你是否遇到过这样的困惑:在多线程或多核程序中,明明代码逻辑正确,变量赋值顺序也没错,但运行结果却总是不对?这背后,很可能就是“内存乱序访问”在作祟。为了解决这个问题,我们需要理解并正确使用内存屏障。
本文将围绕三个核心问题展开:
- Why? 为什么需要内存屏障,它主要解决什么问题?
- What? 内存屏障有哪些种类?
- How? 内存屏障如何使用?(本文主要探讨前两个问题)
一、为什么要有内存屏障
在计算机中,CPU负责逻辑运算,内存负责数据存储,二者需要频繁交互。然而,CPU的运算速度与内存的访问速度之间存在巨大的数量级差距。为了弥补这个差距,现代处理器普遍引入了高速缓存(Cache),它的读写速度尽可能接近CPU。
CPU在进行计算时,会先将需要的数据从主内存复制到缓存中,这样CPU就能快速进行运算,而不必等待缓慢的内存读写。计算完成后,再将结果从缓存同步回主内存。下图展示了一个典型的多核CPU缓存架构。
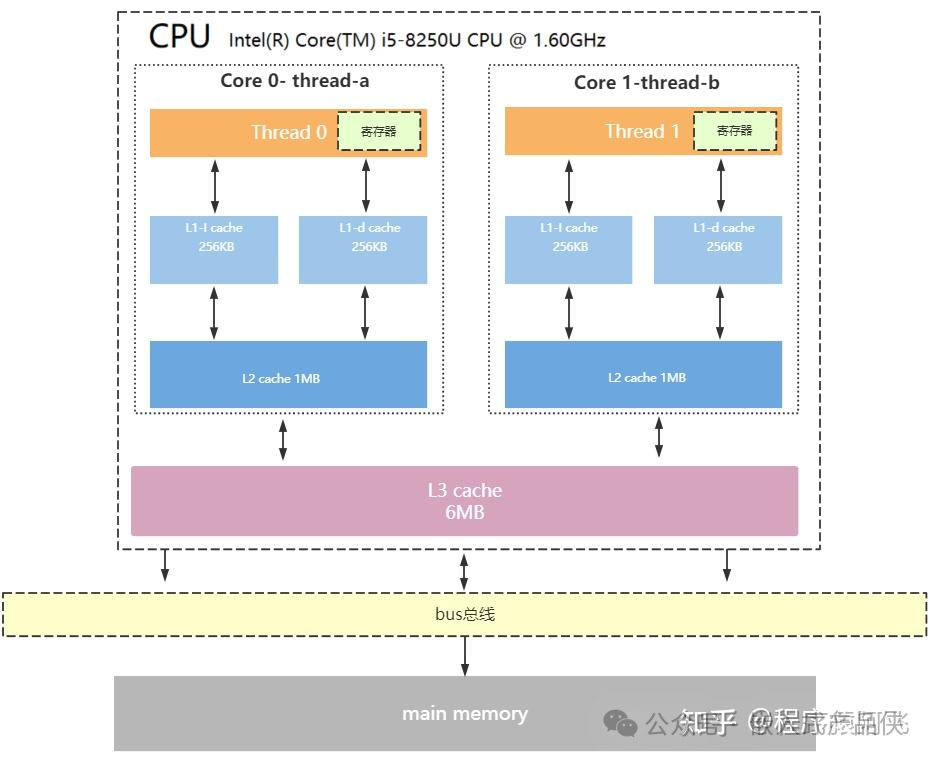
每个CPU核心都拥有自己独享的缓存(常见的有L1、L2),甚至多个核心共享L3缓存。缓存的引入极大地提升了性能,但也带来了一个显著问题:数据在不同CPU核心的缓存中可能存在多个副本,且这些副本的更新无法实时同步到主内存或其他CPU的缓存中,从而导致不同CPU上运行的不同线程看到同一个变量的值可能不一致。
简单来说,现代计算机为了极致性能,普遍采用了指令的“乱序执行”策略。而乱序执行可能会导致程序运行结果不符合开发者的直观预期,这正是内存屏障成为并发编程中必需品的原因。
二、乱序访问
乱序访问主要分为两类:编译时内存乱序访问和运行时内存乱序访问。
2.1 编译时内存乱序访问
编译器在优化代码时,可能会改变实际执行指令的顺序(例如在使用g++的-O2或-O3优化选项时)。看一个简单的例子:
int x, y, r;
void f()
{
x = r;
y = 1;
}
首先,我们不加优化直接编译这个源文件:g++ -S test.cpp。得到的汇编代码如下:
movl r(%rip), %eax
movl %eax, x(%rip)
movl $1, y(%rip)
可以看到,x = r和y = 1的指令顺序与源码一致,没有乱序。
现在,使用优化选项-O2编译上面的代码(g++ -O2 -S test.cpp),生成的汇编代码变成了:
movl r(%rip), %eax
movl $1, y(%rip)
movl %eax, x(%rip)
可以清楚地看到,经过编译器优化后,movl $1, y(%rip)(对应y=1)先于movl %eax, x(%rip)(对应x=r)执行。这意味着编译器优化导致了内存访问顺序的变更。
解决这个问题的方法是使用编译器屏障(又称优化屏障)。Linux内核提供了barrier()宏,用于让编译器保证其之前的内存访问先于其之后的内存访问完成。
#define barrier() __asm__ __volatile__("": : :"memory")
现在将这个编译器屏障加入代码中,再编译就会发现内存乱序访问被消除了。
int x, y, r;
void f()
{
x = r;
__asm__ __volatile__("" : : : "memory");
y = 1;
}
2.2 运行时内存乱序访问
在运行时,CPU本身也可能会乱序执行指令。早期的处理器是有序处理器(in-order processors),严格按照程序顺序执行指令。如果某条指令需要的输入数据不可用(例如还在从内存加载),处理器就会停下来等待。
相比之下,乱序处理器(out-of-order processors)则会先执行那些输入数据已经可用的指令,从而避免了空闲等待,显著提高了效率。现代处理器的速度远快于内存,即使是乱序执行,在单个CPU核心内部,由于指令获取和结果提交的队列机制,所有内存操作看起来仍然是按程序顺序执行的(在不考虑编译器优化的情况下)。因此,在单核场景下,内存屏障的必要性较低。
但在SMP(对称多处理)架构下,情况就大不相同了。
在SMP架构中,每个CPU核心都有自己的高速缓存,用于减少访问主内存时的冲突,这是现代计算机基础架构的典型设计。
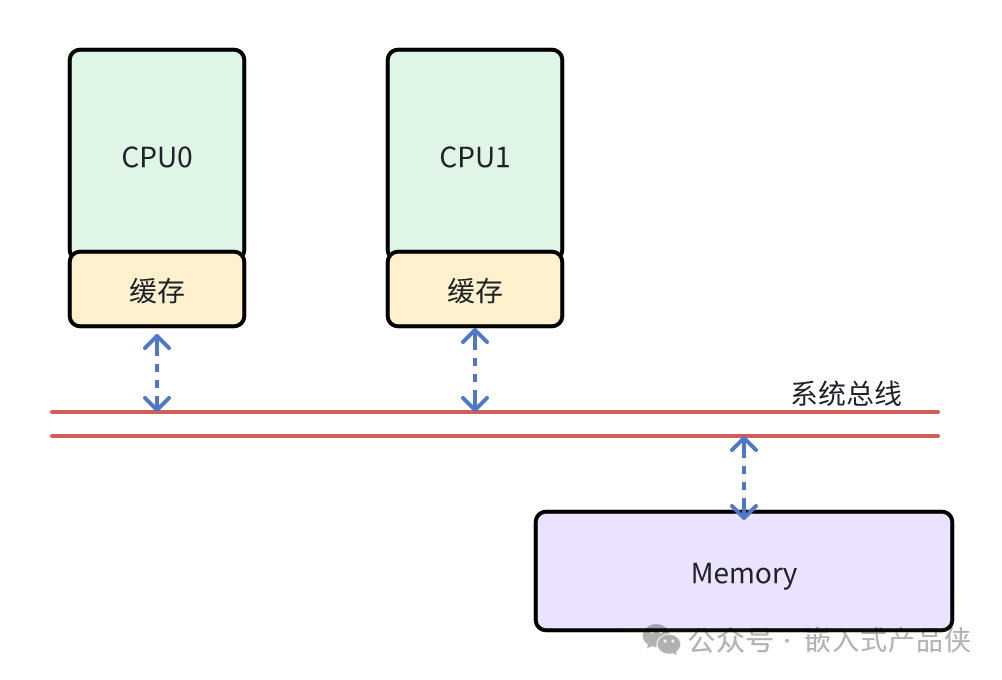
高速缓存的写入通常有两种模式:
- 写穿透(Write through):每次写操作都直接写回主内存。这种方式简单但效率较低。
- 写回(Write back):写操作先写入高速缓存,随后由缓存硬件在缓存行(Cache Line)需要被复用(淘汰)时自动写回内存,或由软件主动“冲刷”相关缓存行。出于性能考虑,系统通常采用这种模式。
正是由于写回模式的存在,才导致了在SMP架构下,对高速缓存的操作可能会改变从其他CPU核心视角观察到的内存操作顺序。
来看下面这个经典例子:
// thread 0 -- 在CPU0上运行
x = 42;
ok = 1;
// thread 1 – 在CPU1上运行
while(!ok);
print(x);
请问,线程1打印出的x一定是42吗?答案是不一定。下图展示了一种可能的错误时序:
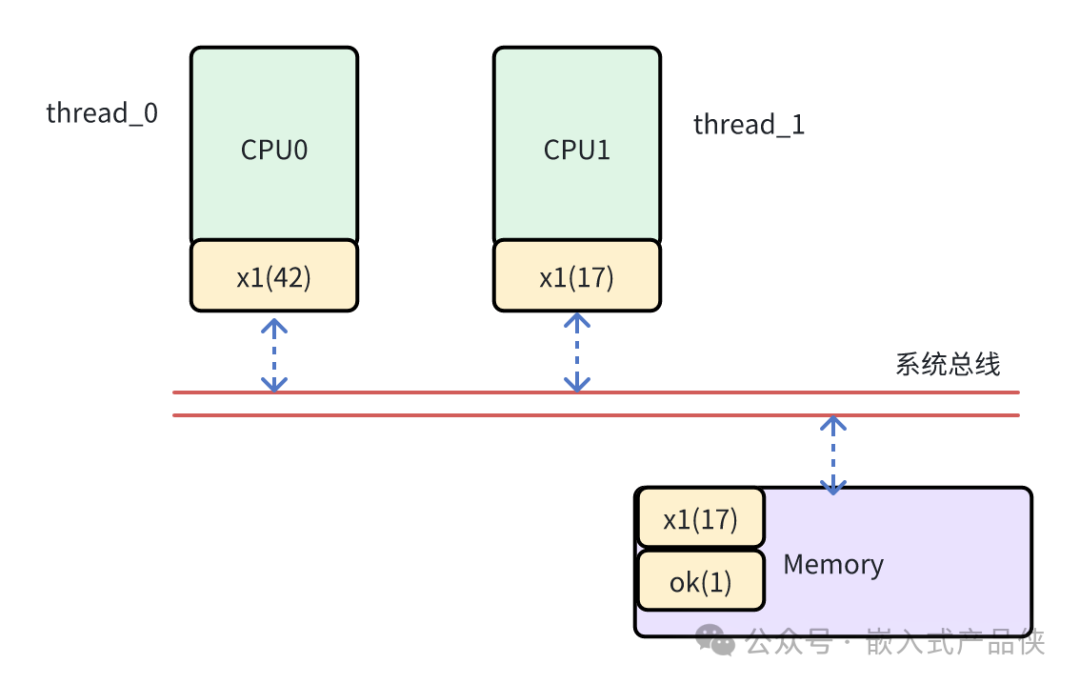
假设发生以下情况:
- CPU0的缓存中存有变量
x,执行x=42时,值42只写入了CPU0的缓存,尚未刷回主内存。
- 变量
ok也在CPU0的缓存中,但由于缓存行淘汰机制,ok=1这个写操作被提前刷回了主内存。
- 此时,CPU1执行循环
while(!ok),它从主内存读到了ok=1,于是跳出循环,去读取x的值。
- 由于
x=42还停留在CPU0的缓存中,CPU1从主内存(或其自身缓存)读到的x可能仍然是旧值(例如17)。
这就是运行时内存乱序访问导致的数据不一致性问题,它是由多核CPU的缓存一致性协议(如MESI)以及写缓冲、无效队列等微架构优化共同作用的结果。
三、内存屏障分类
为了解决上述问题,我们需要不同种类的内存屏障来约束处理器和内存系统的行为。
3.1 编译屏障
如前所述,编译屏障(如barrier())的作用是阻止编译器对屏障前后的内存访问指令进行重排序。它只影响编译器生成的指令顺序,对CPU运行时的指令重排没有任何约束力。
3.2 写内存屏障
写内存屏障保证:从系统中其他组件(包括其他CPU)的角度来看,在屏障之前的所有写操作,都将在屏障之后的任何写操作之前生效(即变得可见)。
映射到上面的例子,写内存屏障做了两件事:
- 限制指令重排:确保屏障前的写指令不会被重排到屏障后的写指令之后。
- 清空写缓冲区:确保在执行屏障后的写指令前,必须将当前CPU写缓冲区(Store Buffer)中的所有写操作全部“提交”到缓存或内存中。
这样,系统中的其他CPU就能保证先看到x=42,然后才可能看到ok=1。写内存屏障只约束存储(写)操作,不约束加载(读)操作。它只能保证自己CPU上写入操作的提交顺序,但管不了其他CPU的缓存是否失效。因此,它通常需要与读内存屏障配对使用。
3.3 读内存屏障
读内存屏障保证:从系统中其他组件的角度来看,在屏障之前的所有读操作,都将在屏障之后的任何读操作之前完成。
它同样做两件事:
- 限制指令重排:确保屏障前的读指令不会被重排到屏障后的读指令之后。
- 处理无效队列:确保在执行屏障后的读指令前,必须处理完当前CPU的无效化队列(Invalidate Queue),从而使其缓存状态严格遵循一致性协议。
这样,CPU1在print(x)之前插入读屏障,就能确保它在读取x之前,已经处理完了可能使x缓存行失效的请求(即来自CPU0的x=42的更新通知)。读内存屏障只约束加载操作,不管存储操作。它需要写内存屏障的配合,才能完整保证数据一致性。
3.4 通用内存屏障
通用内存屏障(或称全内存屏障)结合了读屏障和写屏障的功能。它保证:屏障前的所有加载和存储操作,都在屏障后的任何加载和存储操作之前完成。
它是最强的一类屏障,通过同时限制加载和存储的排序,并确保清空写缓冲区、处理无效队列,来提供最强的顺序一致性保证。它可以在功能上替代单独的读屏障或写屏障,但性能开销可能更大。
通常,写屏障、读屏障和通用屏障的实现都会默认包含编译屏障的效果。
四、现有架构的内存屏障操作
不同的CPU架构提供了不同的内存屏障指令。
4.1 x86/64
x86/64架构提供了三种明确的内存屏障指令,在Linux内核中定义如下:
// linux-6.9.1/arch/x86/include/asm/barrier.h (示例)
#define __mb() asm volatile("mfence":::"memory")
#define __rmb() asm volatile("lfence":::"memory")
#define __wmb() asm volatile("sfence" ::: "memory")
- sfence:可近似理解为“存储屏障”,确保该指令前的所有存储操作在该指令后的存储操作之前对内存可见。
- lfence:可近似理解为“加载屏障”,确保该指令前的所有加载操作在该指令后的加载操作之前完成。
- mfence:全能屏障,同时具备
lfence和sfence的功能。
4.2 ARM64
ARM64架构提供的内存屏障指令更为丰富和精细:
// linux-6.9.1/arch/arm64/include/asm/barrier.h (示例)
#define isb() asm volatile("isb" : : : "memory") // 指令同步屏障
#define dmb(opt) asm volatile("dmb " #opt : : : "memory") // 数据内存屏障
#define dsb(opt) asm volatile("dsb " #opt : : : "memory") // 数据同步屏障
// 多核场景下常用的SMP屏障
#define __smp_mb() dmb(ish) // 全屏障
#define __smp_rmb() dmb(ishld) // 读屏障
#define __smp_wmb() dmb(ishst) // 写屏障
// 更强的系统范围屏障
#define __mb() dsb(sy)
#define __rmb() dsb(ld)
#define __wmb() dsb(st)
// 用于DMA操作的外围设备屏障
#define __dma_mb() dmb(osh)
#define __dma_rmb() dmb(oshld)
#define __dma_wmb() dmb(oshst)
ARM64的屏障指令(dmb, dsb)可以通过参数指定屏障的作用域(如ish表示Inner Shareable Domain,即所有核心),从而进行更精确的控制,这也是其计算机体系结构设计上的一个特点。
五、总结
现代计算机,无论是通过编译器的激进优化,还是CPU自身的乱序执行与缓存体系,都在以“乱序”的方式追求极致的性能。这种乱序主要分为编译乱序和运行时乱序。编译乱序可以通过编译器屏障来约束,而运行时乱序,尤其是在SMP多核环境下,则需要依靠读内存屏障、写内存屏障或通用内存屏障来保证多线程间数据访问的正确顺序与可见性。
理解内存屏障的原理和分类,是编写正确、高效并发程序的关键一步。对于更深入的系统级开发或内核驱动开发,掌握不同硬件架构下的屏障指令差异也至关重要。如果你想与其他开发者交流更多底层技术细节,欢迎来到云栈社区的计算机基础板块进行探讨。
 发表于 2026-4-11 08:21:05
|
查看: 134|
回复: 0
发表于 2026-4-11 08:21:05
|
查看: 134|
回复: 0
