如果大家对之前的Radeon RX 9070/9070 XT显卡评测还有印象,应该记得AMD在驱动软件里增加了一个名为AMD Chat的功能。这是一个基于Qwen模型的本地AI聊天机器人,它与AMD Software的集成度很高,你甚至可以直接问它显卡温度和驱动版本信息,确实挺有趣。
为了让更多对AI感兴趣的玩家能快速上手应用和开发,AMD在今年的驱动更新中加入了一个名为“AI Bundle”的可选安装组件。今天就让我们借助盈通显卡,看看这个AMD的AI大礼包里到底装了些什么好东西。

AI Bundle 是什么?
AMD把主板、显卡驱动更新都整合到了AMD Install Manager这个统一安装管理器中,AI Bundle也是其中的一个可选组件。它之所以是可选的,一方面可能是因为包含的应用都来自第三方,另一方面则是它的体积确实不小——比如PyTorch和ComfyUI的安装包都达到了13GB。当然,这两个应用体积大的主要原因在于集成了ROCm的whl包,Python环境和ComfyUI本体本身并不大。
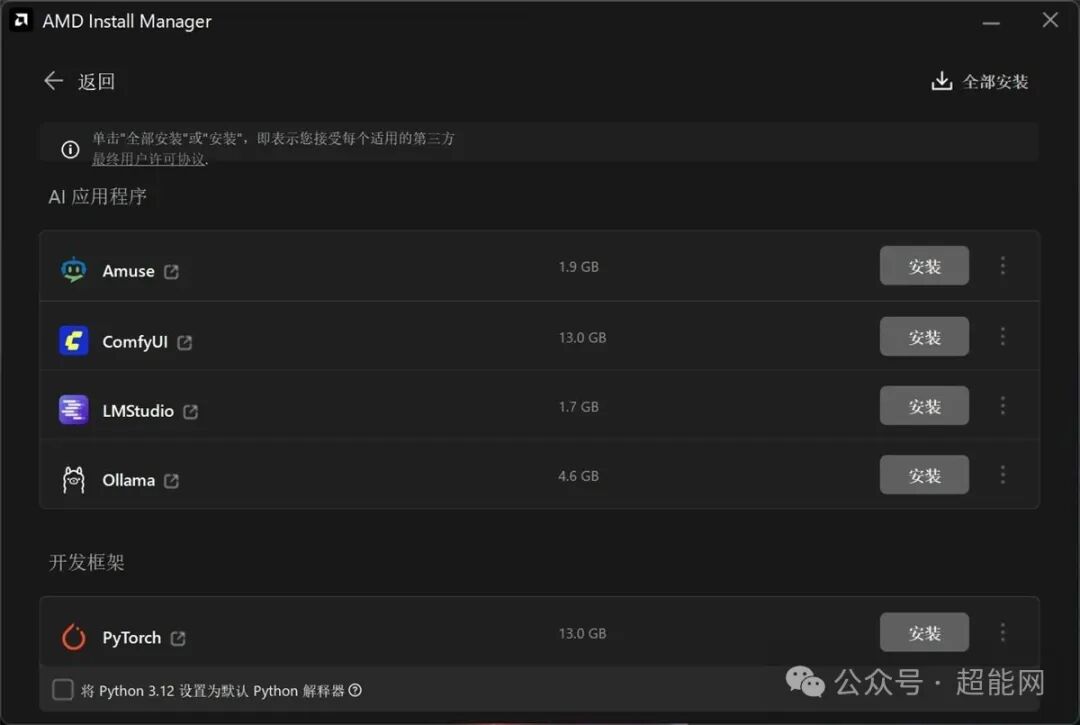
AI Bundle 核心应用一览
让我们从第一个应用——Amuse开始介绍。Amuse是一款由TensorStack AI开发的本地AI创作工具,支持图片和视频生成。它的最大优点在于易用性:它是一个独立的桌面程序,没有繁杂的窗口或命令行界面。新手可以使用EZ模式快速入门,而专家模式则提供了步数、分辨率等进阶控制选项。更重要的是,它针对AMD硬件进行了专门优化,能充分发挥Radeon显卡的性能。
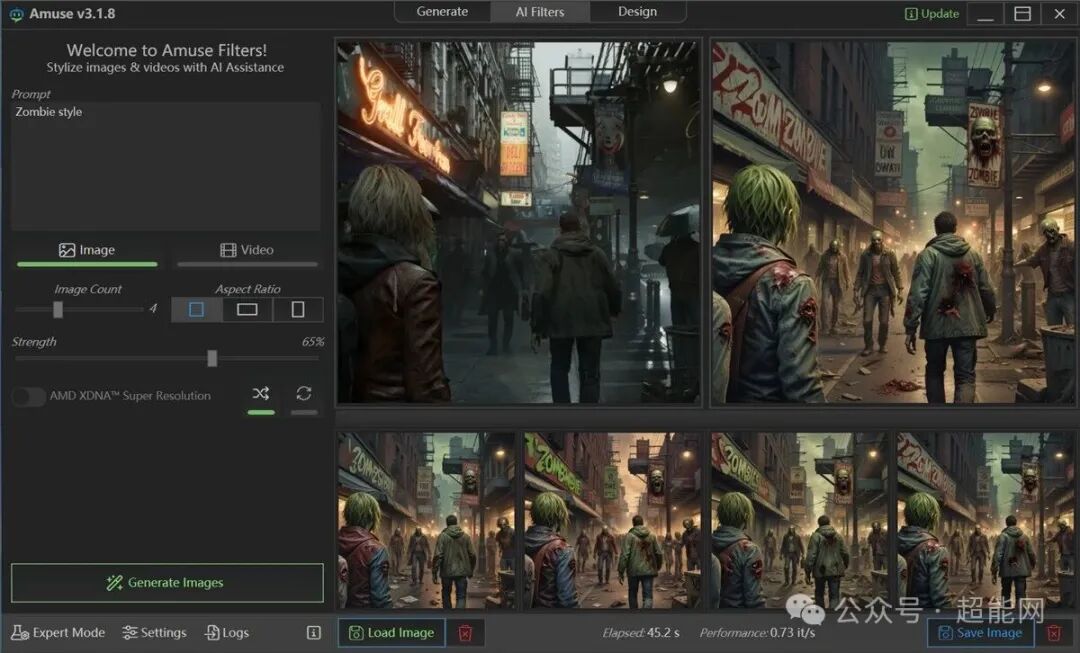
ComfyUI:强大的节点式工作流工具
相信大家对ComfyUI这个节点式创作工具已经不陌生了,我们在之前的AI应用相关文章中也经常提及。ComfyUI功能强大,但安装配置往往令新手头疼。AI Bundle则把这一切都打包好了——在AMD Install Manager目录的AllBundle.json文件里,你可以看到所有需要下载的文件,其中一系列标有“ROCm”字样的文件就是AMD的加速组件。
AllBundle.json文件中包含了详细的安装包信息,例如:
{
"packages": [
{
"InstallerFileName": "run_comfyui.bat",
"InstallerSha256": "2CF6F32F369127865AD1AC8FD1345E8B781CC8B644A6C94846B3F484530468",
"AdditionalFiles": [
{
"Url": "https://repo.radeon.com/roc/windows/roc-rel-7.1.1/a/roc_sdk_core-0.1_dev-py3-none-win_amd64.whl",
"Filename": "roc_sdk_core-0.1.dev-py3-none-win_amd64.whl",
"Sha256": "95342D638AD4C0992E4C9E7328248785301134ADEE28F76A214A2D26D67F95",
"Size": "999"
},
// ... 更多ROCm组件文件
]
}
]
}
LM Studio 与 Ollama:本地大语言模型运行器
最后是LM Studio和Ollama,两者都用于在本地运行大语言模型(LLM)。从核心功能上看,它们是一致的,但操作方式区别较大:Ollama虽然有图形界面,但其命令行操作体验更佳;而LM Studio的图形界面则非常完善,大部分操作都可以通过点击鼠标完成。
至于PyTorch开发框架,说实话,我并不太推荐通过AMD Install Manager来安装(尤其是它还把Python装在了AppData\Local目录下)。从开发者的角度来看,开发环境最好还是自己部署,至少安装路径、环境变量和Python版本都能由自己完全掌控。
测试平台配置
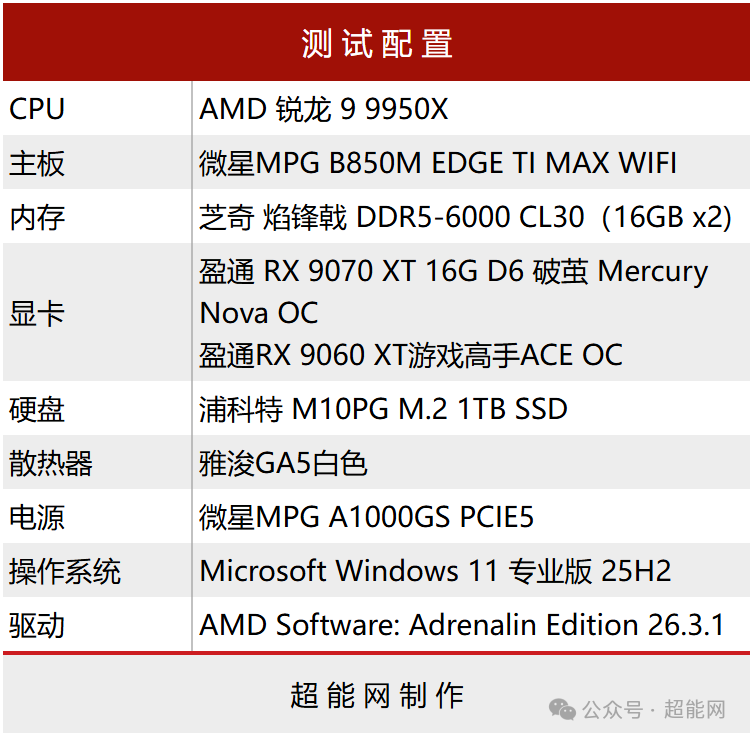
本次测试平台采用了锐龙9 9950X处理器、微星MPG B850M EDGE TI MAX WIFI主板和32GB DDR5-6000 C30内存。显卡方面,使用了盈通 RX 9070 XT 16G D6 破茧 Mercury Nova OC和盈通 RX 9060 XT游戏高手ACE OC。虽然两者规格不同,但都配备了16GB显存,足以流畅运行200亿参数级别的Q4量化模型,运行图像生成模型自然也不在话下。


AI Bundle 应用实战体验
安装AI Bundle的过程极其简单,完全就是在AMD Install Manager上点几下鼠标的事情。唯一的要求可能就是一个稳定且速度不错的网络环境,因为它需要从GitHub、HuggingFace等网站拉取资源。
Amuse:新手友好的AI生图工具
打开Amuse,首先看到的就是EZ模式界面。这个界面将选项精简到最少,以便新手快速上手。你会注意到,连模型选择、步数、分辨率这些常见选项在EZ模式下都被隐藏了,只剩下生成图片数量、比例和一个控制性能的滑块。首次生成时,Amuse会提示你下载模型。或许是考虑到不同硬件的兼容性,Amuse EZ模式提供的模型并非计算压力最大的那些,而是侧重于Stable Diffusion XL这类体量相对较小的优化模型。
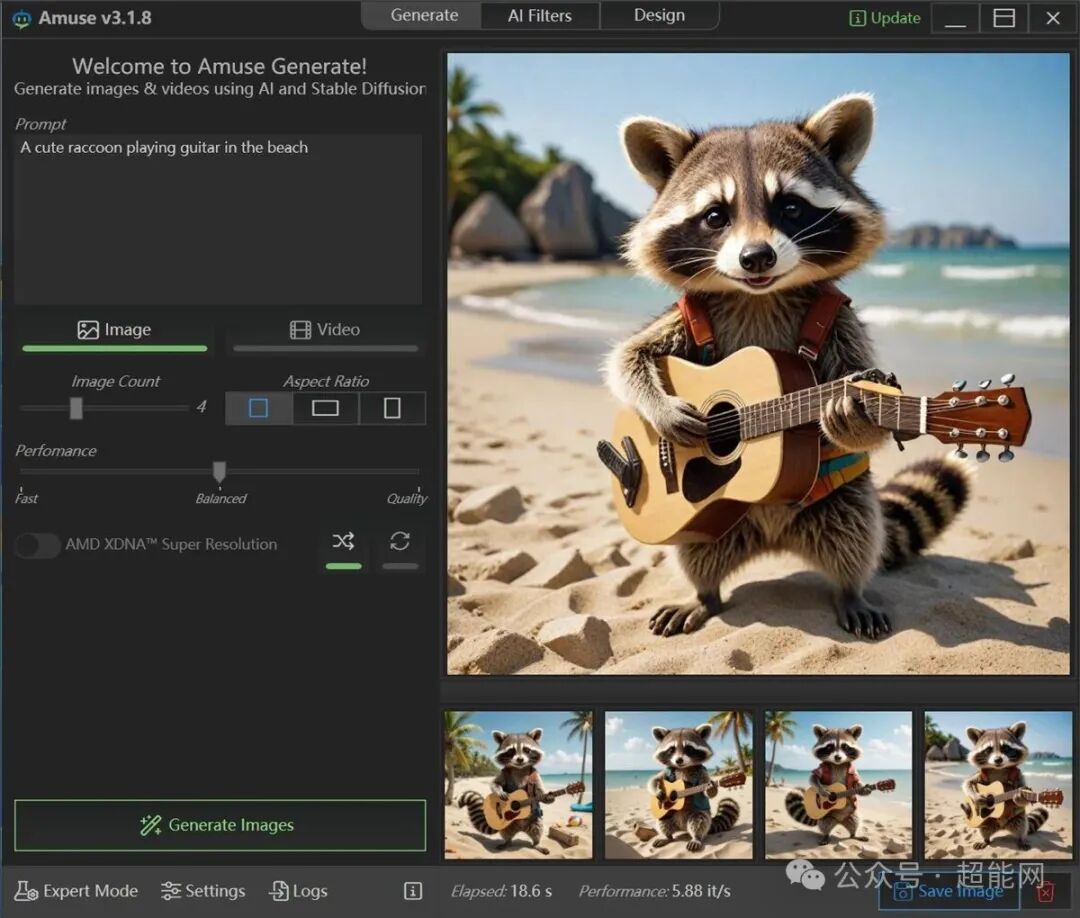
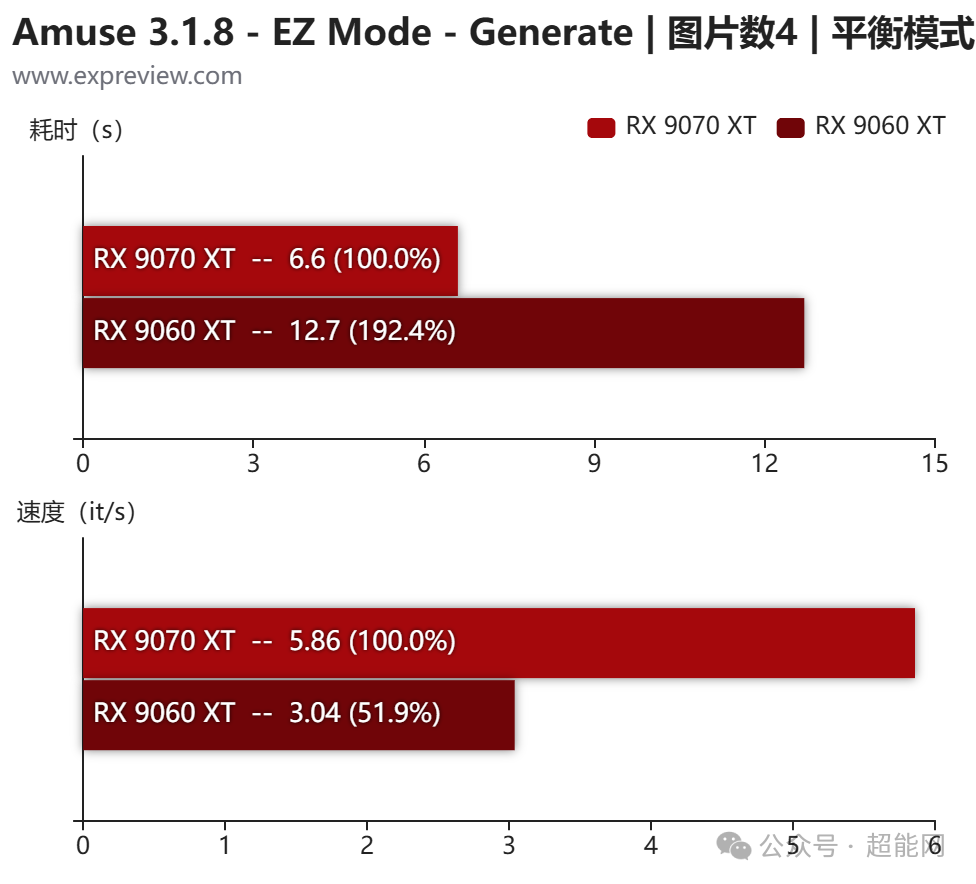
由于EZ模式下载的模型都是针对AMD优化的ONNX模型,无论是Radeon RX 9070 XT还是RX 9060 XT,在Amuse上都能获得快速且流畅的体验。在文生图测试中,RX 9070 XT仅用6.6秒就生成了4张1024x1024分辨率的图片;RX 9060 XT耗时12.7秒,速度大约是前者的50%,这与两者核心规模的比例基本吻合。
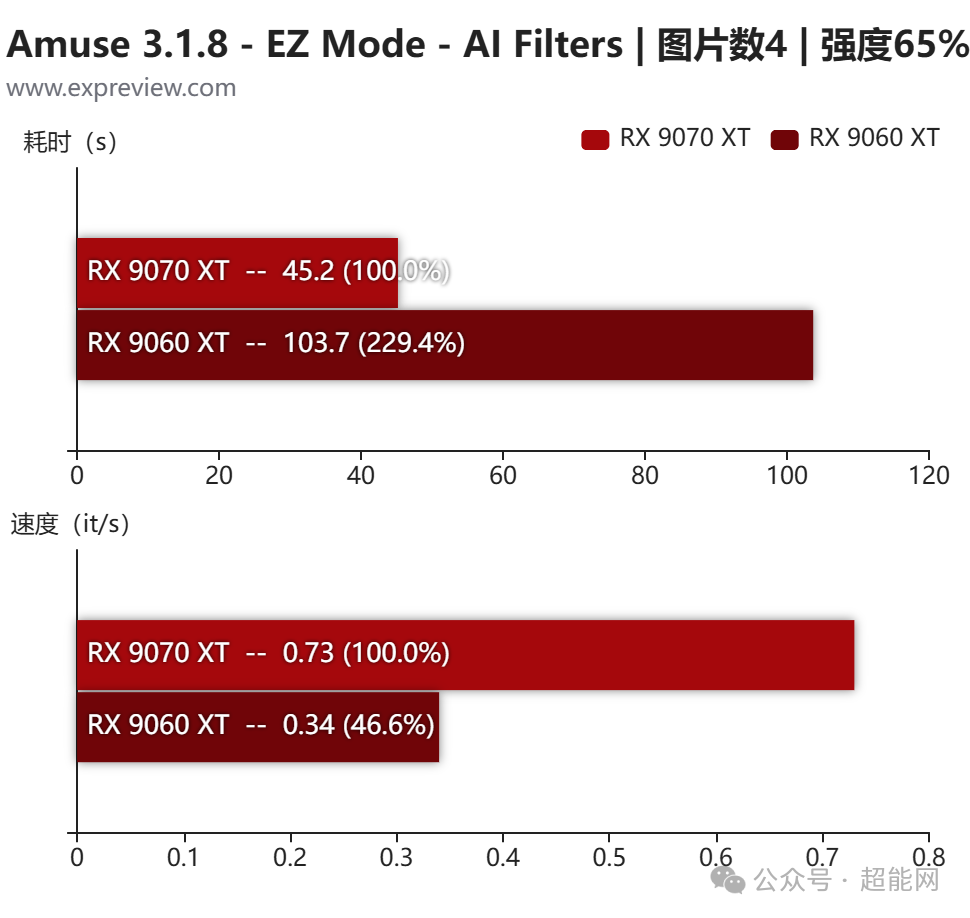
在以图生图的AI Filter功能中,两张显卡也呈现出相似的性能关系。值得一提的是,尽管速度有差异,但两张卡的16GB显存都足以支撑模型的完整运行,没有出现爆显存的情况。
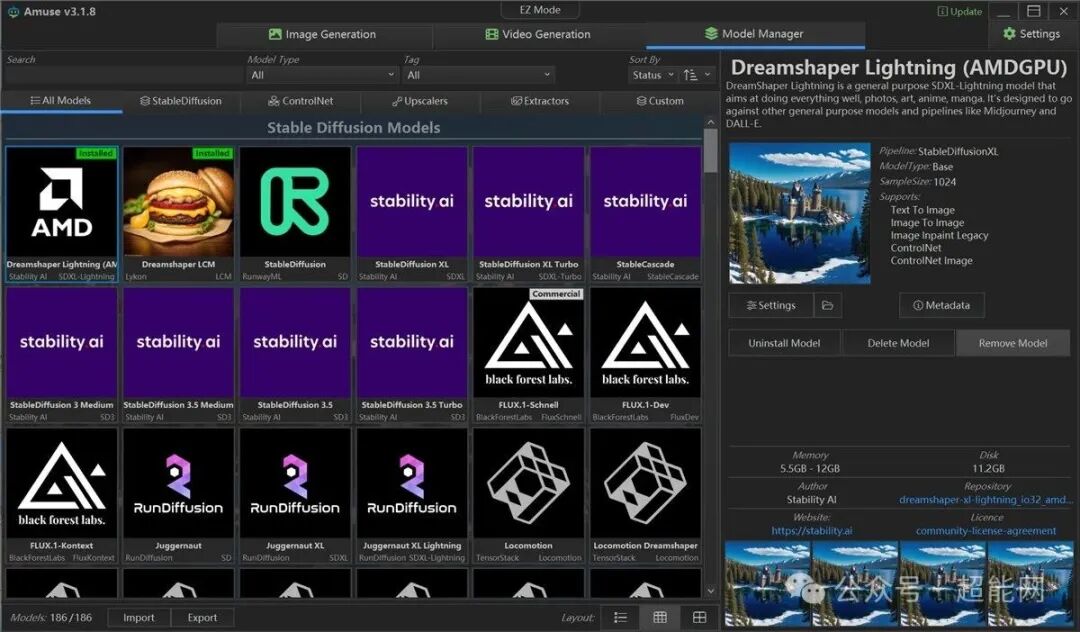
除了EZ模式,Amuse还提供了参数更丰富的Expert Mode。这里的选项就更接近ComfyUI了,例如独立的正面/负面提示词输入框、步数、引导尺度等。界面右下角还有一个实时系统信息监视器。此外,在专家模式下,Amuse内置了模型管理器,可以直接下载和管理模型。

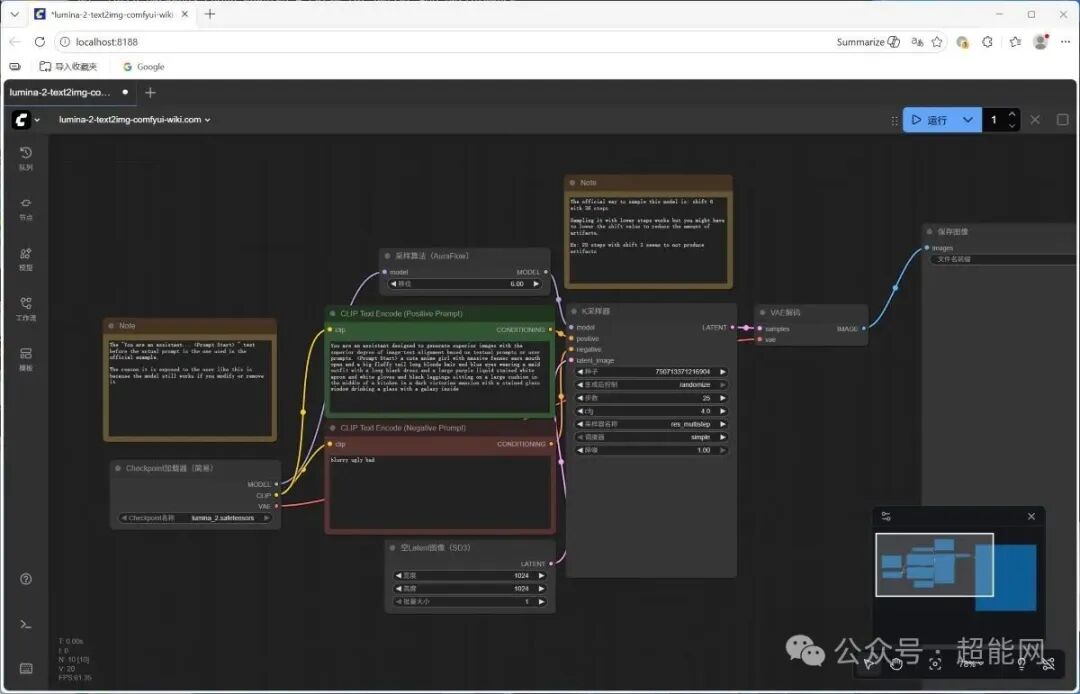
ComfyUI:释放创造力的工作流平台
相比Amuse,ComfyUI的启动稍显复杂。你需要到AMD Software控制面板的“AI”分页中点击ComfyUI的启动项。这会打开两个窗口:一个用于监控ComfyUI后端的启动状态并自动打开浏览器,另一个就是ComfyUI本体的Web界面。
因为AMD Install Manager已经为我们安装好了ROCm、PyTorch等全部运行组件,所以你可以在控制台和ComfyUI的设置页面中看到正确的设备识别信息。你可以直接从ComfyUI的模板库中选择一个工作流开始,也可以自己下载模型后搭建个性化的工作流。
启动日志会显示类似以下信息:
pytorch version: 2.9.0+rocm5dk20251116
Set: torch.backends.cudnn.enabled = False for better AMD performance.
AMD arch: gfx1200 ROCm version: (7, 1)
Device: cuda:0 AMD Radeon RX 9060 XT : native
ComfyUI version: 0.3.68
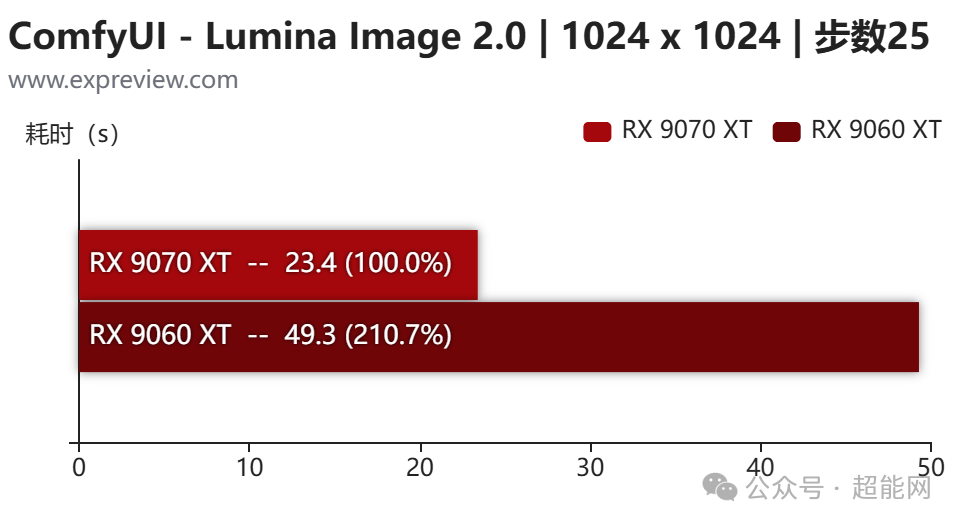
ComfyUI的节点式界面允许你对图像生成过程进行极其精细的控制。我们使用Lumina Image 2.0这个26亿参数的模型进行测试。在步数25、分辨率1024x1024的默认设置下,RX 9070 XT生成一张图大约需要23秒,而RX 9060 XT则需要接近50秒。
你可能会好奇,为什么测试用的是Lumina Image 2.0而不是FLUX.2 [klein]这类更新的模型?这就涉及到另一个问题:目前AI Bundle默认提供的ComfyUI版本和ROCm并非最新版,而AI领域的迭代速度极快。当然,这样做也可能是出于稳定性的考虑。个人建议是,熟练之后可以自行升级到最新版本,因为一些新的图像模型在发布时,会同步推出效率更高的FP8量化版本,而RDNA 4架构的第二代AI加速器正好原生支持这种格式。
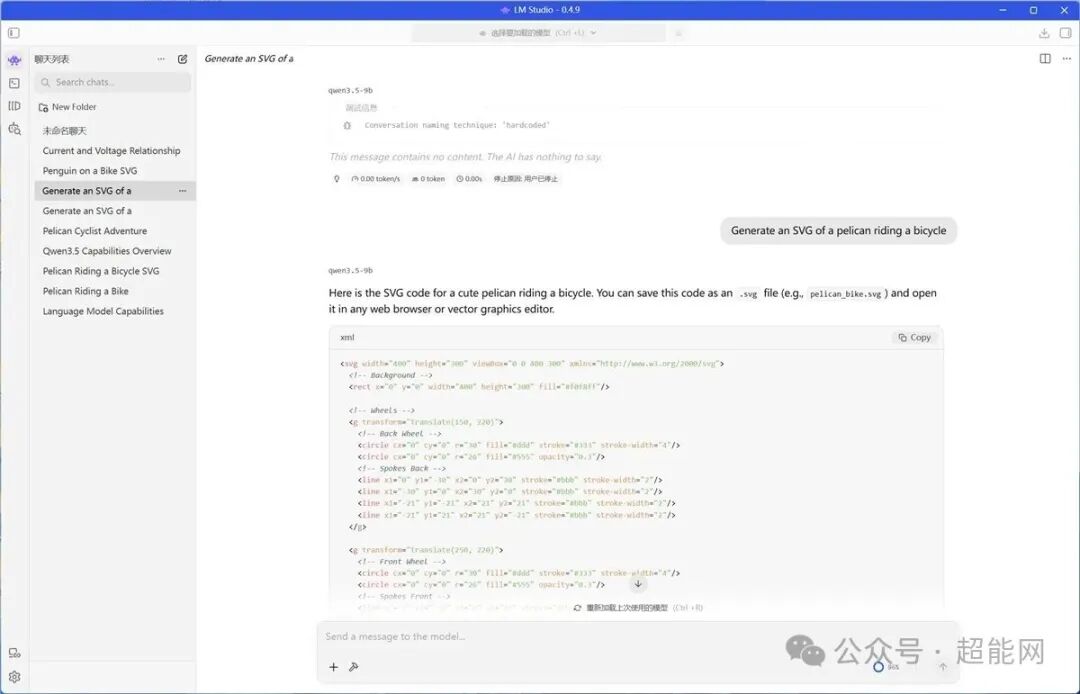
LM Studio:图形化LLM利器
前面提到,LM Studio的图形化界面非常完善,因此使用起来非常方便。其内置的模型库可以直接搜索和下载海量开源大模型。下载完成后,即可在主页加载模型并开始对话。在设置中,你可以看到LM Studio已经正确识别到了Radeon显卡,并且运行时选择了“ROCm llama.cpp”。当然,你也可以选择通用的“Vulkan llama.cpp”运行时。
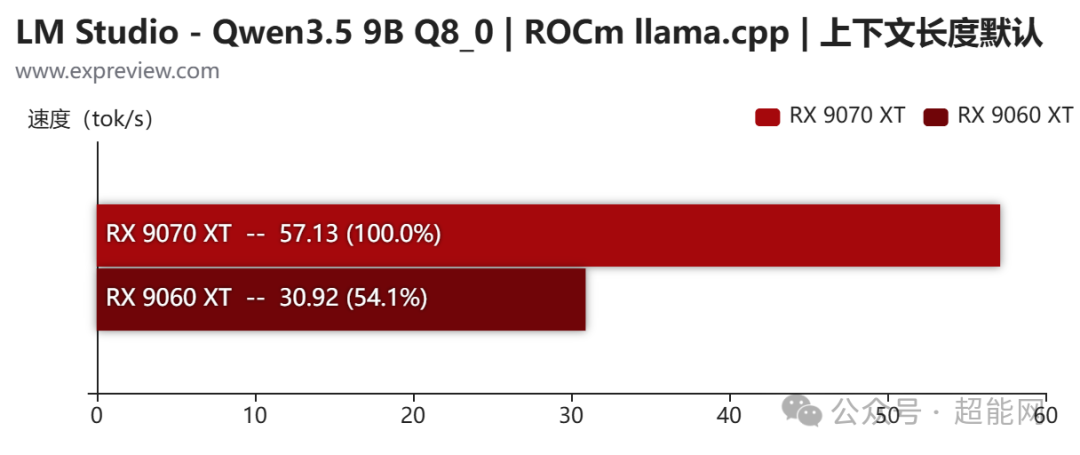
我们采用Qwen3.5 9B的Q8_0量化版本来测试。模型加载完成后,大约会占用10.5GB显存。在输出速度方面,RX 9070 XT可以达到57 token/s,而RX 9060 XT则为31 token/s。在整个输出过程中,两张显卡都表现得非常流畅,无论是输出数学公式还是代码,基本都能一气呵成。
Ollama:简洁而强大的框架
Ollama的图形界面有点像Amuse的EZ模式,设计非常简洁。在聊天主界面选择你想要的模型并开始对话,Ollama就会自动下载对应的模型。但这只是Ollama框架最基础的用法。只有通过命令行,你才能体验到它的全部功能,例如,运行一个完全本地的AI智能体(Agent),比如基于Qwen3.5 9B Q4_K_M模型的OpenClaw。目前Ollama支持Vulkan加速,为了提升生成速度,我们通过设置环境变量启用了这一实验性功能。
总结
即便到了2026年,相比于打开网页或App就能用的云端AI,想要在本地顺畅运行一个AI模型,仍然存在一定的门槛。下载模型、安装框架只是第一步,更重要的是如何让显卡硬件真正发挥出全部性能,并在长时间运行中保持稳定。对于缺乏相关经验的新手来说,光是前期的查阅文档、处理Python环境冲突,就可能耗费大量时间。说实话,这可比给游戏安装运行库或打Mod复杂多了。

而AMD AI Bundle的出现,为使用Radeon显卡的玩家提供了一种简单快捷的“开箱即用”体验。只需要一个良好的网络环境,点几下鼠标,就能一站式体验从图像生成到聊天机器人的各类AI应用。同时,借助ROCm、DirectML或Vulkan的加速,被测的Radeon显卡的GPU和显存使用率都能被充分调动起来。虽然深度玩转AI最终可能仍离不开命令行甚至Linux系统,但AMD AI Bundle至少为初学者提供了一个轻松愉快的起点。等到玩家熟练之后,再学习如何升级ComfyUI或部署自己的PyTorch开发环境也为时不晚。

当然,除了软件生态,硬件本身也至关重要,尤其是在连续AI生图这类高负载场景下,显卡的散热能力是必须考量的因素。我们本次测试使用的盈通RX 9070 XT破茧OC采用了三把93mm风扇加7根热管的豪华散热组合,即使在切换到超频BIOS时也能保持稳定的功耗释放。可以说,它不仅是一张游戏利器,在应对新兴的AI应用时也能从容应对,展现出不俗的实力。对于想要入门AI创作和本地大模型部署的A卡用户,不妨多逛逛云栈社区,这里有许多关于AI应用的实战讨论和资源分享。
 发表于 2026-4-10 06:11:20
|
查看: 892|
回复: 0
发表于 2026-4-10 06:11:20
|
查看: 892|
回复: 0
