我们都写过 go func(){...}(),但从“能跑”到“健壮、可维护、敢上线”,中间隔着一条巨大的鸿沟。裸奔的 Goroutine、失控的资源、隐蔽的内存泄漏、棘手的竞态条件……这些都是考察工程能力的核心要点。
别慌!这篇文章不谈空洞的理论,直接上干货,为你彻底讲透 Go 并发编程中最重要的“三件套”:Worker Pool(并发约束)、Pipeline(流水线)、Fan-out/Fan-in(扇出扇入)。
- 并发约束 (Worker Pool):如何给你的 goroutine 套上“缰绳”,防止资源耗尽?
- 流水线模式 (Pipeline):如何像工厂流水线一样,优雅地处理多阶段任务?
- 扇入扇出 (Fan-out/Fan-in):如何将任务分发给“千军万马”,再将结果从容回收?
为什么需要“并发模式”?
启动一个 goroutine 的成本极低,但“简单”不等于“容易”。很多开发者常常陷入“为了并发而并发”的误区。
我们经常面临的痛点:
- 资源失控:毫无节制地启动 goroutine,瞬间耗尽 CPU 和内存,导致服务雪崩。
- 状态混乱:多个 goroutine 同时读写共享数据,一不小心就出现数据竞争,调试如同噩梦。
- Goroutine 泄露:Goroutine 启动后无法正常退出,像幽灵一样常驻内存,最终拖垮系统。
Go 的并发哲学核心是 “不要通过共享内存来通信,而要通过通信来共享内存”。Channel 是实现这一理念的利器,而并发模式,就是使用 channel 等工具来组织、协调和管理成千上万 goroutine 的“设计蓝图”。它能帮助我们写出结构清晰、易于维护的高质量并发代码。
核心理念:约束与编排
在深入实战前,先理解 Go 并发的两个核心理念:约束(Limitation) 和 编排(Orchestration)。
- 约束:意味着我们不能放任 goroutine 野蛮生长。必须对其数量、生命周期进行有效管理。这就像城市的交通系统,如果没有红绿灯和交通规则,车辆再多也只会造成拥堵。
- 编排:指的是将独立的 goroutine 按照一定的结构组织起来,协同完成一个复杂任务。这就像一个交响乐团,每个乐手都很有才华,但需要指挥家来协调,才能演奏出华美的乐章。
小贴士:优秀的并发程序,不是看你启动了多少 goroutine,而是看你把它们管理和编排得多么井然有序。
实战演练:3个核心并发模式
光说不练假把式,接下来,让我们通过三个由浅入深的实战示例,来掌握这些强大的并发模式。
模式一:并发约束(Worker Pool 模式)
这是最基础也是最实用的模式,用于解决“资源失控”问题。
场景:假设我们要处理100个独立的计算任务,每个任务耗时1秒。
错误示范(裸写 go):
func main() {
var wg sync.WaitGroup
for i := 0; i < 100; i++ {
wg.Add(1)
go func(id int) {
defer wg.Done()
fmt.Printf("开始处理任务 %d\n", id)
time.Sleep(time.Second) // 模拟耗时操作
fmt.Printf("任务 %d 处理完成\n", id)
}(i)
}
wg.Wait()
}
这段代码会瞬间启动100个goroutine。如果任务数是10万,你的系统可能就直接“跪了”。
🔥 最佳实践(Worker Pool):
我们创建一个固定数量的“工人”(worker goroutine),让它们从“任务管道”(tasks channel)中领取任务来执行。
package main
import (
"fmt"
"sync"
"time"
)
// worker 是我们的“工人”,负责处理具体的任务
func worker(id int, tasks <-chan int, wg *sync.WaitGroup) {
defer wg.Done()
for taskID := range tasks {
fmt.Printf("工人 %d 开始处理任务 %d\n", id, taskID)
time.Sleep(time.Second) // 模拟耗时
fmt.Printf("工人 %d 完成了任务 %d\n", id, taskID)
}
}
func main() {
const numTasks = 100 // 总任务数
const numWorkers = 5 // 工人数量(并发度)
tasks := make(chan int, numTasks)
var wg sync.WaitGroup
// 启动固定数量的工人
for i := 1; i <= numWorkers; i++ {
wg.Add(1)
go worker(i, tasks, &wg)
}
// 分配任务
for i := 1; i <= numTasks; i++ {
tasks <- i
}
close(tasks) // 所有任务分配完毕,关闭任务通道
// 等待所有工人完成工作
wg.Wait()
fmt.Println("所有任务处理完毕!")
}
执行流程图:
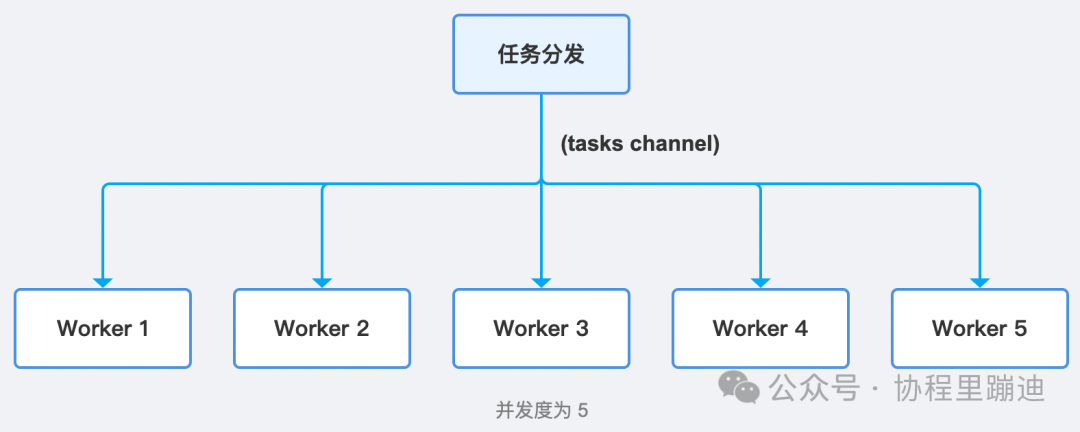
通过这种方式,我们始终只有5个 goroutine 在真正执行任务,极大地控制了系统资源。
模式二:流水线(Pipeline 模式)
当一个任务可以被拆分成多个连续的阶段时,流水线模式就派上用场了。
场景:我们要处理一系列数字,需要经过两个步骤:1. 计算平方;2. 将结果加倍。
package main
import (
"fmt"
"sync"
)
// 第一个阶段:生成数字
func generator(nums ...int) <-chan int {
out := make(chan int)
go func() {
for _, n := range nums {
out <- n
}
close(out)
}()
return out
}
// 第二个阶段:计算平方
func square(in <-chan int) <-chan int {
out := make(chan int)
go func() {
for n := range in {
out <- n * n
}
close(out)
}()
return out
}
// 第三个阶段:加倍
func double(in <-chan int) <-chan int {
out := make(chan int)
go func() {
for n := range in {
out <- n * 2
}
close(out)
}()
return out
}
func main() {
// 构建流水线
nums := []int{1, 2, 3, 4, 5}
stage1 := generator(nums...)
stage2 := square(stage1)
stage3 := double(stage2)
// 消费最终结果
for result := range stage3 {
fmt.Println(result)
}
}
执行流程图:

每个阶段都是一个独立的 goroutine,通过 channel 连接,代码结构清晰,高度解耦。
⚠️ 注意:优雅地关闭流水线是关键。我们遵循一个原则:数据的生产者负责关闭 channel。这样,下游的 for range 循环才能在处理完所有数据后自动退出。
模式三:扇入扇出(Fan-out, Fan-in 模式)
这是流水线模式的威力加强版!如果流水线中的某个阶段处理速度很慢,成为了瓶颈,我们就可以使用“扇出”来并行化这个阶段。
场景:在上面的例子中,假设 square 阶段计算非常耗时。
🔥 最佳实践(扇出/扇入):
我们可以启动多个 square worker 来并行处理,然后用“扇入”模式将它们的结果合并到一个 channel 中。
package main
import (
"fmt"
"sync"
)
// generator 和 double 函数与上例相同...
func generator(nums ...int) <-chan int {
out := make(chan int)
go func() {
for _, n := range nums {
out <- n
}
close(out)
}()
return out
}
func double(in <-chan int) <-chan int {
out := make(chan int)
go func() {
for n := range in {
out <- n * 2
}
close(out)
}()
return out
}
// 扇出:启动多个 square worker
func squareFanOut(in <-chan int, numWorkers int) []<-chan int {
outs := make([]<-chan int, numWorkers)
for i := 0; i < numWorkers; i++ {
out := make(chan int)
go func() {
for n := range in {
// 模拟复杂计算
// time.Sleep(time.Millisecond * 500)
out <- n * n
}
close(out)
}()
outs[i] = out
}
return outs
}
// 扇入:将多个 channel 的结果合并到一个 channel
func fanIn(ins ...<-chan int) <-chan int {
var wg sync.WaitGroup
out := make(chan int)
// 为每个输入 channel 启动一个 goroutine
for _, in := range ins {
wg.Add(1)
go func(ch <-chan int) {
defer wg.Done()
for n := range ch {
out <- n
}
}(in)
}
// 启动一个 goroutine,在所有输入 channel 都关闭后,关闭输出 channel
go func() {
wg.Wait()
close(out)
}()
return out
}
func main() {
nums := []int{1, 2, 3, 4, 5, 6, 7, 8, 9, 10}
// 构建流水线
stage1 := generator(nums...)
// 扇出到3个 square worker
squareChannels := squareFanOut(stage1, 3)
// 扇入合并结果
stage2 := fanIn(squareChannels...)
stage3 := double(stage2)
// 消费最终结果
for result := range stage3 {
fmt.Println(result)
}
}
通过扇入扇出,我们极大地提升了瓶颈阶段的处理能力,能更有效地利用多核 CPU 资源!
最佳实践与“彩蛋”技巧
1. 模式对比总结
| 模式 |
适用场景 |
优点 |
缺点 |
| Worker Pool |
批量处理独立任务,控制并发度 |
资源可控,稳定可靠 |
若任务处理时间不均,可能导致部分 worker 空闲 |
| Pipeline |
多阶段、流式数据处理 |
结构清晰,解耦度高 |
额外的 channel 开销,关闭逻辑需谨慎 |
| Fan-out/Fan-in |
并行化流水线中的瓶颈阶段 |
极大提升吞吐量 |
同步逻辑复杂,容易出错(尤其扇入) |
2. 优雅地处理错误
在流水线中,错误处理是个难题。一个最佳实践是,将返回值封装成一个 struct,同时包含数据和错误。
type Result struct {
Data int
Err error
}
这样,错误就可以和数据一起在 channel 中传递,下游可以统一处理。
3. 彩蛋技巧:使用 context 进行优雅的取消
当我们需要提前终止所有 goroutine 时(比如用户取消了请求),暴力 close channel 是危险的。Go 官方推荐的方案是使用 context 包。
func worker(ctx context.Context, tasks <-chan int) {
for {
select {
case <-ctx.Done(): // 上下文被取消
fmt.Println("收到取消信号,工人退出。")
return
case task, ok := <-tasks:
if !ok {
return // 通道关闭
}
// 处理任务...
}
}
}
通过 context,我们可以像广播一样,将取消信号安全地传递给所有相关的 goroutine,实现真正的优雅退出。
结语
今天,我们从最基础的 Worker Pool,到结构化的 Pipeline,再到高性能的 Fan-out/Fan-in,学习了 3 个核心的 Go 并发设计模式。掌握了它们,你就拥有了驾驭 Go 并发的“内功心法”。
真正的并发编程,艺术远大于技术。希望这篇文章能为你打开一扇新的窗户,帮助你在未来的面试求职和项目开发中更加得心应手。如果你想继续深入探讨或寻找更多实战案例,欢迎来云栈社区交流分享。
 发表于 2026-4-8 17:53:03
|
查看: 115|
回复: 0
发表于 2026-4-8 17:53:03
|
查看: 115|
回复: 0
