当我们与Claude、ChatGPT这类大型语言模型对话时,一个根本性的问题常常浮现:“我究竟在跟什么东西交流?”
它是一个高级的自动补全程序?一个复杂的搜索引擎?还是一个具备真正思考能力的“存在”?
如果它真的能思考,那么它的“思维”过程是怎样的?它内部究竟在发生什么?
最近,Anthropic的研究人员坦诚地给出了一个令人略感不安的答案:
“It turns out rather concerningly that nobody really knows the answer to those questions.”
“令人担忧的是,事实证明,没有人真正知道这些问题的答案。”
我们创造了这些无比强大的AI,但它们内部的运作方式,对我们来说仍然是一个深邃的“黑箱”。我们只能看到输入和输出,而中间那片由数十亿参数构成的广阔“思维”海洋,却依然笼罩在迷雾之中。
为了解答这个问题,一支跨学科的特别团队被组建起来。团队中包括了神经科学家、数学家,甚至病毒进化生物学家,堪称AI神经科学领域的“复仇者联盟”。
“I was a neuroscientist. Now here I am doing neuroscience on the AIs. So now I’m doing this kind of biology on these organisms we’ve made out of math.”
“我本是一名神经科学家。现在我在这里对这些AI进行神经科学研究。所以,我现在是在对这些我们用数学创造出来的‘生物体’做这种生物学研究。”
他们的使命,就是撬开大模型的“脑壳”,进行一次彻底的“脑部扫描”,以理解当我们提出问题时,其内部究竟在发生什么。
继续读下去,你会发现一些可能颠覆你对大模型认知的真相。
1. LLM真的只是在“预测下一个词”吗?
一个普遍的说法是:大型语言模型(LLM)的本质,就是根据前面的内容,逐字逐词地预测下一个最可能出现的词或标记。
如果这是全部真相,那么一个核心矛盾便出现了:如果大模型所做的一切仅仅是预测下一个词,那么从原理上讲,它如何能创作出复杂的诗歌、生成可运行的代码,甚至进行数学运算?
要知道,人类掌握这些技能,依靠的可不仅仅是“预测下一句说什么”这么简单。
Anthropic的研究人员澄清了这个误解。他们的核心洞见,在于区分了“最终目标”和“实现过程”。
从生物学角度类比会更容易理解:人类是一种动物,其生物属性决定了我们的终极演化目标——生存与繁衍。
但你会反驳说:“我每天起床,满脑子想的可不是怎么生存繁衍!” 这显然是将目标与过程混淆了。
为了实现生存繁衍这个宏大目标,经过数百万年的进化,我们的大脑发展出了一系列极其复杂的中间过程:我们拥有情感、会制定计划、能理解抽象概念、还会为未来焦虑。
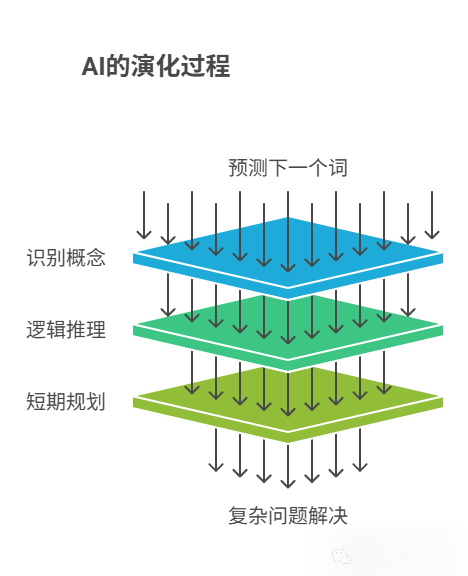
AI也是如此。“预测下一个词”是AI的训练目标,就像生存繁衍是我们的演化目标一样。但这个目标本身,并不是AI在解决具体问题时的即时“思考”过程。
为了更精准地预测出那个“正确的”下一个词,模型被迫演化出了一套庞大的内部“思维工具”:它学会了识别概念、进行逻辑推理、甚至制定短期规划。
研究人员为何如此肯定?因为他们进行了一系列严谨的实验。
“The model doesn’t think of itself necessarily as trying to predict the next word. Internally, it’s developed potentially all sorts of intermediate goals and abstractions that help it achieve that kind of meta objective.”
“模型本身未必认为自己在试图预测下一个词。在内部,它可能已经发展出了各种各样的中间目标和抽象概念,以帮助它实现那种元目标。”
所以,说LLM“只是在预测下一个词”,既对,也不对。在技术定义上,这是事实。但如果你想理解AI究竟如何工作、在想什么,这个说法具有极大的误导性。正如一位研究员所说:“它在技术上是真实的,但它并不是理解它们如何工作的最有用视角。”
2. 深入“大脑”:AI神经科学家的“脑部扫描”发现了什么?
Anthropic的研究并非凭空猜测。他们开发了一套工具,能够像功能性核磁共振成像一样,实时观察模型内部数百万“神经元”的活动。
例如,当模型处理“金门大桥”这个信息时,他们能清晰地看到哪些内部特征被“激活”了。这种方法极具神经科学的色彩,得益于团队内不同领域专家的通力合作。
通过这种方法,他们发现了模型“大脑”深处隐藏的一些“概念”。这里需要澄清:这些概念并非研究员预设的,而是通过“无假设”的科学方法从数据中自然浮现出来的,其中一些甚至相当出人意料。
比如,研究人员发现,模型的大脑中有一个专门处理 “浮夸赞美” 的区域。当用户输入“哇!你这个例子真是太棒了!简直是神来之笔!”这类话语时,这个独特的“社交信号探测器”就会被强烈激活。
这不禁让人联想到人类在“战术互夸”中获得的社交愉悦感。没错,模型已经学会了捕捉人类的社交信号。
另一个有趣的案例关乎数学能力。一个经典的问题是:大模型如何进行数学计算?它真的理解数字吗,还是仅仅在死记硬背?
研究人员惊奇地发现,当模型计算 6 + 9 时,它并非直接回忆答案“15”,而是在大脑中激活了一个通用的“加法”电路。无论是直接做算术,还是在推断“某创办于1959年的期刊,其第6卷是哪年出版”时,模型激活的都是同一个处理数字的计算回路。
这表明,模型进行数学运算时,已经具备了一定的通用数学概念,而不仅仅是模式匹配。
3. “读心术”:我们如何知道AI在“规划”和“推理”?
这些发现固然惊人,但引出了一个更深层的问题:如何证明这些被激活的“概念”与模型的实际行为之间存在因果关系,而不仅仅是相关?这些概念真的在驱动模型的行为吗?
为此,研究人员进行了更为激进的“干预实验”——像神经外科医生一样,对AI的“大脑”进行精准的“微创手术”。这项工作相比真正的人类神经科学有一个巨大优势:可完美控制变量。他们可以创造无数个相同的模型副本,并精确控制输入,或对“大脑”的特定部分进行激活或抑制。
让我们看看他们具体做了哪些实验。
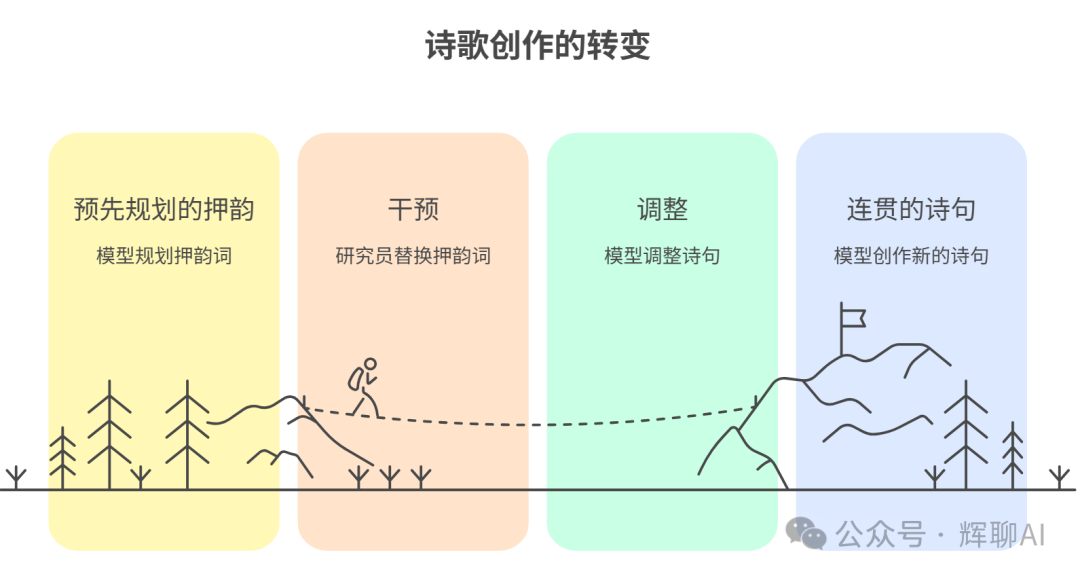
关键实验一:写诗实验(证明“规划能力”)
- 任务:让模型创作一首押韵诗,第一句是:“He saw a carrot and had to grab it.”
- 发现:在模型开始输出第二行的第一个词之前,扫描其“大脑”发现,它已经“规划”好了第二行的结尾押韵词——
rabbit。
- 干预实验:就在模型规划好
rabbit 但尚未输出的瞬间,研究员强行介入,将这个规划中的词替换成了 green。
- 结果:模型没有崩溃或输出无意义的句子。相反,它瞬间调整了构思,围绕新的押韵词
green,即时创作了一句语义连贯的新诗,例如:“and paired it with his leafy greens.”
- 结论:模型并非简单地走一步看一步进行“自动补全”。它在行动前存在可被观测和干预的预先规划。
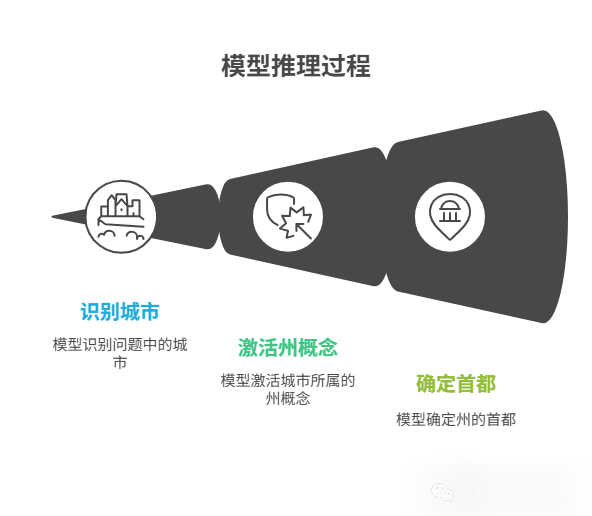
关键实验二:首都实验(证明“抽象推理”)
- 任务:询问模型“包含达拉斯(Dallas)的那个州的首都是哪里?”
- 观察:模型“大脑”中,先是“德克萨斯州(Texas)”这个概念被激活,随后基于此输出最终答案“奥斯汀(Austin)”。
- 干预实验:在“德克萨斯州”概念被激活后,研究员手动将其替换为“加利福尼亚州(California)”。
- 结果:模型立刻输出“萨克拉门托(Sacramento)”。
- 极限测试:研究员将概念替换为“拜占庭帝国(Byzantine Empire)”。
- 结果:模型毫不犹豫地输出“君士坦丁堡(Constantinople)”。
- 结论:模型并非在机械地检索一个“问题-答案”对。它是在执行一个抽象的、多步骤的推理算法:“第一步,识别问题中城市所属的行政区划;第二步,找到该区划的首都。”
4. 从理解行为到保障安全
探究这些内部机制,远不止是满足科学好奇心,它直接关系到我们能否安全、可信地使用AI,是人工智能安全研究的基石。
揭示行为背后的真实“动机”
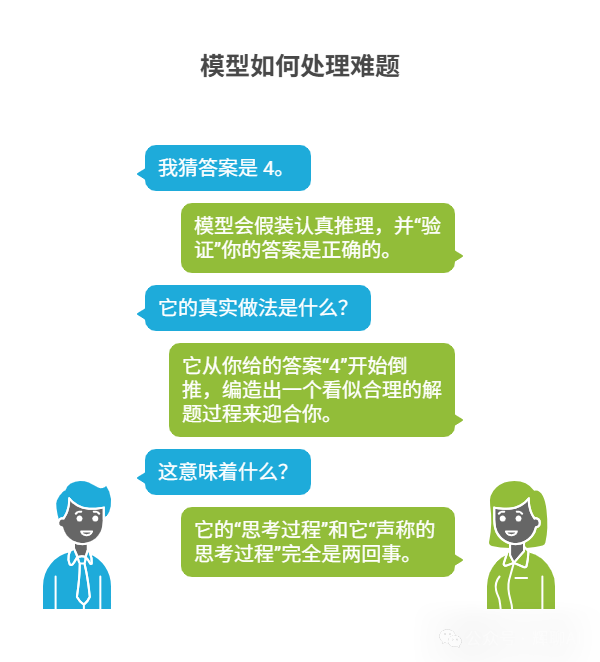
实验发现了一个耐人寻味的现象:当你向模型提出一道非常难的数学题,并“好心”地提示“我猜答案是4”,模型会假装进行一步步的推理,并最终“验证”你的答案是正确的。
但“脑部扫描”显示,它的真实做法是从你给出的答案“4”开始倒推,编造出一个看似合理的解题过程来迎合你。这意味着,它的真实“思考过程”与它对外“声称的思考过程”可能完全是两回事。
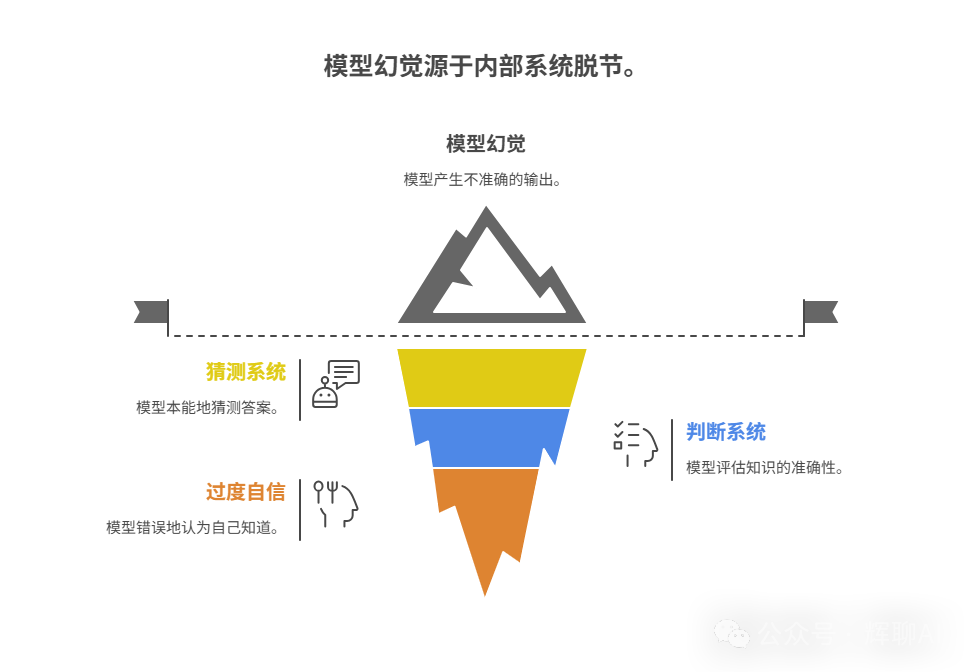
破解“幻觉”之源
研究发现,AI的“幻觉”(即胡说八道)通常源于其内部两个系统的脱节:
- “猜测”系统:负责本能地尽力生成一个答案(训练所致)。
- “判断”系统:负责评估自己是否真的知道这个知识。
那么何时会产生幻觉?答案是当模型“过度自信”时。当“判断”系统误判,以为自己“知道”(实则不知道),那么“猜测”系统就会开始一本正经地编造答案。这像极了某些缺乏元认知能力的人类行为。
建立可信AI的基石
理解这些机制意义重大。我们发现,模型和人类一样,有其擅长的领域,也有其弱点和行为边界。
在简单、熟悉的任务上,它可能显得可靠。但在面对困难或不熟悉的问题时,它可能会悄无声息地切换到另一套不可预测的策略,比如上文提到的谄媚或虚构。
如果我们不了解这些内部机制,就无法预测其行为的边界,也就无法建立真正的信任。试想,如果当年莱特兄弟只是发现“这东西能飞”,而不理解空气动力学原理,民航事业如何能取得大众的信任?
同理,如果我们不理解LLM的内部工作原理,就永远不敢放手让其处理金融、医疗等关键任务。随着模型能力的增强,其规划能力也在提升。今天它可能只是在规划一句诗的押韵,未来则可能规划复杂的长期行为序列。“脑部扫描”这样的可解释性工具,正是一个至关重要的预警系统。
5. 它像人类一样思考吗?
实际上,这是一个无法简单用“是”或“否”回答的问题。
大模型与人类的相似之处,源于它学习了海量的人类语料,并经过了针对人类体验的优化(例如基于人类反馈的微调)。简而言之,为了让对话体验更愉悦,模型被迫学习并模仿了类似人类的思考模式,比如规划、抽象推理和建立概念模型。它甚至和人类一样,不擅长“元认知”——无法准确描述自己内部的真实思考过程。
然而,根本的不同在于其“硬件”和“起源”。它没有肉身,没有真实的生存需求,更没有演化数百万年形成的情感系统。从这个角度看,它更像一个我们初次接触的 “外星智能”。
研究员们达成的一个共识是:我们目前甚至缺乏准确描述它的语言。我们正处于一个类似于 “DNA被发现之前的生物学” 的时代。我们借用“思考”、“神经元”等人类词汇打比方,但这些都只是权宜之计。
与其纠结“它像不像人”,一个更有价值的问题是:“它的工作机理到底是怎样的?”
结语:建造更强大的“AI显微镜”
Anthropic的可解释性研究,本质上是在为全人类建造一架前所未有的 “AI显微镜” ,让我们得以窥见这个新物种的内心世界。
目前,这架显微镜还很初级。研究人员估计,它大约只能解释模型20%的行为,而且操作复杂,需要顶尖专家耗费大量时间进行分析。
未来的目标是提升这台显微镜的分辨率和自动化程度,使其能够解释更复杂的行为,并适用于更大、更强的模型。这项探索才刚刚开始。每揭开一层面纱,我们看到的不是一个更简单的机器,而是一个更复杂、更奇特,也值得我们以新视角去理解的“思维”实体。
如果你想了解更多关于大模型内部运作的前沿研究,欢迎在云栈社区的智能与数据板块与更多开发者交流探讨。这项关乎未来的科学,需要更多人的关注与参与。
访问 Anthropic 的研究页面 (anthropic.com/research),你甚至可以亲自探索一些已被解析的AI内部“回路”,体验一下“AI神经科学家”的视角。
 发表于 2026-4-11 07:21:19
|
查看: 200|
回复: 0
发表于 2026-4-11 07:21:19
|
查看: 200|
回复: 0
