
OpenSearchCon 是由 Linux 软件基金会旗下 OpenSearch 基金会主办的年度技术大会,今年(2026年)首次来到中国。作为开源搜索与分析领域的深度技术交流盛会,全球顶尖的开发者、架构师与社区领袖汇聚一堂,探讨从底层引擎 Apache Lucene 到上层 OpenSearch 在向量检索、AIOps 等前沿领域的实践。作为社区的核心贡献者与重量级用户,字节跳动分享了其如何在数百万 CPU Core、数百 PB 数据的庞大规模下,极致挖掘 OpenSearch 潜能的工程实践。
OpenSearch 是支撑字节跳动全球产品矩阵背后海量数据实时检索与分析的关键引擎之一,从抖音、今日头条到 TikTok、Lark,被广泛应用于全文搜索、可观测性分析与向量检索等核心场景。
以下是字节跳动内部 OpenSearch 应用规模的核心数据:
- CPU 核心数:超过 200 万
- 数据存储量:超过 300 PB
- 集群总数:超过 9,000 个
- 节点总数:超过 12 万 个
- 总文档数:超过 210 万亿
- 最大单向量集群规模:超过 1000 亿条
在本次大会上,字节跳动数据库团队云搜索服务负责人、OpenSearch 基金会管理委员会成员李亚坤分享了题为《OpenSearch at ByteDance》的主题演讲,系统阐述了其内部工程实践、技术创新,并首次披露了在实时搜索、存算分离、向量检索等领域的最新成果。
深耕社区,引领开源技术演进
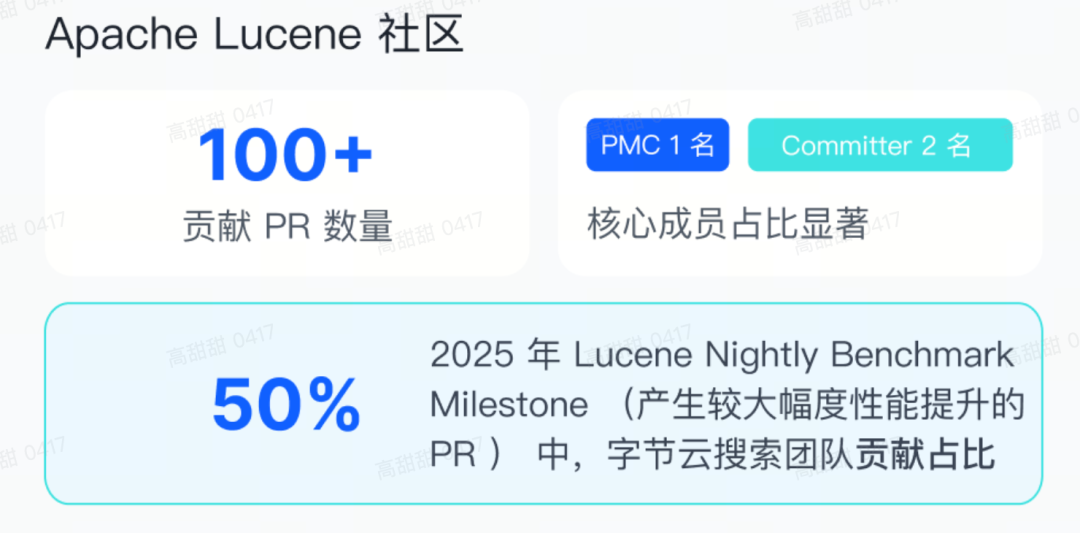
字节跳动不仅是 OpenSearch 的重度用户,更是基金会会员与核心贡献者。团队已累计向 OpenSearch 和 Lucene 社区贡献超过 200 个重要 PR,并在 2025 年 Lucene Nightly Benchmark 榜单中贡献了 50% 的性能改进。这种体系化的深度参与,体现了对开源技术的持续投入。
对 Lucene 社区的贡献:
- 拥抱现代 Java 特性:率先引入并深度应用 Java Vector API 和 Foreign Memory API (FFI),将 SIMD 指令威力带入搜索引擎,提升向量计算与数据处理效率。
- 优化核心数据结构与算法:重构倒排索引的 编解码器(Codec),引入 Trie 字典树 和 Bitset 等高效数据结构,显著提升索引与查询性能。
- 培养核心人才:团队拥有 2 位 Committer 和 1 位 PMC 成员,深度参与社区决策。
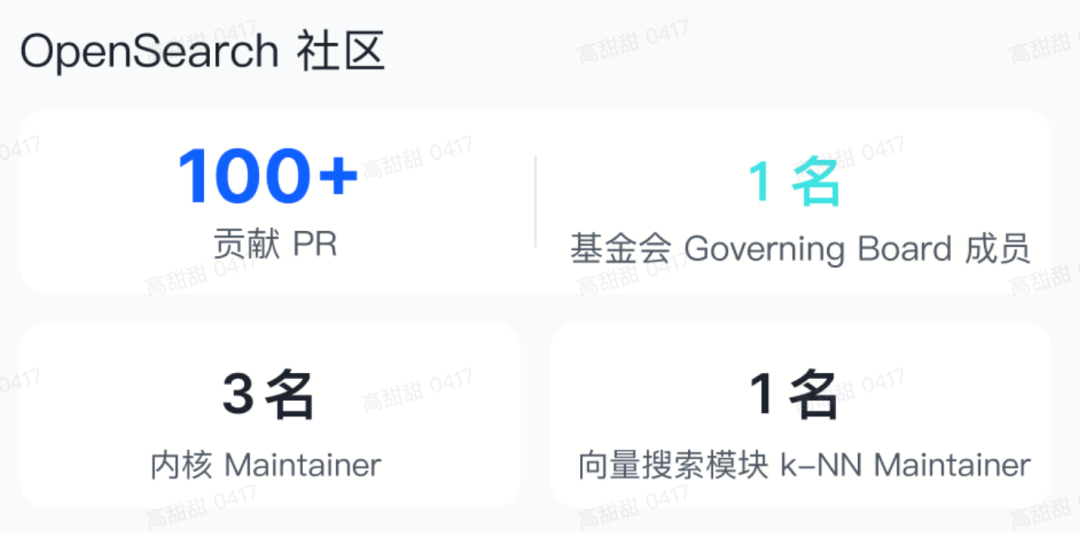
对 OpenSearch 社区的贡献:
- 向量搜索(k-NN)的早期开拓者:自2020年起深度参与 OpenSearch 向量搜索能力建设,并完成对业界顶级向量引擎 Faiss 的集成。
- 核心功能的设计与优化:深度参与 Segment Replication、Derived Source、Flat Object 等关键特性的设计与性能优化,为存算分离、降本增效奠定基石。
- 社区中坚力量:团队拥有 3 位 OpenSearch 内核仓库的维护者(Core Maintainer) 及多位领域专家。
攻坚核心挑战,释放数据价值
面对内部 PB 级数据、百万亿级文档、毫秒级延迟 的极致要求,字节对 OpenSearch 进行了深度定制与架构演进,重点攻坚五大核心领域。
创新领域一:极致的实时搜索
在电商库存、社交动态等场景,传统基于 refresh 机制的“近实时”搜索存在分钟级延迟,无法满足“写入即可搜”的需求。同时,主副分片在高并发写入下的数据强一致性也是难题。
解决方案:针对未 refresh 的增量数据,在内存中构建轻量级实时索引结构。
- 引入堆外内存(Off-Heap Memory):借鉴 Apache Arrow 设计理念,将新写入数据暂存于 堆外内存 并直接管理,实现快速写入与检索,避免占用紧张的 JVM 内存资源。
- 乐观锁提升性能:引入 乐观锁 机制,访问数据时先获取状态,操作完成后再检查状态是否变化,仅在必要时升级为读写锁,保证内存数据强一致性的同时对性能影响最小。
效果:实现了写入后立即可查,并保证了主副本数据的实时一致性。
创新领域二:下一代存算分离架构
传统存算一体架构中,存储与计算资源强绑定,弹性差、成本高。
解决方案:自研并落地基于 Segment Replication(段复制)机制 深度改造的新一代存算分离架构,搭配自研高性能分布式存储。
- 计算层(Compute Layer):无状态 OpenSearch 节点,负责查询、计算与索引构建。
- 存储层(Storage Layer):基于自研 分布式存储系统,仅存储一份逻辑索引段文件,通过纠删码保证可靠性。
- 工作流程:新生成的 Segment 直接上传至远端存储。计算节点按需拉取元数据与热数据到本地缓存即可提供服务。
成果:
- 总成本降低:通过独立扩展与资源池化,总体拥有成本(TCO)降低 50% 以上。
- 扩容时间缩短:计算节点扩容从小时级缩短至分钟级,效率提升 50 倍。
创新领域三:聚焦可观测性与日志场景的极致性价比
应对海量日志数据的高并发洪峰写入,团队从写入、查询与存储三个维度进行深度优化。
解决方案:
- 写入吞吐突破:实现 单分片批量摄入(Single-Shard Bulk Ingestion) 与 自适应分片选择(Adaptive Shard Selection),通过智能路由与批处理平滑吸收流量洪峰。
- 查询规划与剪枝优化:利用日志强时间属性,在查询规划器中引入 基于时间范围的索引剪枝(Time-range-based Index Pruning),并结合 Lucene 底层的 基于 DocValuesSkipper 的稀疏索引(Sparse Index),实现块级数据裁剪,降低磁盘 I/O。
- 存储效率极致压榨:引入 Derived Source(派生 Source) 技术,抛弃原生
_source 冗余存储,改为查询时动态生成。并对列存数据进行 高阶编码与压缩优化,自适应采用最优编码方式。
成果:达成写入吞吐量提升 3 倍,存储空间减少 54%。
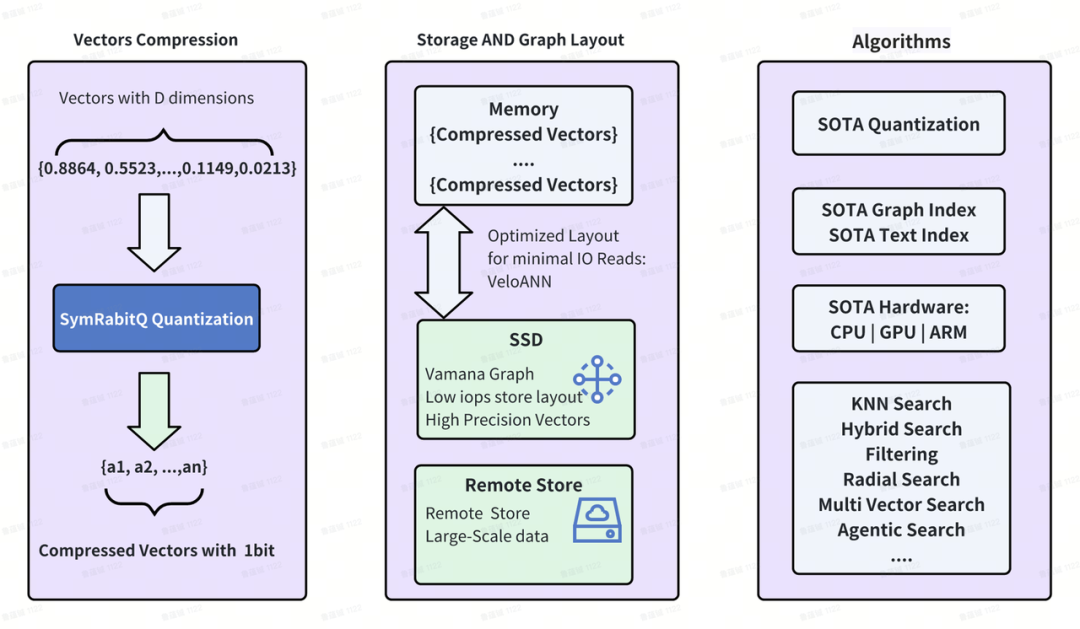
创新领域四:向量检索场景——打破“高精度、高性能与低成本”的不可能三角
随着 RAG(检索增强生成) 等 大模型应用 的爆发,如何在百亿、千亿级别向量规模下,同时实现低成本、高性能、高精度检索成为核心挑战。字节云搜索团队工程师、OpenSearch KNN Maintainer 鲁蕴铖分享了全栈式重构方案。
解决方案:
- 双模索引与高阶量化算法:引入 DiskANN Vamana 图索引算法,打造“双模索引”(低成本磁盘索引与高性能内存索引)。在 Vamana 中支持扩展的 RaBitQ 量化算法,并自研优化出 SymRaBitQ 算法,在保证召回精度的同时极致压缩内存占用。
- 多级存储与架构解耦:构建支持纯内存、纯磁盘及混合存储的架构。深度优化磁盘文件布局,并率先在 存算分离架构上实现了 k-NN 向量检索(k-NN on Disaggregated Storage),实现计算与存储的独立扩缩容。
- 精准高效的检索能力层:实现 基于 RaBitQ 的径向过滤(Radial Filtering),提供高效前置剪枝能力,完美应对带复杂标量过滤的混合检索场景。针对小数据段,系统自动切换为精确 k-NN 查找以守住精度底线。
成果:
- 性能狂飙:系统吞吐量(QPS)提升 5.5 倍。
- 体验跃升:P99 延迟降低 70%。
- 成本骤降:总成本降低 80% 以上。
创新领域五:突破跨索引 Join 难题,重塑新一代分析体验
为满足复杂分析场景中对不同索引、数据源的高效关联查询需求,团队进行了架构演进。
解决方案:实现具备独立分析节点形态的 SQL 插件,通过优化的数据传输协议与数据节点交互,实现存储与计算资源隔离。
- 分析节点侧:提供完整 SQL 语法支持与查询计划优化器,定制算子下推、Runtime Filter 策略,借助流水线加向量化执行引擎提升计算效率。
- 数据节点侧:以 Arrow 格式按 block 流式传输数据,保障节点间高效交换。
- 多数据源对接:分析节点可无缝连接 Hive、Hudi/Iceberg、MySQL、PostgreSQL 等外部数据源,实现跨数据源统一关联查询。
成果:使 OpenSearch 在处理分析型负载时具备更强的跨索引/跨数据源 Join 能力,为构建统一查询平台和实时湖仓分析奠定基础。
社区贡献案例:Apache Lucene 最新性能优化实践
Apache Lucene 是 OpenSearch 的核心底层引擎。字节云搜索团队工程师、Lucene PMC 成员郭峰分享了 Lucene 在性能优化方面的深度实践,重点介绍了通过底层 Codec 重构、向量化(SIMD)、无分支编程等手段实现的显著性能进步。
根据 Search Benchmark Game 数据,在最新的 10.3 版本中,通过一系列底层优化,Lucene 在 TopN 和 Count 等核心任务的平均性能上已追平乃至超越 Tantivy。Lucene 与 Tantivy 之间形成了良性的“兄弟社区”式互促关系。
核心优化路径解析:
- 索引结构与编解码(Codec)演进:引入 Trie 字典索引 替代部分 FST 结构,为主键查找带来约30%性能收益。为倒排链引入 Bitset 编码技术 存储稠密文档块,节省存储并暴露新接口以加速交并集查询与 Count 性能。
- 榨干硬件潜力:向量化与 SIMD:深度集成 Java Vector API,利用 SIMD 指令在单周期内并行处理数据,在“寻找块内首个大于目标值的文档”等热点路径上获得直接性能增益。
- 优化指令流水线:无分支与减少虚函数:
- 无分支编程(Branchless):通过代码重构,使编译器生成
cmov 等非跳转指令,避免分支预测失败导致的流水线停顿,部分热点函数获得数倍提速,端到端性能提升约10%。
- 减少虚函数调用(Less Virtual Call):将虚函数调用提取到循环外部,减少高频循环中的 vtable 查找开销。
在新的 Lucene 10.4 版本中,计划将倒排块大小从128扩展至256,这将进一步放大向量化与无分支编程的收益。
面向未来:现代化、可扩展、智能化、可观测的搜索新范式
展望未来,字节跳动将继续围绕 现代化、可扩展、可观测、智能化 方向,与社区共同探索下一代搜索范式。
- 持续推进搜索能力现代化:打磨基于 Vamana 与 RaBitQ 的向量检索方案,利用 GPU 算力,支持原生多租户,并向万亿级向量规模演进。
- 深化可观察性与分析能力:引入更先进列式存储与计算技术,优化复杂查询与聚合分析性能,在数据湖侧原生支持日志与向量数据,打通检索、分析与模型训练。
- 强化可扩展性与弹性:建设基于大数据引擎的外部索引服务,剥离大规模索引构建压力;通过并发 translog 快照回放、搜索与索引职能分离、远程 translog 等一系列存算分离架构优化,提升高并发、故障恢复与跨地域部署能力。
- 开放拥抱社区与生态:深度参与并回馈 OpenSearch 与 Lucene 社区,积极对接 LangChain、OpenClaw 等主流 AI 生态,打通上层应用框架与底层检索引擎。
总结
从 Lucene 内核的指令级优化,到 OpenSearch 的存算分离架构重塑;从向量搜索的工程落地,到跨索引分析引擎的构建,字节跳动在开源搜索领域的探索源于对技术本质的尊重与对业务场景的深刻理解。李亚坤表示:“我们坚信开源的力量,字节跳动将持续深化与 OpenSearch、Lucene 社区的合作,共同构建一个更强大、更高效、更智能的搜索生态。” 这不仅是承诺,更是与全球开发者并肩前行,推动数据与 AI 深度融合,创造更丰富价值的实践。
欢迎对云原生、数据智能与搜索技术感兴趣的朋友,前往 云栈社区 交流更多实践经验与技术思考。
 发表于 2026-4-11 04:29:33
|
查看: 231|
回复: 0
发表于 2026-4-11 04:29:33
|
查看: 231|
回复: 0
