最近,我花了些时间,从零开始用 Rust 搭建了一个完整的多租户AI Agent云平台——RustClaw。市面上火热的OpenClaw,本质上也是一个 Agent 框架,算不上全新概念。但我这个版本,用 4130 行 Rust 加上 1220 行 TypeScript,实现了很多项目几万行代码才能做到的功能:一个能真正执行代码、操作文件、搜索网页、安装技能的智能体。
光说不练假把式,咱们先看看实际效果。
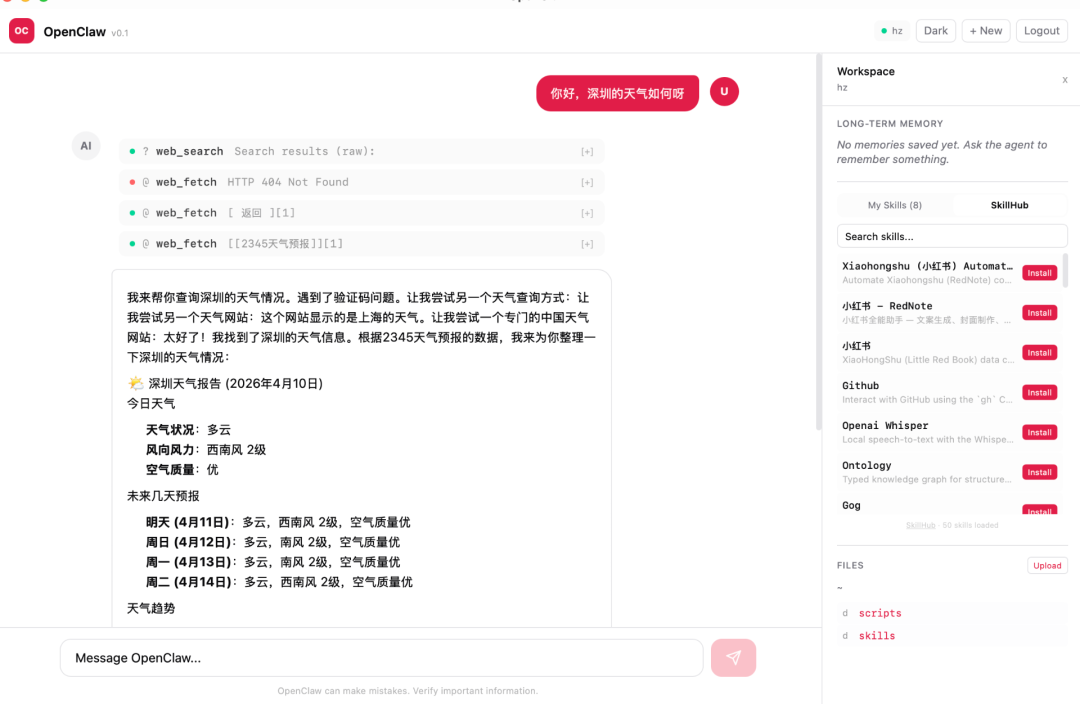
这是一个桌面应用,左侧是聊天区,右侧面板展示记忆、技能市场和文件管理。乍一看和普通聊天界面区别不大?关键区别在于它“动真格”的能力:当我输入“帮我创建一个 hello.py 并运行它”时,Agent 不是只给出文字指导,而是真的去执行了。
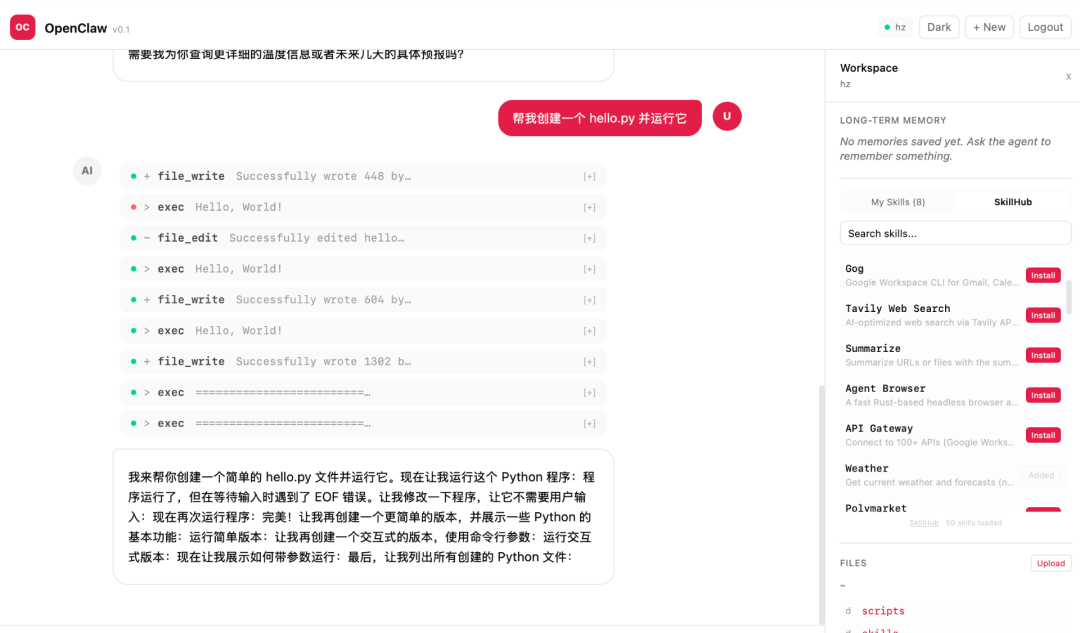
[tool_start] file_write: 创建 hello.py
[tool_result] 写入成功 (42 bytes)
[tool_start] exec: python3 hello.py
[tool_result] hello from openclaw agent
[done] 文件已创建并运行,输出是 "hello from openclaw agent"
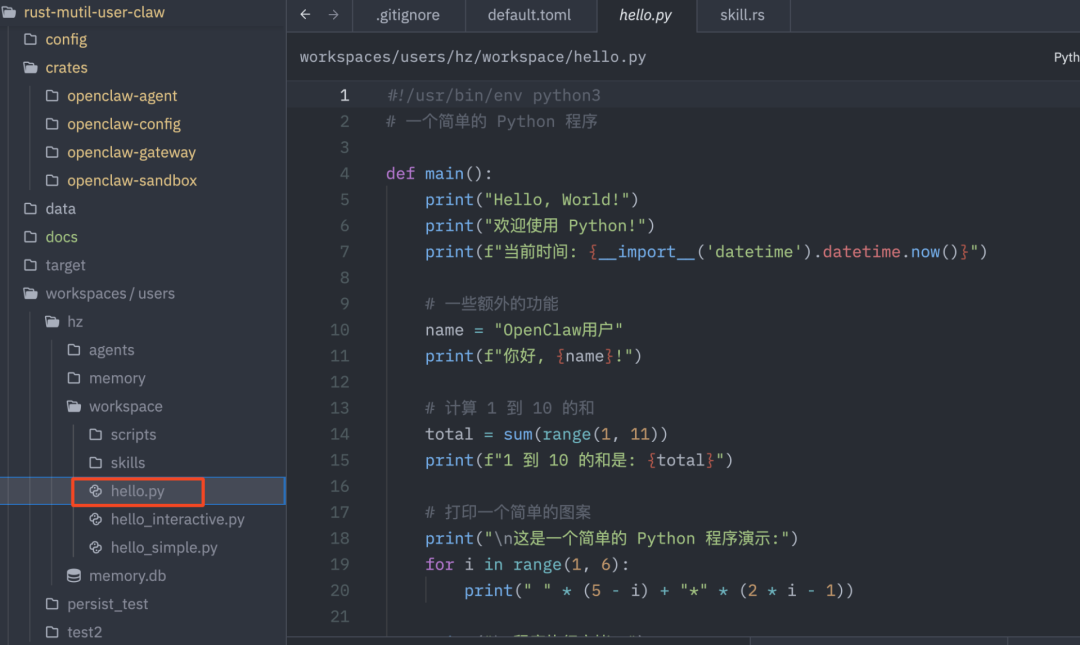
文件被真实地写入到了隔离的租户工作空间下。每一步都是真实的工具调用,而非模拟。
为什么选择自己造轮子?
市面上已有不少方案:
- Dify / Coze —— 功能足够,但闭源,数据不掌握在自己手中。
- LangChain —— 基于 Python 生态,依赖管理复杂,部署体验一言难尽。
- OpenClaw (Node.js) —— 设计很好,但我想要一个 Rust 版本:单二进制、零依赖、内存占用极低。
我的核心需求很明确:
✅ 单二进制部署,不需要 Docker Compose 编排一堆服务
✅ 每个用户拥有隔离的沙箱环境,互不干扰
✅ Agent 能自主决策并调用真实工具
✅ 支持 MCP 协议,可接入浏览器自动化等生态
✅ 具备技能市场,用户可以按需安装新能力
✅ 提供桌面客户端,当然也支持通过其他端连接云端部署
架构设计:四个 Crate,各司其职
整个后端由四个清晰的 Crate 组成:
openclaw-gateway → Axum HTTP/WebSocket 网关,负责 JWT 鉴权
openclaw-agent → Agent 核心:LLM 交互、工具注册、技能管理、记忆、MCP 集成
openclaw-sandbox → 沙箱隔离:文件夹隔离 + 路径防穿越 + 命令执行超时控制
openclaw-config → TOML 配置解析
前端则是一个 Tauri + React 构建的桌面客户端。这里最令我满意的设计决策是:不搞复杂的微服务,单进程搞定一切。凭借 Rust 的并发模型(tokio),完全能够胜任。
Agent Loop —— 系统的灵魂
市面上 99% 的“AI 应用”本质上是:用户 → LLM → 文本回复。这充其量是个“转发器”,而非真正的 Agent。
真正的 Agent 应该是一个循环决策过程:
用户消息 → LLM 决策 → 调用工具 → 结果回传 LLM → 可能再调工具 → ... → 最终回复
我的核心循环实现如下:
for iteration in 0..20 { // 最多 20 轮,防止死循环
let response = llm.chat_with_tools(&messages, &tools).await?;
if response.has_tool_calls() {
for tc in response.tool_calls {
let result = tool_registry.execute(&tc.name, tc.params).await; // 每个工具有 60 秒超时
messages.push(tool_result(tc.id, result));
}
} else {
return Ok(response.content); // 得到最终回复,结束循环
}
}
关键细节控制:
- 每个工具执行有 60 秒超时。
exec 命令有 30 秒超时,超时自动终止子进程。- 最多进行 20 轮 循环,防止 LLM 陷入逻辑死循环。
- 全程支持 token-by-token 流式输出,用户体验无需长时间等待。
10个内置工具:覆盖基础能力
我预置了不多不少 10 个工具,刚好覆盖一个自主 Agent 所需的基本操作能力:
| 工具 |
功能 |
exec |
执行任意 shell 命令(支持管道、重定向) |
file_read / file_write / file_edit |
对文件进行读、写、编辑操作 |
list_files |
列出目录内容 |
apply_patch |
应用补丁文件 |
web_search |
使用搜索引擎 |
web_fetch |
抓取网页,并自动将 HTML 转换为 Markdown |
memory_search / memory_get |
搜索和读取用户的长期记忆 |
所有工具都实现同一个 Trait,注册到 ToolRegistry 后,即可自动生成供 OpenAI function calling 使用的 JSON Schema:
#[async_trait]
pub trait Tool: Send + Sync {
fn name(&self) -> &str;
fn description(&self) -> &str;
fn parameters_schema(&self) -> Value;
async fn execute(&self, params: Value) -> ToolResult;
}
想要增加新工具?只需实现这四个方法并注册即可。
MCP 协议:接入无限工具生态
MCP(Model Context Protocol)是由 Anthropic 推出的开放协议。简单来说,它让 AI Agent 能够连接任何符合协议的外部工具服务器。
我用了大约 150 行 Rust 实现了完整的 MCP 客户端。只需在配置文件中添加如下配置:
[[mcp.servers]]
name = "playwright"
command = "npx"
args = ["-y", "@playwright/mcp@latest"]
启动后,Agent 便自动获得了 Playwright 的所有浏览器自动化能力。当用户说“打开百度搜索 Rust”,Agent 就会真的启动浏览器去执行操作。
技术实现要点:
- Stdio 传输:启动子进程,通过 stdin/stdout 进行通信。
- JSON-RPC 2.0:使用请求-响应配对机制,通过 oneshot channel 处理。
- 自动发现:调用
tools/list 获取 MCP 服务器提供的工具列表,并自动注册到系统的 ToolRegistry。
- 超时控制:每个 MCP 请求都有 30 秒 的超时限制。
技能系统:复用成功经验
如果说工具是 Agent 的“手脚”,那么技能就是它的“大脑”。一个技能本质上是一个结构化的提示词,指导 Agent 在特定场景下按特定流程使用工具。
一个技能就是一个 SKILL.md 文件:
---
name: weather
description: 查询任意城市天气
---
当用户问天气时:
1. 用 web_search 搜索该城市天气
2. 用 web_fetch 获取详细数据
3. 整理成温度、湿度、风速格式展示
这其实是一种结构化的提示词,教会 Agent 在什么场景下,按什么步骤调用哪些工具。
技能有三种获取方式:
- 内置 6 个基础技能:如 weather(查天气)、coding(编程助手)、research(研究分析)等。
- SkillHub 技能市场:集成了多个技能源,提供 107+ 个技能 供用户一键安装。这里有个技术亮点:后端并发请求多个数据源,合并并去重后返回给前端。
let (search_res, cos_res) = tokio::join!(
client.get(&clawhub_url).send(),
client.get(&tencent_cos_url).send(),
);
// 合并两个来源的结果,按唯一标识去重
- 对话创建:直接告诉 Agent“帮我创建一个自动格式化代码的技能”,它会利用内置的
skill-creator 技能,自动编写出 SKILL.md 文件并存入工作区。
记忆系统:实现跨会话持续记忆
记忆不仅仅是存储聊天记录。每个用户的工作区都有清晰的结构:
workspaces/users/{user_id}/
├── workspace/
│ ├── MEMORY.md ← 长期记忆,每次对话自动加载
│ └── memory/
│ └── 2026-04-09.md ← 当日的上下文日志
└── memory.db ← SQLite 存储的完整聊天历史
每次开始新对话时,Agent 会自动读取 MEMORY.md 和最近两天的日志,将其作为系统提示词的一部分注入。例如,用户说“记住我喜欢用 Python”,Agent 会通过 file_write 工具将这条信息写入 MEMORY.md,下次对话时它依然记得。前端侧边栏会实时展示这些记忆内容。
多租户隔离:安全与独立的基石
这是设计的核心挑战之一,目的是确保每个用户拥有完全独立、互不干扰的:
- 📁 文件工作区(需严防路径穿越攻击)
- 🧠 记忆文件
- 🔧 已安装的技能集合
- 💬 聊天历史记录
- 🔑 JWT 认证令牌
用户注册/登录后获得 JWT,之后在任何设备上使用同一账号,都会映射到同一个隔离空间。
路径安全是重中之重,我们通过 normalize_path 结合 starts_with 进行双重校验:
fn safe_path(&self, user_id: &str, relative: &Path) -> Result<PathBuf> {
let root = normalize_path(&self.user_root(user_id));
let normalized = normalize_path(&root.join("workspace").join(relative));
if !normalized.starts_with(&root) {
bail!("Path escape detected"); // 想通过 ../../etc/passwd 逃逸?没门。
}
Ok(normalized)
}
从单进程到水平扩展:多进程架构改造
完成核心功能后,我们面临一个现实:整个系统是单进程的。启动第二个实例会导致用户数据丢失、Session 失效、限流策略形同虚设。
问题有多严重?
Process A (8080) Process B (8081)
┌──────────────┐ ┌──────────────┐
│ UserStore: │ │ UserStore: │
│ zhang → pwd │ │ (空) │ ← zhang 在 A 注册,B 不认识
│ Sessions: │ │ Sessions: │
│ zhang → agt │ │ (空) │ ← 负载均衡到 B,session 丢了
│ RateLimit: │ │ RateLimit: │
│ zhang: 5次 │ │ zhang: 0次 │ ← 实际能发起双倍请求
└──────────────┘ └──────────────┘
六个核心组件的状态全部存储在内存中,无法跨进程共享。
改造方案:状态外置
我们主要做了四件事:
-
UserStore → SQLite 持久化
将原本存储在内存 HashMap 中的用户数据迁移到 SQLite 数据库,实现重启不丢失,多进程可共享同一数据源。
-
Session → 二级缓存 + 按需重建
Session 中包含 AgentRunner 等复杂状态,难以序列化。我们的方案是:本地 LRU 缓存热数据 + 缓存未命中时从磁盘重建。
pub struct SessionManager {
sessions: DashMap<String, Session>, // 本地缓存
lru_order: Mutex<VecDeque<String>>, // LRU 淘汰队列
max_cache_size: usize, // 例如 100
}
所有会话状态(记忆、技能、聊天历史)都已持久化在磁盘上。Cache miss 时重建耗时约 100ms。
-
StorageBackend 抽象层
所有文件操作不再直接使用 tokio::fs,而是通过一个统一的 Trait 接口:
#[async_trait]
pub trait StorageBackend: Send + Sync {
async fn read(&self, path: &str) -> Result<Vec<u8>>;
async fn write(&self, path: &str, data: &[u8]) -> Result<()>;
async fn list(&self, prefix: &str) -> Result<Vec<String>>;
async fn exists(&self, path: &str) -> Result<bool>;
async fn delete(&self, path: &str) -> Result<()>;
}
目前实现了 LocalStorage,未来可轻松替换为 S3/MinIO 等对象存储,实现真正的分布式存储。
-
MCP 连接池
为了避免每个用户都独立启动 MCP 服务子进程导致内存爆炸,我们实现了 MCP 连接池,让多个用户共享连接实例,用完后归还池中复用。
多节点部署配置示例:
[database]
url = "sqlite:./data/openclaw.db?mode=rwc" # 多进程共享同一个数据库文件
[session]
backend = "memory" # 对于单节点部署,内存缓存足够高效
local_cache_size = 100
配合 Nginx,可以通过用户授权头信息进行一致性哈希,实现会话亲和性:
upstream openclaw {
hash $http_authorization consistent;
server gateway-a:8080;
server gateway-b:8080;
}
桌面客户端:Tauri + React
前端技术栈为 Tauri 2.0 + Vite + React + Tailwind CSS,由大约 10 个核心组件构成,包括登录界面、聊天视图、消息气泡、工具调用卡片、输入栏、记忆侧边栏、技能面板、文件面板等。
一个关键技术点是 SSE 流式响应的处理,核心 Hook 大约 70 行:
for await (const event of chatStream(token, text)) {
switch (event.type) {
case 'text': msg.content += event.content; break;
case 'tool_start': msg.toolCalls.push({...}); break;
case 'tool_result': updateLastTool(event); break;
case 'done': msg.isStreaming = false; break;
}
}
Tauri 应用启动时会自动拉起后端进程,退出时自动关闭,用户无需手动管理任何服务。
下一步规划
- Agent 自我进化:参考 Hermes 等项目的思路,让 Agent 能利用 skill-creator 为自己编写新技能。
- 多 Agent 协作:在前端支持切换不同的 Agent 角色(如程序员、研究员、写手)并协作。
- 语音交互:集成 Whisper 进行语音输入,以及 TTS 语音输出。
- 知识库 RAG:支持上传文档,进行向量检索,增强回答能力。
- Redis Session:实现真正的分布式 Session 共享。
- S3 存储层:为
StorageBackend 接入对象存储后端。
- 移动端:利用 Tauri 向 iOS/Android 平台扩展。
写在最后
这个项目证明了:用 Rust 构建一个功能完备的 AI Agent 云平台,不仅是可行的,而且可以非常优雅。
从单进程原型到支持水平扩展的云架构,总计 5000 多行代码,涵盖了一个 AI Agent 平台应有的核心模块:自主 Agent 循环、10 个基础工具、MCP 协议集成、技能市场、持久化记忆、多租户隔离、Token 流式输出、LRU Session 缓存、存储后端抽象以及完整的桌面客户端。
单二进制、极低内存占用、强大的类型安全、高效的异步并发——这些都是 Rust 与生俱来的优势。
项目代码已在 GitHub 上开源,欢迎感兴趣的朋友查看、Star 或一起贡献,目标是打造性能最好的 Agent 平台之一。如果你也在进行 AI Agent 相关的 开源实战 或对 Rust 后端开发感兴趣,也欢迎在 云栈社区 交流讨论。希望这个实践能让更多人看到 Rust 在 AI 工程化领域的强大潜力。
 发表于 2026-4-11 06:43:55
|
查看: 200|
回复: 0
发表于 2026-4-11 06:43:55
|
查看: 200|
回复: 0
