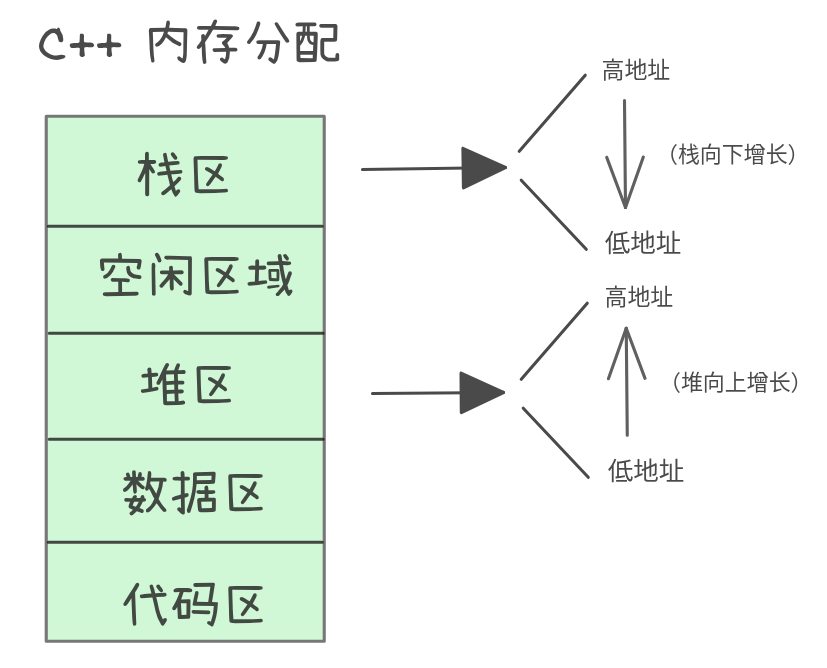
当我们谈论C++编程时,内存管理是无法绕开的基石。一个程序在运行时,其代码和数据会被有条理地安置在不同的内存区域中。这些区域从逻辑上做了划分,各自承担着特定的使命。通常,我们可以将它们大致分为以下几块:代码区、全局/静态存储区、栈区、堆区和常量区。理解它们的区别、用途与限制,是写出健壮高效C++代码的关键。
栈区(Stack)
存储内容
- 局部变量、函数参数、返回地址、临时值(寄存器溢出保存)等。对于多线程程序来说,栈区里的内容是线程的私有资源,你几乎没有办法直接访问另一个线程栈帧中的数据。
初始化与销毁时机
- 初始化:当函数被调用并为其栈帧分配空间时,局部变量按其定义方式(无初始值、默认初始化或显式初始化)被初始化。具有非平凡构造函数的局部对象在到达其定义处时构造。
- 销毁:函数返回或控制流离开变量的作用域时,局部对象按逆序(LIFO,后进先出)析构并释放其栈空间,整个过程是自动的。
注意事项
- 切勿返回指向栈上局部变量的指针或引用,否则将产生“悬挂引用”,访问这些指针是未定义行为。
- 栈空间是有限的(每个线程栈大小受限),应避免在栈上分配大型数据结构(如巨大的数组)。
- 过深的递归调用或过大的栈上数组都可能导致“栈溢出”(Stack Overflow)错误。
补充:栈大小的那些事
栈大小并没有一个全球统一的标准,它取决于操作系统、编译器、运行时环境、进程类型与平台。以下是一些常见环境下的典型默认值:
- Linux (x86_64, glibc):
- 主线程(进程)默认通常为 8 MB。
- 新创建的线程(通过pthread)默认栈通常为 2 MB(可由
pthread_attr_setstacksize 调整)。
- Windows (x86_64):
- 默认约为 1 MB(32-bit程序常见),64-bit可执行文件常见为 1 MB 或更高;可在链接时通过
/STACK 选项或在PE头中设置。
- macOS:
- 主线程通常为 8 MB;pthread默认栈也通常为 8 MB(具体版本与配置可能有差异)。
- 嵌入式/裸机环境:
- 由链接脚本或启动代码决定,可能只有几十KB到几百KB,甚至更小。
- 容器环境(Docker):
- 容器内默认继承宿主系统的线程栈限制(例如Linux的默认8MB),但受到ulimit、cgroups限制时可能有所不同。
如何查询与修改?
- Linux:查看主线程限制:
ulimit -s (单位KB);创建线程时可用 pthread_attr_getstacksize / pthread_attr_setstacksize 设置。
- Windows:使用链接器选项
/STACK 或在Visual Studio的项目属性中设置;也可使用 CreateThread 的参数指定栈大小。
- macOS:使用
pthread_attr_setstacksize 或在系统层面调整。
最佳实践
- 对于需要跨越当前作用域保存的数据,应该使用堆或静态存储,而不是栈。
- 充分利用自动对象的特性,采用 RAII(资源获取即初始化)原则来管理资源,依赖析构函数自动释放。
- 对于可能因递归深度过深或缓冲区过大导致栈溢出的场景,应考虑改用动态分配(堆)或迭代算法。
堆区(Heap / Free Store)
存储内容
- 动态分配的对象、动态数组、运行时大小未知的数据结构。堆区是进程内线程间共享的资源,任何线程都可以通过指针访问堆上的数据。
初始化与销毁时机
- 初始化:通过
new / new[](或 malloc 后接 placement new)分配并构造对象;现代C++更推荐使用智能指针或容器来封装分配过程。
- 销毁:必须显式调用
delete / delete[] 或 free(对应 malloc);如果使用了智能指针(如 std::unique_ptr/std::shared_ptr)或标准容器,资源会在最后一个所有者销毁时自动释放。
注意事项
- 避免内存泄漏:忘记释放已分配的内存。
- 避免双重释放:对同一块内存重复调用
delete 或 free。
- 注意异常安全:在分配资源后如果抛出异常,必须确保已分配的资源能被正确释放(这正是RAII的用武之地)。
- 避免使用悬挂指针:内存被释放后,不应再通过原有的指针访问它。
- 准确配对:
new 对应 delete,new[] 对应 delete[],不可混淆。
最佳实践
- 优先使用标准容器(如
std::vector、std::string)和智能指针,而不是直接使用裸的 new/delete。它们能极大地简化内存管理。
- 尽量限制动态分配的范围与生命周期,使用RAII对象进行封装。
- 在性能极其敏感的场景,可以考虑使用对象池或内存池,但需仔细衡量其带来的复杂性。
- 在多线程环境下,需确保堆分配的并发安全,或考虑使用带有线程局部缓存特性的分配器(如
tcmalloc、jemalloc)。
数据段(Data Segment)
存储内容
- 已初始化的全局/静态变量(
.data段)、未初始化的全局/静态变量(BSS段)、常量(只读段,如 .rodata)。
初始化与销毁时机
- 初始化:
- 静态初始化(零初始化或常量初始化)在程序加载或启动前完成(由编译器/运行时保证)。
- 动态初始化(需要运行时代码,如非
constexpr 的构造函数)在进入 main 函数之前完成。注意:不同编译单元(.cpp文件)之间的全局对象初始化顺序是未定义的(这就是著名的“静态初始化顺序问题”)。
- 销毁:程序退出时,按逆序(编译器/运行时定义的规则)调用全局/静态对象的析构函数(通常在
exit 或程序终止阶段)。
注意事项
- 避免依赖不同翻译单元(不同源文件)间静态对象的初始化顺序,否则可能导致使用未初始化的对象。
- 全局可变状态会增加代码的耦合度,使程序难以测试,并可能引发并发安全问题。
- 在库中定义非局部静态对象时,需要特别注意其生命周期与可见性。
最佳实践
代码段(Code Segment)
存储内容
- 程序的机器指令(全局函数、静态函数、类成员函数的实现)、只读常量字面值(通常也放在
.rodata,逻辑上接近代码段)。
初始化与销毁时机
- 初始化:代码段在程序加载时(或动态库加载时)由操作系统/加载器映射到内存;不存在“构造”过程。
- 销毁:程序结束或动态库卸载时由系统回收;代码本身不存在“析构”。
注意事项(针对各类函数)
- 普通/全局函数:存放在只读的代码段;注意函数指针的使用与跨模块(动态库)的可见性问题。
- 静态(文件作用域)函数:仅在其所在的翻译单元内可见,有助于避免命名冲突。
- 类内定义的函数(成员函数):
- 非虚成员函数:代码存放在代码段;每个对象不包含函数代码,只包含数据成员和
this指针。
- 虚函数:虚函数的实现代码仍在代码段,但对象会包含一个指向虚函数表(vtable)的指针(vptr)。虚表通常在只读数据段生成,并在加载时初始化。
- 内联函数:编译器可选择将其代码内联展开到调用处,也可能保留一个外部的可调用实体;内联和模板实例化会影响最终的代码体积和链接。
最佳实践
- 限制函数的可见性(使用
static、匿名命名空间或visibility属性),以减少符号冲突和潜在的安全攻击面。
- 对于频繁调用的短小函数,可以考虑使用
inline 关键字提示编译器,但实际是否内联由编译器优化决定。
- 对于类的非模板、非内联成员函数,应将实现放在
.cpp 文件中,以缩短编译时间并隐藏实现细节。
- 使用虚函数和多态要有性能意识(虚调用有一定开销);在必要时可以使用
final、模板或静态多态(如CRTP)作为替代方案。

下面的代码示例整合了上述各个内存区域的特性,并通过构造和析构的顺序来验证我们的理解:
#include <iostream>
#include <memory>
#include <vector>
struct A {
A(const char* n): name(n) { std::cout << "Construct " << name << "\n"; }
~A() { std::cout << "Destruct " << name << "\n"; }
const char* name;
};
// 全局(数据段)对象(初始化在 main 之前,销毁在程序退出时)
A globalA("globalA");
// 静态全局变量(file-scope static,作用域限于本翻译单元,存储在数据段)
static A staticGlobalA("staticGlobalA");
// 函数内按需静态(数据段/初始化顺序安全示例)
A& getSingleton() {
static A s("local static s"); // 第一次调用时构造,程序退出时销毁
return s;
}
void stackExample() {
A a("stack a"); // 进入作用域时构造,离开作用域时析构
{
A b("stack b"); // 嵌套作用域,离开时先析构 b 再 a
}
}
void heapExample() {
A* p = new A("heap p"); // new 时构造(堆)
delete p; // delete 时析构并释放
// 推荐:用智能指针管理
auto up = std::make_unique<A>("unique_ptr up"); // 离开作用域时自动析构并释放
}
class C {
public:
void member() { // 类成员函数的代码在代码段;调用才创建栈帧与局部变量
A m("member-local m");
}
static void staticMember() { // 静态成员函数也在代码段,可在没有实例下调用
A s("static member s");
}
virtual void vfunc() { // 虚函数:实现仍在代码段,对象含 vptr 指向虚表
A v("virtual v");
}
};
int main() {
std::cout << "main start\n";
stackExample(); // 构造 & 析构栈对象
heapExample(); // heap 分配与智能指针示例
getSingleton(); // 第一次调用构造 local static
C c;
c.member(); // 成员函数内部栈对象构造/析构
C::staticMember(); // 静态成员函数内部栈对象构造/析构
c.vfunc(); // 虚函数调用,局部对象构造/析构
std::cout << "main end\n";
return 0;
}
初始化与销毁顺序分析(典型行为)
- 程序加载/启动阶段(在进入
main 之前):
- 运行时(
main 执行过程中):
- 根据函数调用顺序,栈对象、堆对象、函数内静态对象、成员函数内的局部对象依次构造和析构。
- 程序退出阶段(返回到运行时/CRT清理):
注意事项
staticGlobalA(文件静态)和 globalA(全局)都具有静态存储期,都在程序启动前初始化,但可见性不同。- 函数内静态对象
s 在首次执行 getSingleton() 时才初始化(C++11起线程安全),其析构发生在程序终止阶段。
- 重要:跨翻译单元的静态初始化顺序是未定义的,这是“静态初始化顺序问题”的根源。使用上述的函数内静态(Meyers单例)是解决此问题的常用方法。
典型的完整输出顺序如下(假设单一翻译单元):
Construct globalA
Construct staticGlobalA
main start
Construct stack a
Construct stack b
Destruct stack b
Destruct stack a
Construct heap p
Destruct heap p
Construct unique_ptr up
Destruct unique_ptr up
Construct local static s
Construct member-local m
Destruct member-local m
Construct static member s
Destruct static member s
Construct virtual v
Destruct virtual v
main end
Destruct local static s
Destruct staticGlobalA
Destruct globalA
注意:不同平台、编译器以及链接器的具体行为可能略有差异,尤其是涉及多个源文件时。
总结
| 区域 |
核心特点 |
适用场景 |
注意事项与最佳实践 |
| 栈 (Stack) |
自动管理,速度快,生命周期与作用域绑定。 |
短期存在的小型对象、函数参数、局部变量。 |
注意栈溢出;切勿返回指向栈对象的指针/引用;善用RAII。 |
| 堆 (Heap) |
手动或通过RAII管理,灵活,生命周期由程序员控制。 |
运行时大小未知的数据、需要跨作用域存活的对象、大型对象。 |
严防内存泄漏与悬挂指针;优先使用智能指针和标准容器;考虑性能时可使用内存池。 |
| 数据段 (Data) |
静态存储期,程序启动前初始化,结束时销毁。 |
全局配置、单例、只读常量。 |
警惕“静态初始化顺序问题”;最小化全局可变状态;使用函数内静态保证安全初始化。 |
| 代码段 (Code) |
只读,存放程序指令和部分常量。 |
所有函数实现。 |
关注函数可见性;合理使用inline;理解虚函数机制的开销。 |
掌握这四块内存区域,就如同掌握了C++程序世界的“地图”。希望这篇指南能帮助你更清晰、更自信地进行C++内存管理与编程。如果你对更多底层细节或现代C++特性感兴趣,欢迎到云栈社区的C++板块继续深入交流与学习。 |  发表于 2026-4-12 03:48:53
|
查看: 196|
回复: 0
发表于 2026-4-12 03:48:53
|
查看: 196|
回复: 0
