最近,不少用 Claude Opus 写代码的开发者可能遇到了一个相似的问题:模型的行为模式似乎变了。过去,它会耐心地把文件从头读到尾,制定出完整的计划,再开始编辑。现在,它经常只读一半内容就开始动手修改,以前几乎不出现的 stop hook violations 这类错误也突然增多了。
这不是因为你的提示词写得不好,也不是工作流程出了问题,而是模型的“思考深度”实实在在地下降了。
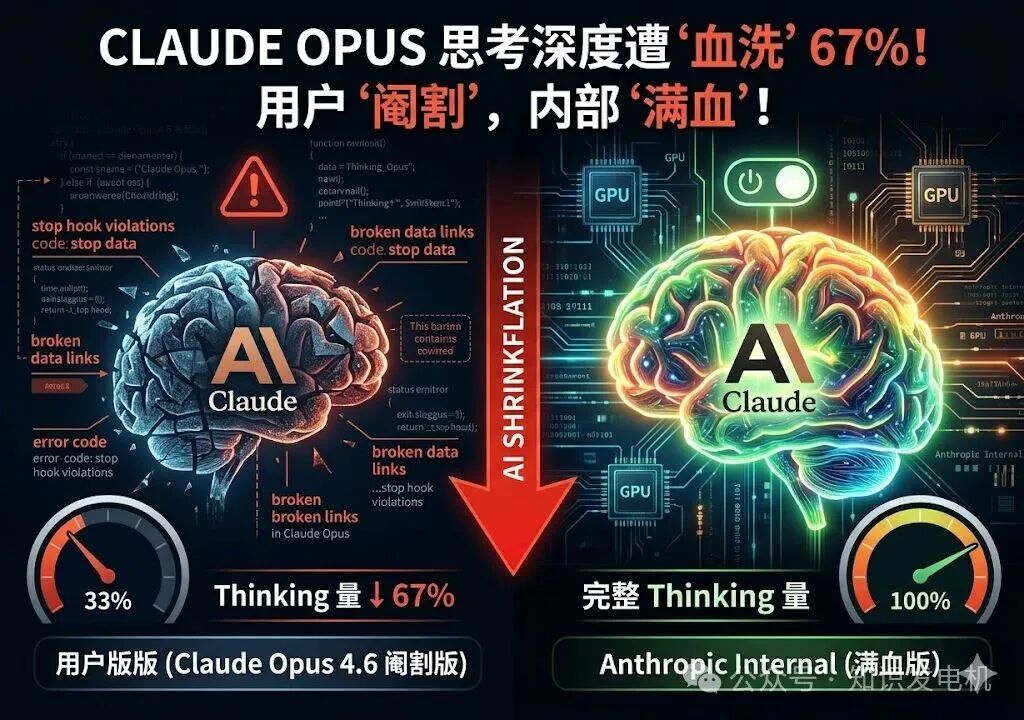
有实测数据显示,Claude Opus 4.6 版本的 “thinking” 量被直接削减了大约三分之二,相当于下降了 67%。起初,Anthropic 对此保持沉默,直到 GitHub 等开发者广场上的讨论激烈发酵,Claude Code 项目的创始人才出面回应。更令人意外的是,有泄露的源码表明,Anthropic 内部员工的模型版本中似乎存在一个“开关”,可以切换到“满血”性能状态。这引发了社区的不满——用户支付着同样的订阅费用,拿到的却是性能被“阉割”的版本。这种现象被社区戏称为 “AI Shrinkflation”(AI 缩水通胀)。当前普遍的猜测是,Anthropic 可能有意降低了 Opus 的性能,以节省算力用于训练下一代模型。
那么,所谓的 “thinking” 量到底是什么?它指的是模型在生成最终答案前,内部用于推理的 token 数量。简单来说,这个数值越高,代表模型“思考”的步骤越多,处理复杂问题的能力越强。被砍掉 67% 之后,模型的“脑容量”大幅缩水,这对需要多轮逻辑推演的代码任务影响尤为明显。理论上,这确实能为公司节省大量计算资源,但用户端体验到的质量下滑是肉眼可见的。许多开发者反馈,同样的提示词,以前能一次通过的任务,现在需要反复纠正才能完成。
📉 67%的性能下降是如何被发现的?
这次事件的数据最初来源于一位开发者在国外知名论坛上的详细投诉帖。他从今年初就开始使用 Claude Code,但在二月底左右突然察觉到模型的输出“变浅”了。具体表现为,模型经常在没有仔细通读文件的情况下就进行编辑,而此前罕见的 stop hook violations 错误也激增。
他首先怀疑是自己的提示词或工作流出了问题。随后,他通过检查实际日志、追踪模型的行为模式,最终量化了这一变化,估算出“思考深度”在二月底左右下降了约 67%。这个数字并非空穴来风,而是有日志证据链支持的。如果不理解“thinking”量的含义,很难分清这究竟是一个技术故障,还是有意的性能调整。
思考量直接决定了模型能够执行的逻辑链深度。砍掉 67% 相当于原来需要思考三轮的问题,现在只进行一轮浅层思考,输出的质量自然变得肤浅。对于开发者而言,这意味着代码中会出现更多低级错误,需要人工干预和修正的地方也变多了。
社区中许多用户独立报告了类似问题,且模式高度一致,这说明并非个例。Anthropic 最初的默认回应是将问题归咎于用户提示词或期望值,但在投诉积累到一定数量后才打破沉默。理论上,这种性能回归测试在实验室环境中很常见,但 Claude Code 被定位为一款严肃的开发工具,用户对其信任模型完全不同。如果模型在编码前阅读和理解代码的能力悄然下降,不系统性地记录所有信息,就很难察觉到对下游任务产生的负面影响。
🔍 泄露源码中的“内部特权”
最让用户感到不满的,是泄露信息所揭示的“内外有别”:Anthropic 内部员工使用的模型似乎有一个可以切换到完整性能的开关,而外部用户使用的则是被限制了的版本。
这个设计使得内部团队能访问具备完整“思考”能力的模型,而公开版本则被施加了限制。为什么会有这样的设计?一种合理的解释是,公司为了控制运营成本,在用户侧实施性能降级,同时优先保证内部研发团队的效率。Anthropic 作为 AI 模型的开发者,算力是其最核心的资源。降低 Opus 的性能可以释放出大量资源,用于下一代模型的训练。然而,这对付费用户而言,公平性就大打折扣了。
在实际场景中,如果你是重度用户,每天运行复杂的智能体(Agent)任务,思考量被大幅削减后,任务的一次完成率很可能会直线下降。以前一键就能解决的问题,现在可能需要手动拆分步骤,或者更换其他模型。
⚖️ 算力紧张背景下的AI“缩水”博弈
当前的普遍猜测指向一个行业现实:在全局算力紧张的大背景下,Anthropic 可能故意降低了旗舰模型 Opus 的性能,以节省算力用于训练下一代。这对于烧钱训练大模型的 AI 公司来说并不意外,各大厂商都在进行类似的权衡。
这种做法会带来直接的行业冲击:即使版本号保持不变,实际加载的模型检查点(checkpoint)可能已经不同,性能也就此改变。开发者圈子甚至有人指出,即便是同一版本,也可能对不同用户群分配不同的参数配置。
如果你一直依赖 Claude Opus 作为工作流中的核心决策工具,现在可能需要重新评估。或许需要监控其“思考”量的变化,或者将繁重的任务拆解,分发给多个模型协作完成。
这一事件提醒我们,AI 服务在本质上是一种动态分配的资源,而非固定不变的商品。Anthropic 的处理方式让许多人开始质疑其商业模式的透明度。理论上,算力优化是整个行业发展的必经之路,但如果将付费用户当作节省成本的“实验品”,无疑会触及信任红线。
总而言之,Claude Opus 思考量缩水 67% 并非一个孤立事件,而是“AI Shrinkflation”现象的一个典型案例。Anthropic 内部“满血版”与用户“阉割版”的对比,让付费体验大打折扣。下次再遇到模型似乎“变笨”的情况,或许可以思考一下,这背后是否是算力资源博弈的结果,而不仅仅是你的提示词出了问题。欢迎在云栈社区继续探讨这一现象对开发工作的实际影响。
 发表于 2026-4-10 05:32:16
|
查看: 116|
回复: 0
发表于 2026-4-10 05:32:16
|
查看: 116|
回复: 0
