从3月底开始,我一直关注着“Harness”(智能体“外脑”系统)这条技术线。可能有人觉得这个话题快成老生常谈了,但最新的变化值得我们再深入一步。
最早是翻看OpenAI的Codex仓库,写下了关于其工程经验沉淀的观察。后来研读Anthropic那篇关于长任务处理的长文,重点分析了其 planner / generator / evaluator 的分工模式和 sprint contract 这种将完成标准系统化的做法。接着,又顺着Claude Code的 query.ts 和 SessionMemory 等源码一路追溯,理解了其如何将压缩、记忆、续写等能力做成运行时(runtime)。直到前两天整理了关于《Coding Agent的6个关键模块》的内容,这些分散的认知才重新整合到一张总图里。
这么多内容下来,其实都在回答同一个方向的核心问题:模型已经如此强大,它外部的那套系统还缺什么?
之前的答案一直是“继续补”。但读完Anthropic前几天发布的 Harnessing Claude‘s Intelligence 一文,思路豁然开朗。这不是方向变了,而是补上了我们思考的另一半。
新文章不再主要讲如何往上加东西,它开始正面追问一个之前很少被深入探讨的问题:What can I stop doing?(我该停止做什么?)
前一篇文章讲的是:当模型自己还扛不住时,系统该补什么(planner, evaluator, context reset, sprint contract 等,全是在替模型兜底)。
后面这篇新文讲的是:当模型已经跨过某些能力门槛后,系统终于可以少做什么。编排、上下文管理、记忆选择,哪些控制权可以慢慢交还给模型。
如果只看新文本身,它像是在讲三个关键模式。但将两篇连起来读,Anthropic其实在传达一个更大的工程判断:Harness 不是只管往上加组件的。该补的时候要果断补,该删的时候也必须敢于删。
这很可能意味着:Anthropic 的 Harness 框架设计,已经进入了一个新的阶段。
核心观点速览
- 将Anthropic前后两篇关于Harness的文章对照来看,会发现一条清晰的变化主线:先补短板,再删 dead weight(无用负担)。
- 新文真正的主问题只有一句灵魂拷问:
What can I stop doing?
- 三个关键模式落到工程实践中,可归纳为:先用Claude已经会的东西、把局部控制权交还给模型、把真正承重的边界留在Harness。
- 这与我们从《Codex为什么能又快又稳》到《Coding Agent的6个关键模块》这条文章线的思路一脉相承:先看怎么补缺,再看如何将治理写进runtime,到现在开始审视哪些工作终于可以少做一点了。
- 真正该慢慢交还给模型的,至少有三类控制权:编排权、上下文管理权、记忆选择权。
- 真正不该轻易交还给模型的,也至少有三类边界:缓存与成本边界、安全与确认边界、可观测性边界。
- 背后真正有价值的不是那三个模式本身,而是一种工程节奏:每次模型能力升级后,都做一次“dead weight inventory”(无用负担盘点)。
两篇文章对比:从“补”到“删”的清晰脉络
前一篇《Harness design for long-running application development》,Anthropic主要解决的是两个具体问题:
- 长任务为什么会越跑越偏?
- 模型为什么总是对自己的结果过于宽容?
所以那篇文章里的关键词是 planner / generator / evaluator、context reset、sprint contract、structured handoff。说得直接点,它更像在回答:当模型自己还扛不住时,系统该补什么。
到了《Harnessing Claude’s Intelligence》,重心明显向另一边转移。新文不再主要讨论如何把框架搭得更厚,而是开始问:
- 编排是否还必须由Harness完全接管?
- 上下文是否还需要大段的预加载?
- 记忆是否一定要先做成模型外的一套检索基础设施?
换句话说,它开始回答的是:当模型已经跨过某些能力门槛时,系统终于可以少做什么。
把这层差别可视化,思路会更清晰:
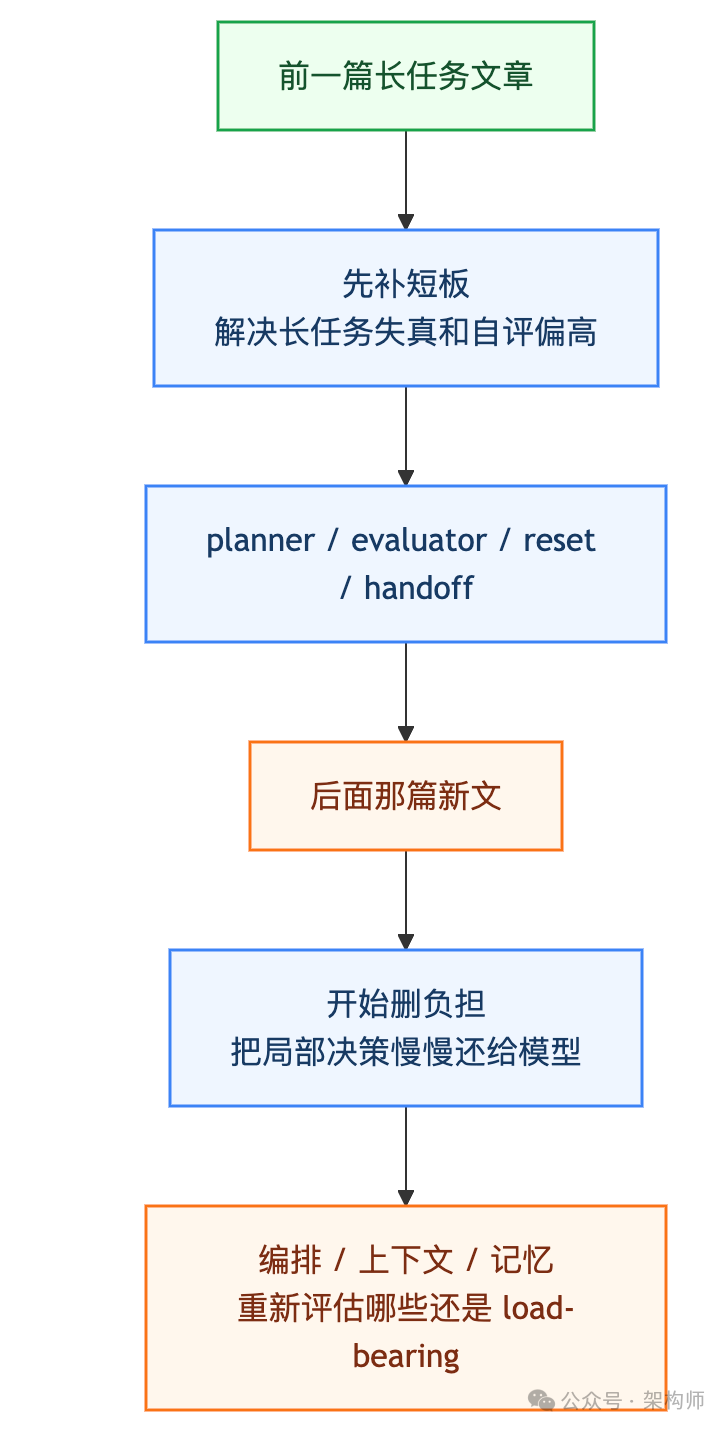
所以,这里并非观点反转,而是前后两篇连起来,Anthropic才把自己的完整意图讲清楚了:该补的时候要补。该删的时候也得删。
Anthropic在原文中举了一个典型例子。他们之前做长任务Agent时,Sonnet 4.5模型会在感知到上下文快到上限时提前“收工”,表现出一种 context anxiety(上下文焦虑)。于是,团队增加了context reset机制,主动清空上下文、重启会话,避免模型草草交卷。
但到了Opus 4.5,这个“焦虑”行为消失了。于是,原来那套用于补偿模型短板的reset机制,就不再是“护栏”,而开始变成“dead weight”(无用负担)。
这句话至关重要:很多Harness组件之所以存在,不是因为它们永远正确,而是因为它们曾经刚好填上了某一代模型的能力缺口。 一旦缺口消失,组件就该被重新评估。
笔者认为,这里真正值钱的不是那几个模式本身,而是它背后揭示的工程节奏:
- 先承认模型有边界。
- 用Harness把边界外移,变成系统能力。
- 每次模型升级后,重新检查哪些控制逻辑仍在“承重”。
- 能删的就删,不要让旧补丁反过来卡住新模型的能力。
模式一:优先利用Claude已掌握的能力
新文开篇仍从 bash 和 text editor 讲起,这与一个反复被验证的判断高度一致:好的AI Agent系统,不是先发明一堆花哨组件,而是先把模型已经熟悉的能力接入真实工作流。
这次原文把这件事讲得更透彻:不要太早替模型定义“正确的工具形态”,先看看它已经擅长使用什么。
回顾一下这条技术线:2024年底,Claude 3.5 Sonnet仅凭 bash 和 text editor 两个工具就在SWE-bench Verified基准上取得了49%的成绩(当时的SOTA);到了Opus 4.5,同样两个工具做到了80.9%。Claude Code也是基于它们构建的。Bash并非为Agent设计,但它是Claude训练数据里大量出现的东西,每一代模型都在变得更善于使用它。
在Anthropic的叙述中,很多今天看起来像独立能力的东西,本质上都是从这两个通用基础工具“长”出来的:
programmatic tool calling(编程式工具调用)Skills(技能系统)memory(记忆工具)
它们并非与基础工具平行的“新发明”,更像是 bash + text editor 上逐步演化出的组合模式。

这里最值得研究的不是“以后都别做专用工具”,而是另一句更实用的工程建议:如果一个问题可以先用Claude已经熟悉的通用工具解决,就别急着把它过早固化成框架逻辑。
过早专用化的问题在于,你很可能在替模型做决策。而模型的能力一旦继续上涨,那些你提前写死的分工、过滤和流程,迟早会过时。
将这层关系总结成一个简单的决策表会更清晰:
| 形态 |
更适合解决什么 |
什么时候优先用 |
通用工具,如 bash、文本编辑器 |
开放式探索、局部编排、临时组合 |
问题形态还在变化,或者模型已经很会做 |
| 声明式专用工具 |
安全门禁、结构化参数、用户交互、审计回放 |
动作高风险、难回滚、必须可追踪 |
也就是说,Anthropic并非在说“专用工具不重要”。它是在强调一个优先级顺序:先把通用能力吃透,再决定哪些地方真的值得升格成必须由系统接管的边界。
模式二:将三类控制权逐步交还模型
文章最具信息量的部分在第二条原则:Ask what can I stop doing?。将其翻译成更工程化的语言,其实就是:Harness里很多默认接管的行为,今天已经值得重新检查,看它们是否还应由框架全权负责。
具体来看,刚好涉及三类控制权。
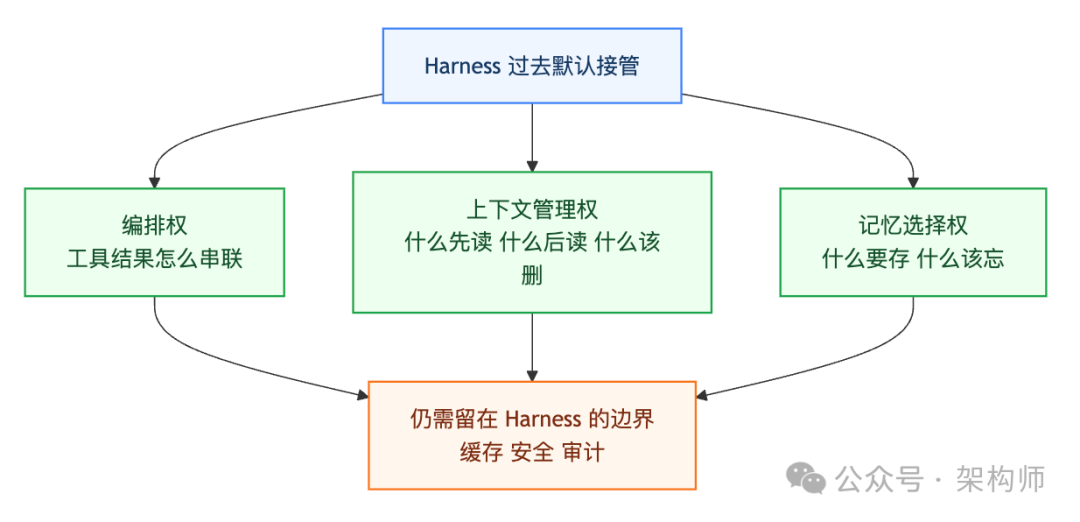
1. 编排权:不必全攥在Harness手里
很多系统默认认为:每次工具调用的结果,都要回到模型上下文里,再由模型决定下一步。这个假设的问题是,它又慢又贵,而且很多时候没必要。
如果Claude只是想从一张大表里查看某一列,你却把整张表都塞回上下文,那你实际上在为模型根本不关心的那部分数据支付token成本。
Anthropic的解法不是继续在工具层硬编码过滤器,而是直接把一部分编排权交还给Claude:
- 赋予它
bash 或 REPL这类代码执行能力。
- 让它自己编写代码去串联工具调用。
- 中间结果在代码内部处理。
- 只有真正需要的最终输出才回到上下文。
这背后是一个关键判断:很多所谓“工具编排”,本质上不是Harness必须接管的系统职责,而是Claude自己就更适合做的局部决策。
原文给出的数据很直接。在BrowseComp基准测试上,让Opus 4.6具备自己过滤工具输出的能力后,准确率从 45.3% 提升到了 61.6%。这不是小修小补,它说明一部分编排权从Harness转回模型后,系统整体性能反而更强。
2. 上下文管理权:也不该全靠预加载
另一个常见的默认动作是:把大量任务指令提前写进system prompt。问题很明显:任务越多,预加载越重;预加载越重,模型处理核心任务的注意力预算就越紧张。而且很多说明在当前任务里根本用不到。
Anthropic给出的答案是我们已经很熟悉的 Skills 机制。不是把所有细节都提前塞给模型,而是只预加载简短描述,让Claude自己按需展开。原文将这个机制明确称为 progressive disclosure(渐进式披露):先给目录,需要时再读全文。
同一思路下,context editing 和 subagents 也能纳入理解:
context editing 负责删掉过时的上下文,如旧的工具返回结果、早期的thinking blocks。subagents 负责在必要时开启一个更干净的上下文窗口,把子任务隔离出去处理。
原文提到,Opus 4.6使用subagents后,在BrowseComp上比最佳单Agent结果又提升了 2.8%。
所以,现在越来越清楚:上下文管理不等于“塞得更满”,而是让模型逐步学会自己决定该看什么、该丢什么、什么时候该分叉处理。
3. 记忆选择权:从外部基础设施回到模型判断
这部分与传统的“记忆即外部检索系统”做法形成对比。新文的重点是:先给模型足够简单的持久化手段,让它自己学会选择什么该被记住。
原文举了两条路径:compaction(压缩总结)和 memory folder(记忆文件夹)。
compaction 让Claude总结过去的上下文,以保持长任务的连续性。关键之处在于,同一套机制在不同模型上表现迥异:
- Sonnet 4.5在BrowseComp上基本卡在 43%
- Opus 4.5到了 68%
- Opus 4.6达到了 84%
这组数字说明了一个根本问题:很多时候,不是你的记忆机制本身不工作,而是模型终于变得更擅长决定“什么值得留下来了”。
memory folder 也是同理。它不是替模型做记忆选择,而是给模型一个可以写入、读取、回头整理的地方。原文给了一组数据:光是给Sonnet 4.5一个memory folder,其在BrowseComp-Plus上的准确率就从 60.4% 提升到了 67.2%。
文章里那个宝可梦游戏的例子更典型。Sonnet 3.5的记录更像流水账,NPC说了什么都记。而Opus 4.6则开始提炼战术笔记、失败经验和目录结构。这不是“存得更多”,而是“记得更像回事”。
模式三:能放权,不等于没有边界
如果只读到前面,很容易得出过度乐观的结论:Harness以后只要不断做减法就行了?并非如此。Anthropic的第三条原则恰好是在“收”:该退让的地方要退让,但该明确接管的边界,必须明确接管。
而且这里点得非常具体,几乎就是一张工程决策表:
| 边界类型 |
为什么必须留在Harness |
典型做法 |
| 成本边界 |
Messages API无状态,缓存命中率直接影响账单与延迟 |
静态内容前置、动态内容后置、断点更新、同一会话内少切换模型 |
| 安全边界 |
高风险动作不能只靠模型自觉 |
用户确认、staleness check(陈旧性检查)、权限门禁 |
| UX边界 |
有些动作需要以特定产品形态呈现给用户 |
弹窗、选项框、阻塞等待用户反馈 |
| 可观测性边界 |
生产系统需要可记录、可追踪、可回放 |
类型化工具、结构化参数、详细的日志与审计 |
成本边界
Messages API是无状态的,每一轮都需要重新打包历史对话。缓存命中率直接关系到成本和延迟。原文提醒了几条实用原则:
- 静态内容放前面,动态内容放后面。
- 更新尽量通过追加消息的方式,不要改动prompt本体。
- 同一会话内不要频繁切换模型。
- 工具列表的改动会影响缓存前缀。
- 多轮应用要持续更新断点(breakpoint)。
尤其是那句“缓存的token成本只有基础输入的10%”,足以说明:缓存命中率不是小优化,而是Harness该主动负责的预算纪律。
安全与UX边界
Anthropic给出了一个很认同的判断标准:reversibility(可逆性)。越难回滚的动作,越值得做成独立的声明式工具,而不是让它隐藏在一串 bash 命令里。
例如:
- 外部API调用,可能需要用户确认。
- 文件写入,最好附带staleness check,防止意外覆盖旧版本。
- 需要展示给用户的动作,最好做成能渲染成弹窗或选项框的专用工具。
这一点在Claude Code上看得很清楚。bash 很强大,但它给Harness的只有一串命令字符串。删除一个文件和调用一个外部API,Harness看到的“形状”没区别,但风险完全不同。而像 edit 这种声明式工具,才能让系统真正拿到结构化参数,从而进行审计、回放、拦截和权限控制。
原文还提到,Claude Code的auto-mode使用“第二个Claude”来审查bash命令的安全性。这种“用模型审查模型”的思路,在一定程度上减少了对专用工具的依赖——但它只适用于用户对操作大方向已经足够信任的场景。对于那些一步走错就难以回滚的动作,老老实实做成声明式工具仍然更稳妥。
可观测性边界
只要动作是通过类型化工具执行的,Harness就能记录参数、追踪链路、实现回放。这在Demo阶段常被低估,但系统一旦进入真实生产环境,它会变得越来越重要。不是因为“工具长得更高级”,而是因为你终于有了可审计的、结构化的动作“形状”。
所以,Anthropic的立场其实非常克制:它既没有说“把所有事都交给模型”,也没有说“继续堆砌更多框架外壳”。它做的是另一种更精细的职责划分:
- 在编排、上下文管理、记忆中,识别出哪些属于可以交还给模型的局部决策。
- 在成本、安全、UX、可观测性中,划定哪些是必须由Harness坚守的系统边界。
- 甚至连“是否要将某个功能做成专用工具”这个决策本身,也得跟随模型能力演进,持续进行重新评估。
对Agent开发者的五点自查建议
读到这里,真正有价值的可能不是记住那三个模式,而是回过头来检查你自己的系统。如果要为你的Harness做一次“体检”,或许可以从以下5个问题开始:
- 历史包袱识别:当前系统中有哪些流程或组件,其实只是为了补偿旧模型的能力短板而存在的?
- 过度接管检查:哪些工具过滤、任务编排、上下文拼装逻辑,已经在替模型做它本可以自己做出的决策?
- 专用工具评估:哪些专用工具是真正在安全、审计等边界上“承重”的?哪些可能只是历史上“先做出来了”,但今天带来的收益已不明显?
- 核心边界确认:哪些动作涉及安全、用户确认、审计追踪或回滚,必须继续牢牢留在Harness的控制面?
- 迭代机制建立:每次底层模型升级后,你有没有系统地做过一次“dead weight inventory”(无用负担盘点)?
很多团队面临的问题,不是Harness不够多,恰恰相反,是组件做出来以后就再也没有删除过。而一个从来不删减的Harness,最终很容易变得两头不讨好:
- 对模型来说太重,限制了其能力的发挥。
- 对系统来说太复杂,增加了维护成本。
- 对成本来说太贵,产生了不必要的开销。
- 对开发团队来说太难维护和理解。
总结:进入“Build to Delete”的新阶段
回顾从《Codex为什么能又快又稳》到《Coding Agent的6个关键模块》这条技术线,其核心判断一直是:很多任务处理中的“失真”问题,不能只指望模型临场克服,需要将它们外移、沉淀为可靠的系统机制。而Anthropic的新文,等于把后半句话也补上了:系统机制不是越多越好。
真正成熟的Harness,不只是会补短板,还得在模型能力跨过门槛、短板消失之后,主动审视并删掉那些已经不再“承重”的旧补丁。
如果把最近的思考收成一句话,笔者的判断是:Harness 的设计正在进入第二阶段。
- 第一阶段,是拼命“补”——填补模型的各项能力缺口。
- 第二阶段,是持续“删”——清理因模型进步而产生的历史包袱。
新文最有价值的地方,不是又给出了三个新名词,而是把“删减”这一工程逻辑明确地提了出来,并提供了可操作的模式。前面那篇长任务文章的结尾有句话令人印象深刻:“Harness的可能性空间不会随模型进步而缩小,它只是在不断移动。”
后面这篇新文,则为那句话提供了一个更实操的版本:Sprint被优化了,硬编码的过滤器不需要了,预加载的长指令换成了按需读取的Skills,模型能自己进行局部编排、管理上下文、选择记忆了。但与此同时,新的边界问题也随之浮现——memory folder如何设计更高效?安全边界具体画在哪里?缓存策略不当导致成本翻倍怎么办?
所以,最后还是想把全文收在这样一句工程格言上:Build to delete(为删除而构建)。
先基于当前认知和模型能力把系统搭出来,然后在运行中持续验证,最后敢于在条件成熟时拆掉那些过时的部分。这可能才是AI Agent时代,技术演进更像扎实的工程实践,而不仅仅是炫目“魔法”的地方。
对这类AI Agent框架的工程化演进、最佳实践和源码解析感兴趣?欢迎到云栈社区的 智能 & 数据 & 云 或 开源实战 板块,与更多开发者一起深入探讨。
参考文献
 发表于 2026-4-8 06:30:02
|
查看: 160|
回复: 0
发表于 2026-4-8 06:30:02
|
查看: 160|
回复: 0
