编写SQL查询时,你是否曾困惑于WHERE和HAVING谁先执行?或者为什么在SELECT中起的别名能在ORDER BY中使用,却不能在WHERE里用?这背后的一切都源于SQL语句独特的执行顺序。理解这个顺序,是写出正确、高效查询的基石,能让你从“知其然”进阶到“知其所以然”。
下图清晰地展示了SQL查询中主要子句的逻辑执行顺序:
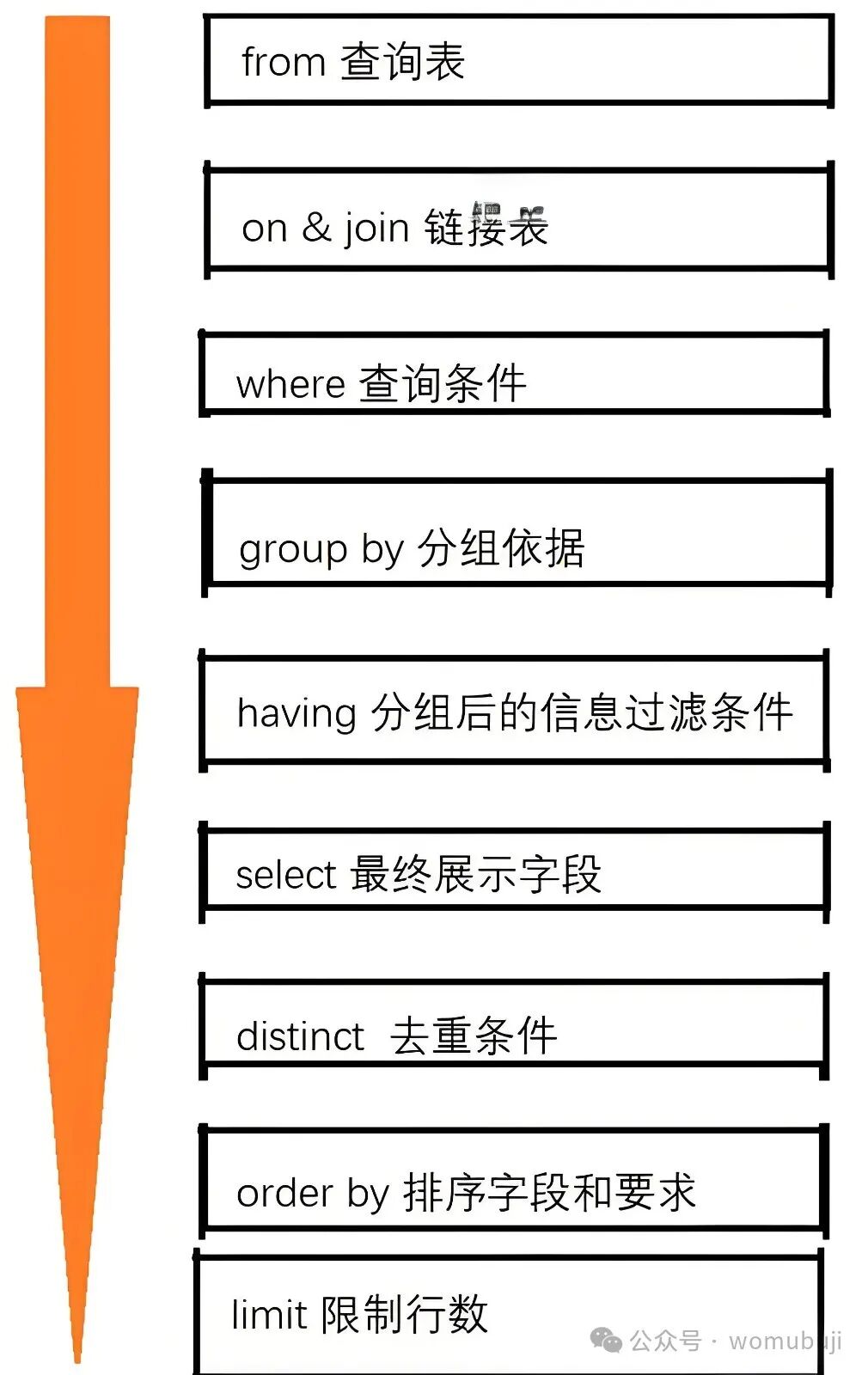
注意,这个顺序是逻辑上的,而非数据库引擎物理执行时的顺序。数据库优化器会根据索引、数据分布等情况调整实际执行步骤以提升性能,但最终结果必须符合此逻辑顺序。下面我们来逐一拆解。
一、SQL核心子句执行顺序详解
-
FROM & JOIN
- 作用:首先确定数据的来源。如果查询涉及多张表,会通过
JOIN(如INNER JOIN, LEFT JOIN)和ON条件将这些表连接起来,形成一张临时的“大表”(虚拟表)。
- 逻辑:先计算所有参与表的笛卡尔积,再根据
ON条件进行筛选。
-
WHERE
- 作用:在数据分组前,对
FROM/JOIN后产生的临时表中的每一行进行过滤。
- 关键限制:此处不能使用
SELECT中定义的列别名,也不能使用聚合函数(如SUM(), AVG())。
-
GROUP BY
- 作用:将经过
WHERE过滤后的行,按照指定的一个或多个列进行分组。分组后,数据从“行”的视角转变为“组”的视角。
-
HAVING
- 作用:在数据分组后,对每个分组进行过滤。
- 与WHERE的区别:
HAVING可以使用聚合函数(例如HAVING SUM(sales) > 1000),而WHERE不行。它作用于分组结果,WHERE作用于原始行。
-
SELECT
- 作用:选择最终需要返回的列或表达式。可以在此处使用聚合函数、为列定义别名(
AS)。
- 注意:虽然
SELECT在书写时位于开头,但逻辑上它是在大部分过滤和分组之后才执行的。这也是为什么其别名能被后续的ORDER BY和LIMIT使用。
-
DISTINCT
- 作用:去除
SELECT结果集中的重复行。逻辑上在SELECT之后执行。
-
ORDER BY
- 作用:对最终的查询结果集进行排序。
- 关键:可以使用
SELECT中定义的列别名。因为此时结果集已经确定。
-
LIMIT / OFFSET
- 作用:限制返回结果的行数,常用于分页。这是整个查询逻辑链条的最后一步。
简单记忆口诀:从哪拿 -> 行过滤 -> 分组 -> 组过滤 -> 选字段 -> 去重 -> 排序 -> 限行。
掌握这个顺序,是进行高效数据库查询与优化的关键第一步。接下来我们通过案例加深理解。
二、实战案例分析
案例1:统计部门员工数并排序
需求:查询每个部门的员工数量,并按员工数量从多到少排序。
SELECT
department,
COUNT(*) AS employee_count
FROM employees
GROUP BY department
ORDER BY employee_count DESC;
执行顺序分析:
- FROM employees:从
employees表获取所有数据。
- GROUP BY department:按
department字段分组。
- SELECT ...:计算每个分组的行数(
COUNT(*)),并选中department字段,为计数结果起别名employee_count。
- ORDER BY employee_count DESC:使用别名
employee_count对结果进行降序排序。
案例2:筛选高价值客户
需求:找出销售额超过1000的订单,按客户ID分组,计算每个客户的总销售额,筛选出总销售额大于0的客户,按总销售额升序排列,只返回前5名。
SELECT
customer_id,
SUM(sales_amount) AS total_sales
FROM orders
WHERE sales_amount > 1000
GROUP BY customer_id
HAVING SUM(sales_amount) > 0 -- 此处演示HAVING用法,实际上WHERE已过滤掉<=1000的订单
ORDER BY total_sales ASC
LIMIT 5;
执行顺序分析:
- FROM orders:获取订单数据。
- WHERE sales_amount > 1000:先过滤掉单笔销售额不超过1000的订单行。
- GROUP BY customer_id:将过滤后的订单按
customer_id分组。
- HAVING SUM(sales_amount) > 0:对分组进行过滤。虽然本例中
WHERE已确保销售额为正,但这里演示了HAVING可使用聚合函数SUM()。
- SELECT ...:计算每个客户分组的总销售额(
SUM(sales_amount)),并为结果起别名total_sales。
- ORDER BY total_sales ASC:使用别名按总销售额升序排序。
- LIMIT 5:仅返回前5条记录。
案例3:多表关联与分组过滤
需求:查询女生在每门课程中的平均成绩,只显示平均分大于75分的课程,并按平均成绩降序排列。
假设有学生表students和成绩表scores,结构如下:
students表:
| student_id |
student_name |
gender |
| 1 |
Alice |
Female |
| 2 |
Bob |
Male |
| 3 |
Carol |
Female |
scores表:
| score_id |
student_id |
course |
score |
| 1 |
1 |
Math |
80 |
| 2 |
1 |
English |
70 |
| 3 |
2 |
Math |
60 |
| 4 |
2 |
English |
75 |
| 5 |
3 |
Math |
90 |
| 6 |
3 |
English |
85 |
查询语句:
SELECT
course,
AVG(score) AS average_score
FROM students
JOIN scores ON students.student_id = scores.student_id
WHERE gender = 'Female'
GROUP BY course
HAVING AVG(score) > 75
ORDER BY average_score DESC;
执行步骤详解:
- FROM & JOIN:将
students和scores表通过student_id连接,生成包含所有学生成绩信息的中间数据集。
- WHERE gender = 'Female':从上一步的中间数据中,筛选出性别为女生的记录。
- GROUP BY course:将筛选后的女生成绩记录,按
course(课程)进行分组,形成“Math组”和“English组”。
- HAVING AVG(score) > 75:对每个课程分组计算平均分。假设Math组平均分85,English组平均分77.5,均大于75,故两个分组都保留。
- SELECT course, AVG(score) AS average_score:选出课程名称和对应的平均分,并为平均分设置别名
average_score。
- ORDER BY average_score DESC:使用别名
average_score对结果进行降序排序。
| 最终结果: |
course |
average_score |
| Math |
85 |
| English |
77.5 |
总结与常见误区
- SELECT别名:在
SELECT阶段定义的别名,只能在ORDER BY和LIMIT(以及某些数据库的HAVING)中使用,不能在WHERE或GROUP BY中使用,因为它们的执行顺序在SELECT之前。
- WHERE vs HAVING:最根本的区别在于作用时机。
WHERE在分组前过滤行,HAVING在分组后过滤组。因此,所有能用WHERE完成的过滤,都应优先使用WHERE,因为它能减少后续分组操作的数据量,提升性能。
- 聚合函数位置:聚合函数(如
COUNT, SUM, AVG)可以出现在SELECT列表和HAVING子句中,但不能直接用于WHERE子句。
透彻理解SQL的执行顺序,能帮助你避免许多编码错误,并写出更高效、意图更清晰的查询语句。当面对复杂查询时,在脑海中按此顺序“运行”一遍,往往是调试和优化的最快途径。如果你想进一步探讨数据库优化技巧或查看更多实战案例,欢迎在云栈社区与更多开发者交流。 |  发表于 2026-4-11 07:35:13
|
查看: 190|
回复: 0
发表于 2026-4-11 07:35:13
|
查看: 190|
回复: 0
