在开始本章之前,先对系列文章(一)中的一处描述进行勘误。原文提到“virtual runtime = physical runtime/ weight”, 并称其为PELT负载计算的简化。这里的描述有误。virtual runtime 主要用来量化不同CFS进程间的调度竞争关系,而PELT是用于量化系统负载大小的,二者并非同一概念。
回顾前文内容,可能会让人有些困惑:负载统计基于历史,不准确;频率预测也不准;功耗模拟计算同样不准。如果这些核心输入都不准,EAS(能效感知调度)最终的效果真的可靠吗?然而,挑战远不止于此。
前文介绍了PELT和WALT两种负载量化方法,但我们都暂时忽略了一个关键变量:CPU的运行频率。
1. 任务负载归一化
为了便于理解,我们以WALT为例,其窗口内的负载计算比PELT的复杂衰减计算更直观。

在引入大小核(big.LITTLE)架构后,问题变得更加复杂。显然,同样是运行5毫秒,在100MHz频率下与在200MHz频率下,对算力的需求是不同的,最终的量化结果也应不同。同理,在小核上运行5毫秒与在大核上运行5毫秒,其需求和量化结果也不一样。
因此,我们不得不补充WALT计算的剩余部分,即负载的归一化(load scale)。更细节的内容可以参考 官方文档。
假设我们认为整个CPU系统中,算力最大的CPU(通常是超大核)在其最高频率下的能力值定义为1024(1024是2的10次方,计算机处理方便)。在“算力与频率线性相关”的假设下,我们可以计算出任何CPU(无论小核、大核或超大核)在任一频率下的能力值。
举例:假设超大核的IPC(每时钟周期指令数,性能指标)是3,最高频率是3GHz;大核的IPC是2,最高频率是2GHz。那么大核在2GHz下的能力值计算如下:
1024 * (2/3) * (2GHz/3GHz) = 455.11
因此,在计算某个任务在特定窗口内的负载时,归一化公式变为:
task_load = (running_time / window_size) * (f_curr / f_max) * capacity_max(cpu);
running_time:线程在窗口周期内的运行时间。capacity_max:该CPU的最大能力值。f_max:该CPU的最大频率。f_curr:CPU的当前运行频率(f_curr <= f_max)。window_size:WALT的统计窗口周期(注:在WALT中,此周期随屏幕刷新率变化但非完全对齐。为降低开销,窗口大小是时钟tick的整数倍。例如120Hz下为8ms,60Hz下为16ms。这可能导致负载统计跨窗口的问题)。
再次考虑前文讨论的死循环进程(模拟突发高负载),此时 running_time == window_size。
task_load = f_curr / f_max * capacity_max(cpu);
因此,即使任务是一个CPU使用率很高的死循环,如果当前运行频率较低,它仍可能被判定为一个小任务。这是否让你感到熟悉?一个任务在小核上长时间运行,难以迁移到大核,其根本原因正是调度器在量化时判定它是一个小任务。
本系列聚焦于任务调度本身,但本章不得不涉及一个与调度紧密互动的模块:CPU调频器。
2. CPU调频(cpufreq governor)的相互作用
CPU调频是一个与调度互相影响的模块。根据上面的讨论,任务的归一化负载计算公式变为:
task_load = f_curr / f_max * capacity_max(cpu);
显然,任务负载的计算直接依赖于当前CPU的运行频率。
为了最大化简化模型,我们假设调频的计算公式如下:
f_next = CPU_load / capacity_max * f_max * 1.25;
在CPU 100%满载的情况下,CPU_load = f_curr / f_max * capacity_max(cpu)。 那么 f_next 就变为:
f_next = (CPU_load / capacity_max) * f_max * 1.25
= (f_curr / f_max * capacity_max(cpu)) / capacity_max(cpu) * f_max * 1.25
= f_curr * 1.25;
这里的1.25(即除以0.8)是一个经验值。普遍认为CPU使用率维持在80%左右比较理想,能在保障性能余量的同时节省功耗。至于为什么是80%,这类似于煮米饭时水没过手指的经验,是一个性能拐点的经验选择。
因此,在CPU满载的情况下,下一个频率将是当前频率的1.25倍。记住这个结论。
一个奇怪的循环出现了:负载计算依赖于频率,而频率调节又反过来依赖于负载的输入。二者形成了“鸡生蛋还是蛋生鸡”的互相依赖关系。
以 f_next = f_curr * 1.25 这种极端情况为例,我们得出了一个结论:CPU在低频时,升频速度会非常慢,因为基数低,增加的25%绝对值也很小。而频率低,又会导致我们准确量化任务负载所需的时间变得更长。
这就引出了一个根本性难题:对一个任务负载的量化不够准确,且存在很长的延迟。这种延迟会在性能上导致诸多问题。如下图,QQ主线程因业务实现问题导致负载不均匀、出现跳变,而调度器对此似乎无能为力。所幸大部分情况下,负载相对均匀。

当然,虽然从调度机制本身看这个问题似乎无解,但结合具体业务,仍可缓解。笔者曾写过一篇相关文章:《利用ADPF性能提示优化Android应用体验》。
前面介绍了Linux的RT/CFS调度类、负载量化算法、大小核算力归一化以及EAS。现在让我们再次回到RT/CFS调度类。大家最关心的其实是任务的调度延迟(即就绪状态到运行状态的等待时间),因为在实际性能分析中,由调度延迟导致的卡顿最为常见。
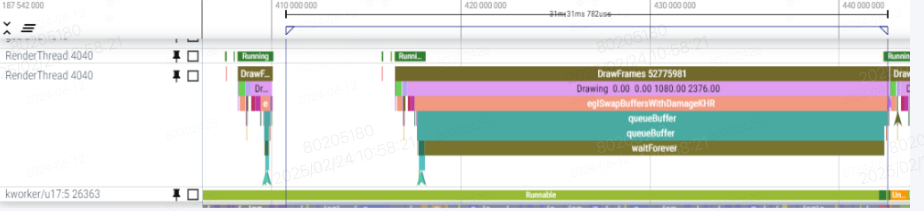
如上图,内核线程 kworker 的 runnable 延迟最终导致了掉帧。
前文提过,RT调度类基于优先级选核,严格遵循高优先级抢占。而CFS进程的priority字段实际上代表的是一个权重(weight),用于表示在一定时间内占用资源的比例。
在之前的例子中(特别是cgroup份额的例子),我们多以死循环为例。这里有必要说明原因。当我们讨论资源分配的比例时,有一个重要前提:任务间存在资源竞争。没有竞争,就谈不上比例分配。或者说,权重比例问题,只存在于竞争环境下。
举个例子:两个任务task1和task2,task2权重是task1的两倍。但task1全程处于active状态参与竞争,task2只在后半段时间active(前半段可能因条件未满足而sleeping)。
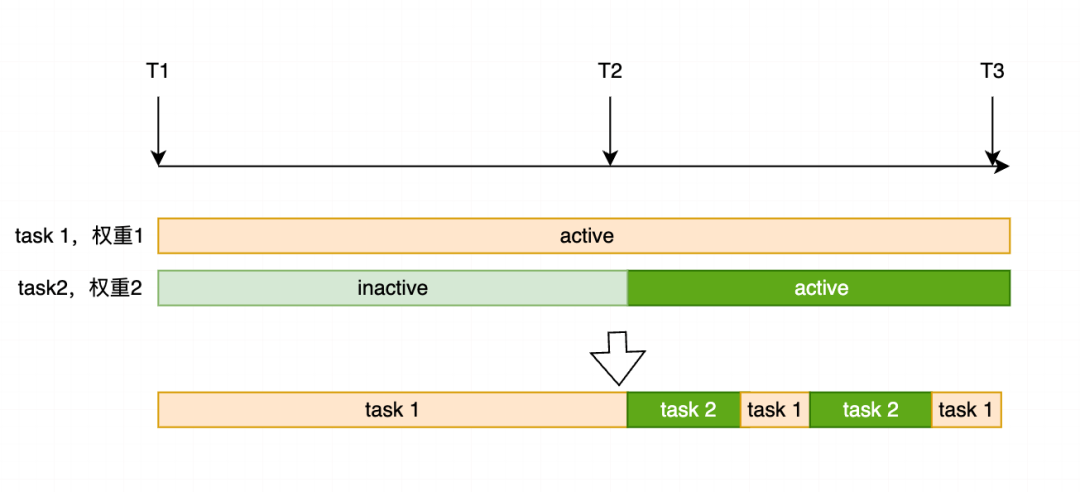
那么在时间(T1, T2)内,task1独占CPU,因为不存在竞争;在(T2, T3)内,task1和task2存在竞争,由于权重比2:1,task2占有的资源比例更高。我们不应该认为在整个(T1, T3)时间段内,task1和task2的资源配比必须是1:2。这是不对的(试想,服务器上一个进程已运行数月,此时新建一个进程,难道运行数月的进程就没机会运行了?)。当然,实际情况比我描述的更复杂。
3. sys.use_fifo_ui 与特权CFS线程
在Android中,有一个 sys.use_fifo_ui 属性,将其设置为true可以将UI主线程和渲染线程设为 SCHED_FIFO 而非 SCHED_OTHER。这能有效消除界面线程造成的抖动。那Google为何不默认开启呢?原因可能包括:
- RT负载均衡器不具备能力(capacity)感知:Linux RT调度类设计之初假设RT线程负载轻、对延迟敏感。因此它不要求特定算力,可以运行在任何CPU上。但Android的应用主线程和渲染线程负载经常很重。缺乏负载感知容易将其调度到小核,导致算力不足。这也是一些平台上GPU合成时,SF/RE/Composer等线程跑在小核引发卡顿的原因。
- RT调度类过于“霸道”:调度类有优先级之分,RT调度类的优先级高于CFS。只要存在可运行的RT线程,CFS线程就得不到运行机会,系统易发生ANR。为此,RT调度类设计了一个定时器进行周期性采样限制:在一个
sched_rt_period_us 周期内,RT线程累计运行时间不能超过 sched_rt_runtime_us。这两个参数可调。
OP5AE7Ll:/proc/sys/kernel # cat schd_rt*
1350000
1250000
OP5AE7Ll:/proc/sys/kernel # ls sched_rt*
sched_rt_period_us sched_rt_runtime_us
OP5AE7Ll:/proc/sys/kernel #
- 权限可能失控:一个RT线程
fork出来的新进程默认也是RT优先级。
因此,各平台厂商设计了不同的特权CFS线程策略,如高通的MVP线程、联发科的VIP线程等。有兴趣可以查阅高通WALT(msm-kernel/kernel/sched/walt/)或联发科EAS(kernel_device_modules-6.6/drivers/misc/mediatek/sched/eas/)的代码。
当一个CFS线程被标记为VIP(此处统称特权CFS进程)时,它会得到优先调度,类似于CFS中的“RT”线程。原理简单:当没有RT线程时,调度器执行CFS选任务逻辑,会先尝试从VIP队列中选一个未“超时”的有效VIP线程,如果没有,则回退到原生CFS逻辑。
相关逻辑在 pick_next_task_fair 函数中,由于Google GKI的限制,这部分UI选任务逻辑被写在了 trace_android_rvh_replace_next_task_fair 这个hook函数里。
针对不同类型的UX线程,厂商设置了超时机制,避免VIP线程运行过久导致系统卡顿或ANR。
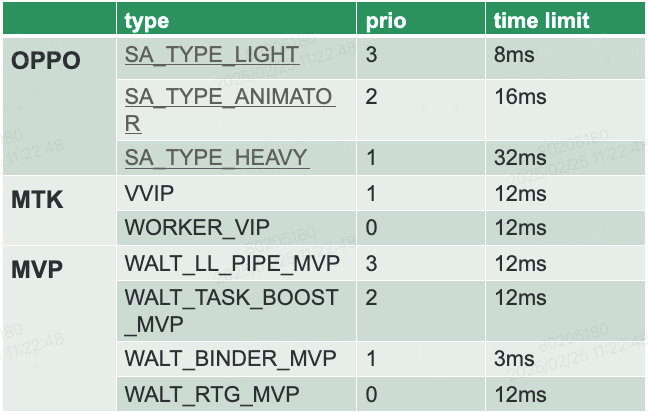
实际上,整个Android系统中的RT线程越来越多(如audio service部分线程优先级96,SurfaceFlinger线程优先级98,部分内核threaded irq线程优先级49等),它们都对调度延迟有极高要求。
那么,是否将系统关键线程都设为RT或VIP就高枕无忧了?
4. 优先级反转(Priority Inversion)
事情远未结束。
关于优先级反转,有一篇知乎文章讲得比较详细。我们先描述现象。

上图是一个卡顿的Trace截图。kgsl_worker_thr 是高通GPU驱动的一个RT线程,但它处于D状态(不可中断睡眠),在等待某个锁。而锁正被 kworker/u24:8 这个普通CFS线程持有。如前所述,CFS是比例分配策略,在高负载下必然出现 runnable 延迟(只是长短问题)。这种情况就被称为优先级反转。
Linux内核提供了解决优先级反转的方法:rtmutex(kernel-6.6/kernel/locking/rtmutex.c)。其实现复杂但原理简单:当一个RT线程因锁进入D状态等待时,它会将自己的RT优先级传递给锁的持有者(即上图中的 kworker/u24:8 线程)。kworker/u24:8 会被临时提升到RT优先级,获得优先调度。当它释放锁(rtmutex_unlock)时,优先级恢复为原来的CFS级别。
通过这种优先级传递和临时提升的方法,可以缓解优先级反转。既然Linux有此机制,为何我们仍会在Android上遇到该问题?
答案是:只有 rtmutex 能触发此机制,但系统中锁的类型非常多(如 mutex、futex、rwsem 等)。要解决优先级反转,必须显式使用 rtmutex 锁。该机制的覆盖范围太有限。
类似机制在Binder中也能看到。参考 binder_transaction_priority 函数,当RT线程发起Binder请求时,服务端线程可以临时继承客户端的RT优先级,防止客户端被阻塞。
5. 不同设计哲学的权衡
在整个Linux系统设计中,存在几种不同的考量:
- 偏向低延迟:如RT调度类、
rtmutex。它们保证高优先级线程优先调度,但引入了额外开销(如 rtmutex 需要查找owner、遍历链表调整优先级等),降低了系统整体吞吐量。
- 偏向公平与均衡:如CFS比例分配调度、
mutex 的FIFO队列、以CPU利用率为输入的调频策略。它们在性能与功耗、公平与效率间寻求平衡。
Linux是一个高度兼容的开源操作系统,从MCU到服务器都能支持。为了兼容各种设备的业务需求,它不断进行调和与折中,导致其调度系统变得有些“四不像”,往往只能做到“基本能用”,离“极致”体验尚有距离。
这里不得不提Windows(参考《深入解析Windows操作系统》)和iOS,它们都更接近一种调度类(类似于Linux的RT调度类),基于高优先级抢占,并结合系统状态动态调整线程优先级(如解决优先级反转、I/O阻塞提权等)。但这种设计也可能导致高优先级线程占用资源过多,使低优先级线程“饿死”。为此,Windows引入了一个“平衡集管理器”线程,周期性地扫描并提升可能被饿死线程的优先级。

网上有一篇文章《为什么Windows/iOS操作很流畅而Linux/Android却很卡顿呢》,可以扩展了解。
本系列文章源于内部的技术科普,为控制篇幅,部分内容由多篇短文拼接而成,若有不连贯之处,敬请见谅。此系列暂告一段落,后续将探讨具体平台(如“绿厂”)如何优化此类问题,敬请期待。
 发表于 2026-4-11 19:36:23
|
查看: 205|
回复: 0
发表于 2026-4-11 19:36:23
|
查看: 205|
回复: 0
