做后端开发的同学肯定都经历过连接池超时、连接泄漏的线上事故。为什么 Spring Boot 2.0 之后直接把 HikariCP 设为默认连接池?它比 Druid、C3P0 快在哪里?今天我们就从 源码 层面把它的高性能原理掰开揉碎讲清楚,看完你也能处理连接池 90% 的问题。
一、HikariCP 凭啥这么快?先捋清楚核心优化点
HikariCP 的官方压测数据比 Druid 快 2~3 倍,靠的就是极致的极简设计和对性能的彻底榨取。下面几个核心优化点先划重点:
- 无锁并发设计:核心数据结构
ConcurrentBag 用 CAS 代替重量级锁,大幅降低多线程竞争开销。
- ThreadLocal 级别缓存:优先从当前线程的缓存中拿空闲连接,几乎没有竞争。
- 数据结构极简优化:用自定义
FastList 代替 ArrayList,去掉多余的范围校验和遍历逻辑。
- 时钟优化:所有超时判断用
System.nanoTime() 代替 System.currentTimeMillis(),避免时钟回拨问题,同时性能更高。
- 字节码级别优化:编译期用 Javassist 把大量动态代理逻辑直接生成字节码,比 JDK 动态代理快得多。
二、核心数据结构:无锁 ConcurrentBag 设计
HikariCP 的高性能心脏就是它实现的无锁并发容器 ConcurrentBag,专门用来存储连接对象,和普通阻塞队列相比优势巨大:
- 每个线程都有自己的
ThreadLocal 缓存列表,优先从本地拿,无任何锁竞争。
- 全局共享列表用 CAS 操作修改状态,不需要
synchronized 或 ReentrantLock。
- 等待线程用
LockSupport.park() 挂起,连接释放时主动唤醒等待线程,避免空轮询。
核心状态定义非常简单,只有 4 种:
// 空闲状态
private static final int STATE_NOT_IN_USE = 0;
// 使用中状态
private static final int STATE_IN_USE = 1;
// 已被移除状态
private static final int STATE_REMOVED = -1;
// 正在被移除状态
private static final int STATE_RESERVED = -2;
每个连接对象都用原子整型保存状态,所有状态变更都是 CAS 操作,完全无锁。
三、连接获取全流程源码拆解
我们从用户调用 getConnection() 方法开始,一步步走源码流程。下面是完整的流程图:
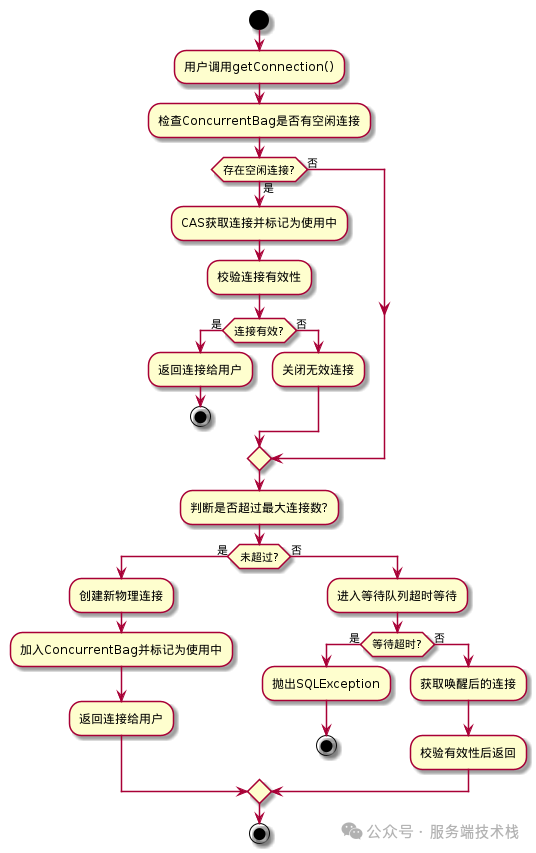
3.1 优先从 ThreadLocal 本地缓存拿连接
第一步完全无锁,直接从当前线程的 ThreadLocal 里拿空闲连接,性能最高:
public T borrow(long timeout, TimeUnit timeUnit) throws InterruptedException {
// 第一步:优先从当前线程 ThreadLocal 缓存获取,无锁操作
List<Object> list = threadList.get();
for (int i = list.size() - 1; i >= 0; i--) {
Object entry = list.remove(i);
T bagEntry = weakThreadLocals ? ((WeakReference<T>) entry).get() : (T) entry;
// CAS 修改状态为使用中,成功就直接返回
if (bagEntry != null && bagEntry.compareAndSet(STATE_NOT_IN_USE, STATE_IN_USE)) {
return bagEntry;
}
}
// 本地缓存没拿到,走全局队列
...
}
注意,这里是从后往前遍历,因为最近归还的连接大概率还在 CPU 缓存里,命中率更高。
3.2 遍历全局共享列表抢连接
本地缓存没拿到的话,就去遍历全局共享列表,用 CAS 抢空闲连接:
// 第二步:遍历全局共享列表抢空闲连接
final int length = sharedList.length();
for (int i = 0; i < length; i++) {
final T bagEntry = sharedList.get(i);
if (bagEntry.compareAndSet(STATE_NOT_IN_USE, STATE_IN_USE)) {
// 抢到了直接返回
return bagEntry;
}
}
这个阶段也没有锁,只是多线程 CAS 争抢,竞争不大的时候性能依然很高。
3.3 没抢到就进入等待队列
如果全局列表也没有空闲连接,同时当前连接数已经达到 maxPoolSize,就进入等待队列挂起,等待超时或者被释放连接的线程唤醒:
// 第三步:没抢到连接,进入等待队列
final long startNanos = System.nanoTime();
timeout = timeUnit.toNanos(timeout);
do {
// 把当前线程的 Parker 对象加入等待队列
final boolean queued = waiters.offer(parker);
while (queued) {
// 挂起当前线程,等待唤醒
LockSupport.parkNanos(this, timeout);
// 被唤醒后重新尝试抢连接
T bagEntry = tryBorrow();
if (bagEntry != null) {
return bagEntry;
}
// 计算剩余超时时间
timeout -= (System.nanoTime() - startNanos);
if (timeout <= 0) {
throw new SQLException("Timeout after " + timeUnit.toMillis(timeout) + "ms waiting for connection");
}
}
} while (timeout > 0);
3.4 连接有效性校验
拿到连接后,HikariCP 会做一个非常快的有效性校验,不会像其他连接池那样发送 select 1 查询,而是用 JDBC4 的 isValid() 方法,直接调用驱动层面的校验,性能高很多:
boolean isConnectionValid(Connection connection, int timeout) {
try {
// JDBC4 原生校验,比 select 1 快几倍
return connection.isValid(timeout);
} catch (SQLException e) {
return false;
}
}
四、FastList:比 ArrayList 还快的自定义集合
HikariCP 没有用 JDK 自带的 ArrayList,而是自己实现了 FastList,核心优化有两点:
- 去掉
get/set 的范围校验:连接池的索引都是合法的,不需要每次都判断下标越界,省掉了分支判断。
remove 方法从后往前遍历:连接池里的连接大部分都是最近归还的,从后往前找更快,而且删除时不需要移动后面的元素,直接把最后一个元素移到删除位置就行。
public boolean remove(Object element) {
// 从后往前遍历,命中率更高
for (int index = size - 1; index >= 0; index--) {
if (element == elementData[index]) {
// 直接把最后一个元素移到当前位置,不需要移动大量元素
final int numMoved = size - index - 1;
if (numMoved > 0) {
System.arraycopy(elementData, index + 1, elementData, index, numMoved);
}
elementData[--size] = null;
return true;
}
}
return false;
}
就这么一个小优化,在连接池频繁增删元素的场景下,性能提升非常明显。
五、生产环境 HikariCP 配置避坑指南
下面是一些生产环境必调的核心参数,帮你避开常见坑:
- maxPoolSize:不要设得太大,一般是「CPU 核心数 × 2 + 磁盘数」的值,最高不要超过 50。连接数太多反而会加剧数据库竞争,导致性能下降。
- connectionTimeout:连接超时时间,建议设为 3000ms,不要太长,避免请求堆积。
- idleTimeout:空闲连接超时时间,建议设为 600000ms(10 分钟),一定要比数据库的
wait_timeout 小,避免连接被数据库主动断开。
- maxLifetime:连接最大生命周期,建议设为 1800000ms(30 分钟),避免长时间连接带来的性能问题。
- leakDetectionThreshold:连接泄漏检测阈值,建议设为 2000ms,超过这个时间还没归还连接就会打错误日志,方便排查泄漏问题。
好了,今天的分享就到这里。HikariCP 能火靠的正是这些极致的性能优化思路,很多设计在我们日常业务代码里也可以复用。连接池超时、泄漏这类问题在实际项目中确实常常碰到,值得大家反复琢磨。
 发表于 2026-5-24 19:23:49
|
查看: 186|
回复: 0
发表于 2026-5-24 19:23:49
|
查看: 186|
回复: 0
