前段时间收到一个关于 oracle_exporter 离线的告警。由于与DBA确认暂不影响业务,就先做了静默处理。最近终于抽出时间来处理这个告警,并在今天彻底解决了问题。
整个排查过程如下,希望能为遇到类似问题的朋友提供参考。
1. 查看监控大盘
收到告警后,首先登录 Grafana 查看对应的监控大盘。

从大盘中可以清晰看到,exporter 的进程数监控是断断续续的,初步判断是 exporter 进程本身出现了问题,而非网络或采集间隔导致。
2. 登录服务器排查日志
根据告警信息中的 exporter IP,登录到目标服务器进行排查。第一步是查看 oracle_exporter 的服务日志,发现其中存在大量 No space left on device 的报错信息。

看到“磁盘空间不足”的报错,本能反应是检查磁盘。于是立刻使用 df -h 和 df -i 分别查看了磁盘的可用空间和 inode 使用情况,但结果均显示正常。这就有点奇怪了,说明问题可能不是常规的磁盘或 inode 耗尽。
3. 分析系统日志
既然应用日志指向空间问题,但磁盘空间又正常,那就需要查看更底层的系统日志。果不其然,在系统日志(/var/log/messages 等)中发现了持续刷新的“Directory index full!”警告。

这个错误提示并不常见。简单查询后了解到,这是 EXT4 文件系统的一个特性:为了提高大目录的访问效率,EXT4 默认启用了目录索引功能(dir_index),使用 HTree(哈希树)结构来组织目录中的文件项。当一个目录下的文件数量多到让这个 HTree 索引结构无法再扩展时,就会出现 “Directory index full” 警告。

关键点:这不是磁盘空间不足,也不是 inode 耗尽,而是目录本身的索引结构达到了上限。这解释了我们之前看到的现象。
4. 定位问题磁盘与目录
从系统日志的报错信息中,可以看到触发警告的设备是 dm-2。接下来需要确认这个设备对应的挂载点是什么。
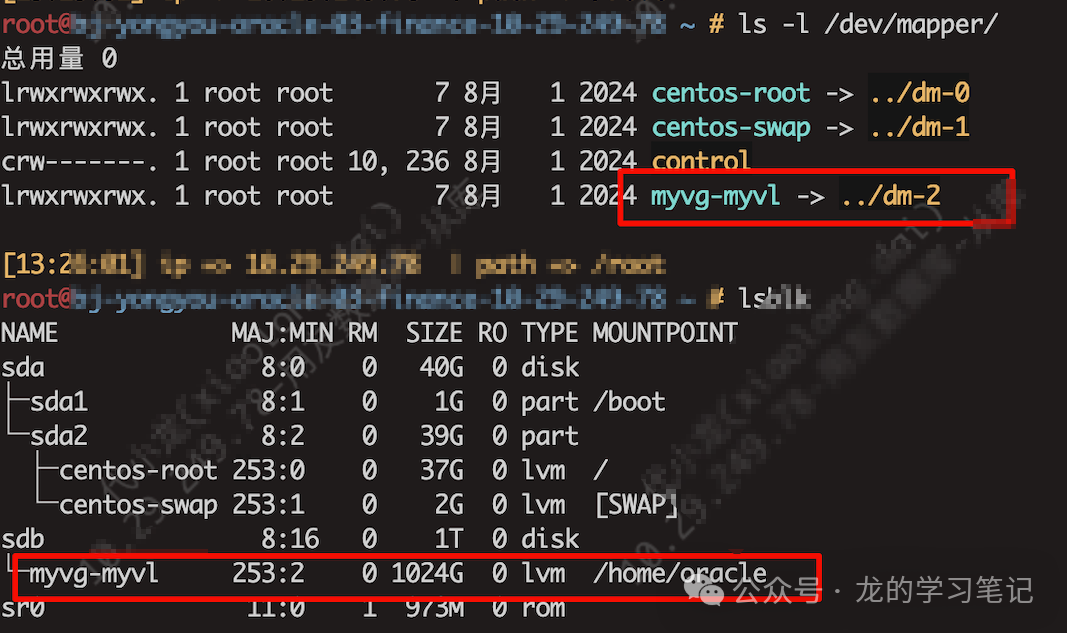
通过 ls -l /dev/mapper/ 和 lsblk 命令,可以确认 /dev/dm-2 设备映射的是 /home/oracle 这个逻辑卷。那么问题范围就缩小了:在 /home/oracle 目录树下,存在一个文件数量极其庞大的子目录。
5. 结合Oracle错误锁定具体目录
回过头来仔细看 oracle_exporter 的报错日志,发现其中包含了更具体的信息:Unable to create audit trail file。这是一个典型的 Oracle数据库错误,表示数据库无法创建审计日志文件。
那么,问题的根源很可能是Oracle审计日志所在的目录满了。其默认路径通常为:/home/oracle/app/oracle/admin/<数据库实例名>/adump。
6. 确认并清理问题目录
定位到可疑目录后,尝试使用 ls 命令查看,发现命令卡住,无法正常列出文件列表——这本身就是一个强烈的信号,说明目录内的文件数量可能超乎想象。
与负责的DBA老师确认后,得知该目录下的审计日志文件确实可以清理。DBA老师统计发现,该目录下竟然有1800多万个文件!持续对这些文件进行删除操作后,监控告警随即恢复正常。
7. 后续优化措施
问题解决后,为了防止再次发生,DBA老师增加了一个定时任务脚本,定期清理该审计目录下的过期文件,从源头避免了目录索引被撑满的情况。
总结一下:本次 oracle_exporter 离线的根本原因,并非服务器磁盘空间或 inode 不足,而是由于 Oracle 数据库某个审计目录下的文件数量过多,达到了 EXT4 文件系统目录索引(HTree)的上限,导致系统无法在该目录下创建新文件,进而使得 oracle_exporter 进程因写日志失败而异常。
这个问题本质上属于特定场景下的存储管理问题。在日常运维中,除了关注磁盘使用率,对于数据库、日志服务等可能产生大量小文件的场景,也需要关注目录本身的文件数量限制。更多关于数据库和中间件的运维实践,欢迎到 云栈社区 的数据库/中间件/技术栈板块交流讨论。
问题解决,可以安心下班了。
 发表于 2026-4-12 03:46:10
|
查看: 151|
回复: 0
发表于 2026-4-12 03:46:10
|
查看: 151|
回复: 0
