论文名称:A Dual-Store Structure for Knowledge Graphs
论文作者:齐志鑫,王宏志,张昊然
论文链接:https://ieexplore.ieee.org/document/9468312
代码链接:https://github.com/database-ai4db-group/Dotil
转载须标注出处:哈工大海量数据计算研究中心
摘要
随着知识图谱在各领域的规模不断膨胀,如何高效存储和管理它们成为了一个关键问题。现有的主流方案主要分为关系型存储和原生图存储,但两者各有短板:关系型存储(如MySQL)擅长处理大规模数据更新,却在复杂查询时性能骤降;原生图存储(如Neo4j)能高效响应复杂查询,但存储容量有限且更新笨拙。
为了取长补短,本文创新性地提出了一种双存储结构,旨在利用图存储为关系型存储加速。然而,核心难题在于:如何动态决定将哪些数据、在何时从关系库迁移到图库?本文将这一问题形式化为一个马尔可夫决策过程,并设计了一个基于强化学习的物理设计调优器——DOTIL。通过DOTIL,双存储结构能够智能适应动态变化的工作负载,实现性能与灵活性的平衡。
背景
知识图谱作为认知智能的基石,其规模与复杂性日益增长。现实应用中,数据量巨大、查询模式复杂且负载动态变化的特性,给存储系统带来了严峻挑战。传统的关系型存储和图数据库在应对这些挑战时显得力不从心。
为了直观展示两种存储的差异,我们执行了一个复杂的SPARQL查询:“SELECT ?p WHERE{?p y:wasBornIn ?city. ?p y:hasAcademicAdvisor ?a. ?a y:wasBornIn ?city.}”,并对比了典型关系数据库MySQL与流行图数据库Neo4j的性能。测试中,我们将三元组数量从50万逐步增加到500万。
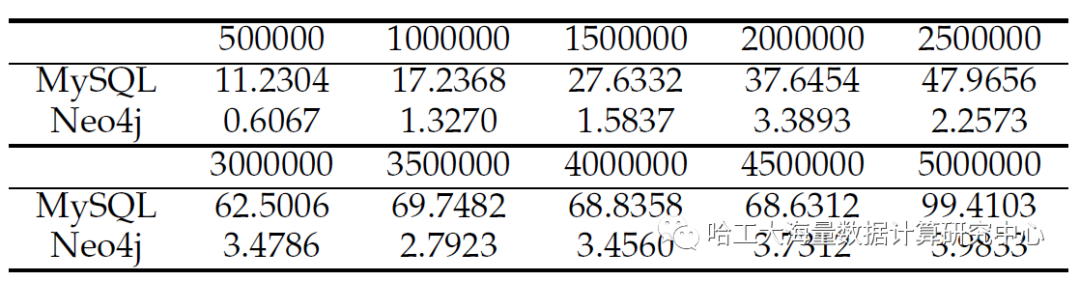
表1:MySQL和Neo4j的查询性能结果(单位:秒)
从表1可以看出,随着数据规模增大,MySQL的响应时间显著上升,而Neo4j的时间代价增长则平缓得多。这表明,对于复杂的图谱查询,图数据库受数据规模扩大的影响较小。基于此观察,我们萌生了一个核心思路:结合两者优势,设计一个双存储结构,让图数据库充当复杂查询的“加速器”,而关系数据库则作为存储完整数据的“大仓库”。
但这个结构面临一个关键挑战:工作负载是不断变化的,我们该如何动态决定将哪些数据子图迁移到图数据库中用于加速?这个问题,我们称之为双存储结构的物理设计调优。
现有的物理设计调优技术(如针对索引或物化视图的)无法直接套用。首先,动态场景要求调优器能基于历史经验自我调节,而传统启发式方法缺乏“记忆”能力。其次,我们的基本设计单位是数据划分(即图谱的子图),而非索引或视图。这本质上是一个收益未知且动态变化的背包问题变种。为此,我们引入机器学习模型的记忆与学习能力来解决这一难题。
我们将调优过程建模为马尔可夫决策过程:根据当前存储状态决定下一步动作(迁移哪些数据划分)。然后,利用强化学习技术来优化决策目标。假设图谱有n个数据划分,状态空间将达到2^n,如何利用有限的工作负载在如此巨大的状态空间中有效训练模型?为此,我们在调优器DOTIL中融合了状态分解策略和反事实场景技术,前者分解状态空间以增加训练频率,后者确保负载中的每个复杂查询都能被有效利用。
知识图谱双存储结构
本文提出的双存储结构有两个明确目标:一是充分发挥关系型存储与原生图存储的各自优势;二是能够根据动态工作负载进行自适应调节。
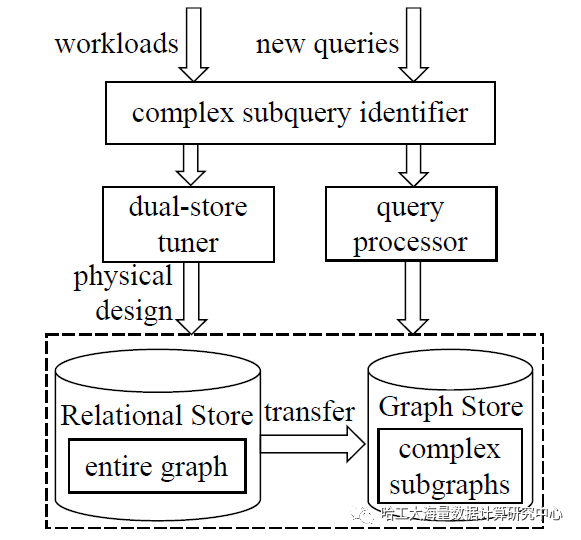
图1:知识图谱双存储结构
如图1所示,整个系统包含三个核心组件:
- 复杂子查询识别器:负责分析输入查询,判断其是否包含选择性大、执行代价高的复杂子图模式,并进行标记。
- 查询处理器:负责处理所有到来的查询。对于被标记的复杂查询,会优先尝试利用图存储中已有的数据子图进行加速处理。
- 双存储调优器 (DOTIL):这是系统的“智能大脑”。它学习历史工作负载的模式,并决策将关系型存储中的哪些有价值的数据划分迁移到图存储中,以优化未来查询的性能。
工作流程如下:识别器将标记出的复杂查询反馈给调优器;调优器基于强化学习模型积累的经验,自动将关系库中有潜在加速价值的数据子图迁移到图库;查询处理器则利用最新的存储布局来高效处理新查询。通过这一闭环,系统不仅能加速复杂查询,还能持续适应数据和负载的变化。
实验结果
为了验证双存储结构的有效性,我们在YAGO和Bio2RDF两个真实知识图谱数据集上进行了实验。我们将基于Jena(关系存储)和gStore(图存储)构建的双存储系统(Jena-gStore)与多种主流系统对比,包括关系型存储(Jena, Virtuoso, RDF-3X)、图数据库(gStore, GraphDB Lite, Neo4j)以及混合系统(TurboHom++)。
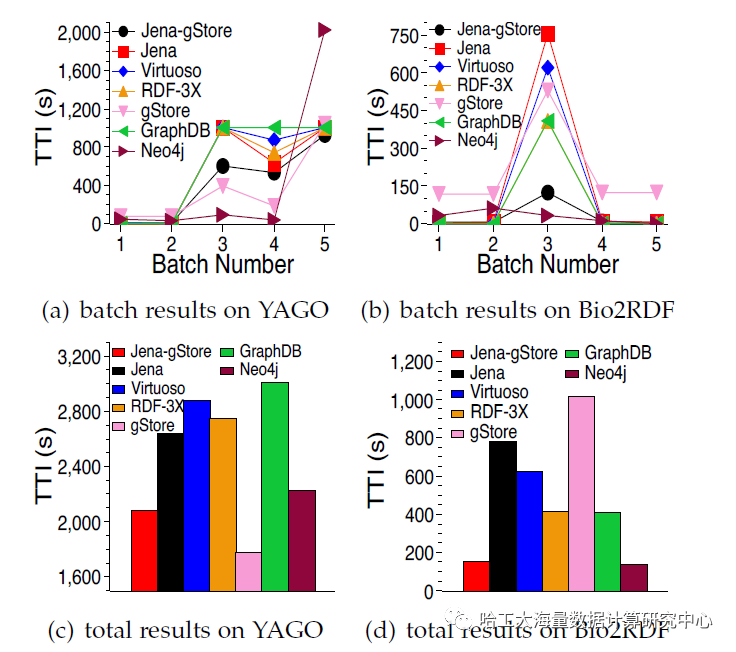
图2:对比实验结果(TTI: Total Time to Integrate)
从图2的实验结果可以得出以下结论:
- 优于纯关系存储:Jena-gStore在每一轮工作负载中的效率都优于所有纯关系型存储。这证明了图存储作为加速器的有效性。
- 与纯图存储的对比:在YAGO数据集上,Jena-gStore的总耗时略多于纯图数据库gStore,但在Bio2RDF上则优于gStore。gStore的性能受查询相关子图大小的影响很大,且其静态存储方式难以适应动态负载。而Jena-gStore凭借DOTIL调优器的学习能力,在动态场景下表现更稳定、更适用。
- 与其他图数据库对比:Jena-gStore的总耗时低于GraphDB Lite,且在YAGO上优于Neo4j。这凸显了双存储结构中“复杂子查询识别与分解”机制的优势,避免了像Neo4j那样需要匹配整个复杂子图带来的开销。
- 稳定性:Jena-gStore的性能曲线变化最为平缓,这得益于DOTIL能够持续学习并积累调优经验,使系统状态平滑过渡,避免了性能抖动。
这些结果充分验证了所提出的双存储结构及其基于强化学习的调优机制的高效性与适应性。
结论
本文针对大规模知识图谱的存储挑战,提出了一种创新的双存储结构。该结构巧妙融合了关系型数据库的容量优势与图数据库的复杂查询处理优势。为了解决动态数据迁移的核心难题,我们设计了基于强化学习的智能调优器DOTIL,使系统能够自主适应不断变化的工作负载。在真实数据集上的实验表明,该结构在保持高查询性能的同时,具备出色的适应性和稳定性,为大规模知识图谱的存储管理提供了一种有效的解决方案。
参考文献
[1] L. Zou, M. T. Özsu, L. Chen, X. Shen, R. Huang, and D. Zhao,“gstore: a graph-based sparql query engine,” The VLDB journal, vol. 23, no. 4, pp. 565–590, 2014.
[2] J. LeFevre, J. Sankaranarayanan, H. Hacigumus, J. Tatemura, N. Polyzotis, and M. J. Carey, “Miso: souping up big data query processing with a multistore system,” in Proceedings of the 2014 ACM International Conference on Management of Data, 2014, pp. 1591–1602.
[3] D. Van Aken, A. Pavlo, G. J. Gordon, and B. Zhang, “Automatic database management system tuning through large-scale machine learning,” in Proceedings of the 2017 ACM International Conference on Management of Data, 2017, pp. 1009–1024.
[4] K. Kara, K. Eguro, C. Zhang, and G. Alonso, “Columnml: Columnstore machine learning with on-the-fly data transformation,” Proceedings of the VLDB Endowment, vol. 12, no. 4, pp. 348–361, 2018.
[5] B. Ding, S. Das, R. Marcus, W. Wu, S. Chaudhuri, and V. R. Narasayya, “Ai meets ai: Leveraging query executions to improve index recommendations,” in Proceedings of the 2019 ACM International Conference on Management of Data, 2019, pp. 1241–1258.

技术探索的节奏,如同心跳,持续而有力。更多前沿技术讨论,欢迎访问云栈社区。
哈尔滨工业大学海量数据计算研究中心
 发表于 2026-4-11 08:02:34
|
查看: 115|
回复: 0
发表于 2026-4-11 08:02:34
|
查看: 115|
回复: 0
