你有没有发现,每次向AI提问一个技术问题时,它总会先说一句“Great question!”,接着用三段话铺陈背景,再用两段解释你根本没问的东西,直到第六段才给出那个其实一句话就能讲清楚的答案?
说实话,这种冗长的回复方式已经让不少开发者感到抓狂。终于有人忍无可忍,捣鼓出了一个听起来有点荒诞的解决方案:强制让Claude用穴居人的方式说话。
这个项目叫做Caveman,在GitHub上已经收获了4500颗星,采用MIT协议,并在今年4月6日刚刚发布了v1.2.0版本。
效果如何?输出token直接砍掉75%,回复速度快了3倍。
Caveman GitHub 仓库:4.5k Stars,MIT 许可证
. . . . .
核心速览
一、Caveman 是一个 Claude Code 技能插件,旨在让AI用极简语法回复,砍掉废话,保留关键精度。
二、提供三档强度可选:Lite(去除修饰词)、Full(完整的穴居人语法)、Ultra(电报式极限压缩)。
三、在10个常见编程任务测试中,平均节省 65% 的token,最高节省达 87%。
四、有学术论文指出,简短约束非但不降低准确率,在某些场景下甚至能提升26个百分点。
五、真正的问题或许不是token贵不贵,而是AI回复的“信噪比”正在持续恶化。
Caveman 到底做了什么?
先看一个直观对比。
假设你问AI:“我的React组件为什么一直重新渲染?”
正常模式,AI的回复可能需要 69 个token:
The reason your React component is re-rendering is likely because you are creating a new object reference on each render cycle. When you pass an inline object as a prop, React shallow comparison sees it as a different object every time, which triggers a re-render. I would recommend using useMemo to memoize the object.
穴居人模式,同样的答案被压缩到仅 19 个token:
New object ref each render. Inline object prop = new ref = re-render. Wrap in useMemo.
信息量完全一致。少了什么?客套话、背景铺垫、过渡句以及重复性的解释。仅仅是这些东西,就占用了原回复72%的token。
Caveman提供了三档可调节的强度:
- Lite:仅去掉“Great question!”之类的修饰词和客套话,保持正常语法。
- Full:默认档位,采用完整的“穴居人语法”,省略冠词、连词,像原始人一样直奔要点。
- Ultra:电报模式,极限压缩到只剩下关键词和核心符号。
此外,它还附带一个compress工具,能够将已有的长对话上下文压缩掉45%的输入token,这对于需要处理长会话上下文的场景非常实用。
安装只需一行命令:
npx skills add JuliusBrussee/caveman
项目作者进行了一项基准测试,跑了10个常见的编程任务。结果显示,使用Caveman后平均节省了65%的token。其中,关于React error boundary的任务节省最显著,达到87%;即使是最简单的“将callback改为async”任务,也节省了22%。
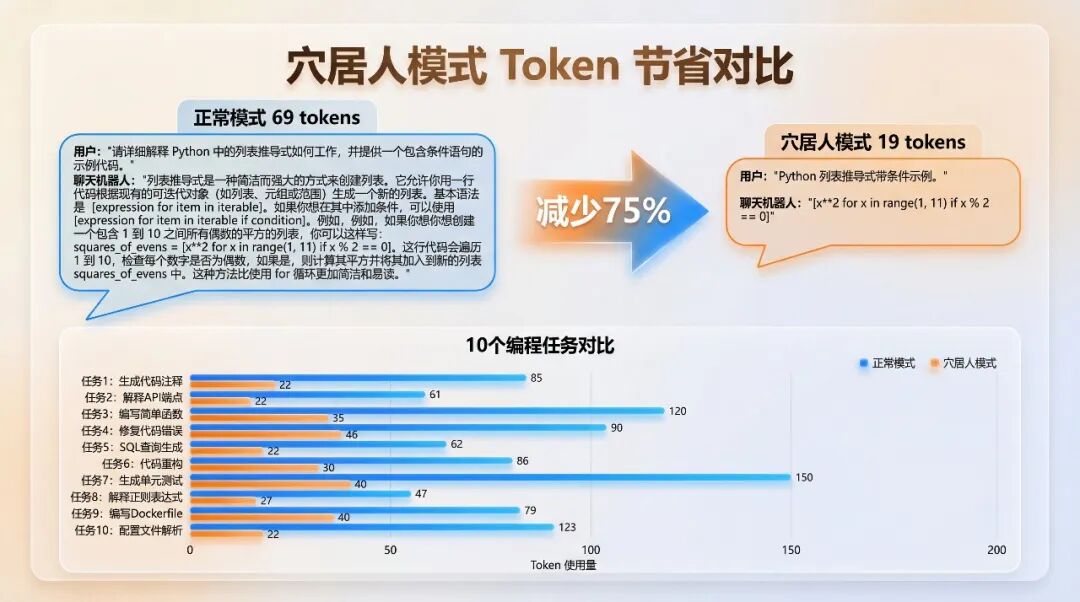
Caveman Token 节省对比:10个编程任务实测数据
有趣的是,作者本人坦言,这个东西“本来就是个玩笑”。
Token省了,模型的“思考”会不会也省了?
这个项目在Hacker News上引发了热烈讨论,获得了867分和358条评论。
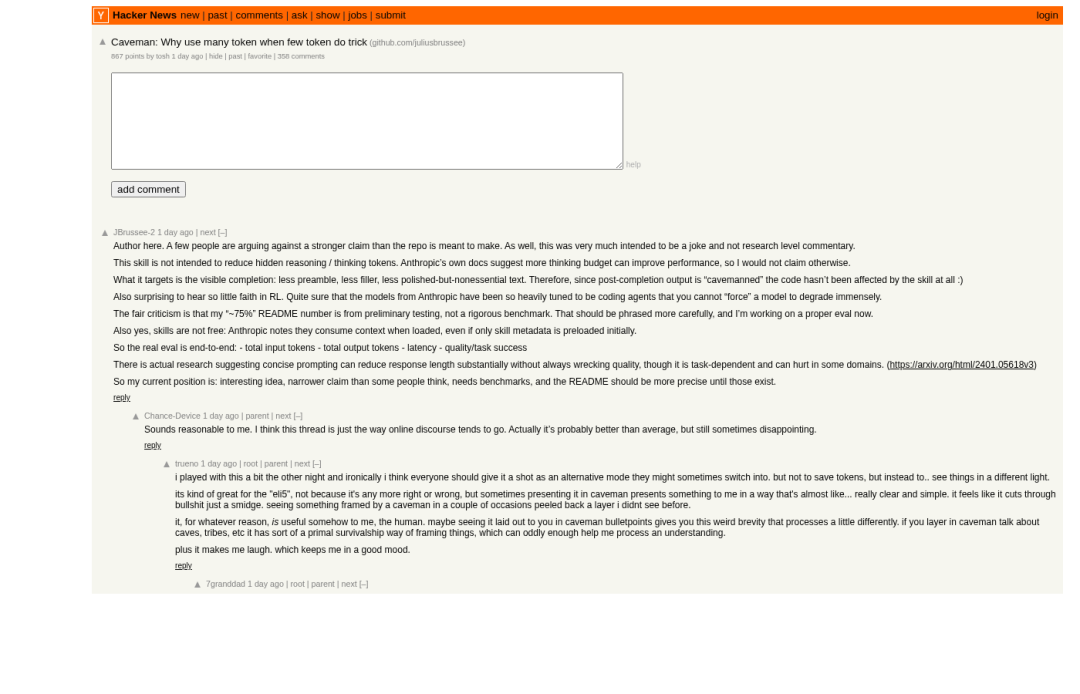
Hacker News 热议:867 分,358 条评论
争论的核心焦点在于:强行让模型输出变得简短,是否会损害其推理能力?
反对者的逻辑很直接:Token是大语言模型的基本计算单位,模型生成每个token时都在进行推理。限制输出长度,等同于限制其“思考”空间。这看起来不是在省钱,而是在砍断推理链条。
这个观点听起来颇有道理。
但支持者指出了关键区别:Caveman削减的并非推理步骤,而是修饰性语言。将“I would recommend using useMemo to memoize the object”压缩为“Wrap in useMemo”,完整的推理逻辑(“因为创建了新对象引用,所以触发重渲染,建议使用useMemo”)并没有丢失,被去掉的只是“I would recommend”、“to memoize the object”这类对解决问题无实质帮助的填充词。
这就像一个外科医生在手术中。你不需要他一边操作一边和你闲聊天气,你需要的是精准、高效的动作。去掉闲聊,并不会影响手术本身的质量。
随后,一篇学术论文的出现让讨论出现了翻转。
2026年3月发表的一篇题为《Brevity Constraints Reverse Performance Hierarchies》的研究发现,给模型施加“简短回复”的约束后,在某些基准测试上的准确率反而提升了26个百分点。更引人深思的是,这种约束直接逆转了不同模型之间的性能排名。原本排名靠后的模型,在简短约束下表现反而超过了之前的领先者。
这或许说明,冗长的输出中可能包含大量的“自我重复”和“对冲性表达”。模型在说得过多时,有时反而会混淆自己的核心判断。简短约束相当于逼迫它只输出最有把握、最核心的信息。
真正的问题或许不是Token,而是注意力
讨论到这里,我们可能忽略了一个更根本的问题。
Token有明确的价格,可以量化、可以优化。但人的注意力没有价签,却更容易在无形中被浪费。
当你使用AI编程辅助工具时,真正的成本往往不是API调用账单。而是你盯着那一大段回复,花30秒快速浏览,再用10秒定位关键信息,最后花5秒确认这就是你要的答案。这45秒,如果乘以一天几十次的交互,累积起来就是半小时到一小时的注意力消耗。
把这些宝贵的注意力花在“Great question!”和“I would recommend”这类填充词上,无疑是一种浪费。
Hacker News的评论里有人提到了一个更荒诞的现象:某些公司竟然将AI的token消耗量当作一项KPI。消耗得越多,似乎就越“智能”;产出的token越多,仿佛就代表AI工作得越“努力”。
仔细想想这个逻辑链:我们先是训练AI说一大堆“正确的废话”来显得礼貌和详尽,然后再花费资源开发工具去压缩这些废话。
AI回复的“信噪比”正在恶化。这不是因为模型变笨了,而是因为我们一直在奖励冗长。在人类反馈强化学习(RLHF)的训练过程中,更长、更详细的回复往往能获得更高的人类偏好评分。模型学会的策略就是:多说总不会错,说少了反而可能被扣分。
Caveman的火爆,恰恰从用户端印证了需求正在发生反转。
一些观察
回顾整件事,有几条线索值得串联起来思考。
一个“本来是个玩笑”的项目获得了4500星;一篇严肃论文证明了简短约束能提升准确率;社区关于token与推理的争论暴露了人们对AI输出质量的普遍焦虑;还有那个将token消耗量作为KPI的荒诞现实。
把这些放在一起看,似乎指向同一个判断:AI交互正在进入一个“去泡沫”阶段。
过去两年,大家追求的是AI能做更多、说更多、生成更多。现在,一部分用户开始往回拉了。他们不要“更多”,要“更准”;不要“更长”,要“更快”;不要“客套”,要“信息密度”。
Caveman就是这个趋势的一个极端表达。它不优雅,甚至有点简单粗暴。但粗暴有粗暴的好处,它把一个核心问题摆上了台面:你究竟是需要AI给你一个确切的答案,还是需要它为你表演一场详尽的解说?
这个问题,或许值得每一个日常使用AI编程辅助工具的开发者认真想一想。
. . . . .
相关链接
- 项目GitHub:github.com/JuliusBrussee/caveman
- 安装命令:
npx skills add JuliusBrussee/caveman
- 参考论文:Brevity Constraints Reverse Performance Hierarchies (2026.03)
如果你也厌倦了AI的“长篇大论”,不妨去试试这个项目,并在云栈社区分享你的使用体验。
 发表于 2026-4-8 06:32:43
|
查看: 240|
回复: 0
发表于 2026-4-8 06:32:43
|
查看: 240|
回复: 0
