最近,一篇关于 DreamX 团队 SkillClaw 框架的论文在 HuggingFace 上快速获得了超过 200 次投票。这引发了许多开发者的兴趣,因为它触及了一个常见的痛点:在许多智能体系统中,预定义的技能文件一旦部署,就变成了静态代码。即使不同用户反复遭遇同样的失败,系统自身也“学不会”,问题得不到根本解决。
这正是 DreamX 团队试图通过 SkillClaw 框架来改变的,其切入角度颇为巧妙。
问题的根源:孤立的经验
当前,改进智能体技能的常见思路无外乎两种:要么记录历史轨迹,要么将经验总结成技能文档。然而,这两种改进都局限于单个用户的环境。这意味着,一个用户通过反复试错学到的东西,无法自动分享给其他用户;而其他人踩过的坑,新用户也只能自己再踩一遍。
想象一下,八个用户同时使用同一套存在缺陷的技能,他们都会失败,然后各自尝试各自的临时解决方案,而技能库本身却纹丝不动。此外,单用户的失败信号存在一个硬伤:很难判断一次失败究竟是技能本身有缺陷,还是仅仅遇到了一个极其特殊的边缘案例。只有聚合来自不同用户、不同场景的数据,才有可能将共性问题与个案分离开来。
SkillClaw 的核心机制:将多用户交互转化为共享证据
SkillClaw 的基本思路源于一个自然的观察:不同用户使用同一个技能,但执行不同的任务、处于不同的环境——这本身就构成了一组天然的“对照实验”。
当用户A成功、用户B失败、用户C在第三步卡住时,将这三条信息放在一起,就能精准定位“这个技能在什么条件下有效,在什么条件下会出问题”。这是单用户视角永远无法看到的全局图景。
图:SkillClaw 整体架构——多用户交互数据聚合为共享证据,Agentic Evolver 定期分析并更新技能库,更新后的技能同步给所有用户。
1. 结构化数据收集
每次用户与智能体的交互,SkillClaw 都会记录一条完整的“执行轨迹”,包含:用户请求 → 智能体动作(含所有工具调用细节)→ 中间反馈(工具结果、报错信息)→ 最终回应。
仅仅记录“最终失败”是不够的。大多数技能层面的问题,比如调用了错误的 API 端口、输出路径格式不对、遗漏了某个验证步骤,都隐藏在中间步骤的因果链中。这些完整的轨迹是后续分析的原材料。
收集到的数据会按被调用的技能进行分组:G(s) 代表所有调用过技能 s 的会话集合。那些没有调用任何现有技能的会话则被归入 G(∅) 组,这有助于发现“应该有但还没有”的新技能机会。
2. 基于证据的 Agentic Evolver
这是整个框架的核心,它是一个 LLM 智能体,负责阅读某个技能的所有交互证据,并决定采取以下三种行动之一:
- 优化(Refine):技能本身存在可改进的问题,进行修改。
- 创建(Create):证据中出现了可复用的、有效的流程模式,但现有技能库未覆盖,因此创建新技能。
- 跳过(Skip):证据不足或无需修改,保持现状。
设计的关键在于,成功案例定义了技能的“不变量”——即哪些部分有效且必须保留;失败案例则定义了“修正目标”。这确保了在修复一个问题时,不会意外破坏原有能正常工作的部分。
3. 安全的夜间验证
生成的候选技能更新不会直接上线。系统会在每晚利用当天的真实交互数据作为测试集,让候选技能与当前的最佳技能在模拟环境中同台竞技,比较执行结果。只有被验证为更优的更新才会被接受并部署;否则将被拒绝并归档。
这意味着用户始终使用的是“昨晚验证过的最佳版本”,而非效果未知的实验版本。这一机制保证了技能库的质量是单调不下降的。
实验结果:最高88%的成功率提升
研究团队在 WildClawBench(包含 60 个复杂智能体任务,覆盖 6 个领域)上进行了模拟实验,设置 8 个并发用户,持续运行 6 天,全程由 Qwen3-Max 驱动。
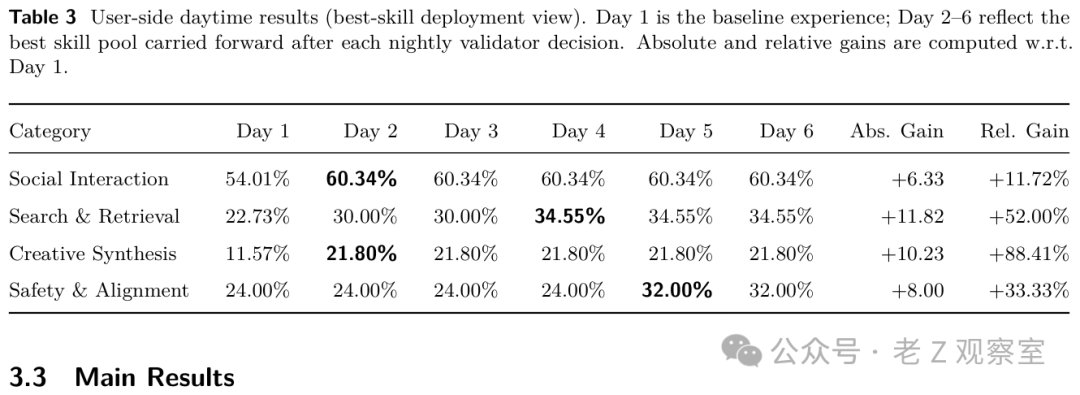
表:6 天进化轨迹——Day 1 是基线,Day 2-6 反映每晚验证后部署的最佳技能池成绩。
经过 6 天的自动进化,各领域技能成功率提升显著:
- 社交互动:从 54% 提升至 60%(相对提升 +11.7%)。
- 搜索与检索:从 23% 提升至 35%(相对提升 +52%)。
- 创意合成:从 12% 提升至 22%(相对提升 +88%)。
- 安全对齐:从 24% 提升至 32%(相对提升 +33%)。
提升幅度的差异背后有清晰的逻辑。例如,社交互动技能在第二天就跃升至60%并保持稳定,说明其核心瓶颈(某个工作流步骤不明确)在第一轮进化中就被快速修复。而搜索与检索技能的提升则是分阶段的,先解决了基础的文件路径问题,后续才引入了更高级的检索规划策略。
在受控验证中(针对“保存报告”等三个定制任务),技能进化带来的提升更为惊人,“保存报告”任务的成功率直接从 28% 跃升至 100%。这类任务的失败大多源于程序性的错误,如输出路径格式问题,一旦被编码进技能文件,问题便彻底根除。
案例研究:Slack消息分析任务的进化
一个具体的案例能更清晰地展示进化的价值。

图:Slack 消息分析任务的技能进化对比——左边是原始技能执行轨迹(失败),右边是进化后技能(成功)。
原始技能采用“拉取所有消息 -> 试错分析”的简单工作流。一旦遇到 API 端口配置错误(如误用 9100 端口),整个流程就会卡住,依赖智能体在运行时进行试错重试,效率低下且不稳定。
进化后的技能基于真实失败证据做出了三项关键改进:
- 选择性检索:先扫描消息预览,识别出可能包含待办事项的消息,再针对性拉取完整内容,减少无效调用。
- 错误前置修正:将已发现的 API 端口错误(9100 → 9110)直接写入技能文件,避免运行时才暴露问题。
- 流程固化:明确指定输出文件路径,不再让智能体临时决定。
这些改进全部来源于真实用户交互中暴露出的问题,而非工程师的主观设计。
启示与思考
SkillClaw 框架提供了一个富有启发性的视角:多用户的正常交互数据,本身就是一个高质量、免费的标注集。它巧妙地绕过了为训练“故障诊断模型”而进行大规模人工标注的成本。随着用户规模的扩大,这种基于集体经验的 技能进化 机制的优势会越发明显。
当然,目前的研究仍处于早期阶段。实验规模较小(8用户/6天),在大规模部署时,技能是否会因被高频场景过度优化而损害低频场景的体验,其收敛性有待验证。此外,夜间验证机制依赖日间数据量,对于调用频率极低的技能,可能因缺乏足够的测试样本而难以进化。
尽管如此,将技能进化从“单用户本地学习”提升到“多用户共享积累”的思路,无疑是推动智能体系统走向真正自适应和持续学习的重要一步。对于关注 Agent 技术发展的开发者和研究者而言,这是一个值得深入探讨的方向。
相关资源:
 发表于 2026-4-13 02:36:24
|
查看: 230|
回复: 0
发表于 2026-4-13 02:36:24
|
查看: 230|
回复: 0
