项目卡片
|
|
| 项目 |
santifer/career-ops |
| Star |
9.2k(3 天内) |
| 技术栈 |
Claude Code / Node.js / Go / Playwright |
| 许可 |
MIT |
| 一句话 |
不是海投工具,是帮你从几百个职位里筛出那几个值得投的 |
最近,一个名为 Career-Ops 的 开源实战 项目在 GitHub 上火了,发布仅三天就收获了超过9000颗星。开发者 Santiago Fernández 开源了他的个人求职系统,其核心思路并非创造新产品,而是巧妙地将 Claude Code 转化为一个全自动的求职处理流水线。
这套系统覆盖了职位发现、结构化评估、定制简历生成和面试准备的全流程,但最终的投递决策权依然牢牢掌握在用户手中。更关键的是,它有实战成果背书——经过对740多个职位的评估,生成了100多份定制简历,最终帮助作者斩获了 Head of Applied AI 的 Offer。
核心痛点:告别低效海投
刷招聘网站时,最耗时的往往不是投递简历本身,而是反复判断“这个职位到底值不值得投”。特别是当你同时关注十几家公司、每个公司又有多个开放岗位时,一天下来可能浏览了几十个职位描述(JD),真正决定投出去的却寥寥无几。
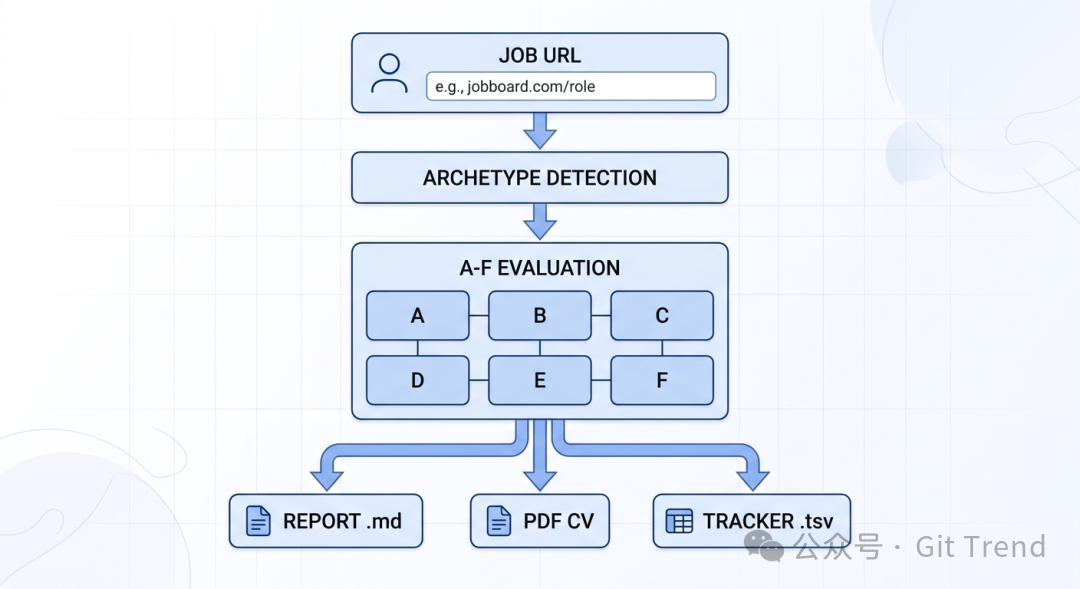
Career-Ops 的解决方案简洁有力:通过一组斜杠命令覆盖求职全流程。其核心理念非常明确:这是一个精准的过滤器,而非盲目扫射的大炮。 系统会对职位进行严格打分,评分低于 4.0/5 的会明确建议你不要投递。
评估系统:A-F六维度深度解析
Career-Ops 的核心能力在于其结构化的评估体系。它不会只给你一个模糊的“匹配度80%”,而是将每个职位放入6个维度(A-F)进行拆解,每个维度都会产出具体、可操作的内容:
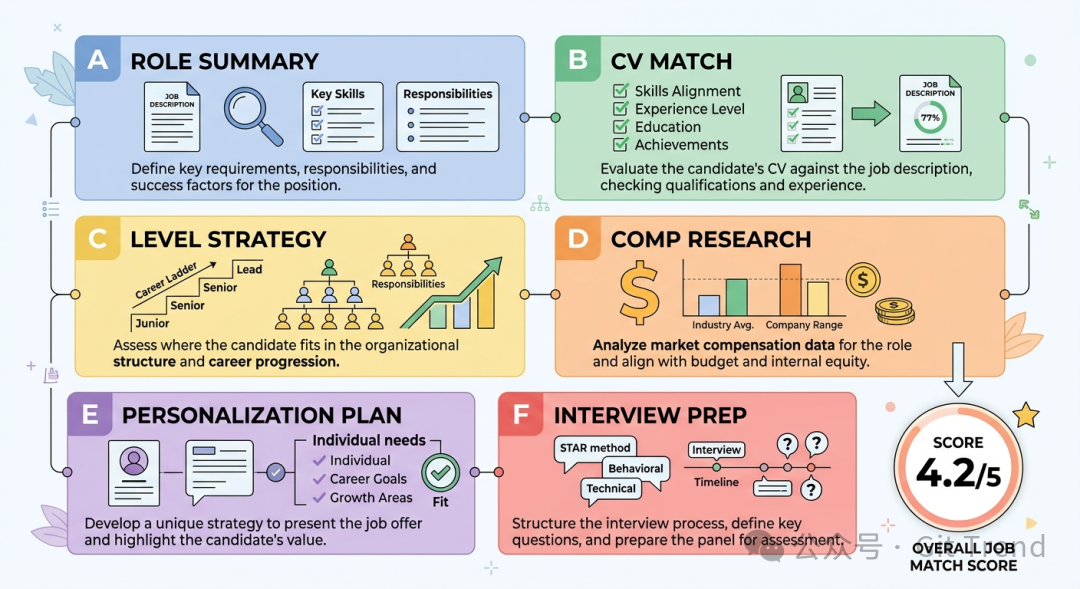
- A 角色摘要:自动检测职位原型(如 LLMOps、Agentic、产品经理、解决方案架构师等)。
- B CV 匹配:逐条对照 JD 要求与你的简历经历,不仅标注差距,还会指明是硬性要求还是加分项,并给出具体的弥补策略。
- C 级别策略:分析职位级别与候选人资历的匹配度,制定“凸显资深经验但不夸大”的沟通策略。
- D 薪资调研:通过 WebSearch 自动查询当前市场薪资数据,提供参考范围。
- E 简历定制:生成排名前5的简历修改建议和 LinkedIn 资料调整建议。
- F 面试准备:运用 STAR+R 方法,将你的过往经历映射到 JD 的具体要求上,帮你积累可复用的面试故事库。
例如,B模块会精确引用你简历中的某一行来证明与某项要求的匹配;F模块的 STAR 故事会明确标注对应了 JD 中的哪一条要求。所有维度加权计算后,给出1-5分的综合评价。4.5分以上强烈推荐,3.5分以下建议跳过,中间的灰色地带则留给个人判断。
值得关注的工程设计与实现
- 清晰的数据契约:项目文件明确分为用户层和系统层。你的个人简历(
cv.md)、档案(profile.yml)和追踪数据永远不会被系统自动覆盖;而模式文件、脚本和模板等系统层文件则可以安全升级。这简单有效地解决了“升级工具却丢失个人数据”的痛点。
- 自我改进机制:每次评估后,如果你给出反馈(如“这个评分太高了”或“你忽略了我的某段经验”),背后的 人工智能 模型(Claude)会更新对你的理解,并调整后续的评分逻辑。就像一个逐步了解你的猎头顾问。
- 高效的批处理:使用
claude -p 进行并行处理。每个工作进程都会获得完整的批处理提示词(batch-prompt.md)作为上下文,独立产出评估报告、定制PDF简历和追踪记录。通过有状态文件(batch-state.tsv)追踪进度,支持断点续跑和失败重试。
- 终端友好的仪表盘:使用 Go 语言的 Bubble Tea 和 Lipgloss 库构建了终端用户界面(TUI),采用 Catppuccin Mocha 主题。支持6个过滤标签、4种排序方式以及懒加载报告预览,提供纯终端操作体验。
智能扫描器:45+公司职位一键发现
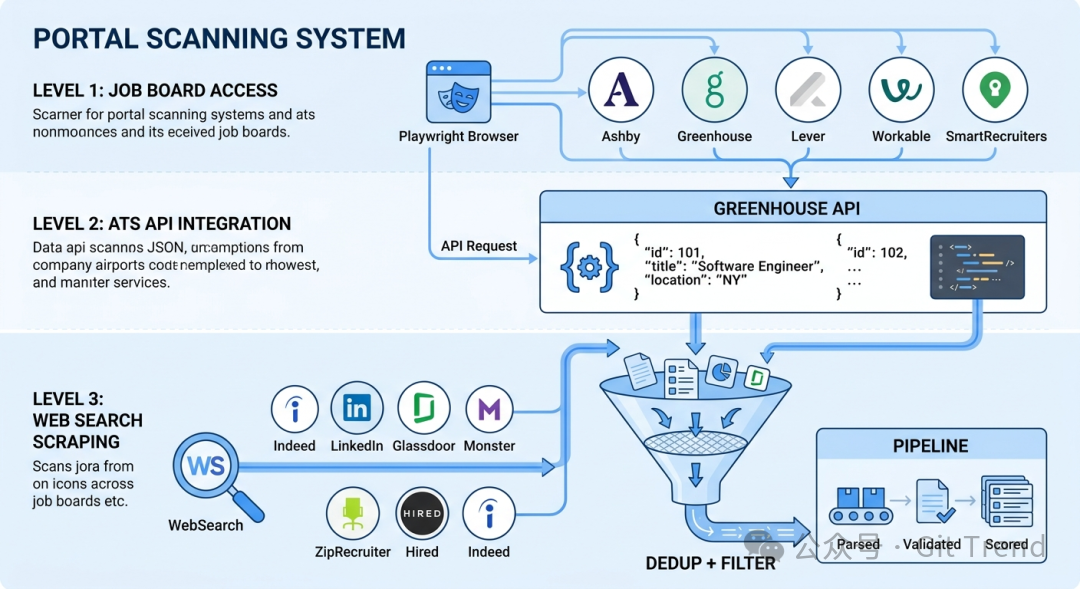
项目的 Portal Scanner 模块是发现新职位的主力。它预配置了45家以上的科技公司(包括 Anthropic、OpenAI、Mistral 等),覆盖 Ashby、Greenhouse、Lever 等主流招聘平台。
扫描策略分为三层,按优先级执行:
- Playwright 直接访问:通过浏览器自动化实时抓取公司招聘页面。
- Greenhouse JSON API:直接调用API快速获取结构化职位数据。
- WebSearch 跨平台查询:进行更广泛的网络搜索以发现新机会。
三层获取的结果会混合、去重,并根据预设关键词进行过滤,新发现的职位会自动进入待评估队列。
快速上手指南
上手体验非常简单,如果你熟悉 Node.js 和命令行,几步就能跑起来:
git clone https://github.com/santifer/career-ops.git
cd career-ops && npm install
npx playwright install chromium
# 配置个人档案
cp config/profile.example.yml config/profile.yml
# 创建 cv.md 并写入你的简历内容
claude # 在项目目录打开 Claude Code
在 Claude Code 界面中,你只需要粘贴职位 URL 或 JD 文本,系统便会自动运行完整的处理流水线。项目设计上也鼓励你直接与 Claude 对话来进行定制,比如修改角色原型、调整评分权重或添加心仪的目标公司列表。
适用场景与注意事项
适合谁用:正在积极寻找 AI 或技术类岗位、每天需要浏览大量 JD、并且在“投与不投”之间反复纠结的求职者。尤其适合需要同时管理多家公司、多个岗位申请流程的人。
前提条件:需要拥有 Claude Code 订阅。评估质量高度依赖于你提供给系统的个人信息——简历越详细,个人偏好越明确,系统的评分和建议就越精准。作者也坦承,前几次的评估结果可能不尽人意,因为系统还需要时间“了解”你。
当前局限:扫描器依赖 Playwright 进行浏览器自动化,需要登录才能访问的页面可能无法抓取。在纯批处理模式下无法使用 Playwright,JD提取会降级为 WebFetch。薪资数据的质量受限于 WebSearch 的结果。现有的模式文件主要覆盖AI相关岗位,其他领域需要用户自行定制角色原型。
总结
Career-Ops 本质上是一个强大的决策支持系统。它帮你完成繁琐的信息收集、结构化分析和准备工作,明确告诉你:该重点投哪个、简历该怎么改、面试应如何准备。但它把最终的决定权——那一下“投递”按钮——完全留给了你自己。这种“人机协同”的思路,或许才是智能工具提升效率的正确打开方式。对这类结合具体场景的AI应用实战感兴趣的朋友,也可以到 云栈社区 交流探讨更多案例。
 发表于 2026-4-10 03:42:47
|
查看: 148|
回复: 0
发表于 2026-4-10 03:42:47
|
查看: 148|
回复: 0
