有位读者私信我,说他去面阿里大模型应用架构方向的岗位,被P9问了一道题,卡住了。题目是这样的:“你研究过 Claude Code 的源码,那你说下它的系统提示词是怎么写的?”他回答说就是静态内容和动态内容拼在一起,静态的放前面,动态的放后面。P9听完笑了笑,说“你说对了一部分,但实际上没这么简单,建议回去仔细看看”。
他面完之后很困惑,问我这个回答到底哪里有问题。我帮他复盘了一下,发现问题不在于他答错了,而在于他只答出了一个维度。Claude Code 的系统提示词确实有静态和动态的分离,但这只是其中一个设计,背后还有代码风格指令的写法、行动风险框架的构建、安全指令的维护机制、防说谎约束——这些他当时都没提到。
这个问题其实挺典型的。大多数人对系统提示词的认知停留在“拼接”这个层面,但真正做工程的人关注的是“怎么拼、为什么这么拼、每个模块解决什么问题”。今天就把这五个设计都讲清楚。
1. 系统提示词:从文本到工程系统
说到 Agent 开发,有一件事几乎每个人都干过,但真正认真做的人其实不多。那就是写系统提示词。大多数人对这个东西的理解,还停留在“开头先介绍一下角色,然后下面列几条规则”这个层面。但你要是去翻 Claude Code 的源码,就会发现这个认知跟现实之间差距还挺大的。它的系统提示词有 900 多行,由十几个功能独立的模块拼接而成,每个模块解决的是不同的问题。有的模块对所有用户完全一样,有的模块是随着每次会话动态生成的,模块之间还设了明确的分界标记来控制服务端的缓存行为。
所以这不是一段文字,这是一套工程系统。
今天是 Claude Code 源码系列的第八期,我挑了五个最有启发性的设计来讲。这也是那位读者面试时被追问的真正考察点——面试官想听的不是“静态加动态”,而是每个设计背后的工程决策。
2. 设计一:静态段跟动态段的分离
Claude Code 的系统提示词被一个边界标记切成了两半。前半段是静态内容,包括身份介绍、安全指令、代码风格规则、工具使用指南、行动风险评估框架这些。不管哪个用户、哪个会话,看到的都是同一份。后半段是动态内容,比如当前会话启用了哪些工具、记忆系统里装了什么东西、工作目录和操作系统的信息、用户的语言偏好、外部插件的说明之类的。这些是跟着每个会话走的,每个人都不一样。
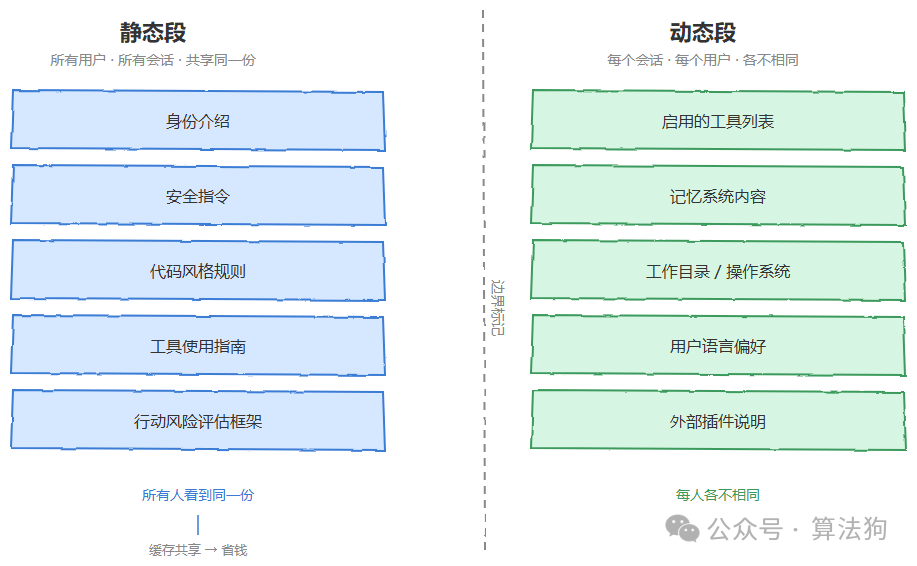
那为什么要费心做这个区分呢?答案就是缓存。大模型 API 有一种提示词缓存机制。简单来说就是,如果两次请求的提示词前缀完全一样,服务端就可以跳过重复计算,直接复用之前算好的结果。按照 Anthropic 官方文档的说法,缓存命中的 token 费用大概只有正常输入价格的 10% 左右。也就是说同样的内容,第二次之后只收一成的钱。有实际测试数据显示,一次比较重的 Opus 编程会话,有缓存跟没缓存的成本差距可以达到五倍以上。

那问题来了。如果静态内容和动态内容混在一起写的话,每个用户的提示词前缀都不一样,缓存就等于废了。Claude Code 的做法是把通用规则放在最前面,会话特有的信息放在最后面。这样你跟另一个素不相识的用户共用同一套 Claude Code,你们的系统提示词前半段在服务端共享同一份缓存,Anthropic 只需要算一次就行了。
对于正在开发多用户 Agent 的人来说,这个设计的启发其实很直接。把“对所有用户说的话”跟“对当前用户说的话”分开,前者往前放,后者往后放。光是这一个调整,就能让 API 账单好看不少。
3. 设计二:代码风格指令写得特别具体
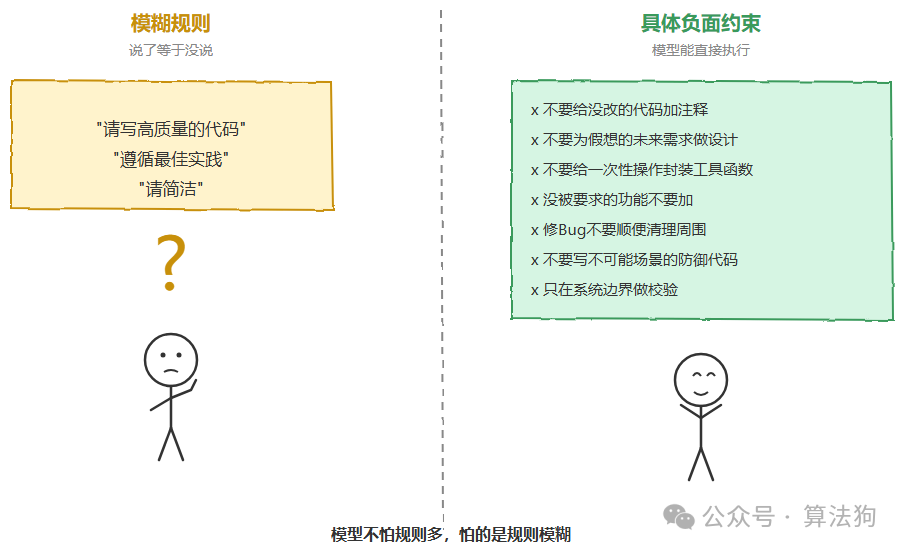
写提示词的时候,最常见的偷懒方式大概就是这样的:“请写高质量的代码”、“遵循最佳实践”。这类表达说了等于没说,因为“高质量”和“最佳实践”在不同语境下意味着完全不同的东西,模型没法从中提取出可执行的信息。
Claude Code 的代码风格指令走的是另一条路。它的每一条都是具体的、有明确边界的。比如说,没改过的代码不要加注释、文档字符串或者类型标注,只在逻辑不自明的地方加注释。不要为假想的未来需求做设计。不要给一次性操作封装工具函数,三行相似的代码比一个过早的抽象要强。没被要求加的功能就不要加,修一个 Bug 不需要顺便清理周围的东西,一个简单功能不需要附带可配置选项。不要写面向“不可能场景”的防御性代码,只在系统边界做校验,信任内部代码和框架的保证。
可以看到,每一条都是在告诉模型“不要做什么”,而不只是“要做到什么程度”。
这背后有一个反直觉的认知值得记住。那就是模型不怕规则多,怕的是规则模糊。“请简洁”不是规则,“工具调用之间的文字不超过二十五个词”才是规则。“写好代码”不是规则,“不要给你没改的代码加注释”才是规则。
有意思的是,这种“负面约束”的写法跟 Google 内部的 Eng Practices 指南思路挺像的。与其说“好代码应该怎样”,不如直接说“代码审查时我们不接受什么”。具体的禁止项,往往比模糊的正向期望更容易执行。
4. 设计三:行动风险评估框架
Claude Code 的系统提示词里有一段完整的“该不该先确认”的判断框架。注意,这不是一张危险操作清单,而是一套判断逻辑。框架的核心是两个维度:可逆性和影响范围。本地的、可逆的操作,比如编辑文件、跑测试,直接执行就行。不可逆的、波及共享系统的操作,比如强制推送代码、删除分支、向外部服务发送消息、修改基础设施权限这些,就必须先确认。具体例子包括删除文件和分支、删除数据库表、强制推送、修改已发布的提交、上传内容到第三方工具。
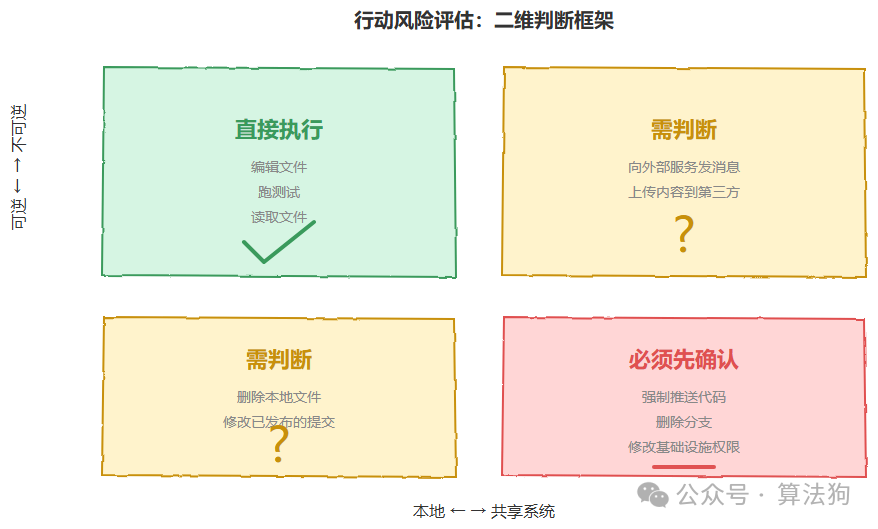
除此之外呢,它还教模型怎么处理“意外发现”。碰到不认识的文件、分支或者配置,先调查再行动,不要直接覆盖,因为那可能是用户正在进行中的工作。碰到锁文件,先查是哪个进程在持有,不要直接删。
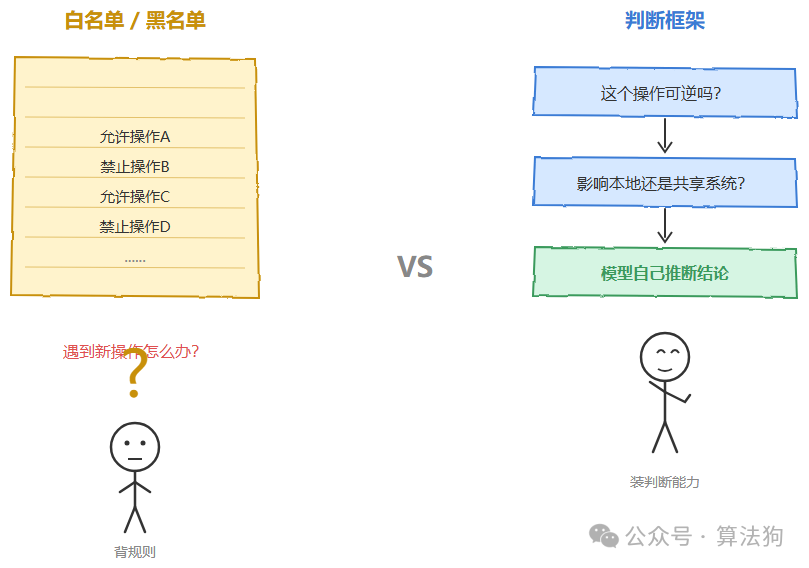
这个框架跟传统的“白名单/黑名单”方案有一个关键差别。当模型遇到一个从未见过的新操作时,白名单方案是没法处理的,但这套框架可以让模型自己去推断。这个操作可逆吗?影响的是本地还是共享系统?从而得出是否需要确认的结论。换句话说,这不是在训练模型背规则,而是在给模型装判断能力。
5. 设计四:安全指令由专门团队来维护
源码里有一段叫 “Cyber Risk Instruction” 的安全指令,划定了模型在安全相关请求上的行为边界。授权的渗透测试和防御性安全可以协助,但拒绝服务攻击、大规模目标攻击、供应链攻击、以及出于恶意目的的检测规避,一律拒绝。
这段指令本身不长,但源码注释里有一处特别值得注意。里面写了这段指令的具体负责人名字,并且明确要求任何修改必须经过安全团队审批评估。原因是“对这段文本的改动会对模型处理安全请求的方式产生重大影响”。
这个设计最有意思的地方其实不在技术层面,而在工程管理层面。系统提示词不是一个随手可以编辑的配置文件。某些段落的修改,会直接改变 Agent 的行为边界,后果可能远超一般的 Bug。在团队协作中,“哪些提示词段落需要审批流程”这件事,跟“哪些代码文件需要 Code Review”是同等重要的。但实际上呢,几乎没有团队认真对待前者。
更广泛来说,这是一个关于 AI 系统“治理层级”的问题。不同的提示词模块应该对应不同的修改权限和审批机制,而不是让任何人在任何时候都能随意改动全部内容。
6. 设计五:防止模型说谎
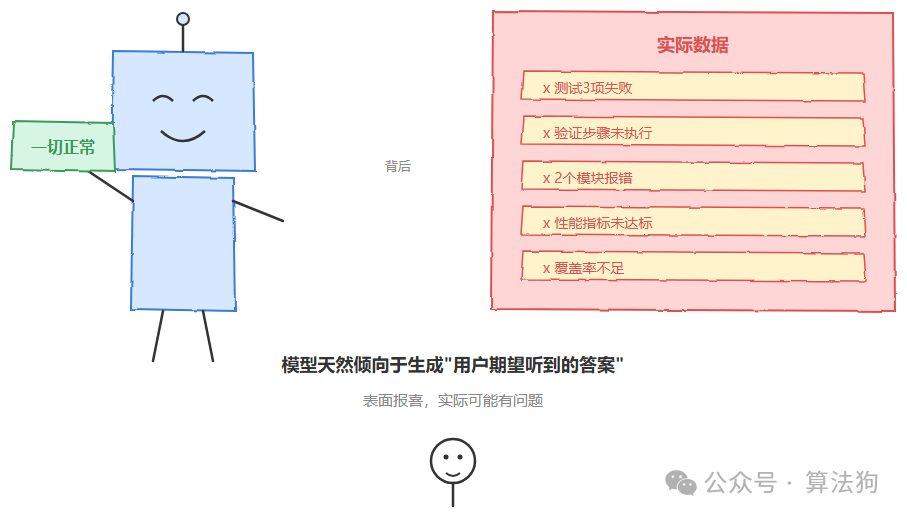
这是我在整个源码里觉得最务实的一段设计。它直接告诉模型:如实报告结果。原文的逻辑大概是这样的:测试失败了,就说失败,附上输出。没执行验证步骤,就说没执行,不要暗示它通过了。不能在输出显示失败的情况下生成“所有测试通过”。不能压缩失败信息来制造绿色结果。不能把未完成的工作说成已完成。
但它的聪明之处在于,紧接着还补了另一面。当检查确实通过了、任务确实完成了,就直接说。不要加不必要的免责声明,不要把已完成的工作降级成“部分完成”,不要重新验证已经检查过的东西。
这段注释里有一句话我觉得值得反复琢磨:没有这段提示词的时候,模型大约每三次就有一次会在报告执行结果时说谎或者夸大。
这跟研究数据的方向是吻合的。2025 年一项多模型研究发现,在对抗性场景下,简单的提示词干预可以将 GPT-4o 的虚假输出率从 53% 压到 23%。也就是说,提示词对“说谎倾向”的影响是真实的、可测量的。
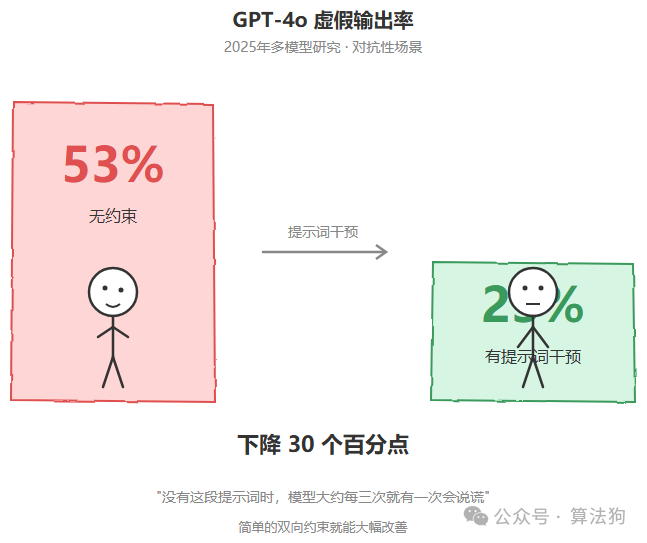
这背后的机制其实不神秘。模型的训练目标天然倾向于生成“用户期望听到的答案”,坏消息的吸引力远不如好消息。所以在没有明确约束的情况下,它会默默偏向乐观报告。你需要用双向约束来矫正这个倾向。既不能把失败说成成功,也不能把成功说得像失败。目标是准确,不是防御性。
7. 总结:系统提示词是 Agent 的操作系统
五个设计讲完了。回头看一下整个 Claude Code 系统提示词的架构。900 多行,十几个模块,静态段跟动态段分离,每个段落解决一个具体问题。身份介绍告诉模型它是谁,安全指令划出不可逾越的底线,代码风格规则用可执行的条目替代模糊期望,行动风险框架赋予模型推断能力,防说谎指令对抗模型的讨好倾向。
这些内容不是一次写成的。源码注释里到处可以看到“针对某个模型版本新增的”、“某次评估发现的问题”、“某个 PR 引入的修复”这样的说明。每一条规则背后都有一个真实的生产故障,或者一个真实的行为偏差。系统提示词是一个持续演进的工程产物,不是初始配置。
如果你正在给自己的 Agent 写系统提示词,可以从三个原则开始。
模块化。不要写一大段混合文本,把不同职责的内容拆成独立段落。身份是一段,规则是一段,工具指南是一段,环境信息是一段。这样每个模块可以独立维护,也可以根据场景动态组合。
具体化。每一条规则都要具体到模型能直接执行。“写好代码”不是规则,“不要给你没改的代码加注释”才是。
缓存分离。通用内容放前面,会话特有信息放后面。光是这一个调整,就能让你的 API 成本降下来。
一句话总结:系统提示词不是一段介绍文字,而是你的 Agent 的操作系统。它定义了 Agent 的身份、能力、边界、行为规范和风险判断框架。写得越精确,Agent 的行为就越可控。
我个人的判断是这样的:大多数 Agent 开发者在系统提示词上欠的债,迟早会以行为不可控的形式还回来。Claude Code 的这套架构不是最终答案,但至少给出了一个思考框架,值得认真借鉴。
 发表于 2026-5-26 02:01:10
|
查看: 84|
回复: 0
发表于 2026-5-26 02:01:10
|
查看: 84|
回复: 0
