智谱最近发布了 GLM-5.1。我自己作为主力用了快两周,说实话,体验确实很惊艳。这不是那种“好像好了一点”的微调,而是能让你停下来愣一会儿的实质性提升。之前我搭建的那个多 Agent 股票分析系统,就是用 GLM-5.1 从零搞定的。
先说结论:GLM-5.1 的编程能力,已经非常接近 Claude Opus 4.6,并且超越了 K2.5。
但编程能力强还不是最让我意外的。最意外的是:它能自己干活,而且是能干很久的那种。
以前不管模型多强,用起来都像带实习生——你说一步它做一步,做多了容易忘,复杂任务你得全程盯着。GLM-5.1 不太一样,你给它一个目标,它能自己拆解步骤、自己推进、中间出问题自己想办法修,最后给你一个完整的交付物。
说人话就是:以前的 AI 是你手边的一个工具,你让它干嘛它干嘛。GLM-5.1 开始像一个你能“甩手掌柜”的同事了——你给方向,它自己跑完全程。
口说无凭,实测为证。我专门拿出了两个近期需要完成的开发任务来测试它:
- Java 智能诊断助手:一款面向线上故障排查的性能诊断工具。用户只需输入服务地址和故障现象,这个智能助手就能自动规划诊断路径,完成线上问题定位,并输出问题代码和解决方案。
- 企业级电商订单服务慢查询治理:一个百万级数据量下、核心订单接口频繁超时的真实案例,涉及多维度复杂查询的系统性梳理与优化。
一个是完全从零搭建的工程交付,另一个是面对既有系统的性能治理。接下来,我们直接看 GLM-5.1 的实际表现。
前置工作
在正式开发之前,需要进行一些简单的配置。按照目前的主流实践,我推荐采用 Claude Code + GLM-5.1 的方式进行编码开发。
环境配置主要两步:
- 安装 Claude Code:
npm i -g @anthropic-ai/claude-code@latest
- 安装 CC Switch 完成模型切换。这是一个专门管理 Claude Code 模型切换的小工具,能让你在不同 Provider 间一键切换,还支持管理 Skills、MCP 和提示词。当然,你也可以直接修改 Claude Code 的配置文件。
配置过程如下:
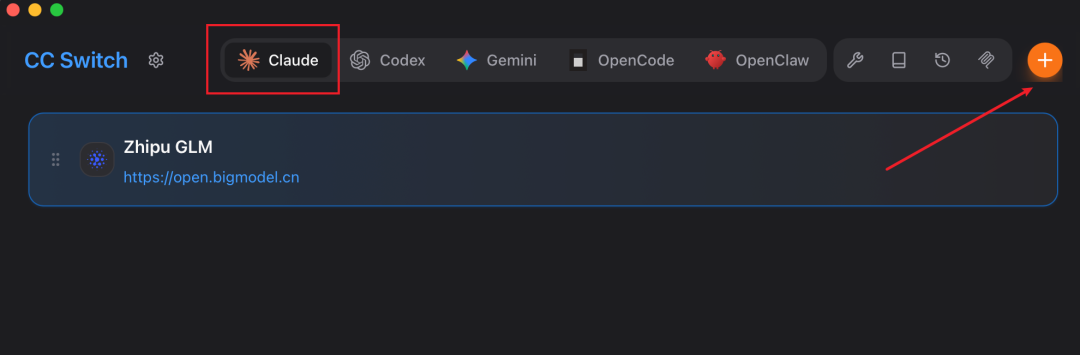
1、点击加号添加智谱模型:
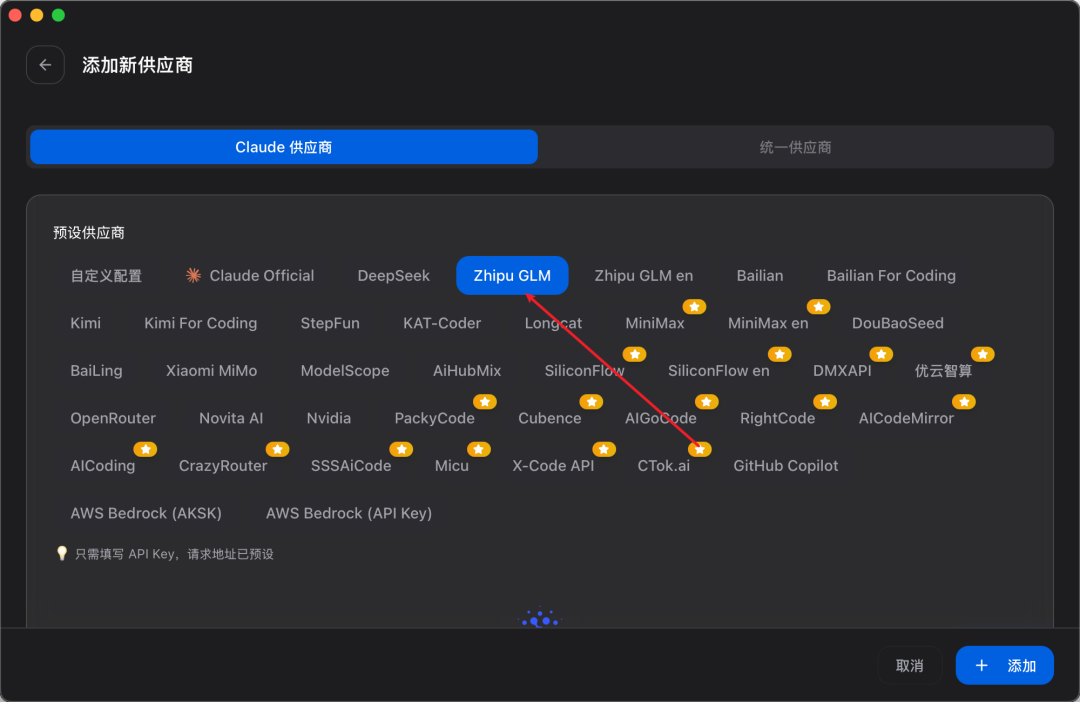
2、在供应商列表中选择 GLM 模型:
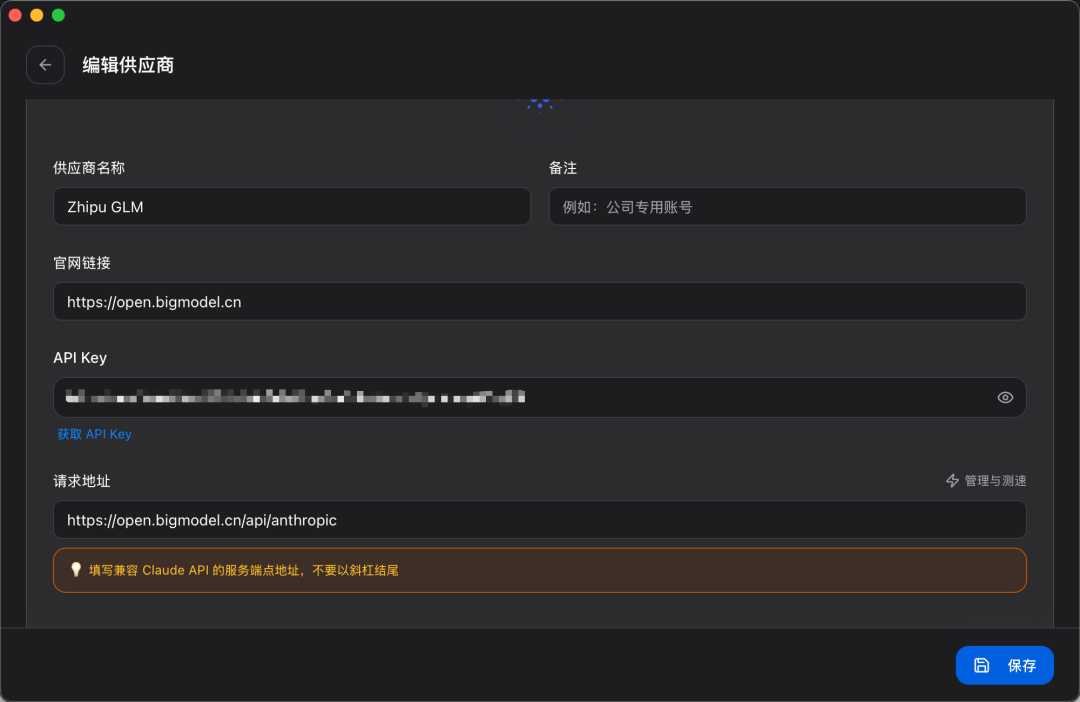
3、配置供应商参数,注意请求地址:
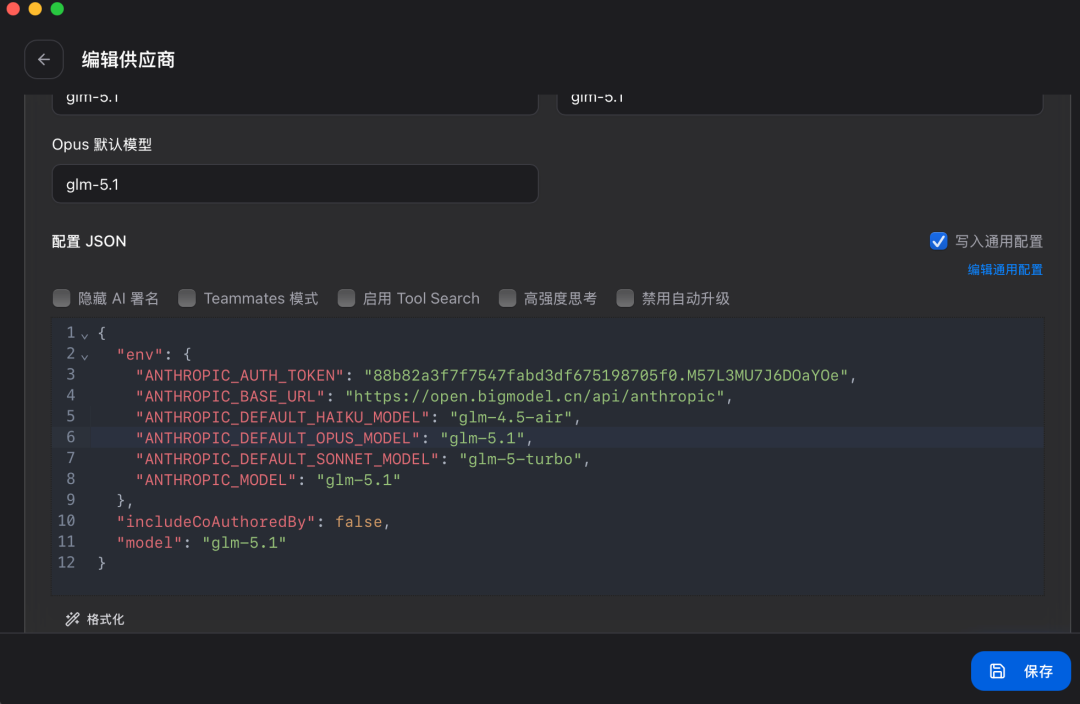
Claude Code 内部模型环境变量与 GLM 模型对应关系 JSON 配置:
因为我更习惯用 IDE,所以推荐通过 VSCode + Claude Code for VS Code 插件进行交互和编码验收。安装插件后,可以直接在 IDE 里和模型对话、审查代码,比 CLI 界面更直观:
从 0 开发一个 Java 智能诊断助手
为什么需要 JVM 智能诊断助手?
JVM 线上诊断一直是 Java 开发中的棘手问题。传统模式下,面对性能瓶颈或线上故障,排查路径基本固定:
- 查看 Grafana 监控面板,初步定位异常方向。
- 登录线上服务器,排查 CPU、内存、GC 等指标。
- 明确是 Java 应用问题后,启动
Arthas 执行一系列诊断指令,逐步缩小范围。
- 定位到具体代码段,分析根因并制定修复方案。
在 AI 出现前,这套流程虽然繁琐,但确实有效。然而,随着业务复杂度和故障响应时效要求的提高,传统模式的弊端越来越明显:
- 监控指标过于主观:面对 CPU 飙升、内存泄漏、OOM 等问题,监控面板指标繁多,研发人员往往依赖经验做主观推断,缺乏系统化的诊断方法论。
- 诊断链路过于冗长:从 Grafana 到服务器再到
Arthas,涉及多个工具切换,耗时且低效,不利于线上故障的快速止血。
- 高度依赖工程师经验:
Arthas 功能强大,但代价是开发人员必须熟悉各种指令和推理路径,才能高效定位问题。
随着 AI 技术,特别是 Agent 和 Skill 等概念的成熟,我有了一个构想:能否借助 AI 将诊断经验沉淀复用,让 AI 根据既有经验构建决策路径?同时,结合它的决策方案赋予对应工具,使其能基于用户给定的服务名和故障表象,自动化连接线上服务器完成诊断,定位代码段,最终输出问题根因和解决方案。
GLM-5.1 如何自主完成技术选型与架构设计?
有了构想,接下来就是技术选型和方案落地。我把完整的需求描述交给了模型:
研发一款基于Arthas的智能体诊断工具,该工具需实现以下核心功能:
1. 当用户输入线上故障服务名称及具体故障现象后,系统能够自动定位至目标故障服务器,主动对目标服务进行实时监控与深度分析。
2. 通过集成Arthas的反编译功能,精准定位到引发故障的具体代码段
3. 基于分析结果生成包含问题根因、代码修复建议及实施步骤的完整解决思路。
请提供该工具的技术选型方案,包括但不限于开发语言(优先考虑Java技术栈)、核心框架、数据库表设计、部署架构等,并设计详细的系统实现方案,涵盖功能模块划分、数据流程设计、关键技术难点及解决方案等内容。
模型收到需求后,没有立刻开始写代码,而是先结合项目上下文(一个空文件夹)进行推理分析,自主完成了一份包含十几个阶段的完整技术方案。这就是 GLM-5.1 的长程规划能力——给一个目标,它自己拆出整条路径。
模型结合需求,针对 Agent 拆解出技术选型和 Arthas 集成方案的检索。从检索关键字可以看出,它在方案选取上会优先考虑成熟稳定的解决方案,这一点让人满意:

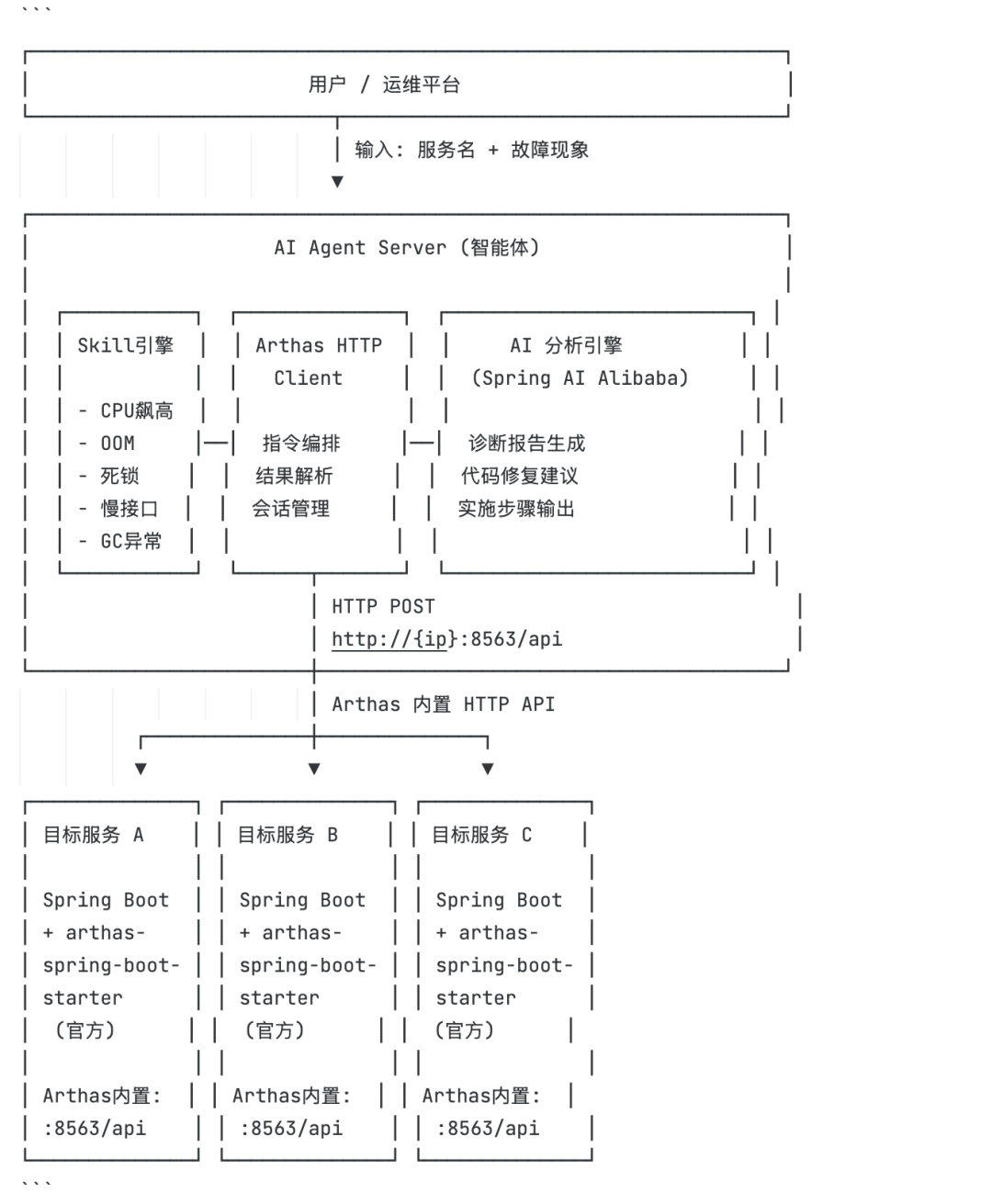
模型检索了大量资料和 Arthas 官方文档后,输出了下面的系统架构设计图。从上到下分三层:用户层输入服务名和故障现象,Agent 层由 Skill 引擎、Arthas HTTP Client 和 AI 分析引擎三大核心模块协同工作,最底层通过 Arthas 内置 HTTP API 对接多个目标服务实例。架构模块划分和职责边界清晰——模型把从故障输入到定位代码再到生成报告的完整链路一次性设计到位:
模型不仅给出了架构图,还进一步拆解了核心组件的职责分工——从 AI Agent Server 的流程编排,到 Arthas HTTP Client 的会话管理,到 Skill 引擎的诊断步骤链定义,再到 AI 分析引擎的报告生成,每个组件的边界和协作关系都交代得很清楚:

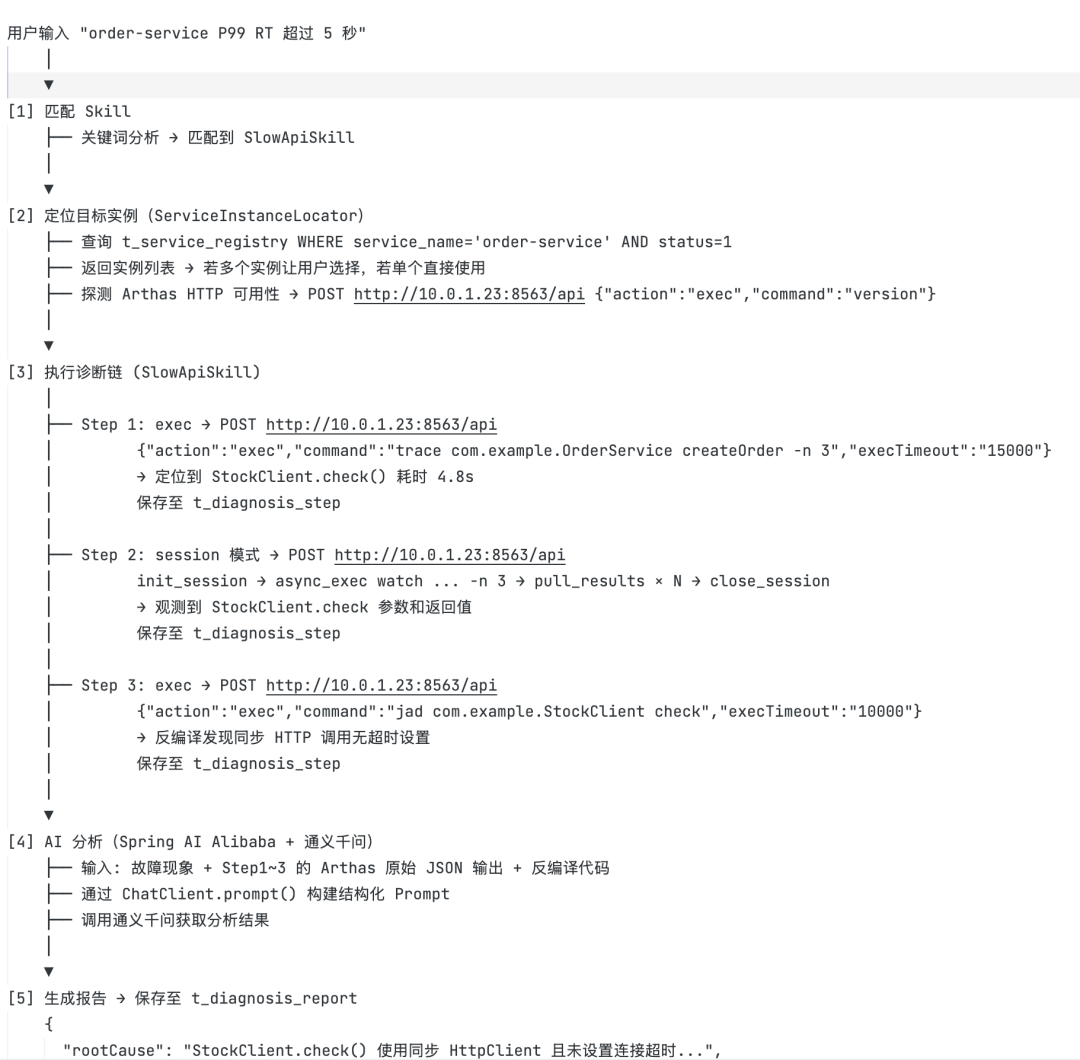
最后来看看最重要的数据流设计。按照我的开发经验,架构明确后,只要数据流链路完整清晰,基本就可以着手开发了。模型结合一个常见的 RT 超时场景,给出了完整的诊断链路——从 Skill 匹配、诊断步骤执行、问题追踪、根因定位,到 Arthas 反编译和最终的诊断报告输出。
一个细节:模型针对 Arthas HTTP API 设计了完整的会话模式交互流程(init_session → async_exec → pull_results → interrupt_job → close_session),甚至连 watch、trace 这类持续监听型命令的异步轮询机制都考虑到了。这种对底层工具交互细节的把控能力,说明它确实理解了 Arthas 的通信模型:
其他细节就不赘述了。整体来说,架构和数据流链路都准确到位。让我比较满意的是,模型不仅针对既有需求给出了简洁准确的方案,还主动输出了后续扩展方向——WebSocket 实时推送、诊断知识库向量化存储、已知 Pattern 的自动修复补丁、告警联动自动触发诊断、自定义 Skill 市场、多语言支持。这些扩展方向都紧扣当前架构的技术延伸点,非常务实。

模型编码交付的效果如何?
整个过程花费不到半小时,模型自主规划了十余个阶段,持续工作约 25 分钟,中间自主检索了多次外部文档,最终交付了一个包含 9 个子模块的完整项目。从技术选型到架构设计到编码落地,整个过程模型持续执行了十几分钟,中间没有断链、没有遗忘前面的约束。
确认方案没有问题后,我直接下达开发指令:
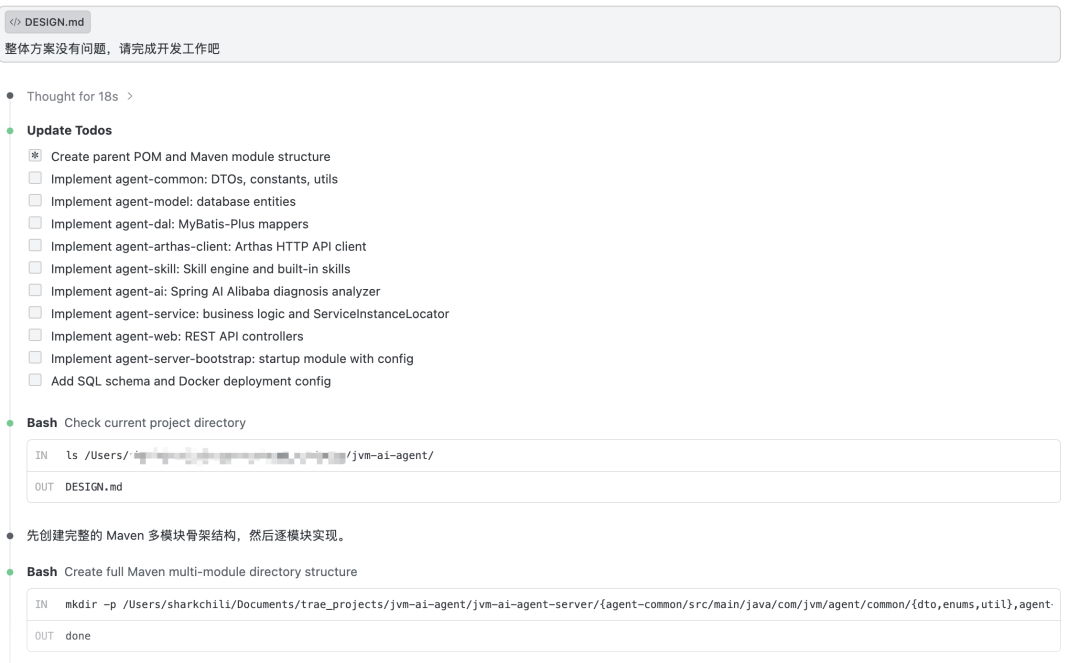
整体方案没有问题,请完成开发工作吧
模型收到指令后,开始在后台自主编码。可以看到模型按照之前的架构设计,有条不紊地逐模块推进——从父 POM 和 Maven 多模块骨架搭建,到通用工具类、数据模型、数据访问层、Arthas 客户端封装、Skill 引擎、AI 分析引擎、业务逻辑层、Web 控制器,直到启动模块和部署配置,11 个子步骤全部自主完成,没有跳过任何一个模块,也没有因为链路过长而遗漏前面的设计约束:
片刻之后,模型完成了全部编码工作,并输出了一份详细的交付清单。可以看到 9 个模块、46 个文件全部到位——从通用工具类到 7 个内置诊断 Skill,从 Arthas HTTP API 的 exec+session 双模式封装到 Spring AI Alibaba 诊断分析器,一个不少。通常模型写到后半程容易跳过一些模块,但 GLM-5.1 把每个模块都完整输出了:
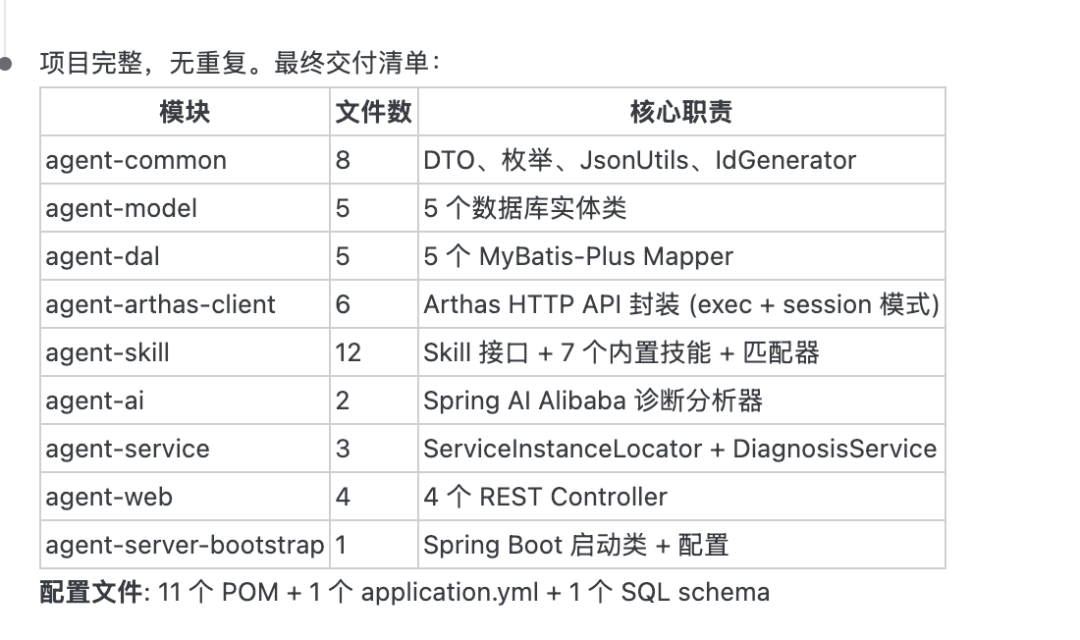
先看整体模块结构,模型按照 Java 多模块的标准规范完成了工程划分,从上到下严格遵循 common→model→dal→client→skill→ai→service→web→bootstrap 的依赖层级,职责边界清晰,命名规范统一。
agent-skill 模块值得关注,模型不仅设计了 Skill 引擎的抽象接口,还内置了 7 个覆盖常见 JVM 故障场景的诊断技能(CPU 飙高、OOM、死锁、慢接口、GC 异常、线程泄漏、类找不到),每个 Skill 都定义了完整的诊断步骤链。这种“框架 + 内置实现”的设计思路,模块划分得比较到位:
jvm-ai-agent/
├── jvm-ai-agent-server/ # 智能体服务端(核心)
│ ├── agent-common/ # 通用模块:工具类、常量、DTO
│ ├── agent-model/ # 数据模型:实体、数据库映射
│ ├── agent-dal/ # 数据访问层:Mapper、Repository
│ ├── agent-arthas-client/ # Arthas HTTP API 客户端封装
│ ├── agent-skill/ # Skill 引擎(诊断方法论)
│ ├── agent-ai/ # AI 分析引擎
│ ├── agent-service/ # 业务逻辑层(含服务实例查询)
│ ├── agent-web/ # Web 层:REST API、WebSocket
│ └── agent-server-bootstrap/ # 启动模块
│
└── pom.xml # 父 POM
再看诊断核心逻辑,模型严格按照架构设计中定义的数据流完成了完整的诊断业务链开发。整个 executeDiagnosis 方法的逻辑编排比较成熟——Skill 匹配、实例定位、诊断链执行、动态命令解析、AI 分析、报告生成,异常处理也考虑到了非关键步骤失败时继续执行的容错策略:
- Skill 匹配:通过
DefaultSkillMatcher 根据故障现象关键词匹配最佳诊断技能
- 实例定位:通过
ServiceInstanceLocator 根据服务名解析目标实例 IP 和 Arthas 端口
- 诊断链执行:遍历 Skill 定义的诊断步骤链,依次执行
Arthas 命令并收集结果
- 动态命令解析:从
Arthas 输出中提取类名、方法名等上下文变量,注入后续步骤的动态命令模板
- AI 分析报告:将全部诊断数据交给 AI 分析引擎,生成包含根因、修复建议、严重程度的结构化报告
private void executeDiagnosis(DiagnosisRecord record, DiagnosisRequest request) {
try {
// 1. 匹配 Skill
Optional<SkillDefinition> skillOpt = skillMatcher.findBestMatch(request.getSymptom());
if (skillOpt.isEmpty()) {
failDiagnosis(record, "无法匹配到合适的诊断技能");
return;
}
SkillDefinition skill = skillOpt.get();
// ......
// 2. 定位目标实例
ServiceRegistry instance = instanceLocator.resolveInstance(
request.getServiceName(), request.getInstanceIp());
// ......
// 3. 执行诊断步骤链
List<DiagnosticStep> chain = skill.getDiagnosticChain();
StringBuilder allDiagnosticData = new StringBuilder();
String decompiledCode = "";
Map<String, String> contextVars = new HashMap<>();
for (int i = 0; i < chain.size(); i++) {
DiagnosticStep step = chain.get(i);
// ...... 初始化步骤实体
try {
// 解析动态命令(支持上下文变量注入)
String command = resolveCommand(step, contextVars);
// ......
// 执行Arthas命令并记录耗时
String result = executeStep(host, port, step, command);
// 如果是 jad 结果,记录为反编译代码
if ("jad".equals(step.getResultType())) {
decompiledCode = result;
}
// 从结果中提取上下文变量供后续步骤使用
extractContextVars(result, contextVars);
} catch (Exception e) {
// 非关键步骤失败时继续执行
// ......
}
}
// 4. AI 分析
String report = diagnosisAnalyzer.analyze(
request.getSymptom(), allDiagnosticData.toString(), decompiledCode, skill);
// 5. 保存报告(从Markdown报告中提取根因、严重程度等结构化字段)
// ......
// 6. 更新诊断记录状态
record.setStatus(DiagnosisStatus.COMPLETED.getCode());
// ......
} catch (Exception e) {
failDiagnosis(record, e.getMessage());
}
}
如何集成 Agent 交互页面?
在模型编码期间,我趁空闲查阅了 Spring AI Alibaba 的官方文档,发现它提供了开箱即用的 Agent Chat UI。这让我有了新思路——与其让模型从头生成前端页面,不如直接集成这个现成的交互组件,实现 SSE 流式输出的诊断体验。于是我给了一条非常简短的指令:
根据Spring AI Alibaba官方文档(参考链接https://java2ai.com/docs/frameworks/studio/quick-start:),实现agent智能体交互页面开发工作
我只给了一个文档链接和一句话,模型就自己去读官方文档、理解集成步骤、完成了页面开发。干到第十步还记得第二步定的技术约束——这就是 GLM-5.1 的状态延续能力,长链路执行中始终不丢上下文。

到这里,一个完整的智能诊断 Agent 就构建完成了。为了验收功能,我在本地起了一个 CPU 飙升的测试接口:
@Slf4j
@RestController
public class TestController {
@RequestMapping("cpu-100")
public void cpu(){
while (true){
}
}
}
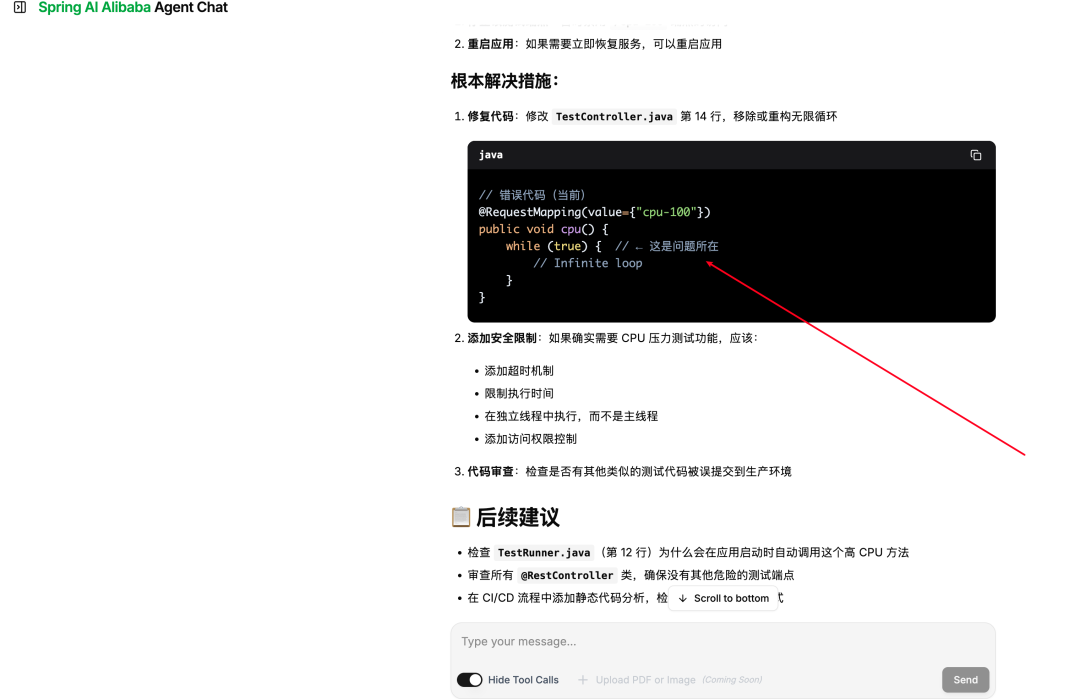
启动 Agent 服务,访问 http://localhost:{应用端口}/chatui/index.html,在聊天框输入:order-service 程序CPU飙升,请协助排查。可以看到 Agent 在收到故障表象后,迅速完成了完整的诊断链路——先通过 Dashboard 获取概览定位到 CPU 占用最高的线程 ID,再基于线程栈帧信息精准定位到问题代码段,最后通过 Arthas 反编译(jad)输出热点代码并生成包含根因分析和修复建议的完整诊断报告。整个过程从输入到报告输出,Agent 全程自主完成,中间没有任何人工介入,SSE 流式输出让每一步诊断进度都清晰可见:
百万级数据量下企业级电商订单服务慢查询治理
如果说任务一验证的是 GLM-5.1 “从 0 到 1 的自主规划能力”,那任务二要验证的就是另一个维度:在一个已有的、有一定复杂度的代码库中,GLM-5.1 能否准确理解既有架构、定位问题、并完成增量优化。 这正是 GLM-5.1 核心能力之一——大代码库自主调试——的最佳试炼场。
慢查询的问题出在哪?
这是一个基于 Spring Boot + MyBatis 的订单查询服务,核心业务围绕订单的查询和分析展开,包含四个接口:
| 接口 |
路径 |
说明 |
| 用户订单查询 |
POST /api/orders/user |
按用户 ID 查询订单列表,支持状态筛选 |
| 订单搜索 |
POST /api/orders/search |
按时间区间+金额+商品关键词搜索订单 |
| 品类销售统计 |
GET /api/orders/category-stats |
按订单状态统计各品类销售汇总 |
| 组合条件筛选 |
POST /api/orders/filter |
按用户+多状态+多品类组合筛选 |
数据库中灌入了百万级测试数据,对应的表结构如下:
CREATE TABLE `orders` (
`id` BIGINT PRIMARY KEY AUTO_INCREMENT,
`order_no` VARCHAR(64) NOT NULL,
`user_id` BIGINT NOT NULL,
`status` TINYINT NOT NULL DEFAULT 0,
`total_amount` DECIMAL(10,2) NOT NULL,
`product_name` VARCHAR(256) NOT NULL,
`category` VARCHAR(64) NOT NULL,
`create_time` DATETIME NOT NULL DEFAULT CURRENT_TIMESTAMP,
`update_time` DATETIME NOT NULL DEFAULT CURRENT_TIMESTAMP ON UPDATE CURRENT_TIMESTAMP,
UNIQUE KEY `uk_order_no` (`order_no`),
KEY `idx_user_id` (`user_id`),
KEY `idx_status` (`status`),
KEY `idx_category` (`category`),
KEY `idx_create_time` (`create_time`)
) ENGINE=InnoDB DEFAULT CHARSET=utf8mb4 COLLATE=utf8mb4_unicode_ci;
项目通过 AOP 切面自动记录每个接口的执行耗时,用于快速定位性能瓶颈:
@Around("controllerPointcut()")
public Object printExecutionTime(ProceedingJoinPoint joinPoint) throws Throwable {
long startTime = System.currentTimeMillis();
Object result = joinPoint.proceed();
long costTime = System.currentTimeMillis() - startTime;
log.info("[{}] {}.{} 耗时: {}ms", Thread.currentThread().getName(), className, methodName, costTime);
return result;
}
我在本地启动服务,向数据库灌入百万级测试数据后,对搜索订单接口进行压测。该接口涉及关键词模糊匹配+时间区间+金额过滤的组合查询,例如下面这个搜索请求:
curl -X POST http://localhost:8080/api/orders/search \
-H "Content-Type: application/json" \
-d '{"startTime": "2025-01-01", "endTime": "2026-12-31", "minAmount": 500, "productName": "蓝牙", "pageNum": 1, "pageSize": 10}'
系统日志直接输出了刺眼的慢查询告警:
[http-nio-8080-exec-1] OrderController.searchOrders 耗时: 18375ms
对应输出结果如下,可以看到本次调测耗时 18375ms,LIKE '%蓝牙%' 的全表扫描导致接口耗时近 18 秒,当前业务接口的实现性能完全无法满足线上要求:

GLM-5.1 如何定位并优化慢查询?
于是我将系统日志中的慢查询告警丢给 GLM-5.1,让其结合项目既有代码完成推理分析和优化方案设计:
针对系统日志中记录的"[http-nio-8080-exec-1] OrderController.searchOrders 耗时: 18375ms"这一慢查询接口问题,对订单业务进行全面梳理分析并提供优化建议。
模型定位到目标业务代码,结合 SQL 和表结构,从索引设计维度给出了系统性的解决方案:

同时它给出了分阶段优化建议和预期效果:

确认方向后,我给出最终优化指令:
请结合项目现有技术栈,对慢查询模块进行系统性优化
模型逐个梳理了每个接口的业务逻辑和查询细节。优化步骤自底向上,从数据库层面一路推进到应用层面,方案涵盖以下几个关键点:
数据库层面——新增 5 个精准索引:
- 全文索引
ft_product_name(ngram 解析器,支持中文分词)替代 LIKE '%xxx%' 全表扫描
- 复合索引
idx_create_time_amount 覆盖时间+金额的 WHERE 和 ORDER BY,避免 filesort
- 覆盖索引
idx_search_covering 让 COUNT 查询不回表
- 组合索引
idx_user_status_category 优化多条件筛选
- 覆盖索引
idx_status_category_amount 优化品类聚合统计
ALTER TABLE `orders` ADD FULLTEXT INDEX `ft_product_name` (`product_name`) WITH PARSER ngram;
ALTER TABLE `orders` ADD INDEX `idx_create_time_amount` (`create_time` DESC, `total_amount`);
ALTER TABLE `orders` ADD INDEX `idx_search_covering` (`create_time`, `total_amount`, `product_name`);
ALTER TABLE `orders` ADD INDEX `idx_user_status_category` (`user_id`, `status`, `category`);
ALTER TABLE `orders` ADD INDEX `idx_status_category_amount` (`status`, `category`, `total_amount`);
应用层面——SQL 和 Service 层同步优化:
LIKE '%xxx%' 替换为 MATCH ... AGAINST 全文检索- 深分页场景自动切换延迟关联(Deferred Join),通过覆盖索引子查询先定位主键再回表
- 按需 COUNT:默认不查总数,仅前端显式传
needTotal=true 时才执行
下面是模型输出的索引优化方案,5 条 DDL 语句全部给出,且每个索引的设计都有明确的优化目标:

从代码 diff 可以直观地看到,模型准确地在既有代码中进行增量迭代,将 LIKE 模糊查询替换为全文检索,同时保留原有业务逻辑不变,确保功能不受影响:
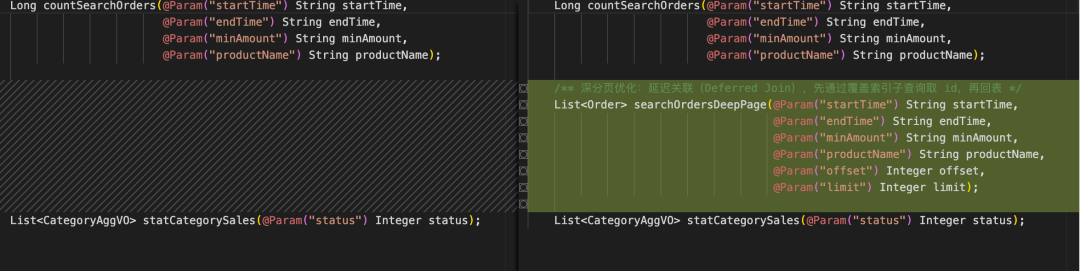
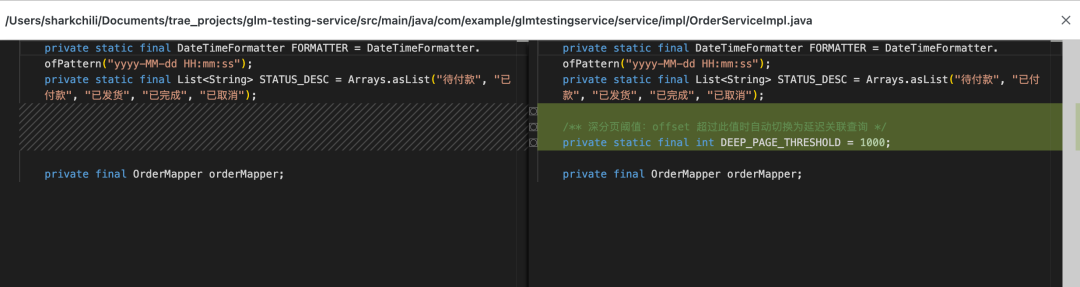
最让我惊喜的是,对于深分页的问题,模型结合当前百万级数据量给出了具体的分页阈值——当 offset 超过 1000 时自动切换为延迟关联查询(Deferred Join),浅分页走普通查询,深分页走覆盖索引子查询先定位主键再回表,在数据库负载和应用性能之间取得平衡:
/** 深分页阈值:offset 超过此值时自动切换为延迟关联查询 */
private static final int DEEP_PAGE_THRESHOLD = 1000;
// 深分页(offset > 1000)走延迟关联,浅分页走普通查询
boolean isDeepPage = offset > DEEP_PAGE_THRESHOLD;
List<Order> orders;
if (isDeepPage) {
orders = orderMapper.searchOrdersDeepPage(...);
} else {
orders = orderMapper.searchOrders(...);
}
这种“先全面梳理业务现状 → 自底向上分阶段优化 → 结合业务体量给出阈值策略”的做法,说明模型确实结合了具体数据量做判断,而不是给一个通用方案。打个比方:大部分模型像一个聪明的应届生,每一步都不差,但你得盯着;GLM-5.1 像一个干了几年的老员工,你给任务就行,它自己能交付。
下面这张截图就是模型针对深分页场景的完整代码实现,DEEP_PAGE_THRESHOLD = 1000 的分页阈值和两条分支查询路径一目了然:
全部优化完成后,模型输出了最终的优化效果总结,涵盖各接口的优化前后对比:

优化后的效果如何?
完成改造后再次对接口进行压测,最终效果如下。可以看到,模型针对既有项目架构准确推断出表设计的最优解,接口经过预热后耗时稳定控制在 300ms 以内,从 18375ms 降至 300ms 以内,性能提升超过 60 倍。 整个过程我们仅仅给出问题,让其完成分析和诊断,我们只负责方案评审,然后让其完成优化。全程没有让我补过上下文,没有在长链路后半程断链——在开源模型中,这种长程稳定性不多见。

榜单与口碑
我前面通过实际体验夸了一波 GLM-5.1,完全是不掺水分的真实感受。如果你不信的话,还可以看看 AI Coding 领域的权威榜单和国外知名开发者的使用感受。
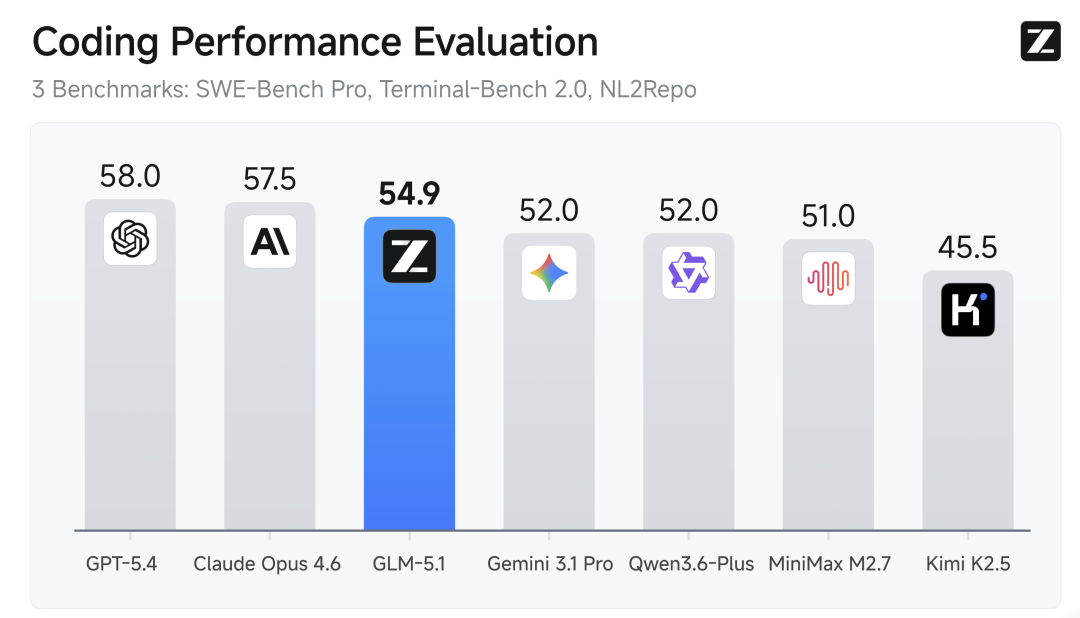
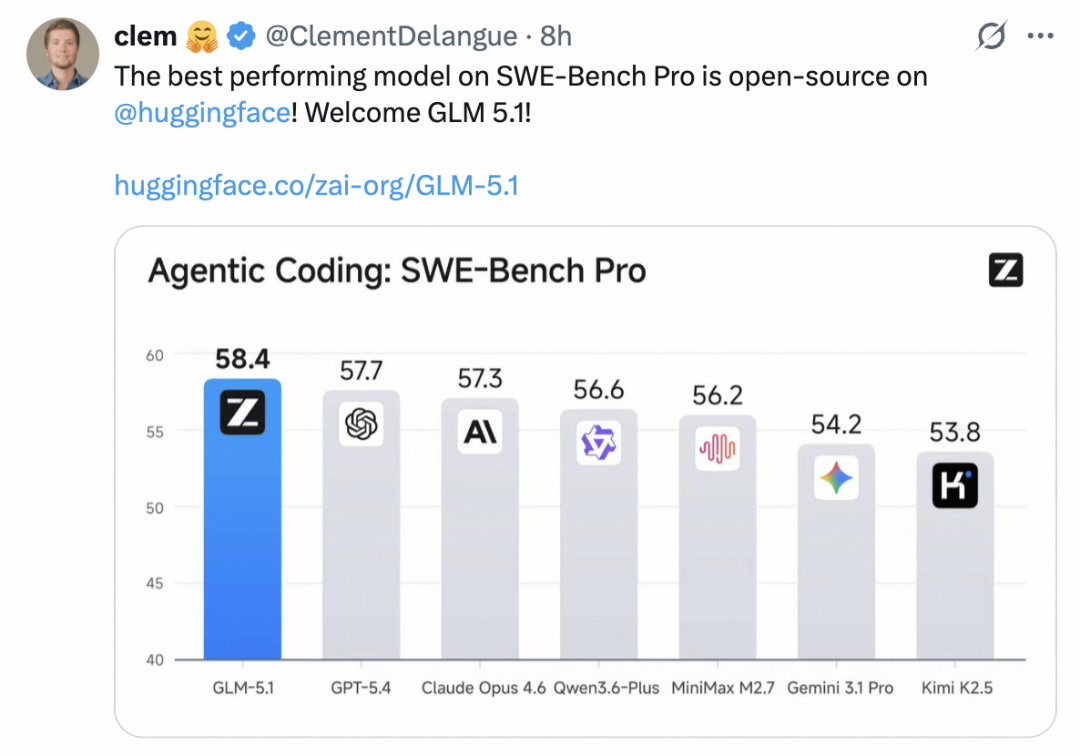
下图为业内最具代表性的三大代码评测基准平均成绩,包括专业级软件开发能力的 SWE-Bench Pro、工程师式命令行操作的 Terminal-Bench 2.0,以及从零构建完整代码仓库的 NL2Repo。
在这三项综合平均分上,GLM-5.1 位列全球模型第三、国产模型第一、开源模型第一。
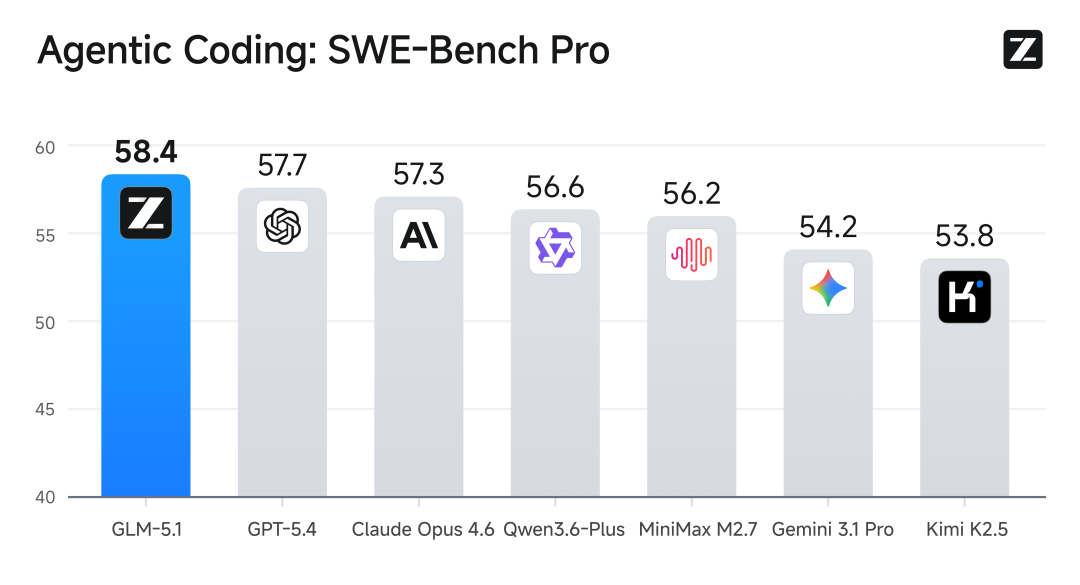
其中,SWE-bench Pro 全球第一,超过 Claude Opus 4.6。
简单科普下 SWE-bench Pro 为什么重要。别的榜单考的是“回答问题”,SWE-bench 考的是“干活”——从 GitHub 上拉一个真实的开源项目,里面藏着真实 bug,模型要自己读几万行代码、定位问题、写修复方案,还要跑通原项目的测试用例。Pro 版更狠,题目更难、评判更严,基本没法刷分。
GLM-5.1 在这个榜单上排第一,它后面是 Claude Opus 4.6、GPT-5.4、Gemini 3.1 Pro。
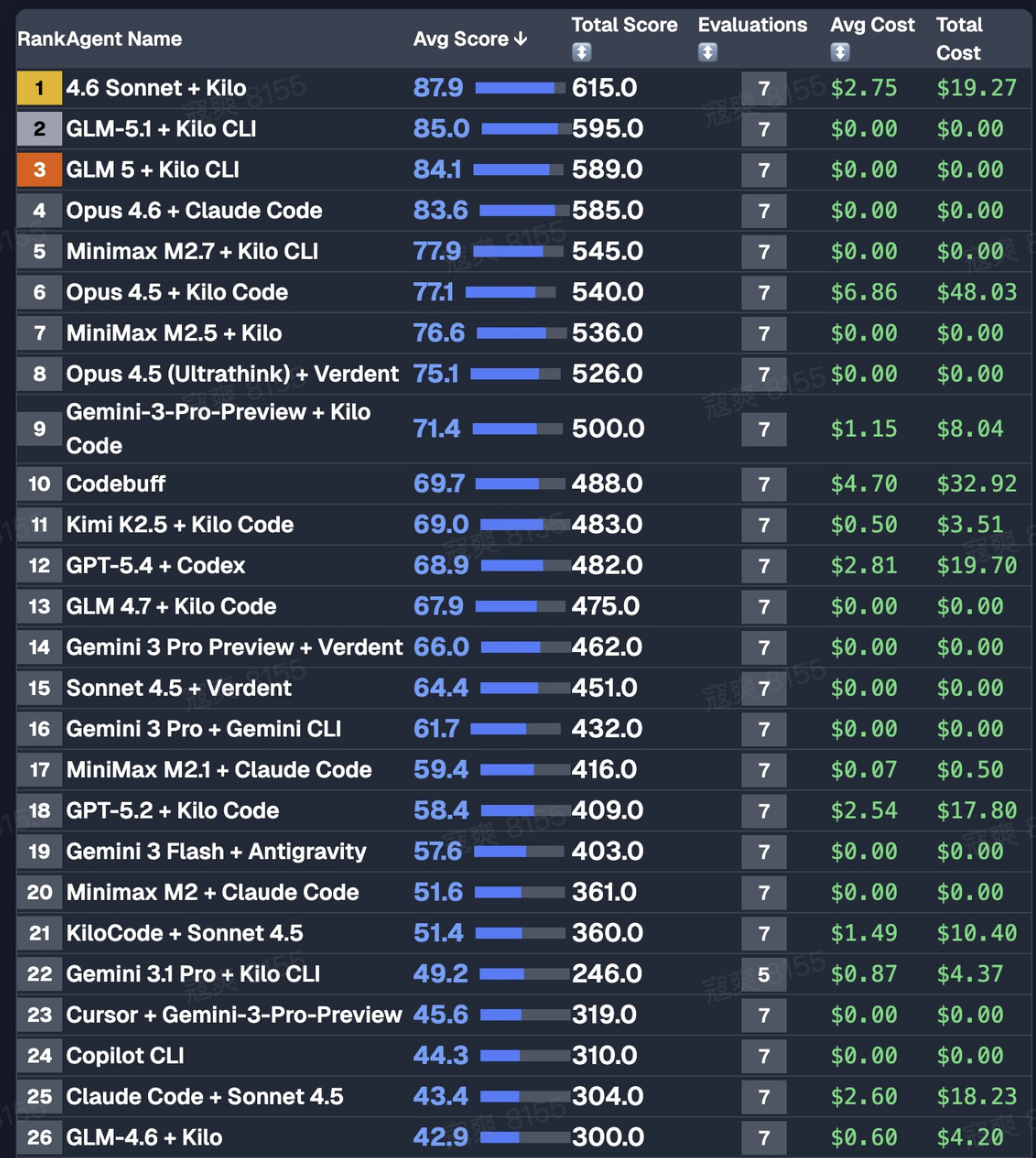
海外社区的反应也很直接——YouTube 博主 AICodeKing 的 King Bench、独立开发者 karminski 的 vector bench,GLM-5.1 都是开源第一。OpenRouter 上调用量断档领先,Reddit 上的反馈集中在长任务稳、工具调用顺,Hugging Face CEO 也发文祝贺其发布。
小结
两个任务跑下来,GLM-5.1 的表现确实超出预期。任务一从零搭建完整的 JVM 智能诊断 Agent,9 个模块 46 个文件全部自主交付;任务二在既有代码库中完成百万级数据量的慢查询治理,接口耗时从 18 秒降到 300 毫秒以内。中间遇到问题它也是自己想办法修的。
这不是 demo 级别的展示,这是可以往生产环境靠的交付物。说实话,做了这么多年开发,第一次在一个开源模型身上感受到“你可以不用管了”这种体验。
回过头来看,整个过程中我做的事情其实只有三件:提出构想、评审方案、验收结果。而真正把构想变成可运行系统的,是模型自己——从技术选型到架构设计到编码落地,一步步完成了方案交付。人提出方向、模型负责交付的模式正在成形。
关于 AI Agent 和 Java 性能优化的更多实践与思考,也欢迎大家在技术社区如 云栈社区 进行深入的交流与探讨。
 发表于 2026-4-9 02:39:43
|
查看: 264|
回复: 0
发表于 2026-4-9 02:39:43
|
查看: 264|
回复: 0
