2025 年,随着 Neon 和 CrunchyData 两家 PostgreSQL 生态公司被收购,PostgreSQL 再次成为行业焦点。除了数据库本体的发展,其生态扩展主要沿两条路径推进:我称之为“自下而上”的扩展方式和“自上而下”的协议兼容方式。
以与 Rust 生态的结合为例,“自下而上”的方式主要基于 pgrx 框架,将各种 Rust 库引入 PostgreSQL 内部,代表项目如 ParadeDB;而“自上而下”的方式则通过模拟 PostgreSQL 的协议和接口,构建出各种“类 Postgres”的全新数据库。
GreptimeDB 从早期版本就开始适配 Postgres 协议,走的正是“自上而下”这条路。
什么是 Postgres 协议?
狭义的 Postgres 协议,特指用于与 PostgreSQL 服务端通信的 TCP 应用层协议。当我们使用 psql 命令行工具或 JDBC 驱动连接数据库时,底层发生的正是基于此协议的通信。
概括来说,这个协议主要包含 5 个部分:
- 启动:包含连接建立阶段的握手信息交换和各类认证机制。
- 简单查询:基于文本的查询和响应。
- 扩展查询:俗称 PreparedStatement,支持后端缓存查询语句,仅传输参数,提升效率。
- 拷贝:用于数据的批量导入和导出。
- 取消:取消一个正在执行的查询。
这里我们并未包含数据库逻辑同步协议和流式同步协议,尽管它们也采用了类似的思路。
然而,要实现相对完整的 Postgres 兼容性,仅支持狭义的网络协议是远远不够的,我们还需要支持广义的 PostgreSQL 接口,包括:
- 查询语言:兼容其 SQL 方言和关键内置函数。
- 数据类型系统:建立与 Postgres 自身类型系统的映射关系。
- pg_catalog 元信息:支持其元数据体系,这是许多客户端工具能正确工作的基础。
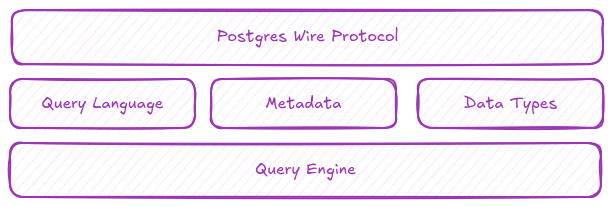
兼容 Postgres 协议的好处
相较于从头设计一套全新的四层协议,复用成熟的 Postgres 协议带来诸多优势:
-
经过充分验证,核心功能可靠。PostgreSQL 当前主流的 3.0 版本协议已稳定运行十多年,经过了海量生产环境的考验。它完整支持 TLS、多种认证方式以及与客户端的特性协商。这套协议本身甚至具备流式返回数据的能力,只是受限于 PostgreSQL 原生的进程模型而未被充分利用。
-
解锁海量的生态工具链。几乎每种主流编程语言都有成熟的 PostgreSQL 客户端驱动。只需实现协议支持,就能直接使用这些驱动来编写访问 GreptimeDB 的应用程序。此外,从最简单的 psql 命令行,到 DBeaver 等 GUI 管理工具,再到各类 BI 报表系统,都可以将兼容 Postgres 协议的数据库直接当作 PostgreSQL 来使用。这部分工具往往对 pg_catalog 的兼容性有更高要求,以便提取元数据。
-
可作为原生 PostgreSQL 的 FDW 数据源。这意味着你可以将 GreptimeDB 挂载为原生 PostgreSQL 的一个外部数据源,直接在 PostgreSQL 中发起 SQL 查询,甚至可以实现两个异构数据库之间的 JOIN 操作。这种架构非常适合混合数据管理的场景,例如用原生 PostgreSQL 管理设备元数据,而用时序数据库 GreptimeDB 管理其产生的指标数据。
当然,Postgres 协议也存在一些局限性:
- 协议面向行式数据结构设计。如果数据库底层是列式存储,在返回原始数据时需要进行行列转换,可能带来额外开销。
- 查询取消机制与 PostgreSQL 的进程模型强绑定,在其他架构中较难实现,且存在一定的安全风险。
- 扩展查询对数据库的类型推断能力有要求。协议要求数据库能在不实际查询数据的情况下,对语句中的变量参数进行类型推断。例如 SQLite 和 DuckDB 就无法直接从语句推断参数类型,因此难以完整适配扩展查询协议。
GreptimeDB 如何实现兼容?
GreptimeDB 通过笔者开发的 pgwire 库及其在 DataFusion 查询引擎上的生态来实现 Postgres 协议兼容。
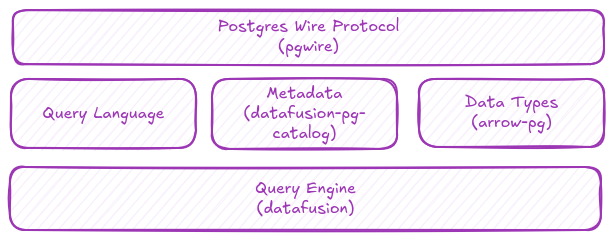
传输协议支持
如果将 Postgres 协议比作 HTTP 协议,那么 pgwire 就相当于 Rust 生态中的 hyper 乃至 axum 框架。它帮助用户构建兼容 Postgres 协议的服务端,用户可以选择性地实现认证、简单查询、扩展查询、拷贝等功能,以达到不同程度的兼容性。
以简单查询为例,pgwire 提供了两个层次的 API:
- 低层 API:
SimpleQueryHandler::on_query,关注网络消息层面的处理和协议语义。
- 高层 API:
SimpleQueryHandler::do_query,关注数据层面的处理和业务语义。
有趣的是,对于简单查询子协议,它甚至不要求客户端发送的必须是 SQL 语句。下面是一个简单的“回声”处理器示例,它会将任何输入字符串原样返回:
#[async_trait]
impl SimpleQueryHandler for EchoHandler {
async fn do_query<C>(&self, _client: &mut C, query: &str) -> PgWireResult<Vec<Response>>
where
C: ClientInfo + Sink<PgWireBackendMessage> + Unpin + Send + Sync,
C::Error: Debug,
PgWireError: From<<C as Sink<PgWireBackendMessage>>::Error>,
{
let query = query.to_string();
let f1 = FieldInfo::new("input".into(), None, None, Type::VARCHAR, FieldFormat::Text);
let schema = Arc::new(vec![f1]);
let data = vec![Some(query)];
let mut encoder = DataRowEncoder::new(schema.clone());
let data_row_stream = stream::iter(data).map(move |r| {
encoder.encode_field(&r)?;
Ok(encoder.take_row())
});
Ok(vec![Response::Query(QueryResponse::new(schema, data_row_stream,))])
}
}
使用 psql 连接这个服务,你会看到如下效果:
❯ psql -h 127.0.0.1 -p 5432 -U postgres
psql (18.1, server 16.6-pgwire-0.38.2)
Type "help" for help.
postgres=# hello world;
input
--------------
hello world;
(1 row)
pg_catalog 元信息支持
pgwire 解决了网络协议问题,但要实现更深入的兼容性(特别是让 GUI 工具正常工作),就必须提供元信息 (pg_catalog) 支持。由于 pg_catalog 本质上是一系列系统表或视图,因此需要构建在某个查询引擎之上。
GreptimeDB 使用了 Apache DataFusion 作为其查询引擎。为此,我们维护了 datafusion-postgres 项目。它充当了 pgwire 与 DataFusion 查询引擎、Arrow 内存格式之间的适配器,其中包含了对 pg_catalog 的支持以及 Arrow 数据到 Postgres 数据格式的转换模块 (arrow-pg)。
pg_catalog 功能庞杂,许多表与 PostgreSQL 内部机制深度绑定。我们优先关注其中几个核心表:
pg_database: 数据库信息pg_namespace: 模式(schema)信息pg_tables: 表信息pg_class: 列信息
一些高级管理工具(如 DataGrip)在连接初始化阶段会发送非常复杂的 pg_catalog 查询,可能涉及 DataFusion 不支持的语法或 UDF。这部分适配工作需要针对性处理,也欢迎对 数据库/中间件 协议兼容感兴趣的开发者参与到 datafusion-postgres 的开源实战中来。
总结
我们将 PostgreSQL 兼容性的能力封装成了可复用的库(pgwire 和 datafusion-postgres)。这不仅让 GreptimeDB 能够快速实现协议兼容,也意味着任何现代数据基础设施都可以利用这些库来适配 Postgres 协议,从而构建一个全新的“类 Postgres”生态。这何尝不是一种新时代的“Postgres”?
除了 GreptimeDB,pgwire 还被应用于多个项目,例如被 ClickHouse 收购的 PeerDB、为实时在线游戏设计的 SpacetimeDB、fly.io 的开源项目 corrosion 以及近期发布的 db9.ai 等。在 DataFusion 生态中,我们甚至可以结合 geoarrow 和 geodatafusion 来探索构建与 PostGIS 兼容的地理空间数据处理生态。
如果你也对构建这样一个新颖的、基于现代技术栈的数据访问生态感兴趣,欢迎加入相关项目的开发,或者直接使用这些工具来实现你的想法。
往期精彩文章:
 发表于 2026-4-12 00:38:48
|
查看: 203|
回复: 0
发表于 2026-4-12 00:38:48
|
查看: 203|
回复: 0
