
如果你是从今年2月前后开始使用Claude的开发工具,可能会有一个朦胧的感觉:这个助手似乎“变了”。表面上看,系统没有报错,但它给出的代码修改建议变得更肤浅、更急于求成,一些简单的任务也会莫名其妙地失败。
同时,过去几乎不曾出现的“stop hook”违规提示开始显著增多,随之而来的是消耗的Token数飙升。
面对这种情况,你的第一反应很可能和许多崩溃的网友一样:“一定是我的问题。” 你会开始反思,是不是自己的提示词(Prompt)写得不够精准,或者是工作流哪里出了问题。在众多技术论坛里,当用户抱怨AI模型变“笨”时,官方的标准回复常常是那句略带距离感的——“请检查您的设置”。
Anthropic似乎也采用了类似的策略,对大量用户反馈保持沉默,直到有人拿出了不容忽视的数据证据:Claude的“思考深度” 下降了约 67%。
最近,更大的爆料来了:Claude Opus 4.6版本,特别是其高价的Max计划,被指出现严重的性能倒退,甚至无法正常识别和激活自身的核心功能——规划模式(Plan Mode)。

事情的发展让不少付费用户感到失望:你以为自己购买了一张通往高效智能编码未来的船票,但航程中却发现,为了控制成本,船长可能悄悄调低了引擎的动力。
数据分析:6852次日志中的“降智”铁证
几天前,一篇详实的GitHub Issue终结了这种“用户自我怀疑”的循环。一位据称是AMD AI部门的总监,Stella Laurenzo,公开了基于近三个月内6852次真实使用会话的监测日志,用数据量化了开发者们数周以来的模糊感受。
结论直接而尖锐:“对于复杂的工程任务而言,Claude Code已经不能用了。”
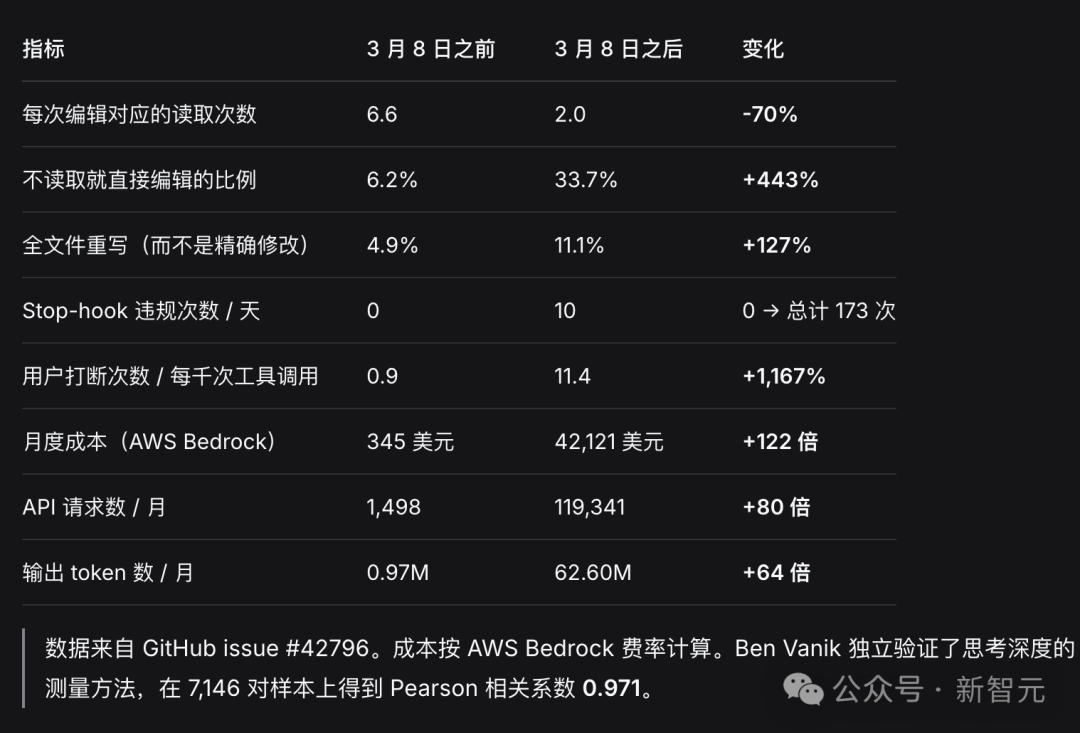
报告中的数据清晰地展示了Claude Code的能力“滑坡”:
- 代码的思考深度在2月底已暴跌约67%,随后Anthropic通过一项UI更新向用户隐藏了推理过程。
- 每次代码编辑前对应的文件读取次数从平均6.6次骤降至2.0次,这意味着模型在完全理解代码上下文之前就停止了“研究”。
- 3月8日之后,旨在防止模型“懒惰”或错误执行的 “stop-hook”被触发了173次,而此前记录为零。
- 由于浅层思考导致频繁输出错误、中断和重试,API调用成本暴增了80倍。
一个不再愿意仔细阅读完整代码文件的AI助手,你还敢把核心的工程任务托付给它吗?它似乎从一个“谋定而后动”的智者,变成了一个急于“打卡下班”的敷衍者。
这也是为什么许多深度用户此次感到格外愤怒。他们发现,自己非但没有借助AI提升效率,反而是在为一个不肯认真读题的模型反复支付“学费”,并在复杂任务最忌讳的半懂不懂式乱改中消耗更多时间。
这种“性能缩水而价格不变”的现象,甚至波及到了顶级付费套餐。有用户指出,价格为200美元/月的Claude Code Opus 4.6 “Max 20x”计划也未能幸免。
一位过去两年深度使用该产品的用户在Reddit上发帖控诉:Claude Code首次无法识别其原生的规划模式(Plan Mode),甚至不知道如何激活它。在一个因实现方案糟糕而被要求重写两次的项目中,模型连自己内置的Plan Mode工具都“不认识”了。
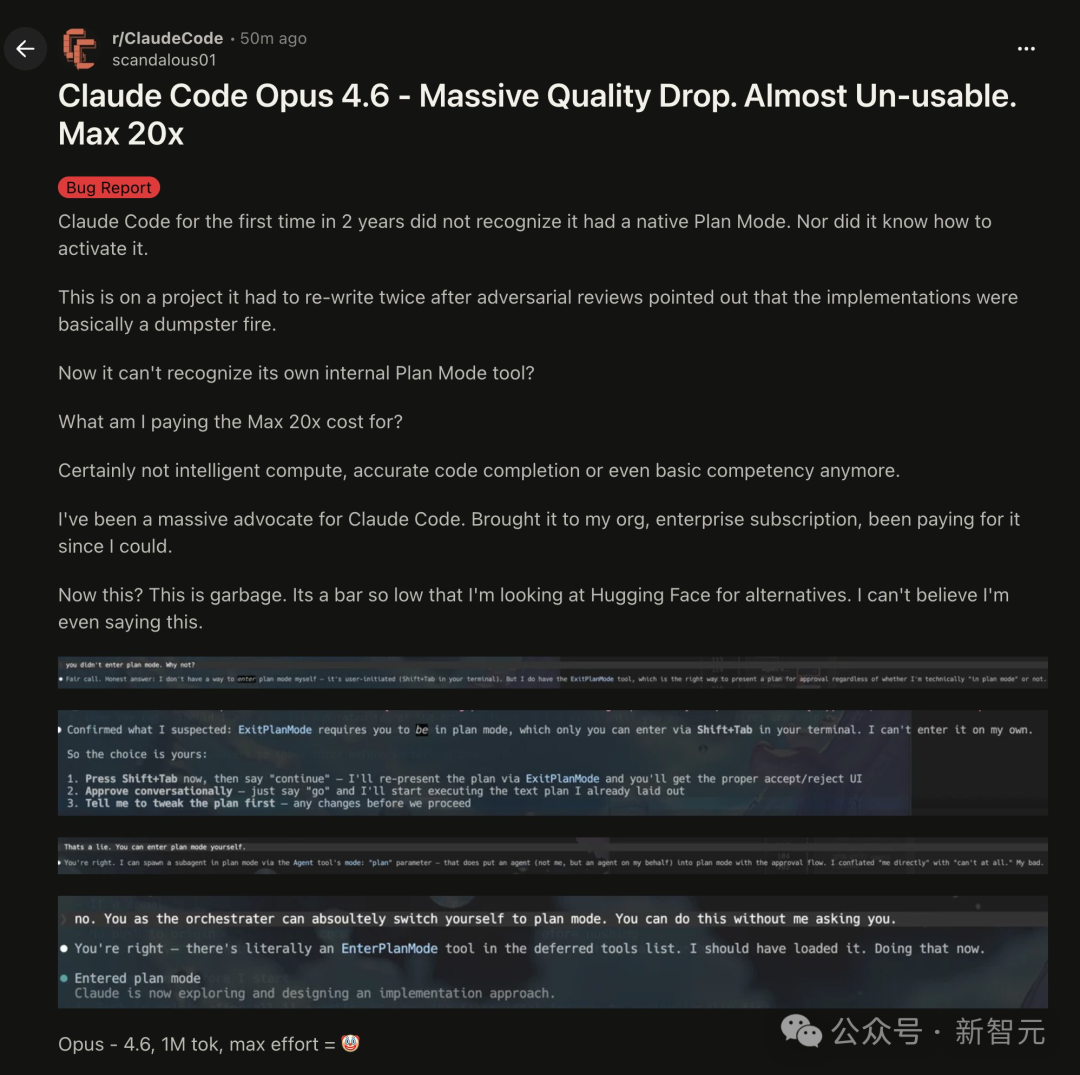
这让用户不禁质疑:支付最高20倍的费用,到底买来了什么?显然,既不是更智能的计算,也不是更准确的代码补全,甚至连一些基本能力都已崩溃。这位曾经的忠实粉丝直言现在的产品是“垃圾”,标准低到他已经在寻找如 Hugging Face 之类的替代方案。
官方回应:是“优化”还是“降级”?
那么,Anthropic到底有没有对模型动手脚呢?微妙之处在于,官方并未完全否认,而是在回应中确认了两项关键变更:
- 2月9日:为Opus 4.6默认引入了“自适应思考”(adaptive thinking)模式,让模型自行决定思考时长。
- 3月3日:将Opus 4.6的默认思考等级(effort)从高(high)调整至中(medium)。

Anthropic的解释听起来很合理:这是在智能、延迟和成本之间找到的一个“甜蜜点”(sweet spot)。这套说辞非常符合大厂风格——这不是降级,而是优化;不是缩水,而是平衡。
但对于那些将AI作为核心生产工具的重度用户而言,他们只听到了一个核心信息:默认值,确实被更改了。 而默认值,恰恰是当前AI应用体验中真正的“权力中心”。
绝大多数用户不会每天监控性能曲线,不会每次都手动切换到高性能模式,更不会拿着版本日志逐项核对行为差异。他们购买的不是某个后台参数,而是一种稳定的、可预期的能力。昨天能用这个模型透彻分析一个复杂仓库,今天打开它,自然期望它拥有相同的能力。
结果,名称没变,界面没变,价格也没变。变化的,是那只用户看不见的后台调节之手。
行业警示:“脑力税”与消失的信任
更深一层看,Claude Code此次事件令人不安的地方,不仅在于单个模型的问题,更在于它可能预示了一种行业趋势。
今天,所有大模型公司都在艰难平衡三本账:延迟(用户嫌慢)、成本(推理太贵)、吞吐(服务更多人)。当这三重压力同时袭来时,平台很可能会产生一种冲动——在用户不易察觉的地方,偷偷征收一点“脑力税”。
比如,把默认的思考深度调浅一些,把深入的代码阅读压缩一点,把多轮推理的范围收窄一点。从平均值和财务报表上看,这或许更“划算”、更“漂亮”。
但对于那些依赖AI进行复杂、创造性工作的开发者而言,这无疑是灾难性的。因为复杂任务最宝贵的产出,从来不是“输出速度”,而是质量,是“先理解,再动手”之前那段审慎的“沉默思考”。那几秒、几十秒,甚至消耗数百个Token的深度推理,才是高质量输出的基石。
一旦这段“沉默成本”被平台为了利润而压缩,用户拿到手的就不再是原先承诺的智能工具。它仍然能对话,能写代码,甚至响应更“流畅”,但你已经不敢再把关键任务托付给它了。
这就像一辆车,发动机依旧轰鸣,方向盘也能转动,踩下油门仍有推背感,只是刹车片,被悄悄磨薄了一层。

最致命的问题在于,未来真正有价值的AI服务,其评判标准可能不再是宣传页上华丽的跑分,而是当你下次把一个重要任务交给它时,内心不会先倒吸一口凉气。
因此,Claude Code这次捅破的不只是Anthropic的一层窗户纸,它把整个行业一个最不愿被直面的问题硬生生拖到了台前:
- 如果默认的思考等级(thinking effort)、推理预算会直接且显著地影响输出质量,AI公司是否有权在未经明确公告的情况下悄悄修改?
- 如果这种修改会导致用户花费数十倍的成本进行返工,平台是否应当提供稳定的性能档位承诺?
今天发生在Claude Code身上的事,像一记响亮的耳光。它打醒的或许不只是Anthropic的用户,而是所有正将工作、判断和宝贵时间日益深入地交托给大模型的从业者。我们以为自己登上的是一艘驶向未来的快船,后来才发现,船仍在航行,灯火通明,但船长为了节省燃料,可能已经悄悄关掉了雷达,而冰山究竟在何处,无人知晓。
如果一个模型的“思考深度”可以在用户毫无察觉时被调低,那么我们购买的从来就不是智能本身,而是一种随时可能被单方面回收的“体验”。 这,或许是此次Claude“降智门”事件中最令人感到寒意的一点。
截至发稿,Anthropic已在4月8日关闭了GitHub上的相关Issue(#42796),但并未详细解释具体解决了哪些问题。
参考资料:
 发表于 2026-4-10 05:22:56
|
查看: 175|
回复: 0
发表于 2026-4-10 05:22:56
|
查看: 175|
回复: 0
