cuDF 作为一个基于 GPU 的 DataFrame 库,旨在为加载、连接、聚合、过滤等数据操作提供强大的平替能力。
cuDF介绍
cuDF 是一个基于 Apache Arrow 列式内存格式的 Python GPU DataFrame 库,用于执行数据加载、连接、聚合、过滤等操作,并且提供了与 pandas 高度相似的 API。
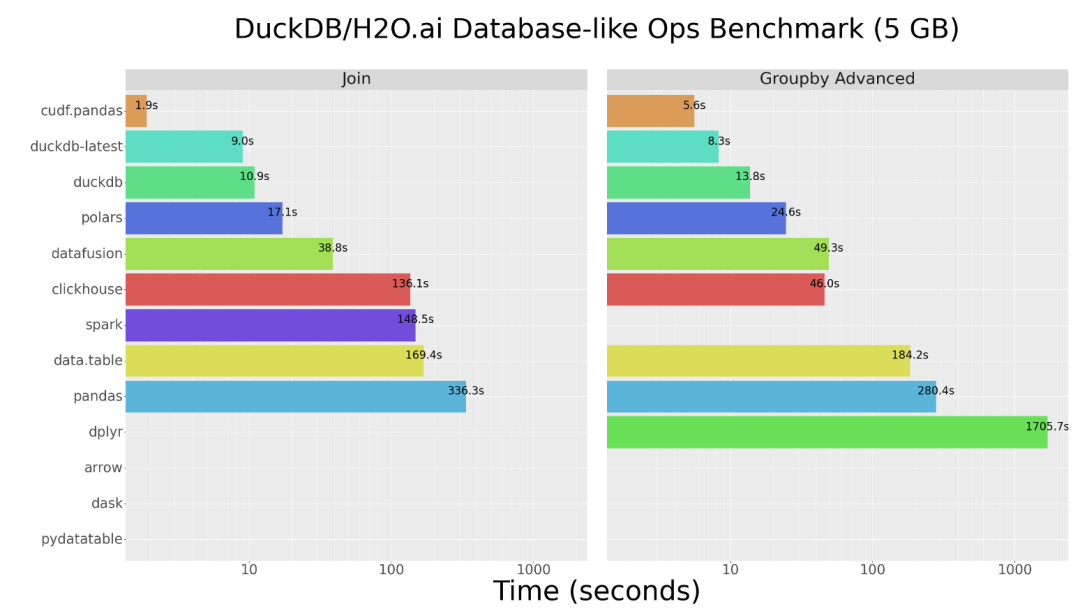
上图展示了在 5GB 数据集上,cuDF.pandas 与其他框架(如原生 pandas、DuckDB、Spark 等)在执行连接(Join)和高级分组(Groupby Advanced)操作时的耗时对比。可以看到,cuDF 凭借 GPU 并行能力,性能显著领先。
GitHub:https://github.com/rapidsai/cudf
Documentation:https://docs.rapids.ai/api/cudf/stable
相关框架介绍
cuDF: cuDF 是一个 Python GPU DataFrame 库,它基于 Apache Arrow 的列式内存格式,用于以类 pandas 的 DataFrame 风格 API 来加载、连接、聚合、过滤和操作表格数据。它允许数据工程师和数据科学家通过熟悉的 API 轻松加速工作流,而无需深入 CUDA 编程细节。其设计目标是在 GPU 上高效处理大规模数据集。
Dask: Dask 是一个灵活的 Python 并行计算库,旨在简化工作流的规模化。在 CPU 上,Dask 利用 Pandas 在多个 DataFrame 分区上并行执行操作,使用户能更充分地利用计算资源处理更大规模的数据,而无需大幅修改代码。
Dask-cuDF: Dask-cuDF 扩展了 Dask,使其 DataFrame 分区能够使用 cuDF GPU DataFrame 而非 Pandas DataFrame 进行处理。例如,调用 dask_cudf.read_csv(...) 时,集群中的 GPU 将通过调用 cudf.read_csv() 来执行 CSV 文件解析工作。这使得能够利用 GPU 上的 cuDF 高性能数据处理能力,从而加速大规模数据任务。
cuDF 和 Pandas 比较
cuDF 是一个与 Pandas API 密切匹配的 DataFrame 库,但直接使用时并非 Pandas 的完全替代品。两者在 API 和行为上存在一些差异。以下是主要对比:
支持的操作:
cuDF 支持许多与 Pandas 相同的数据结构和操作,包括 Series、DataFrame、Index 等,以及它们的一元和二元操作、索引、过滤、连接、分组和窗口操作。
数据类型:
cuDF 支持 Pandas 中常用的数值、日期时间、时间戳、字符串和分类数据类型。此外,cuDF 还支持用于十进制、列表和“结构”值的特殊数据类型。
缺失值:
与 Pandas 不同,cuDF 中的所有数据类型都是可为空的,意味着它们可以包含缺失值(用 cudf.NA 表示)。
迭代:
在 cuDF 中,不支持对 Series、DataFrame 或 Index 进行迭代。因为在 GPU 上迭代数据会导致极差的性能,GPU 专为高度并行操作而非顺序操作优化。
结果排序:
默认情况下,cuDF 中的 join(或 merge)和 groupby 操作不保证输出排序。与 Pandas 相比,需要显式传递 sort=True 或在尝试匹配 Pandas 行为时启用 mode.pandas_compatible 选项。
浮点运算:
cuDF 利用 GPU 并行执行操作,因此操作顺序不总是确定的。这会影响浮点运算的确定性,因为浮点运算是非结合性的。在比较浮点结果时,建议使用 cudf.testing 模块提供的函数,允许根据所需精度进行比较。
列名:
与 Pandas 不同,cuDF 不支持重复的列名。最好使用唯一的字符串作为列名。
没有真正的“object”数据类型:
与 Pandas 和 NumPy 不同,cuDF 不支持用于存储任意 Python 对象集合的“object”数据类型。
.apply() 函数限制:
cuDF 支持 .apply() 函数,但它依赖于 Numba 对用户定义函数(UDF)进行 JIT 编译并在 GPU 上执行。这可以非常快,但对 UDF 中允许的操作施加了一些限制。
何时使用 cuDF 和 Dask-cuDF
cuDF:
- 当您的工作流在单个 GPU 上运行已经足够快,或者您的数据可以轻松容纳在单个 GPU 的内存中时。
- 当数据量不大,可以在单个 GPU 内存中处理时,cuDF 提供了对单个 GPU 上高性能数据操作的支持。
Dask-cuDF:
- 当您希望将工作流分布在多个 GPU 上时,或者您的数据量超过了单个 GPU 内存的容量,或者希望同时分析分布在许多文件中的数据时。
- Dask-cuDF 允许您在分布式 GPU 环境中进行高性能的数据处理,尤其适用于数据集太大无法放入单个 GPU 内存的场景。这在大数据场景下非常有用。
cuDF 代码案例
import os
import pandas as pd
import cudf
# Creating a cudf.Series
s = cudf.Series([1, 2, 3, None, 4])
# Creating a cudf.DataFrame
df = cudf.DataFrame(
{
"a": list(range(20)),
"b": list(reversed(range(20))),
"c": list(range(20)),
}
)
# read data directly into a dask_cudf.DataFrame with read_csv
pdf = pd.DataFrame({"a": [0, 1, 2, 3], "b": [0.1, 0.2, None, 0.3]})
gdf = cudf.DataFrame.from_pandas(pdf)
gdf
# Viewing the top rows of a GPU dataframe.
ddf.head(2)
# Sorting by values.
df.sort_values(by="b")
# Selecting a single column
df["a"]
# Selecting rows from index 2 to index 5 from columns ‘a’ and ‘b’.
df.loc[2:5, ["a", "b"]]
# Selecting via integers and integer slices, like numpy/pandas.
df.iloc[0:3, 0:2]
# Selecting rows in a DataFrame or Series by direct Boolean indexing.
df[df.b > 15]
# Grouping and then applying the sum function to the grouped data.
df.groupby("agg_col1").agg({"a": "max", "b": "mean", "c": "sum"})
总结
cuDF 为熟悉 Pandas 的用户提供了一个强大的 GPU 加速选项,在处理适合 GPU 内存的数据集时,能带来数量级的性能提升。然而,它并非 Pandas 的“无缝”替代品,开发者需要注意其在数据类型、迭代、排序确定性等方面的差异。对于超大规模数据,结合 Dask-cuDF 的分布式能力是更佳的选择。在实际项目中,评估数据规模、硬件条件和具体的 API 兼容性需求,是决定是否采用 cuDF 的关键。想了解更多关于数据处理和性能优化的讨论,可以访问云栈社区的相关板块。
 发表于 2026-4-9 03:23:25
|
查看: 152|
回复: 0
发表于 2026-4-9 03:23:25
|
查看: 152|
回复: 0
