做过网页自动化或者爬虫的朋友,大概率都被 Selenium 折腾过。
环境配置能让人抓狂,各种驱动版本对不上;好不容易跑起来了,又经常卡在网页加载上,只能在代码里疯狂塞 time.sleep()。
不过也不是没有替代方案。
微软前几年开源了一个叫 Playwright 的工具,现在已经成为自动化圈子里的新标杆。今天就来聊聊,这把网页自动化的“瑞士军刀”。
一行命令入坑,告别配环境的痛苦
以前用 Selenium,你要先看自己的 Chrome 是什么版本,再去网上下对应版本的 chromedriver 。一旦浏览器自动升级,得,又得再来一遍。
Playwright 彻底解决了这个问题。在 Python 环境下,你只需要两行命令:
pip install playwright
playwright install
第一行安装 Python 库,第二行它会自动帮你下载配套的 Chromium、Firefox 和 WebKit 浏览器内核。不需要配置任何环境变量,不需要满世界找驱动,直接一步到位。
Playwright 的“杀手锏”
之所以很多人推荐 Playwright,是因为它确实解决了自动化开发中最核心的几个痛点:
1. 自动等待(Auto-waiting)
这是最爽的一点。Playwright 在对一个元素做点击、输入等操作之前,会自动帮你判断这个元素是不是已经加载出来了、是不是可见的、是不是没有被其他东西挡住。你再也不用写一堆硬编码的 time.sleep(),代码不仅执行速度飞快,而且稳如老狗。
2. 录制脚本(Codegen)
这堪称初学者的福音。你只需要在终端输入如下命令(以百度为例):
playwright codegen https://www.baidu.com
它会弹出一个浏览器和一个代码窗口。你在浏览器里点击控件、输入文字,右边的窗口就会实时生成对应的 Python 代码。这样一来,哪怕你完全不会写定位符,也能把操作脚本写出来。
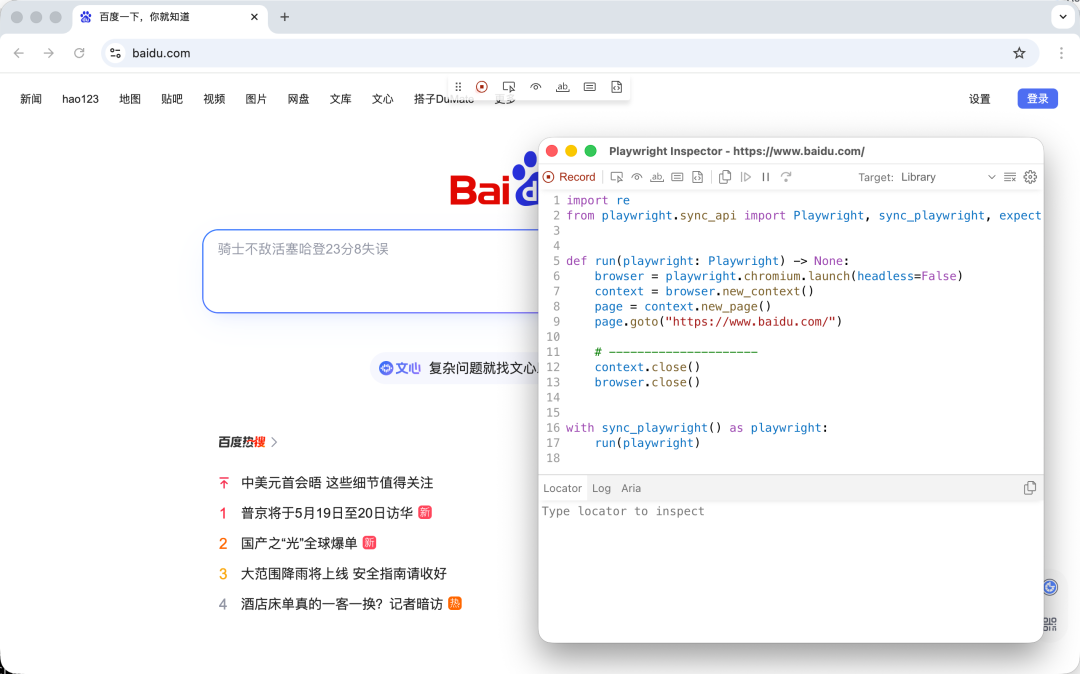
3. 多环境隔离
有时候我们需要在一台机器上同时登录两个账号做测试,或者抓取不同权限的数据。Playwright 引入了“浏览器上下文(Browser Context)”的概念。它不需要你开两个完整的浏览器,而是像浏览器的“无痕模式”一样,每个上下文之间的 Cookie 和缓存都是完全隔离的,省内存还高效。
4. 强大的选择器(Selectors)
以前用 Selenium,定位元素一直是令人头疼的操作。你要么得写又长又臭、网页一改版就崩的 XPath,要么得去翻 F12 源码找那些随机生成的 class 类名。
Playwright 引入了一套极其人性化的“面向用户感知”的选择器。什么叫面向用户感知?就是“你眼睛看到什么,代码就怎么写”。
- 按页面文字找: 按钮上写着“百度一下”,你不用管它是
<input> 还是 <button>,直接写 page.get_by_role("button", name="百度一下").click()。
- 按输入框提示找: 网页上有一个输入框,默认提示为“请输入密码”,直接写
page.get_by_placeholder("请输入密码").fill("123456")。
- 按标签文本找: 网页上有一行标签“用户名:”,后面跟着一个输入框,你就直接用相对定位,通过这行字去精准定位它旁边的输入框:
page.get_by_label("用户名:").fill("crossin")。
Playwright 还支持 CSS 选择器和 XPath 的混合使用,不需要加前缀声明,它自己会判断。这种设计让你的定位代码不仅写起来像写英语句子一样丝滑,而且网页前端只要大结构没变,你的脚本就不会失效。
实例:一个实用的自动化脚本
假设我们需要写一个脚本,自动打开某个页面,搜索关键词,并等待数据加载出来。用 Playwright 写出来的代码是这样的:
import time
from playwright.sync_api import sync_playwright
def run():
# 启动 Chromium 浏览器,headless=False 让你能看到自动化操作的过程
with sync_playwright() as p:
browser = p.chromium.launch(headless=False)
context = browser.new_context()
page = context.new_page()
# 1. 打开百度首页
print("正在打开百度...")
page.goto('https://www.baidu.com')
# 2. 定位输入框并输入内容
# 百度首页输入框的真实 id 是 'kw'
print("填写输入框...")
page.fill('#kw', 'Crossin的编程教室')
# 3. 点击“百度一下”按钮
# 根据按钮文字定位
print("按下按钮...")
page.get_by_role("button", name="百度一下").click()
# 4. 等待结果加载
# 百度搜索结果的外层容器通常是 #content_left
print("等待搜索结果渲染...")
page.wait_for_selector('#content_left')
# 5. 此时页面已经加载完毕,我们截个图证明它跑成功了
page.screenshot(path='baidu_result.png')
print("搜索成功!截图已保存为 baidu_result.png")
# 稍微停 3 秒让你看一眼效果,不然浏览器嗖的一下就关了
time.sleep(3)
# 6. 清理现场
context.close()
browser.close()
if __name__ == "__main__":
run()
工具只是手段,解决问题才是目的。如果你现在还在被 Selenium 的各种报错折腾,强烈建议你花十分钟,按照上面的命令装一个 Playwright 试一下,体验真的会流畅很多。
你在做网页自动化或爬虫时踩过哪些坑?欢迎来 云栈社区 和更多开发者分享交流。
 发表于 2026-5-25 21:40:37
|
查看: 95|
回复: 0
发表于 2026-5-25 21:40:37
|
查看: 95|
回复: 0
