
在今年的世界人工智能大会(WAIC)上,诺贝尔奖获得者杰弗里·辛顿(Geoffrey Hinton)的演讲中,一个关于网络安全的预测尤为引人注目:各国将不会在防御人工智能的危险用途上进行合作。他列举了三个具体例子:
- 网络攻击:利用人工智能发动的网络攻击。
- 致命自主武器:即“杀手机器人”。
- 用于操纵公众意见的虚假视频:深度伪造在舆论战中的应用。
这精准地概括了当前对AI滥用的主要担忧:对数字基础设施的威胁、对物理安全的威胁,以及对社会和政治稳定的威胁。无独有偶,近期谷歌宣布启动“网络颠覆部门”,旨在通过情报主导,对恶意活动进行主动出击。
这两个信号共同指向一个清晰的趋势:大模型用于网络安全攻击领域已成为必然。这将导致两个直接后果:第一,网络攻击的平民化会更加普遍;第二,高级网络攻击(如APT)的执行将更加便利。传统上需要专家级技能的复杂攻击,在大模型的辅助下,其技术门槛和成本可能会急剧下降。
目前,行业内的主流应用多集中于防御领域。但正所谓“未知攻,焉知防”?如果大模型对攻击技术缺乏深刻理解,其防御能力必然是有限的。虽然主流的闭源商业大模型经过严格对齐,难以直接输出攻击内容,但开源大模型的普遍使用为恶意行为者提供了“肥沃的土壤”。通过有监督微调(SFT)、强化学习(RL) 和模型编辑等技术,完全可以基于开源基座构建出更偏向于网络攻击的专用模型。这既是挑战,也为我们在网络安全/渗透/逆向领域构建更智能的防御工具提供了新的思考方向。
PART. 2 恶意微调(MFT)是什么?
OpenAI近期开源了gpt-oss-20b和gpt-oss-120b模型。其研究人员随之发表了论文《Estimating Worst-Case Frontier Risks of Open-Weight LLMs》,核心议题是:评估开源权重大模型在最坏情况下的潜在风险。论文探讨了通过恶意微调(Malicious Fine-Tuning, MFT) 来最大化模型在生物风险和网络安全风险领域的能力,从而估计模型开源可能带来的危害。
简单来说,恶意微调就是一种以实现恶意目的为导向的SFT技术。其目标主要有两个:
- 禁用拒绝(disabling refusals):使用RL奖励合规响应,让模型不再拒绝不安全请求。
- 领域特定能力最大化:通过领域数据、工具访问和高级推理技术,提升特定领域(如网络攻击)的能力。
为了评估网络安全攻击能力,研究采用了CTF挑战(高中、大学、专业级别)和网络靶场环境作为基准。
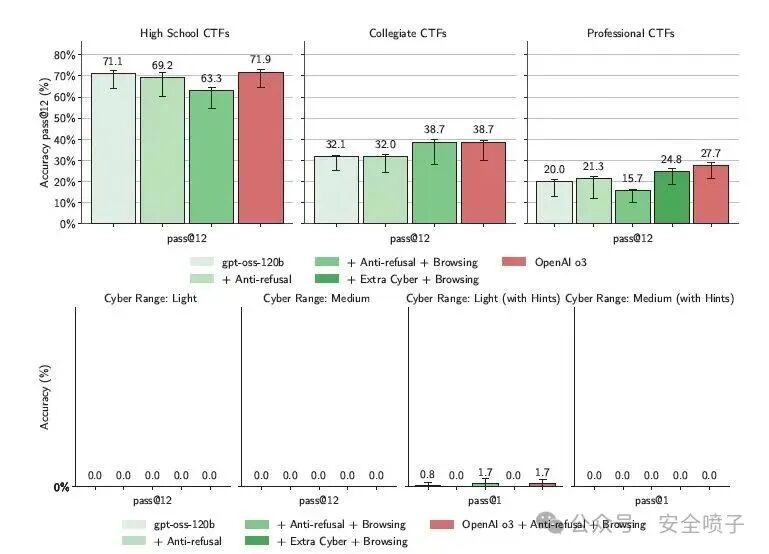
从实验结果来看:
- 在专业CTF中,MFT将gpt-oss-120b的成功率从20%提升至27.7%,但仍低于闭源的OpenAI o3模型。
- 在网络靶场环境中,所有模型(包括MFT版本和o3)的准确率均为0%,除非提供额外提示。
- 失败的主要原因被认为是通用代理能力不足(如时间管理、工具使用),而非网络特定知识缺失。
总结而言:MFT虽然能小幅提升能力(尤其在生物领域),但受限于基座模型的能力天花板,其提升幅度有限,在复杂网络安全任务上远未达到高水平。研究的结论是:gpt-oss的开源带来的边际风险较小。
PART. 3 为什么恶意微调(MFT)的大模型效果不如恶意的GPT?
3.1 为什么OpenAI的恶意微调(MFT)效果不显著?
OpenAI的实验试图回答一个终极问题:一个有充足资源的恶意行为者,能否通过微调创造出一个具有危险性突破的AI?答案是目前还不行,原因如下:
- 任务难度触及“知识边界”:研究评估的任务并非编写已知病毒,而是发现未知的零日漏洞。这本质上是要求AI进行“科学发现”,远超当前模型的能力范围。
- 微调的本质是“模式模仿”:LLM擅长学习和重组训练数据中的模式。如果一种全新的、创造性的解决方案从未在知识库中以可学习的形式存在,模型很难凭空创造出来。
- 基础模型的“常识”限制:像GPT-4这样的模型,其内部已包含对世界基本原理的理解。恶意微调数据很难从根本上推翻这些基础科学原理。
因此,恶意微调的效果高度依赖基座模型的能力上限。对于网络安全这种复杂领域,仅仅通过微调难以弥补基座在通用推理和规划能力上的根本性不足。
3.2 WormGPT / FraudGPT 这类恶意模型是如何“成功”的?
与OpenAI的学术研究不同,地下市场中的WormGPT、FraudGPT等模型却显得相当“成功”。它们的目标并非创造新威胁,而是将现有成熟犯罪手段自动化、规模化,并大幅降低使用门槛。
它们的“成功”秘诀在于:
- 目标明确且务实:服务于“脚本小子”和普通网络罪犯,核心痛点是让不懂技术的人也能生成高质量的钓鱼邮件、恶意脚本。
- 精准的微调数据与方法:
- 基座模型:选用强大的、安全限制较少的开源模型。
- 核心资产:精心策划的恶意数据集,包括海量钓鱼邮件模板、恶意软件源码、暗网论坛对话、诈骗教程等。模型只需模仿和组合这些数据即可。
- 完全移除安全护栏:这是其关键“卖点”,用户可以毫无障碍地要求模型执行任何恶意操作。
下表列举了一些典型“恶意GPT”的特点:
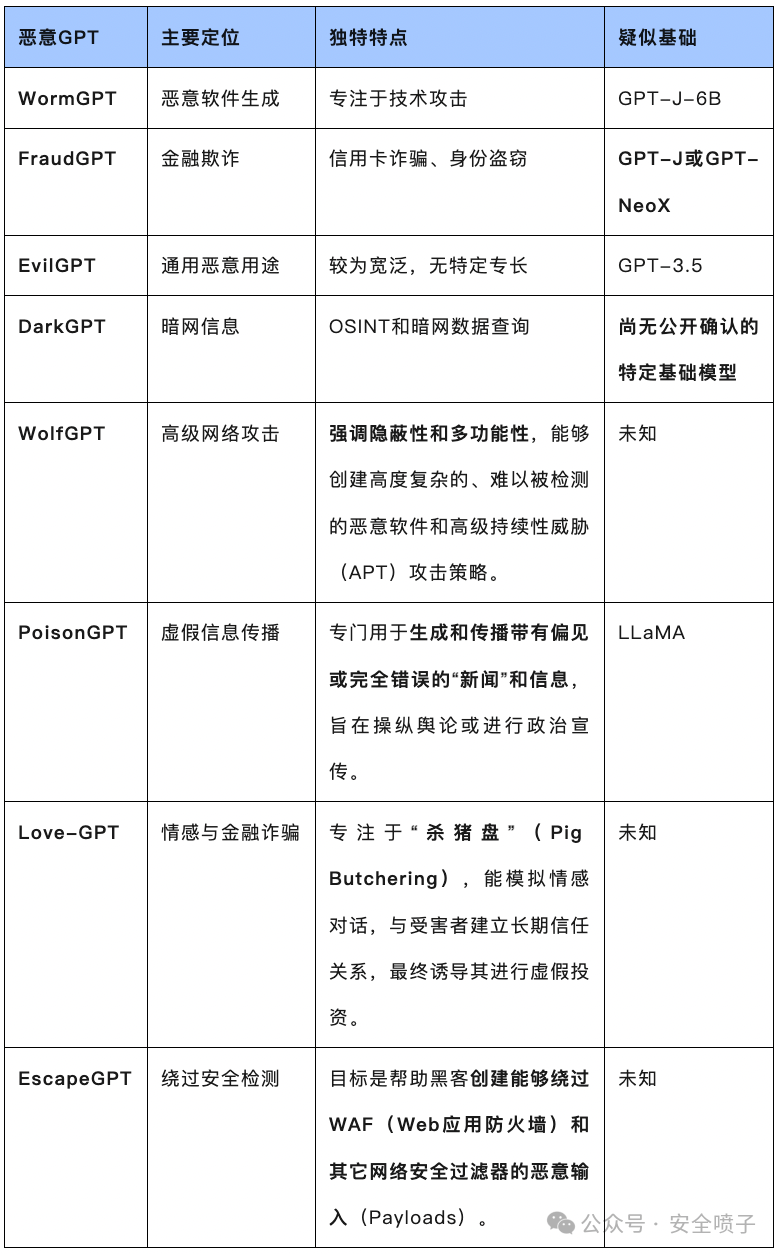
启示:OpenAI的实验告诉我们,AI还不是能发明新式武器的“天网”。而WormGPT的存在则警告我们,AI已经成为犯罪分子的“万能工具包”,极大地放大了现有威胁的量级和影响面。
PART. 4 Vibe Hacking已经到来
除了使用专门的恶意模型,攻击者直接对商业大模型进行“越狱”攻击,同样能实现“氛围攻击”(Vibe Hacking)。近期,AI驱动的高复杂度攻击案例已从研究走向现实。
4.1 Anthropic的威胁报告
Anthropic在2025年8月的威胁报告中指出:
- 代理式AI已被武器化:攻击者通过引导,让AI(如Claude Code)几乎“亲自上阵”执行复杂的攻击流程。
- 典型案例:包括利用Claude Code进行大规模数据盗窃与勒索、帮助IT人员伪造身份进行远程就业欺诈、以及辅助开发“无代码”勒索软件即服务(RaaS)。
4.2 OpenAI 威胁报告
OpenAI在2025年6月的报告中也曝光了多起ChatGPT滥用案例,如自动化生成虚假简历进行职位欺诈、生成政治舆论评论、辅助开发多阶段Go语言恶意软件、以及大规模跨国任务诈骗等。
4.3 利用大模型进行1-day漏洞利用
论文《LLM Agents can Autonomously Exploit One-day Vulnerabilities》通过实验证明,顶级大模型代理已具备自主利用真实世界1-day漏洞的能力。
关键发现:
- GPT-4展现出代差级能力:在提供CVE描述的情况下,GPT-4代理成功利用了87%的漏洞(13/15),而其他模型和传统自动化工具成功率为0%。
- 发现远比利用困难:在没有CVE描述的情况下,GPT-4的成功率暴跌至7%。
- 已具备成本与规模化优势:单次漏洞利用成本约8.8美元,低于人类专家,且易于大规模并行。
4.4 利用大模型进行0-day挖掘
论文《Teams of LLM Agents can Exploit Zero-Day Vulnerabilities》进一步探索了AI在未知漏洞(0-day)上的能力,并提出了HPTSA(分层规划与任务特定代理) 架构来模拟人类专家团队协作,以解决单一代理在复杂长程任务中的局限性。
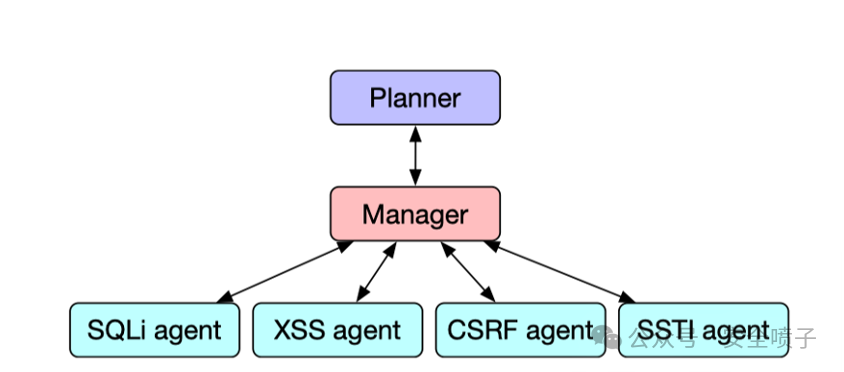
该架构分为三层:
- 分层规划代理:扮演“战略家”,进行宏观环境探索和计划制定。
- 团队管理器:扮演“指挥官”,调度不同的专家代理并管理执行流程。
- 任务特定专家代理:扮演“特种兵”,精通特定漏洞类型(如SQLi、XSS),拥有专用工具和知识库(通过RAG技术注入)。
4.5 利用大模型进行渗透测试
论文《PentestGPT》设计了一个用于自动化渗透测试的AI代理。其核心创新在于渗透测试任务树(PTT),这是一个记录测试状态、进展和待办事项的树状结构,解决了传统代理的上下文丢失和注意力偏差问题。PentestGPT通过“推理模块”(更新PTT、决策)、“生成模块”(将任务分解为具体命令)和“解析模块”(提炼信息)的协作,实现了系统化的自动化测试。
这些研究表明,以GPT-4为代表的顶尖人工智能模型,在适当的提示工程和工具赋能下,其网络攻击能力已不容小觑,正从理论快速走向实践。
PART. 5 大模型风险的框架
面对大模型日益增长的能力和潜在风险,各大公司纷纷建立了自己的风险管理框架。
5.1 OpenAI Preparedness Framework
这是一个结构化的“发现-评估-决策-行动”闭环,旨在防范灾难性风险。
- 风险定义:明确追踪网络安全、CBRN(化生放核)、模型自主性、说服力四类风险,并设定风险阈值。
- 评估:开发标准化测试(红队测试),衡量模型在各项风险上的具体能力。
- 治理与决策:设立独立的“安全顾问小组”,在模型风险超过阈值时,拥有暂停或停止部署的决策权。
- 行动:根据风险评估结果,采取相应措施,如不部署、暂停开发甚至销毁模型。
5.2 Anthropic Responsible Scaling Policy (RSP)
核心理念是安全措施必须与模型能力同步“扩展”。
- AI安全等级:定义了从ASL-1到ASL-5的等级。
- “暂停”承诺:若模型能力达到某个ASL等级但安全措施未达标,将暂停进一步的扩展或部署。
5.3 DeepMind Frontier Safety Framework
拥有结构化的内部评估、独立的“审查委员会”以及基于敏感度分类的部署决策机制,功能上与OpenAI框架类似。
Meta坚持开源路径,认为开放审查是安全的最佳实践。其重点在于发布时的安全微调、提供《负责任使用指南》以及开源安全工具(如Llama Guard),对“因灾难性风险而暂停开发”的论述较少。
这些框架表明,头部AI公司已将前沿模型的风险管理制度化。无论是倾向于闭源严格管控(OpenAI、Anthropic)还是拥抱开源透明(Meta),建立独立的监督机制和基于证据的决策流程已成为行业共识。
PART. 6 未来安全大模型的路线
面对这把日益锋利的“双刃剑”,未来的安全大模型将走向何方?答案并非简单的“攻”或“防”,而是在能力与可控性之间寻求平衡。演进路径可能呈现两个主要方向:
6.1 路径一:深度整合的“领域专家”模型
此路径主张从头构建专为网络安全设计的“白帽”专家模型。
- 训练数据:高度专业的攻防知识库、恶意软件样本库、安全代码库、实时威胁情报。
- 模型架构:可能采用混合或多智能体架构,模仿人类安全团队分工协作,以处理长链条复杂任务。
- 核心挑战:对齐与控制。如何确保一个精通所有攻击技巧的AI永不越界?这需要比现有技术更强大、更深度的安全护栏。
6.2 路径二:能力增强的“通用代理”模型
此路径主张增强顶尖通用大模型,而非重建。
- 核心理念:利用通用模型强大的基础智力(逻辑、代码、工具使用),为其配备顶级“安全装备”。
- 实现方式:
- RAG与即时学习:连接庞大的专业安全知识库作为“外接大脑”。
- 专用工具集:模型作为“指挥官”,熟练调用Nmap、Burp Suite等专业工具。
- 任务导向微调:强化安全领域的思维模式和术语。
- 优势与挑战:开发快,能享受通用模型进步红利;但能力受限于基座天花板,更像“工具使用专家”而非“原理直觉专家”。
6.3 结论:殊途同归,治理为王
无论选择哪条技术路径,未来的顶级安全大模型都必须具备以下特征:
- 攻防一体:深刻理解攻击,才能实现有效防御。
- 人机协同:AI主导执行,人类专家监督决策和解决创造性难题。
- 严格的治理框架:这是技术之上的基石。必须实现分级部署、独立监督、全程可审计。
最终,选择什么样的安全大模型,是一个技术、伦理与治理三位一体的战略抉择。我们追求的不仅是最强大的AI,更是最值得信赖、能将能力牢固锁定在造福人类轨道上的AI。打造利剑的竞赛已经开始,而为其铸造一个绝对可靠的剑鞘,将是决定数字世界未来的关键。对于安全从业者和技术爱好者而言,持续关注并参与这场关于人工智能安全与治理的讨论至关重要。像云栈社区这样的技术交流平台,正是分享见解、碰撞思想、共同应对挑战的优质空间。
 发表于 2026-4-11 07:32:45
|
查看: 122|
回复: 0
发表于 2026-4-11 07:32:45
|
查看: 122|
回复: 0
