 Transformers。但必须做好心理准备,
device_map、量化配置、消息格式,每一个环节都可能出问题。
附录:完整可用脚本
import os
os.environ[“SAFETENSORS_FAST_GPU”] = “0”
from collections import Counter
import torch
from transformers import (
AutoProcessor,
AutoModelForImageTextToText,
BitsAndBytesConfig,
)
MODEL_PATH = r“E:\meihong\hf_cache\gemma-4-E4B-it”
MAX_NEW_TOKENS = 512
# 4-bit 量化配置
quantization_config = BitsAndBytesConfig(
load_in_4bit=True,
bnb_4bit_quant_type=“nf4”,
bnb_4bit_compute_dtype=torch.bfloat16,
)
print(“正在加载 Processor...”)
processor = AutoProcessor.from_pretrained(MODEL_PATH)
print(“正在加载模型 (4-bit 量化)...”)
model = AutoModelForImageTextToText.from_pretrained(
MODEL_PATH,
quantization_config=quantization_config,
device_map={“”: 0}, # ← 关键:强制使用 GPU 0,不要用 auto
low_cpu_mem_usage=True,
)
model.eval()
# 参数分布统计 (用于兜底 hf_device_map 不存在的情况)
devices = Counter(str(p.device) for p in model.parameters())
print(f“参数设备统计: {dict(devices)}”)
def chat(messages, temperature=0.7, top_p=0.9):
inputs = processor.apply_chat_template(
messages,
add_generation_prompt=True,
tokenize=True,
return_tensors=“pt”,
return_dict=True,
).to(model.device)
with torch.no_grad():
outputs = model.generate(
**inputs,
max_new_tokens=MAX_NEW_TOKENS,
do_sample=True,
temperature=temperature,
top_p=top_p,
)
response = processor.decode(
outputs[0][inputs[“input_ids”].shape[-1]:],
skip_special_tokens=True,
)
if torch.cuda.is_available():
torch.cuda.empty_cache()
return response
# 注意:content 必须是列表格式
messages = [
{“role”: “user”, “content”: [
{“type”: “text”, “text”: “你好,请用中文介绍一下你自己。”}
]}
]
print(chat(messages))
llama.cpp 最终命令
# 交互式聊天
E:\meihong\llma\llama-cpp\llama-cli.exe `
-m “E:\meihong\llma\models\gemma-4-E4B-it-Q4_K_M.gguf” `
-ngl 99 -c 4096 -cnv
# OpenAI 兼容 API 服务
E:\meihong\llma\llama-cpp\llama-server.exe `
-m “E:\meihong\llma\models\gemma-4-E4B-it-Q4_K_M.gguf” `
-ngl 99 -c 4096 --port 8080
8 坑速查表
| # |
坑描述 |
解法 |
| 1 |
不量化裸跑,Windows页面文件OOM |
启用4-bit量化 + 调大Windows页面文件 |
| 2 |
hf_device_map属性不存在报错 |
用getattr安全访问,或统计参数分布 |
| 3 |
4-bit量化后模型仍全跑在CPU |
使用device_map={“”: 0}强制指定GPU |
| 4 |
chat_template的content字段不能用字符串 |
改为[{“type”:”text”,”text”:...}]列表格式 |
| 5 |
--chat-template gemma输出乱码 |
不要使用此参数 |
| 6 |
--chat-template gemma3也输出乱码 |
不要使用此参数 |
| 7 |
正确启用对话模式 |
使用 -cnv 参数让GGUF提供自身模板 |
| 8 |
HF镜像对XetHub存储无效,下载超时 |
设置HF_HUB_DISABLE_XET=1禁用XetHub,并编写重试脚本 |
Gemma 4 本身是一个能力很强的模型——逻辑推理、代码生成、中文表现在 4.5B 参数级别中都属于顶配,还自带“思考模式”这样的有趣特性。
但从“拥有模型文件”到“能够稳定使用”,中间往往隔着许多像这样的实践坑。希望这篇在云栈社区分享的详细踩坑记录,能帮你节省大量摸索时间。如果你在部署其他开源实战项目时也遇到了棘手问题,不妨来社区一起探讨。
本文所有命令和代码均在 RTX 4060 + Windows 10 + Python 3.13 环境下实测通过。
 发表于 2026-4-8 06:27:04
|
查看: 708|
回复: 0
发表于 2026-4-8 06:27:04
|
查看: 708|
回复: 0
