
这次,我们将目光投向美食领域,尝试用技术手段“寻味中国”。我们选择“豆果美食”作为数据源,通过编写 Python 爬虫,获取了川菜、粤菜、湘菜等八个中国菜系共计3032个最新发布的菜谱信息,并进行了数据清洗与可视化分析。
数据获取
本次爬取的数据范围涵盖了八个中国菜系,包含菜谱名、链接、用料、评分、图片等关键字段。爬虫的核心思路是遍历不同菜系的列表页,解析并提取详情信息。
核心代码如下所示:
# 主函数
def main(x):
url = 'https://www.douguo.com/caipu/{}/0/{}'.format(caipu,x*20)
print(url)
html = get_page(url)
parse_page(html,caipu)
if __name__ == '__main__':
caipu_list = ['川菜', '湘菜','粤菜','东北菜','鲁菜','浙菜','湖北菜','清真菜'] #中国菜系
start = time.time() # 计时
for caipu in caipu_list:
for i in range(22):
# 爬取多页
main(x=i)
time.sleep(random.uniform(1, 2))
print(caipu,"第" + str(i+1) + "页提取完成")
end = time.time()
print('共用时',round((end - start) / 60, 2), '分钟')
数据清洗
几分钟内我们就获取了3032条菜谱数据。为了方便后续分析,需要使用 Pandas 对数据进行清洗。
导入数据
使用 pd.read_csv 方法导入数据并指定列名,初步预览数据如下:

删除重复项
爬取过程中可能有少量重复数据,使用 drop_duplicates() 方法处理。
df = df.drop_duplicates()
df.info()
缺失值处理
通过 info() 方法检查数据完整性,发现少量缺失值记录,直接删除。
df = df.dropna(axis=0, how='any') #只要有缺失值的记录就删除
评分字段清洗
原始“评分”字段包含“分”字且为字符串类型,需要将其转换为数值型。
df['评分'] = df['评分'].str.replace('分', '').astype('float') #替换多余字符,转为浮点型
df.info()
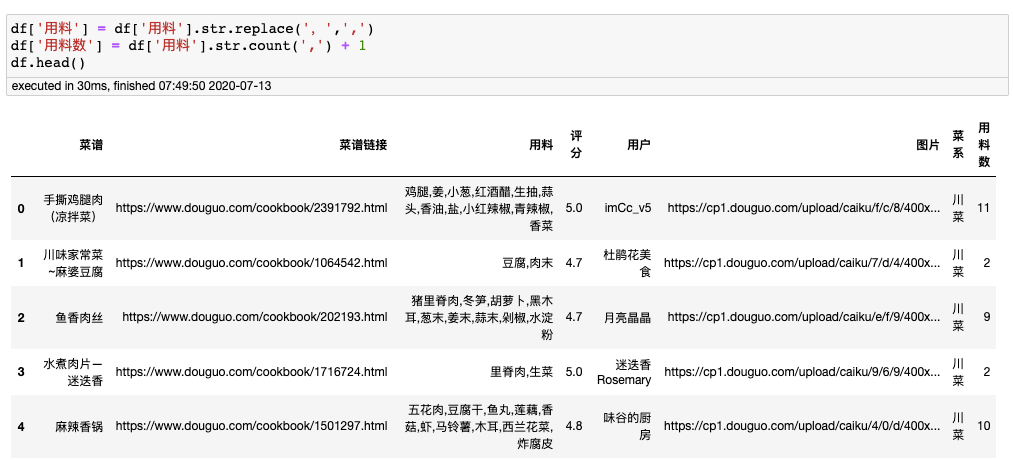
添加用料数字段
“用料”字段以中文逗号分隔不同食材。通过计算逗号数量并加1,可以得到每个菜谱的用料数量。
df['用料'] = df['用料'].str.replace(',', ',')
df['用料数'] = df['用料'].str.count(',') + 1
df.head()
数据可视化
我们主要使用 pyecharts 库进行可视化,它能生成交互性强且美观的图表。
菜谱评分分布
豆果美食的评分采用5分制。我们先将评分划分为几个区间,然后绘制玫瑰图展示分布情况。
from pyecharts import options as opts
from pyecharts.charts import Page, Pie
cut = lambda x : '4分以下' if x < 4 else ('4.1-4.5分' if x <= 4.5 else('4.6-4.9分' if x <= 4.9 else '5分'))
df['评分分布'] = df['评分'].map(cut)
df2 = df.groupby('评分分布')['评分'].count()
df2 = df2.sort_values(ascending=False)
df2 = df2.round(2)
print(df2)
c = (
Pie()
.add(
"",
[list(z) for z in zip(df2.index.to_list(),df2.to_list())],
radius=["20%", "80%"],# 圆环的粗细和大小
rosetype='area' #玫瑰图
)
.set_global_opts(
title_opts=opts.TitleOpts(title="菜谱评分分布"
),
legend_opts=opts.LegendOpts(
orient="vertical", pos_top="5%", pos_left="2%" ,textstyle_opts=opts.TextStyleOpts(font_size=14)# 左面比例尺
),
)
.set_series_opts(label_opts=opts.LabelOpts(formatter="{b}:{d}%",font_size=18),
)
)
c.render_notebook()
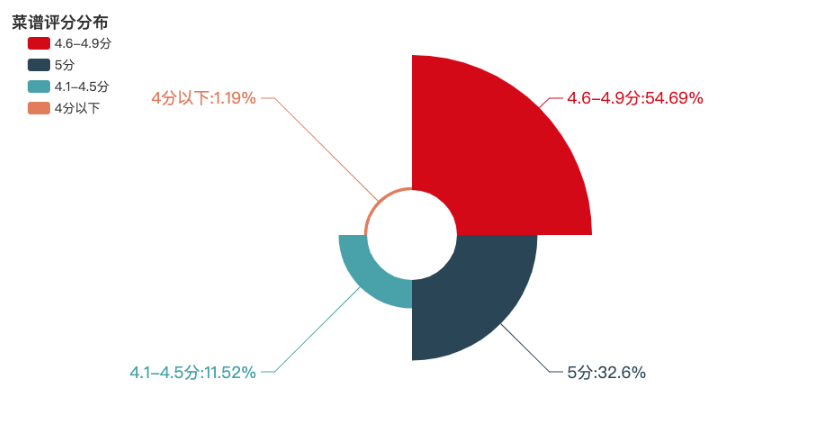
从图中可以看出,4分以下的菜谱仅占1.19%,而满分(5分)菜谱占比高达32.6%。这表明用户对平台上的中国菜系菜谱普遍给予了较高评价。
各菜系菜谱数量对比
我们通过饼图来比较不同菜系的菜谱数量。
from pyecharts import options as opts
from pyecharts.charts import Page, Pie
df2 = df.groupby('菜系')['评分'].count() #按菜系分组,对评分计数
df2 = df2.sort_values(ascending=False) #降序
print(df2)
c = (
Pie()
.add("", [list(z) for z in zip(df2.index.to_list(),df2.to_list())])
.set_global_opts(title_opts=opts.TitleOpts(title="各菜系菜谱数量占比",subtitle="数据来源:豆果美食"))
.set_series_opts(label_opts=opts.LabelOpts(formatter="{b}: {c}"))
)
c.render_notebook()
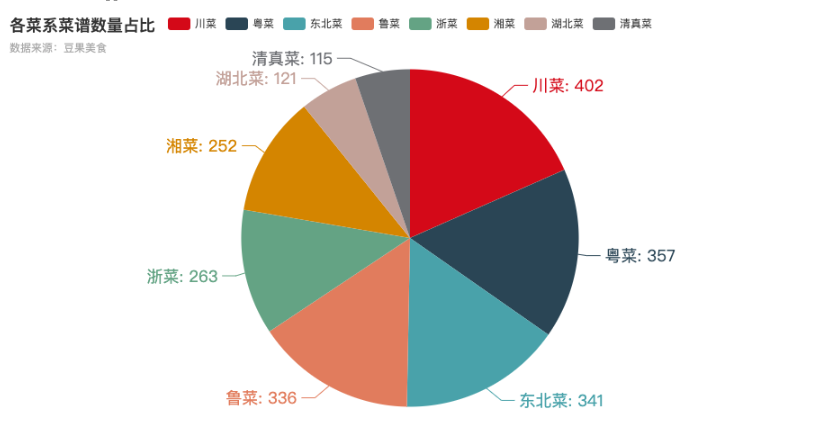
结果显示,川菜(402个)和粤菜(357个)的菜谱数量遥遥领先,这与其在中国“八大菜系”中的地位相符。而湖北菜和清真菜的菜谱数量相对较少。
各菜系平均评分对比
接下来,我们看看不同菜系的平均评分是否有差异。
from pyecharts import options as opts
from pyecharts.charts import Page, Pie
df2 = df.groupby('菜系')['评分'].mean()
df2 = df2.sort_values(ascending=False)
df2 = df2.round(2)
print(df2)
c = (
Pie()
.add(
"",
[list(z) for z in zip(df2.index.to_list(),df2.to_list())],
radius=["40%", "75%"], # 圆环的粗细和大小
)
.set_global_opts(
title_opts=opts.TitleOpts(title="各菜系平均评分"),
legend_opts=opts.LegendOpts(
orient="vertical", pos_top="5%", pos_left="2%" # 左面比例尺
),
)
.set_series_opts(label_opts=opts.LabelOpts(formatter="{b}:{c}"))
)
c.render_notebook()
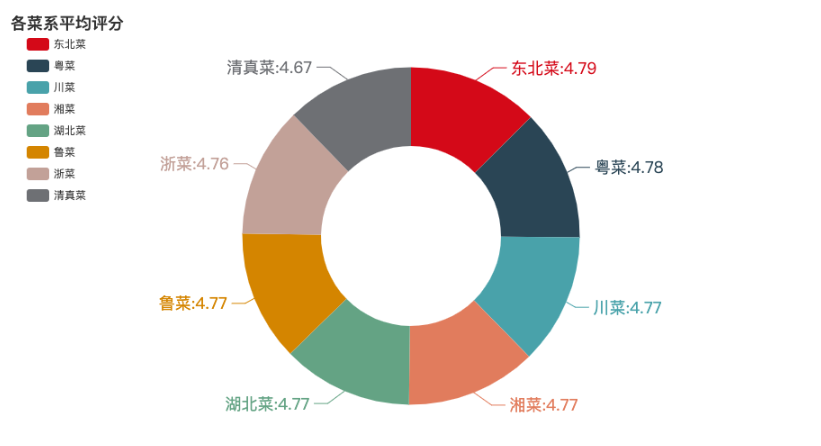
各菜系的平均评分非常接近,均在4.67分以上,东北菜以4.79分略高。这种高度一致的评分或许意味着用户打分普遍偏高,使得评分区分菜品优劣的可信度有所降低。
各菜系用料数量对比
我们通过柱状图分析各菜系平均用料数量的差异。
from pyecharts.charts import Bar,Pie
from pyecharts import options as opts
df1 = df.groupby('菜系')['用料数'].mean() #按菜系分组,对评分计数
df1 = df1.sort_values(ascending=False) #降序
df1 = df1.round(0)
print(df1)
bar = Bar()
bar.add_xaxis(df1.index.to_list())
bar.add_yaxis("用料数量",df1.to_list())
bar.set_global_opts(title_opts=opts.TitleOpts(title="各菜系用料数量",subtitle="数据来源:豆果美食"))
bar.render_notebook()
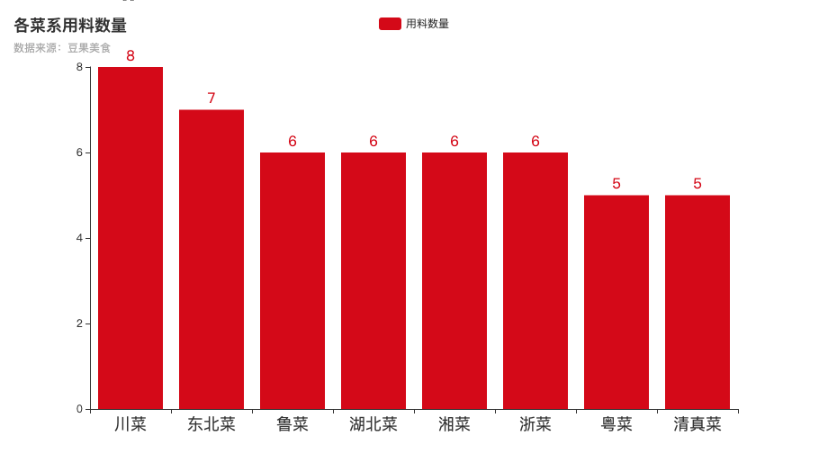
川菜和东北菜的平均用料数量位居前两位,分别为8种和7种。川菜讲究“百菜百味”,取材广泛;东北菜则风格豪迈,用料实在。粤菜注重食材本味,追求清鲜,用料相对精简(平均5种)。清真菜因饮食禁忌,可选食材范围受限,用料也较少。
各菜系核心用料分析
为了更深入地了解每个菜系的特色,我们利用词云图对“用料”字段进行文本分析,提取高频食材。
川菜用料分析

“花椒”、“豆瓣酱”、“干辣椒”在词云图中最为醒目,这精准勾勒出川菜“麻辣鲜香”的魂。在分析的菜谱中,“川味砂锅之足不出户的麻辣烫”用料多达35种,堪称“复杂派”代表。

其用料包括:毛肚,黄喉,鲜牛肉片,自制肉,鸭血,金针菇,平菇,豆芽,苕粉,冬笋片,白菜,莴笋叶,鹌鹑蛋(煮熟剥壳),猪骨汤,猪油,牛油,植物油(菜油上佳),姜片,大粒的蒜,郫县豆瓣,八角,茴香,桂皮,丁香,陈皮,香叶,白胡椒粉,冰糖,生抽,盐,葱结,花椒,干辣椒,鸡精丸,午餐肉。
粤菜用料分析

“胡椒粉”、“五花肉”、“白糖”是粤菜词云中的主角,反映出粤菜对提鲜、增香和平衡口味的追求。“广式肠粉”以23种用料展现了粤式点心的精细。

用料包括:粉浆用料,粘米粉(米打的粉),澄面(小麦淀粉),土豆淀粉,粟米粉(玉米淀粉),水,酱汁用料,独头蒜,大蒜籽,姜片,香菜(不吃香菜的可用葱代替),鸡汤,鲜味生抽,老抽,蚝油,蜂蜜,鱼露(可不放),鸡精(个人喜欢就放,不放也很鲜了),水,肠粉里面放的料,肉末,鸡蛋,生菜叶。
湘菜用料分析

“辣椒”、“大蒜”、“花椒”占据核心,湘菜的“热辣”风情扑面而来。“麻辣卤鸭三件”用20种调料成就复合香辣味。

用料明细:鸭爪(清水泡一小时),鸭翅膀(清水泡一小时啊),鸭肠(洗干净后捆成一个个小捆),白芷,桂皮,香叶,大料(两个焯水用,三个卤用),干辣椒(根据个人喜辣程度放),小茴香,花椒,麻椒,草果,生姜(一块焯水去味用,一块卤用),蒜瓣(全部去皮),辣椒酱(根据个人喜辣放),老抽,生抽,料酒,白糖,盐。
东北菜用料分析

“土豆”、“面粉”、“胡萝卜”等扎实的食材词汇,体现了东北菜朴实、管饱的特点。“翡翠白菜水饺”用料达20种,将寻常饺子做出了新意。

用料明细:面皮制作,面粉(绿色面团所用),面粉(白色面团所用),小白菜叶(取汁),清水,馅料制作,猪五花肉,大白菜,胡萝卜,葱碎,姜沫,盐,生抽,老抽,蚝油,芝麻油,糖,鸡精,花椒粉,花生油。
湖北菜用料分析

“糯米”、“花椒”、“面粉”等词较为突出。“家常美味——香菇鸡肉面”以23种用料诠释了湖北家常菜的丰富。

用料明细:鸡脯肉或鸡腿肉,香菇,刀削面或宽面,芹菜,青菜,郫县红油豆瓣,葱,姜,蒜,干辣椒,花椒,八角,老抽,生抽,料酒,淀粉,蛋清,十三香,白胡椒,鸡精,盐,蒜苗,香菜。
浙菜用料分析

“白糖”、“冰糖”、“胡椒粉”等调味料频繁出现,印证了浙菜“甜而不腻”的风味特点。“经典糖醋排骨”用料17种,是江浙甜口菜的典范。

用料明细:猪肋排,小葱段(煮排骨用),姜(煮排骨用),料酒(煮排骨用),冷水,绵白糖,米醋,香醋,老抽,盐,绵白糖(浇汁用),米醋(浇汁用),香醋(浇汁用),淀粉(浇汁用),温水(浇汁用),食用油,熟白芝麻。
鲁菜用料分析

“面粉”、“胡萝卜”、“蚝油”等词显著,鲁菜善用本地优质食材的特点可见一斑。“大白菜炖牛肉”用料高达28种,体现了鲁菜炖煮技法的讲究。

用料明细:炖牛肉,牛肉,葱姜,小香葱,冰糖,八角,草果,小茴香,香叶,干辣椒,蒜,洋葱,油,生抽,甜面酱,番茄酱,盐,清水,啤酒,大白菜炖牛肉,大白菜,熟牛肉,牛肉汤,粉丝,食用油,葱花,水淀粉,盐。
清真菜用料分析

“蛋白”、“蛋清”、“面粉”等词汇占据主导,这与清真饮食严格的食材禁忌有关,烹饪中更注重对禽蛋、面食等的运用。“糖醋蛋白肉”用料15种。

用料明细:蛋白肉,尖椒,小米椒,蒜瓣,小葱,食用油,糖,醋,蒸鱼豆豉,生抽,黄酒,番茄酱,淀粉,清水,盐。
总结
通过本次从数据爬取、清洗到分析与可视化的完整流程,我们得以从数据角度观察八大菜系的一些特点。分析发现,平台用户评分普遍较高,不同菜系间差异不大。在用料上,川菜、东北菜更为丰富,而粤菜、清真菜则相对精简。词云图直观地揭示了各菜系最核心的用料,与我们的传统认知基本吻合。
这个项目展示了如何利用 Python 爬虫技术获取网络公开数据,并借助 Pandas 和 pyecharts 等工具完成一次完整的、兼具广度和深度的大数据分析实践。代码和思路可以迁移到对其他领域网站的数据分析中。如果你对数据分析或网络爬虫感兴趣,欢迎在 云栈社区 交流讨论更多技术细节。
声明:
- 本数据分析仅作学习研究之用,结论仅供参考。美食烹饪影响因素众多,请理性判断。
- 本文作者与“豆果美食”无任何利益关联,仅因其数据规整适于分析。
- 文中对传统美食文化的描述仅为基于数据的解读,可能存在不完善之处。
 发表于 2026-4-11 07:18:06
|
查看: 169|
回复: 0
发表于 2026-4-11 07:18:06
|
查看: 169|
回复: 0
