2026年4月7日,Anthropic联合Apple、Google、Microsoft等45家机构发布了Project Glasswing计划。该计划的核心,是其尚未公开发行的前沿模型Claude Mythos Preview,在所有主流操作系统和浏览器中自主发现了数千个0day漏洞,并能全自动完成漏洞利用代码的开发。这一事件让安全界意识到,开源权重模型可能在6个月后追平此能力,届时每个勒索软件团伙都能将漏洞快速、低成本地武器化。漏洞攻防的整条时间链,正被AI技术整体压缩,速度远超大多数人的预期。
几乎在同一时间,朱雀实验室蓝军Bot(一个基于多Agent的自动化漏洞挖掘与攻防演练平台)也在OpenClaw与Linux内核等目标上完成了快速挖掘,累计发现了33个0day漏洞,其中包含17个严重与高危漏洞。这些漏洞已全部提交上游社区修复,并获得了OpenClaw、Linux内核等项目的官方公开致谢。
数字本身并非最关键的。真正值得关注的是,这两起事件指向了同一个结论:安全攻防的下半场,比拼的早已不是“能不能找到漏洞”,而是“谁能先于攻击者,把关键风险识别并暴露出来”。
朱雀实验室报告的多个OpenClaw高危漏洞获得官方致谢
变化的不只是洞的数量,是整个攻防节奏
很多人认为AI只是让发现的漏洞变多了。事实真的如此简单吗?并非如此。真正被重塑的,是漏洞从被引入、被发现、被验证到被武器化的整条时间链。
过去挖掘0day,更像老师傅手工打磨一件兵器,需要深厚的手感和经验,在代码库中长期浸润才能有所收获。如今,这门“手艺”正在被AI Agent批量复制。被改写的远不止漏洞数量,而是整个攻防生态的节奏。
漏洞为什么来得更快?
Vibe Coding时代带来了一个越来越普遍的现实:代码生成速度越来越快,但整体安全性并未同步提升。云安全联盟2026年4月的报告提供了侧证:AI辅助开发后的代码提交速度是传统的3到4倍,但安全风险的发现率却增长了10倍,其中架构设计缺陷更是增加了153%。
大模型擅长避免输出SQL注入这类“经典”漏洞代码,却容易忽略架构层面的系统性安全缺陷。最终进入业务环境的,不只是更多的代码,而是带着“先天缺陷”进入生产环境的代码。
漏洞为什么被更快发现?
知名安全研究员Thomas Ptacek的判断切中要害:漏洞研究中的大量工作,本质就是模式匹配、约束求解和不厌其烦的尝试,这些恰好是大模型所擅长的。过去那些因为不够热门、过于分散、人工审计不划算而“逃过一劫”的目标,现在全都被纳入了自动化扫描的清单。
去年Google的Big Sleep项目能发现传统Fuzzing长时间未能触发的深层问题,这已经不只是效率提升,更是将漏洞发现从“手工作坊”推向了“工业化生产”。而Claude Mythos,则是这条进化路径上最新的里程碑。
企业为什么必须正面接招?
需要警惕的不只是开源维护者应接不暇,更在于外部攻击者也在利用同等的AI能力,进行大规模、自动化的攻击准备。例如,麦肯锡的内部AI平台曾被黑客利用Agent在2小时内全自动攻破——从API测绘、漏洞链利用到数据窃取,甚至直接篡改AI业务平台的System Prompt,整个过程均由机器速度完成。
这就是我们所说的“下半场”。过去的安全团队更像是“定期巡检”,现在则像是在与一条不断提速的“风险流水线”赛跑。而流水线的另一端,是同样在飞速进步的自动化攻击能力。
33个0day漏洞背后:蓝军Bot如何排雷
朱雀实验室从2023年开始研发蓝军Bot,经过多次迭代,最新版本聚焦两条主线:一是AI基础设施的软件供应链漏洞排雷——前述33个0day均已进入公开或修复流程;二是真实业务系统的实战演练——蓝军Bot已在多个重点业务的演习中发现了大量有实际影响的漏洞并协助修复。
软件供应链排雷:先把AI基础设施安全里的坑排出来
像OpenClaw这样的开源AI Agent框架增长迅猛,快速进入企业技术栈,同时其自身又处于沙箱、插件、认证、配置等高风险的“边界”上。一旦部署到真实业务环境,其风险会直接传导至企业的身份体系、敏感配置和整个软件供应链。蓝军Bot的首要目标,就是把这条供应链上最值得优先排除的“雷”找出来。
在短时间内,蓝军Bot累计发现了18个OpenClaw漏洞,其中包含了10个高危漏洞,均已修复并获得了OpenClaw官方的公开致谢。这意味着这些修复不仅保护了腾讯自身的业务环境,更直接回馈给了OpenClaw、Linux、Langflow等开源生态的每一个下游用户。
以下是三个具有代表性的案例,它们各自说明了不同层面的价值:
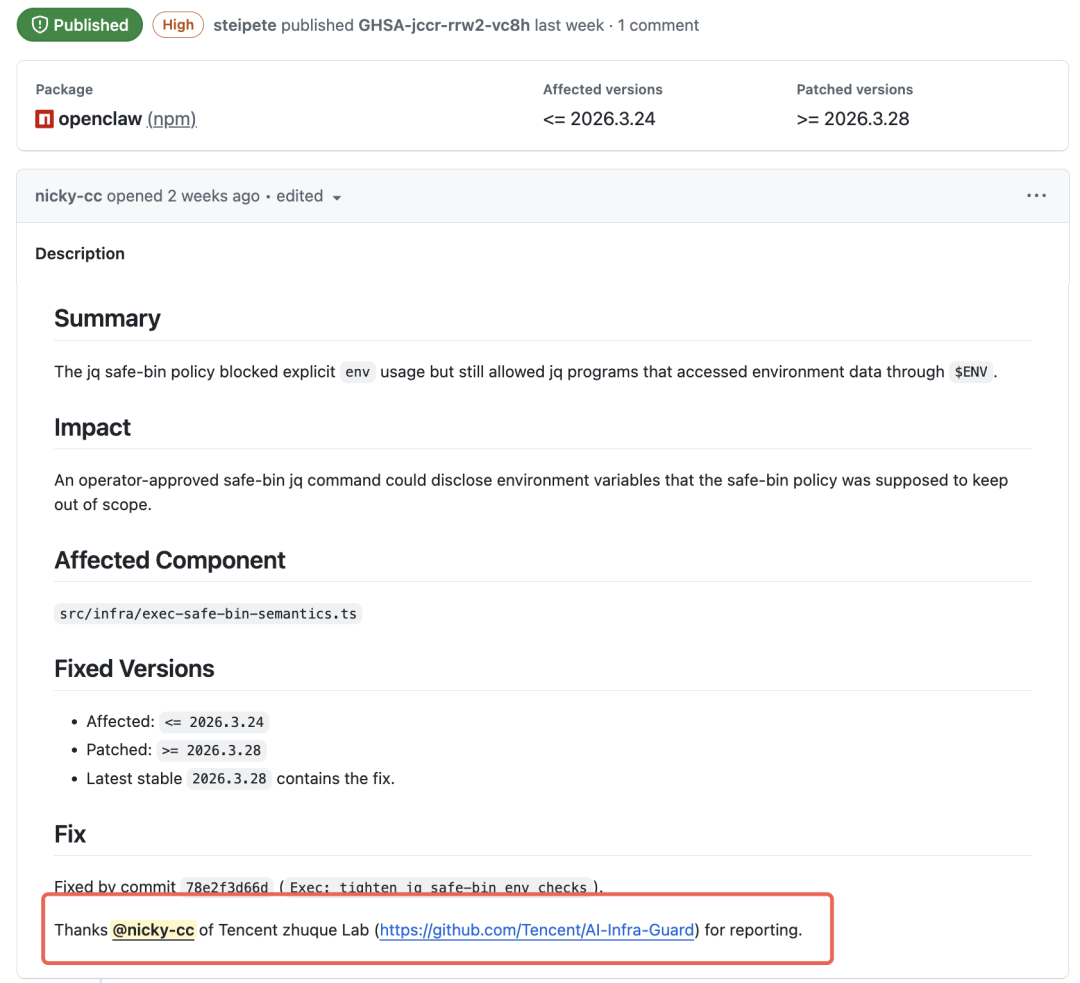
OpenClaw环境变量泄露漏洞(高危,GHSA-jccr-rrw2-vc8h)
OpenClaw是目前最活跃的开源AI Agent框架之一。其真正危险之处在于,一旦部署,便拥有了调用云服务器上各种敏感数据与工具权限的能力。这个漏洞的根源在于其jq safe-bin策略存在逻辑缺陷:它禁用了env关键字来防止数据泄露,却遗漏了jq内置的$ENV对象,导致攻击者可以绕过安全策略,读取服务器环境变量中的配置信息与密钥(如AK/SK、Git凭证、模型API Key等)。该漏洞已获官方致谢,安全补丁已合入主线。
Langflow Agentic Assistant执行链漏洞(严重,CVE-2026-33873)
这个漏洞的有趣之处在于,它属于AI功能链本身的新型风险:Agentic Assistant的验证阶段会直接执行LLM生成的Python代码,已认证的用户无需管理员权限即可通过影响模型输出的方式,在服务端执行任意代码。它揭示了一类通用Agent框架共有的新风险——模型输出、工具调用和执行环境之间的安全边界被意外打通。
Linux内核Bluetooth漏洞(高危,CVE-2025-39981/39982)
这是蓝牙MGMT模块的use-after-free漏洞,在竞态条件下pending结构被提前释放,可导致内核崩溃乃至权限提升,直接影响服务器的可用性与数据安全。针对Linux内核这种被全球安全团队反复审计多年的目标,蓝军Bot结合了Agent的代码理解能力与Fuzzing框架的针对性优化,提升了底层内核漏洞的挖掘能力。这些补丁已合入Linux内核主线。
这三个案例覆盖了三层防护:热门AI框架的上游风险排除、通用Agent生态的风险预警、底层操作系统的供应链加固。它们的共同点是:每一个修复都通过负责任的漏洞披露流程回馈到了开源社区,惠及全球开发者。
真实业务系统实战演练:把自动化渗透测试能力打进业务现场
除了在供应链上游排雷,将自动化能力应用于企业内部实战同样至关重要。
朱雀蓝军Bot已在腾讯内部多个业务系统的演习中落地使用。由于每个潜在漏洞都经过了自动化验证,极大地降低了蓝军专家的人工介入成本。
此外,为了与同类工具进行对比,朱雀蓝军Bot在XBOW Security Benchmark的104个挑战中,成功完成了102个(成功率98%),其表现超过了热门开源AI渗透项目Shannon,在基础覆盖率上也超越了传统人工黑盒测试的水平。

这些成果背后,是蓝军Bot 4.0的Agent Teams和Harness Engineering体系在支撑。目前这套方案已在黑盒、白盒和真实业务环境中稳定运行。尽管复杂漏洞的自动化利用仍有难题待解,但每一轮模型与工程体系的升级,都在让自动化能力的“放大效应”更加显著。这种将前沿研究转化为稳定、可用的工程能力的过程,正是技术落地的关键。
安全攻防下半场的三个判断
1. 漏洞“货架期”快速缩短,传统安全演习节奏已无法覆盖风险
过去,一个漏洞从被引入到被发现,缓冲期可能长达数月甚至数年。如今,这个窗口正在急剧压缩:Mythos挖出了存在10到27年的高危漏洞,而这些漏洞历经全球团队多年审计、数百万次Fuzzing都未被发现;安全公司CrowdStrike的判断更为直接——漏洞从被发现到被利用的窗口,已从“数月”缩短至“数分钟”。
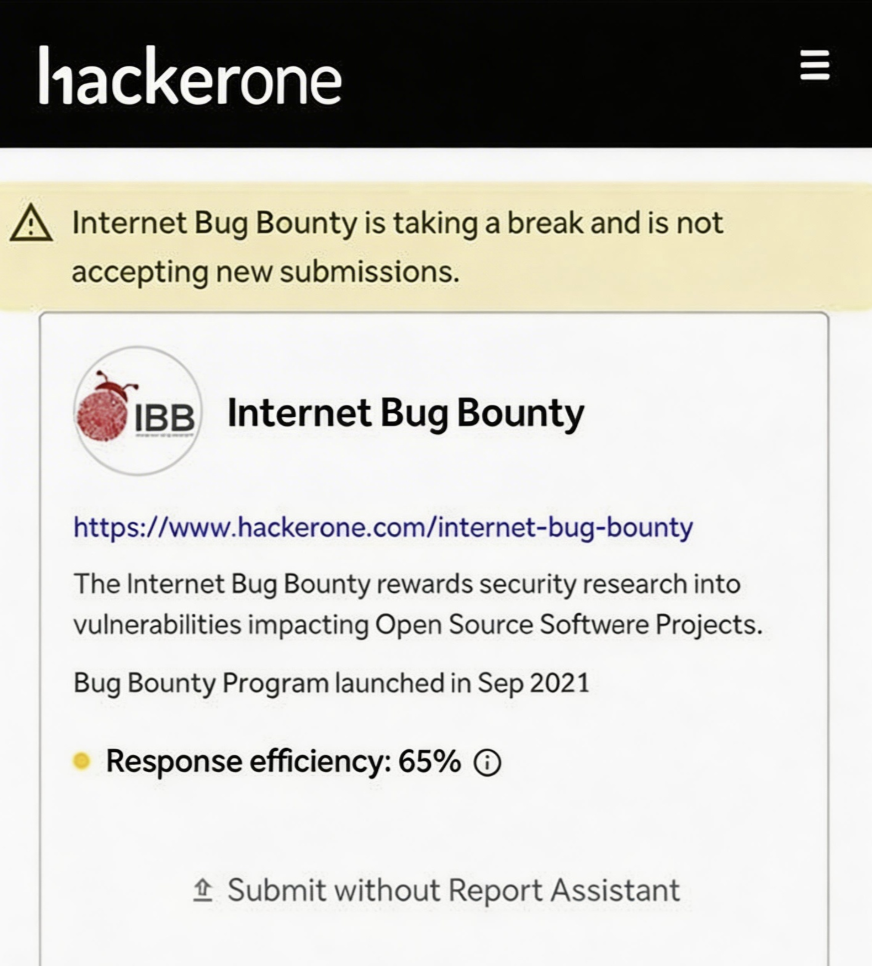
HackerOne IBB暂停接收报告、Google叫停AI提交漏洞、cURL关闭赏金通道,这些信号指向一致:漏洞的发现速度,已经快过了旧有的接收与处理链路。当外部攻击者也能用AI持续扫描你依赖的每一个开源组件,甚至将发现、验证、利用准备串成自动化流程时,企业自身的前置发现能力就必须跟上。否则,攻击者永远会先你一步。
2. “能找到洞”越来越不稀缺,差距在谁能更早、更准地打出有价值的结果
发现漏洞的门槛正被AI大幅拉低。Thomas Ptacek说得直接:现在所有人都拥有了一个“通用的拼图求解器”。未来,最不值钱的或许就是“我又扫出一堆漏洞”这类消息。
但这并不意味着能力差距消失了。真正的差距体现在:谁能更早锁定最具价值的目标?谁能将发现结果转化为必须被认真对待的“可信输入”?Anthropic发布Glasswing时的做法就遵循这一逻辑:将最先进的能力优先交给45家核心厂商与防御方,让它们在攻击者获得同等能力前,完成关键基础设施的排查与加固。
这套“防御者先手”的思路,与朱雀实验室的实践不谋而合——先于攻击者将关键风险暴露出来,帮助业务加固,同时通过负责任的披露,提升整个开源生态的安全水位。这正是技术社区价值的体现,我们也在云栈社区持续关注和讨论此类前沿实践。
3. AI拉低了找洞门槛,但安全专家的判断力和工程化能力依然稀缺
很多人看到AI能批量找漏洞,第一反应是普通人是否也能带着Agent“下场”了。能下场,但很难打出真正有价值的结果。因为真正的难点,从来不只是“把问题扫出来”。
同一个大模型,搭配不同的任务编排与控制体系(Harness),效果可能天差地别。Anthropic自己的数据就是例证:Opus 4.6模型“裸跑”进行漏洞利用开发的成功率接近零,但在专家设计的Harness指导下,却能成功利用FreeBSD NFS的远程代码执行漏洞。朱雀蓝军Bot从1.0到4.0的进化同理——能力的跃迁不只因为换了更强的模型,更因为其Harness从单Agent“裸跑”进化到了全自主的多Agent编排体系。
扫出问题只是起点,Harness背后所体现的专家判断力,集中在三件事上:
- 选对方向。 我们优先审计OpenClaw,并非只因它热门,更因为它已进入众多企业的技术栈,其沙箱、插件、认证边界本身就是高风险攻击面;将Linux内核纳入目标,则因为它是业务与终端无可替代的底层依赖。真正的能力不在于目标越多越好,而在于知道“先打哪里最有价值”。
- 从点打到面。 普通人使用Agent常局限于“扫到一个报一个”。Mythos给出了行业级示范:自主将3-4个内核漏洞链成完整提权链,把4个浏览器漏洞串成从JIT heap spray到沙箱逃逸的全链条利用。蓝军Bot在OpenClaw的审计中,同样做到了对关键攻击面的持续深挖与系统性覆盖——18个漏洞不是18次独立扫描的结果,而是顺着同一类防护机制持续进攻的产出。
- 严格验真。 AI能产出大量“像漏洞的东西”,但并非都值得进入修复流程。Anthropic在Glasswing中用最强模型扫出数千个0day后,仍要求专业安全承包商进行人工审核。我们的33个0day能全部获得上游项目官方确认与致谢,依靠的正是将验证标准与交付结果做得足够准确、严格。这也是为什么这些修复能被社区快速采纳,真正转化为整个生态的安全收益。
我们相信,朱雀蓝军Bot的这次实践只是一个开始。当AI拉低了“找漏洞”的门槛,真正能拉开差距的,是谁更懂得让Agent“去打哪里、打多深、如何稳定可控地打、哪些结果值得交付”。能驾驭AI、能把前置风险发现做得更早、更准、更贴合业务场景的安全团队,将成为企业在AI时代“跑得更快”的同时,也能“跑得更安全”的关键保障。
 发表于 2026-4-10 02:05:20
|
查看: 173|
回复: 0
发表于 2026-4-10 02:05:20
|
查看: 173|
回复: 0
