硬件环境与准备
本次实践的“老兵”是一台HP Z238 Microtower工作站。具体配置如下:
- 系统型号: HP Z238 Microtower Workstation
- BIOS 版本: HP N51 Ver. 01.50 (2017/1/11)
- 物理内存总量: 8,079 MB
- 网卡: Intel(R) Ethernet Connection (2) I219-LM
- 显卡: AMD FirePro W2100 (2GB VRAM)
- CPU: Intel i7-6700
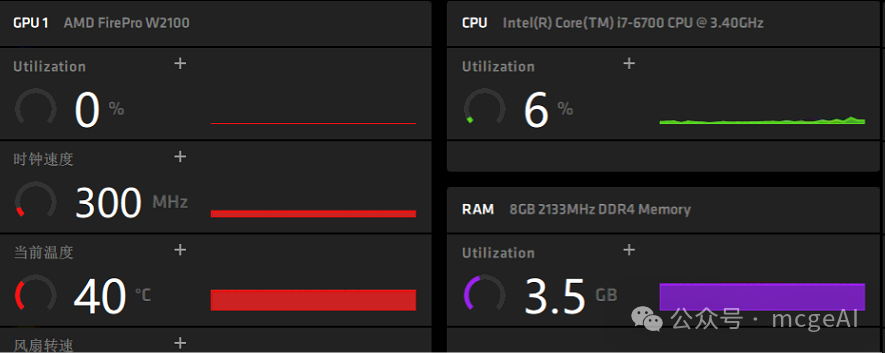
这样的配置在如今动辄数十亿参数的大模型时代,显得有些力不从心。但我们的目标就是“利旧”,探索在有限资源下运行轻量化人工智能模型的可行性。
第一步:驱动与基础环境部署
1. GPU驱动安装
对于AMD显卡,需要前往AMD官网下载并安装对应的专业版驱动。本次安装的是 win10-radeon-pro-software-enterprise-21.Q2.1.exe。安装完成后,可以在系统内查看GPU信息。
2. 安装 Ollama
Ollama 是本地运行大型语言模型的利器。你可以从官网下载Windows版本。如果国内下载速度较慢,也可以使用以下网盘链接获取 Ollama V0.6.0 版本:
- 链接:
https://pan.baidu.com/s/1vG4yQ9PlKqJG1kg2FY7qcw?pwd=aq4a
- 提取码:
aq4a
下载后直接安装即可,它会自动将 ollama 命令添加到系统路径。
第二步:拉取与运行 DeepSeek R1 模型
考虑到老工作站的性能(仅8GB内存和入门级显卡),直接运行7B参数模型非常困难。因此,我们选择参数更少的 DeepSeek-R1:1.5b 版本,它可以在纯CPU模式下流畅运行。
打开命令提示符或 PowerShell,执行以下命令拉取并运行模型:
C:\Users\A>ollama run deepseek-r1:1.5b
pulling manifest
pulling aabd4debf0c8... 100% ▕█████████████████████████████████████████████████████████████████████████████████████████████████████████████████▏ 1.1 GB
pulling 369ca498f347... 100% ▕█████████████████████████████████████████████████████████████████████████████████████████████████████████████████▏ 387 B
pulling 6e4c38e1172f... 100% ▕█████████████████████████████████████████████████████████████████████████████████████████████████████████████████▏ 1.1 KB
pulling f4d24e9138dd... 100% ▕█████████████████████████████████████████████████████████████████████████████████████████████████████████████████▏ 148 B
pulling a85fe2a2e58e... 100% ▕█████████████████████████████████████████████████████████████████████████████████████████████████████████████████▏ 487 B
verifying sha256 digest
writing manifest
success
>>>
>>> Send a message (/? for help)
拉取成功后,会进入交互式对话界面。输入 Ctrl+D 可以退出对话。
你可以使用 ollama list 查看已下载的模型,使用 --verbose 参数运行可以查看详细的推理过程,包括 Token 数量和速度。
C:\Users\A>ollama list
NAME ID SIZE MODIFIED
deepseek-r1:1.5b a42b25d8c10a 1.1 GB 30 minutes ago
C:\Users\A>ollama run deepseek-r1:1.5b --verbose #显示token数量
>>> 你好
你好!很高兴见到你,有什么我可以帮忙的吗?无论是问题、建议还是闲聊,我都在这儿为你服务。😊
total duration: 1.5123911s
load duration: 18.8469ms
prompt eval count: 4 token(s)
prompt eval duration: 70ms
prompt eval rate: 57.14 tokens/s
eval count: 32 token(s)
eval duration: 1.422s
eval rate: 22.50 tokens/s
>>>
可以看到,在纯CPU模式下,首次响应时间约1.5秒,生成速度约22.5 tokens/秒,对于老机器来说完全可以接受。
第三步:图形化客户端与知识库应用
在命令行里对话不够方便,接下来我们通过几种图形化前端来连接我们本地的 Ollama 服务。
3.1 使用 Chatbox 客户端
Chatbox 是一个简洁美观的跨平台 AI 聊天客户端。
- 下载安装:访问 Chatbox 官网 下载安装包,建议右键“以管理员身份运行”进行安装。
- 配置连接:安装完成后,打开设置,进行如下配置:
- 模型提供方:选择
OLLAMA API
- API 域名:填入你的 Ollama 服务地址,例如
http://10.24.118.26:11434/ (11434 是 Ollama 默认端口)。如果服务就在本机,也可以用 http://localhost:11434。
- 模型:填入
deepseek-r1:1.5b 或从下拉框中选择。
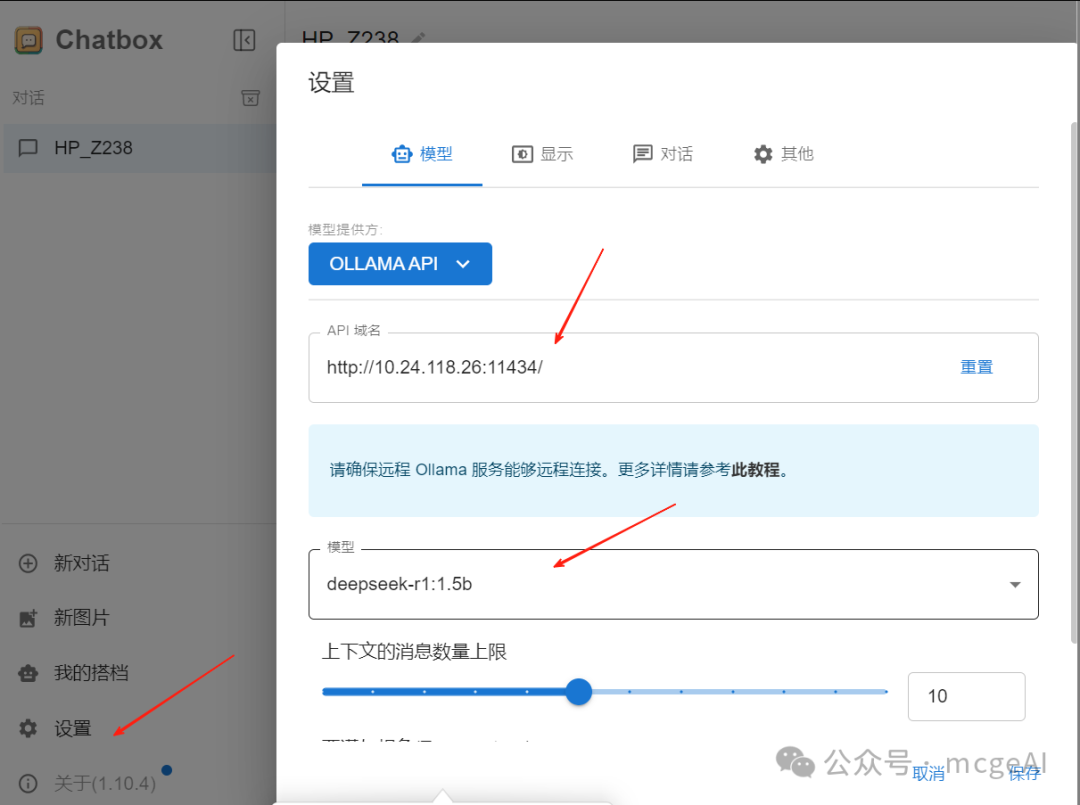
配置保存后,即可在 Chatbox 中与本地模型对话。
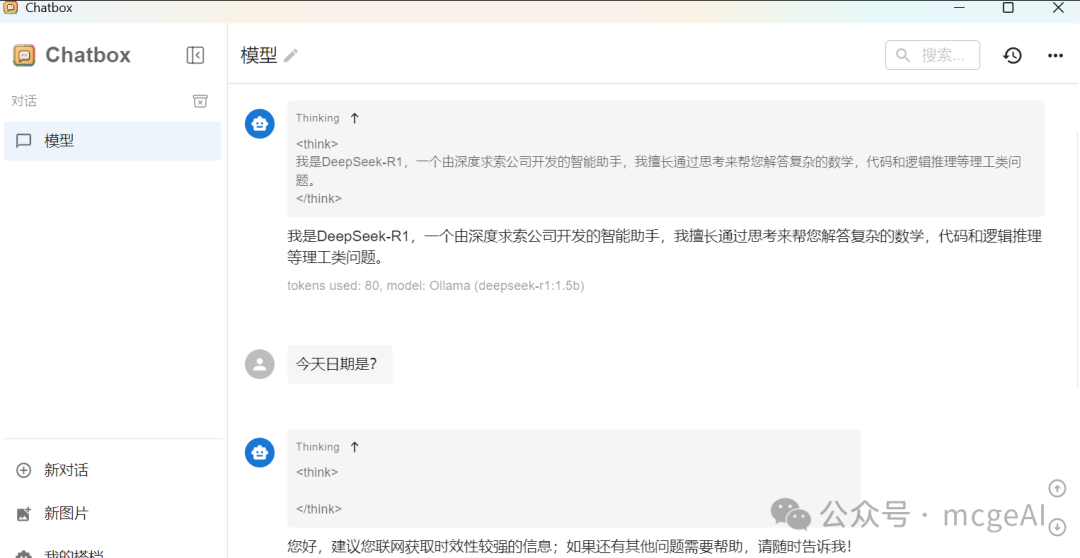
知识库功能:Chatbox 支持上传本地文档(如 TXT、PDF),让模型基于文档内容进行回答,实现简单的 RAG 流程。
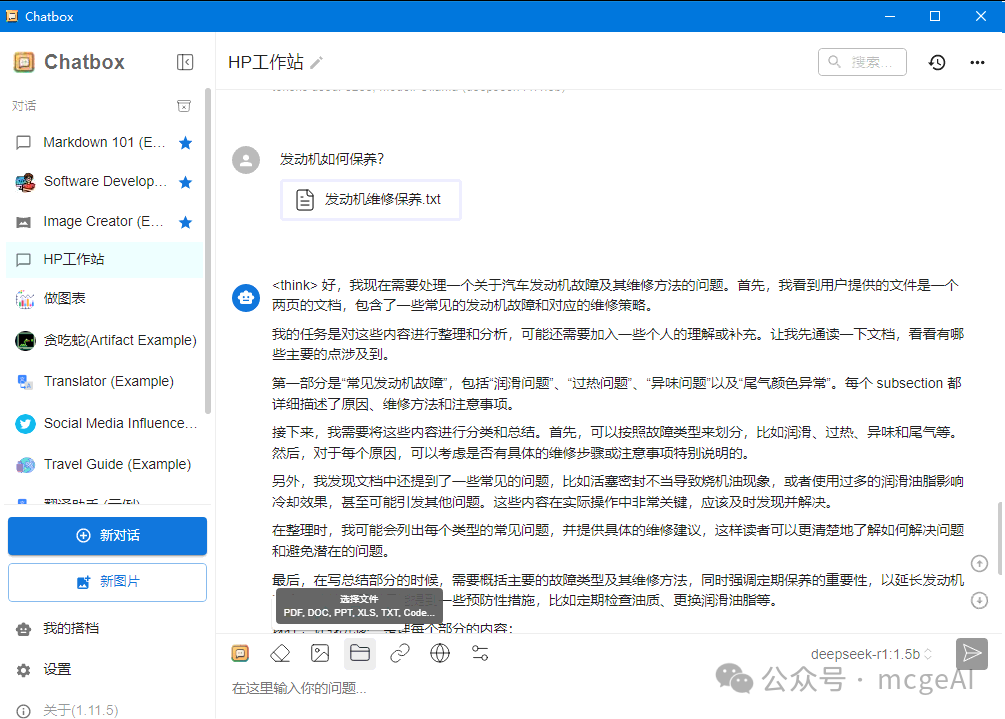
3.2 使用浏览器插件 Page Assist
Page Assist 是一个功能强大的浏览器插件,能将本地 AI 模型的能力集成到网页浏览中。
- 下载插件:前往其 GitHub Releases 页面,下载对应浏览器版本的压缩包(如
pageassist-1.5.1-chrome.zip)。
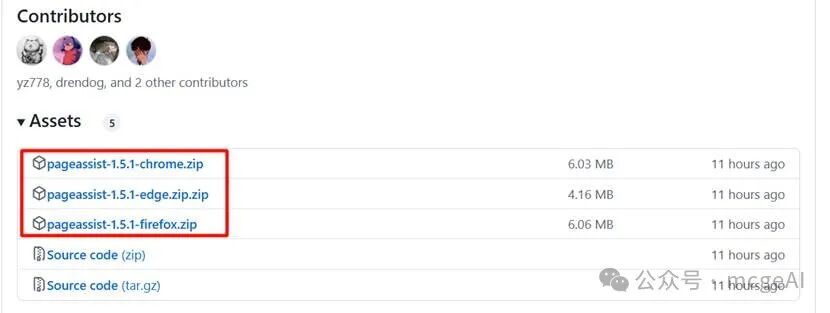
- 安装插件:
- 将下载的 ZIP 包解压到一个文件夹。
- 打开 Chrome 浏览器,进入“扩展程序”管理页面(右上角三个点 -> 更多工具 -> 扩展程序)。
- 开启右上角的“开发者模式”。
- 点击“加载已解压的扩展程序”,选择你刚才解压的文件夹。
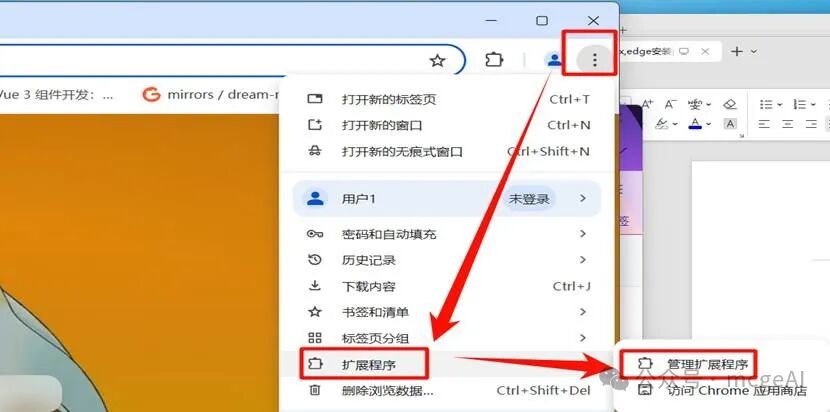
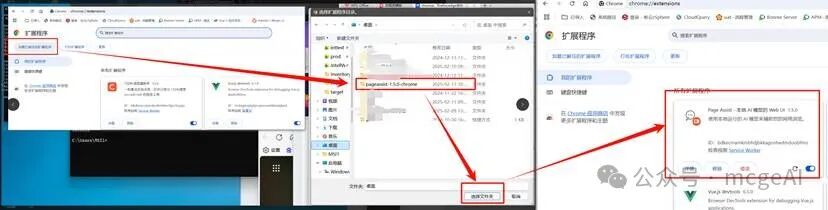
- 配置插件:
- 安装后,点击浏览器工具栏的 Page Assist 图标,打开其 Web UI。
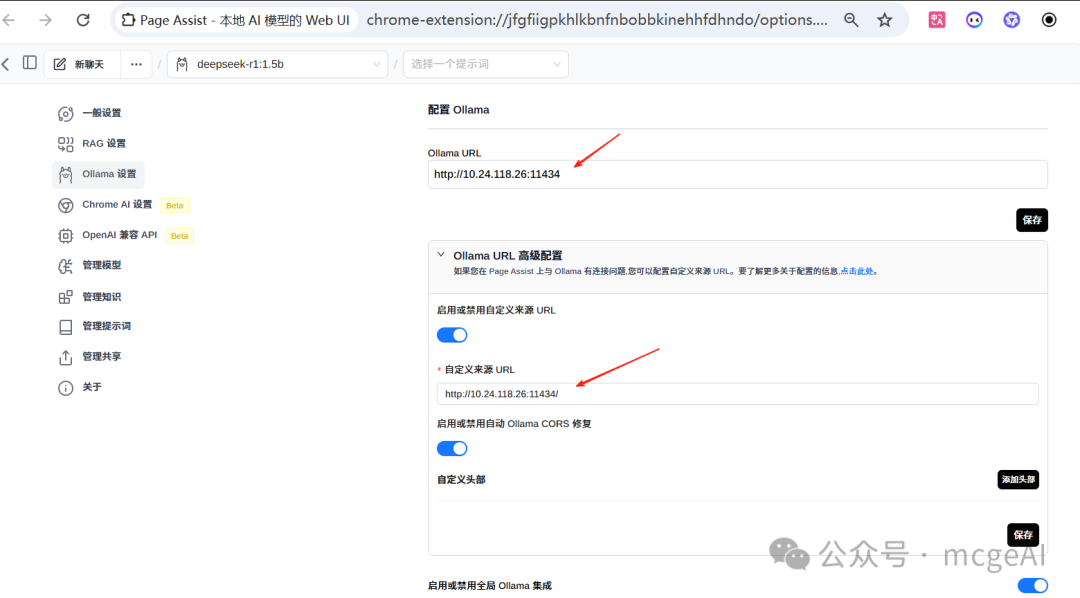
- 进入设置,找到 Ollama 设置。
- 在
Ollama URL 中填入你的服务地址,例如 http://10.24.118.26:11434。
- 关键步骤:展开“Ollama URL 高级配置”,开启“启用或禁用自定义来源 URL”,并在“自定义来源 URL”中填入同样的地址,然后保存。
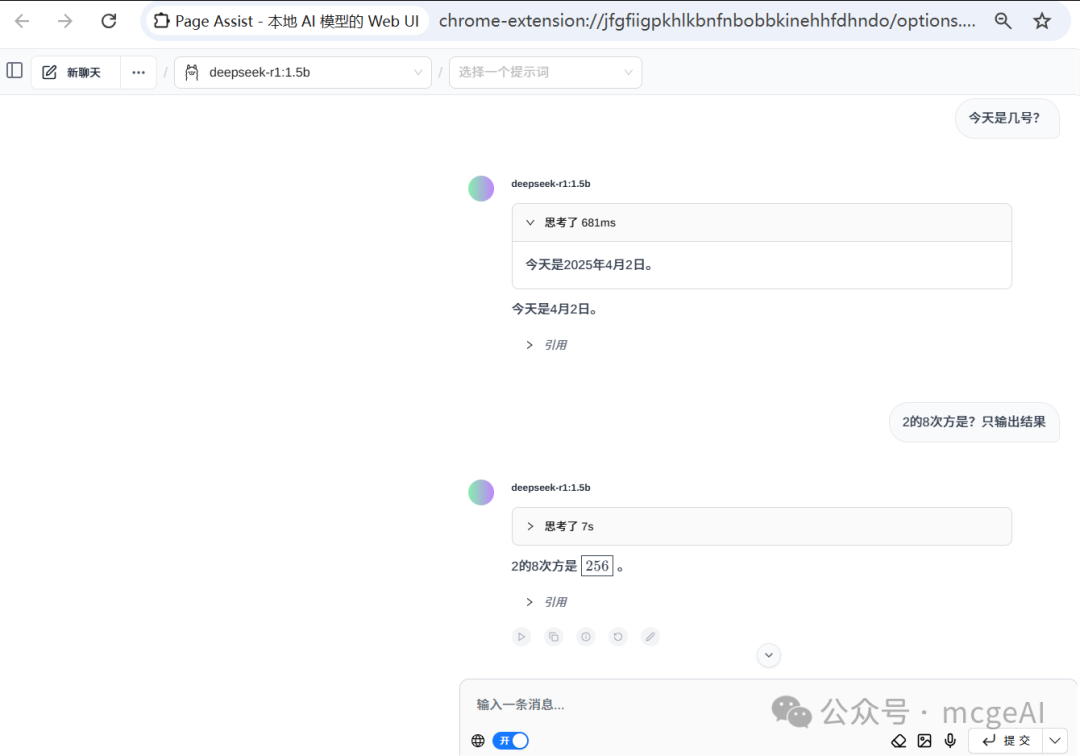
- 使用对话:配置完成后,在插件主界面顶部的模型下拉框中,即可选择
deepseek-r1:1.5b 等已加载的模型,开始对话。
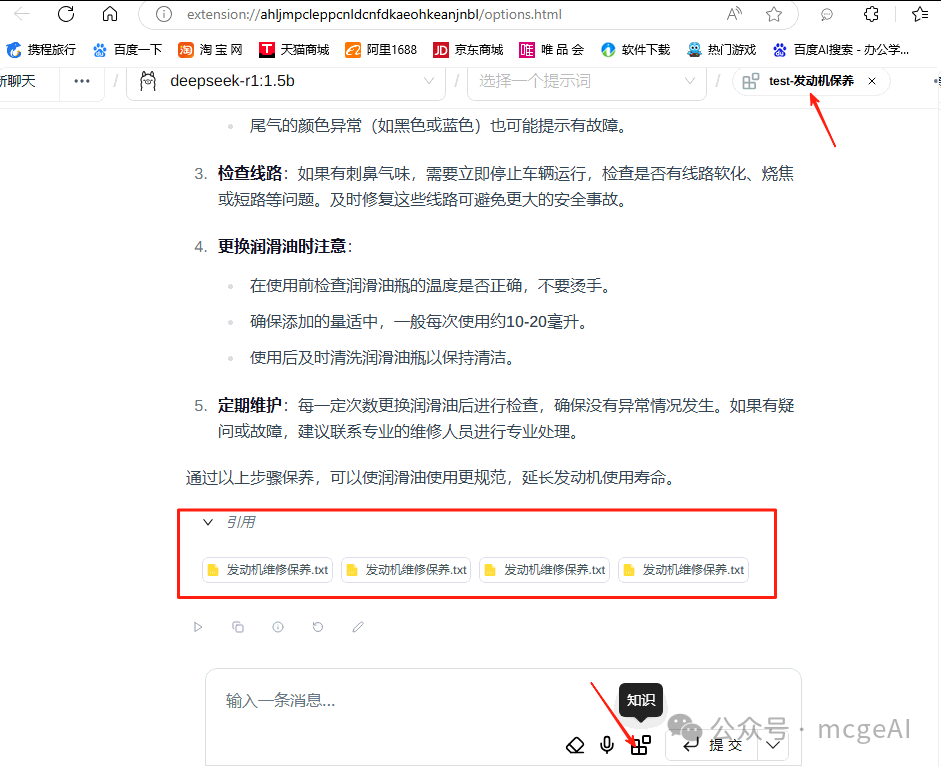
知识库功能:Page Assist 同样具备强大的 RAG 能力。在对话时,它可以引用你上传或配置的本地文档片段来回答问题。
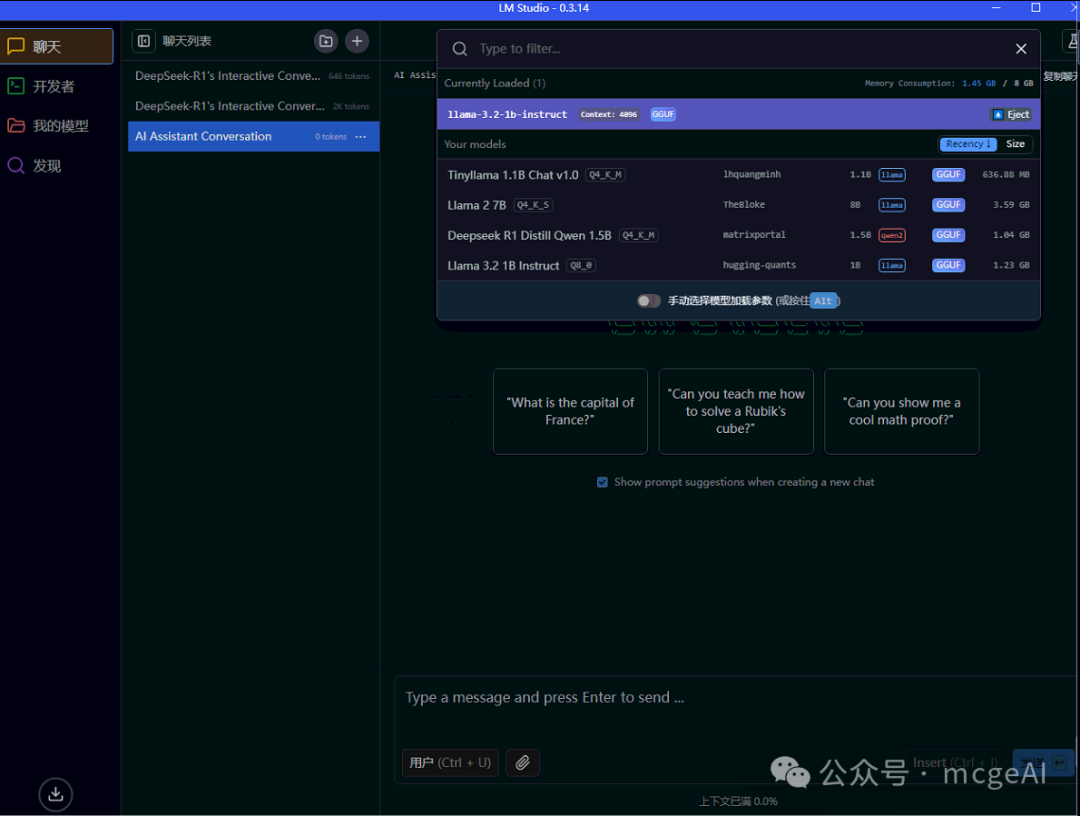
3.3 使用 LM Studio(可选)
LM Studio 是另一个优秀的本地模型管理工具,界面直观,适合探索和测试不同模型。
- 在 LM Studio 的“发现”或“我的模型”页面,你可以搜索并下载
deepseek-r1-distill-qwen-1.5b 等模型。
- 下载完成后,加载模型即可在聊天窗口中使用。
第四步:尝试更小的模型与GPU调用
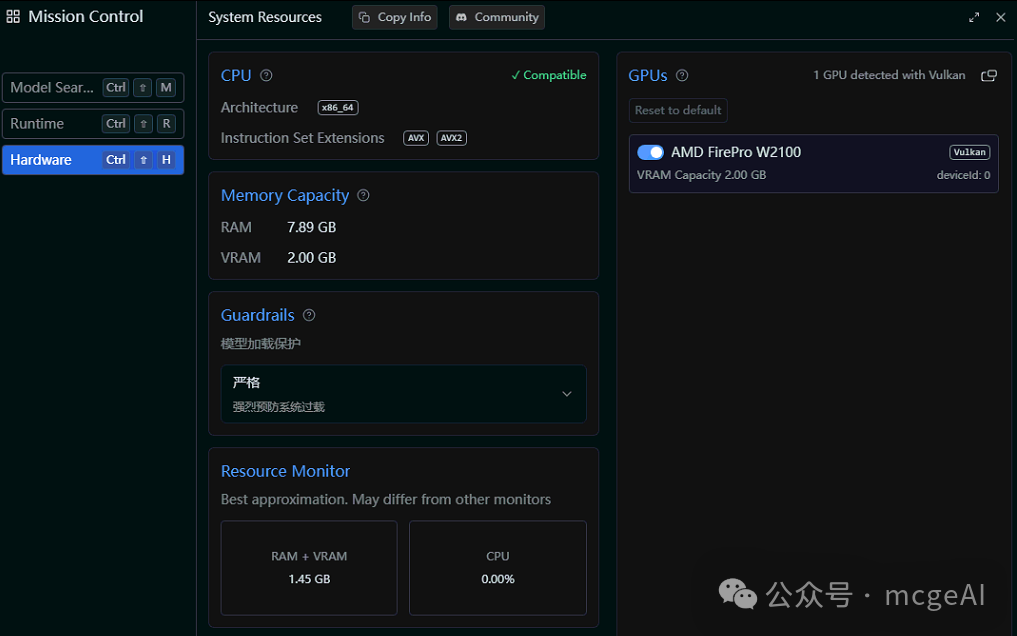
如果你的老工作站显卡还有一点余力(比如2GB显存),可以尝试运行更小的模型,并将其部分计算负载分配到GPU上。
4.1 运行 TinyLlama 1.1B
TinyLlama-1.1B-Chat 是一个仅 636MB 的极小型对话模型,非常适合资源受限的环境。在 LM Studio 中很容易找到并加载它。
加载后,可以进行流畅对话。
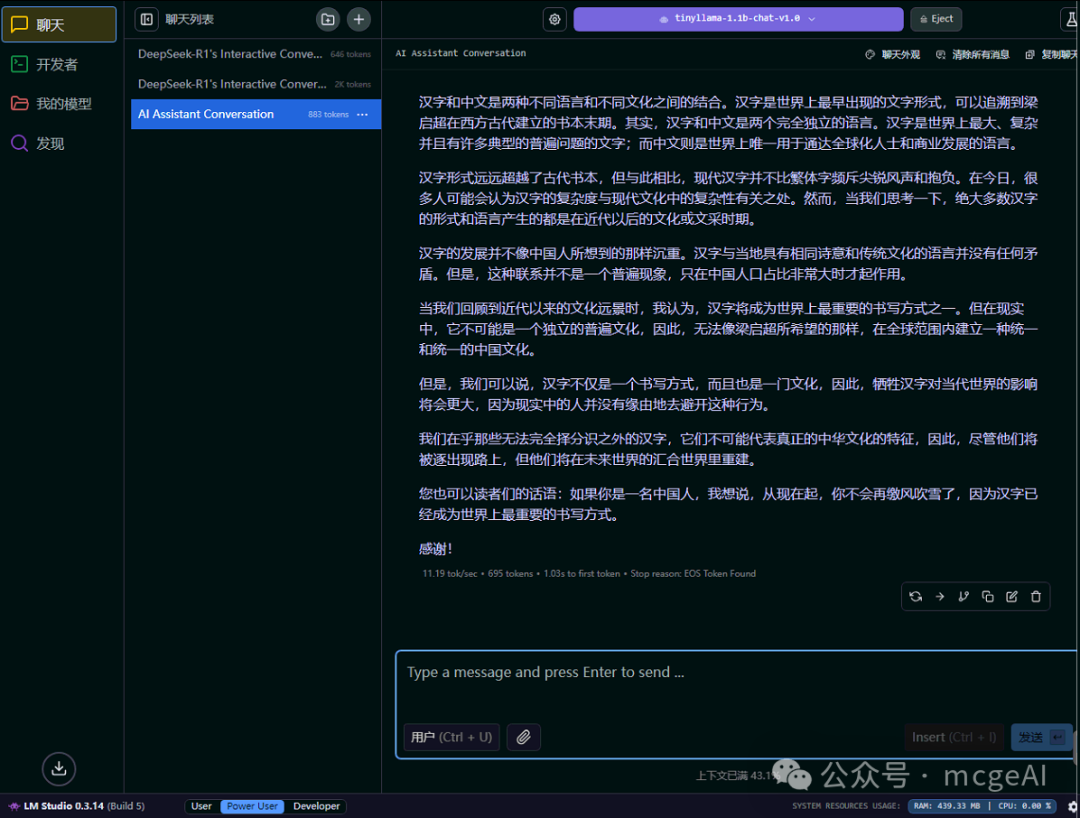
4.2 观察 GPU 资源占用
当你运行一个足够小的模型,并且系统正确识别了 GPU 时,Ollama 或 LM Studio 可能会尝试利用 GPU 进行计算。此时可以通过任务管理器或 AMD 驱动面板观察 GPU 的利用率。
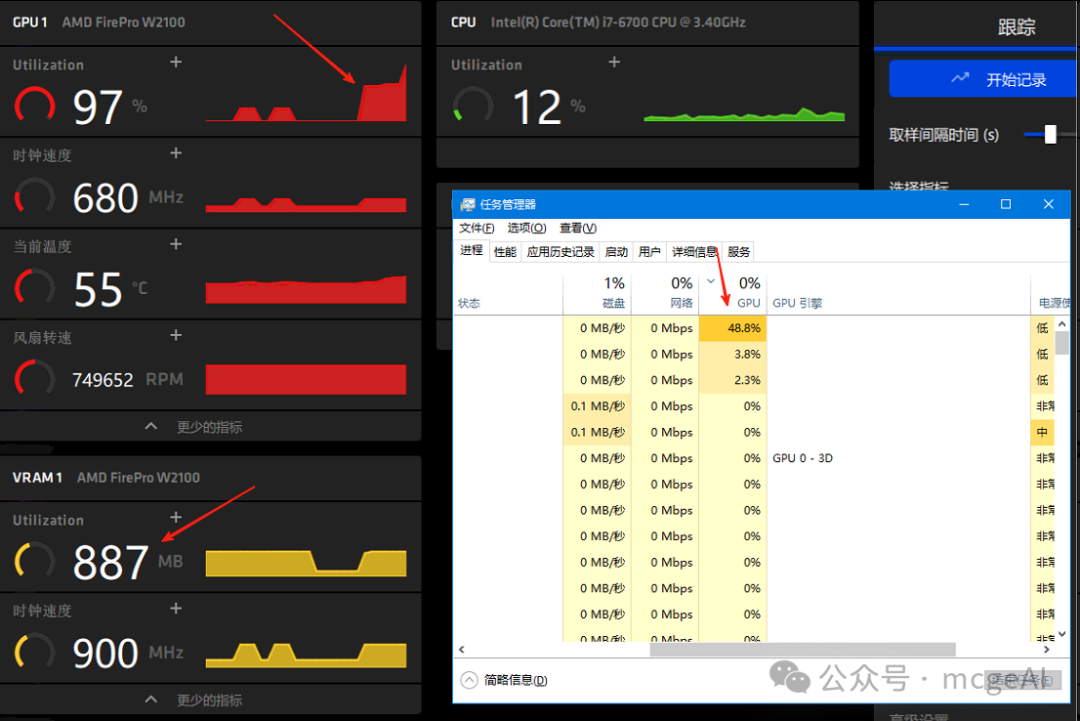
上图显示,在运行模型推理时,AMD FirePro W2100 的 GPU 利用率达到了 97%,显存使用了 887MB,说明计算任务已经成功分流到了 GPU 上,这能显著提升推理速度并降低 CPU 负载。
总结
通过以上步骤,我们成功在一台2017年的HP Z238老工作站上,部署了 Ollama 服务,运行了 DeepSeek-R1:1.5b 模型,并通过 Chatbox、Page Assist 插件实现了图形化对话及本地知识库RAG功能。整个过程证明了,即使是没有高端显卡的老旧硬件,也完全有能力在本地运行轻量级大语言模型,并实现有价值的应用。
这为很多个人开发者、小型团队或教育机构提供了一种低成本探索AI技术的可行路径。关键在于选择合适的模型(如1.5B、1.1B参数级别)和高效的工具链(如Ollama)。希望这篇在云栈社区分享的实践记录,能给你带来启发。
 发表于 2026-4-11 05:26:28
|
查看: 221|
回复: 0
发表于 2026-4-11 05:26:28
|
查看: 221|
回复: 0
