过去,想要体验大模型通常只有两条路:要么调用云端API,要么在本地复杂部署。前者需要管理密钥、计算成本,并时刻担忧数据隐私;后者则要配置Python环境、折腾显卡驱动,对于前端开发者来说,门槛着实不低。
不过,最近在GitHub上出现了一个让人眼前一亮的项目:kessler/gemma-gem。
这本质上是一个Chrome浏览器扩展,它的核心能力是将谷歌最新发布的Gemma 4大语言模型直接“装进”你的浏览器中,并利用WebGPU技术在本地设备上全速运行。整个过程无需API密钥,无需连接云端,所有数据都将在你的设备内部处理,彻底解决了隐私和成本的顾虑。
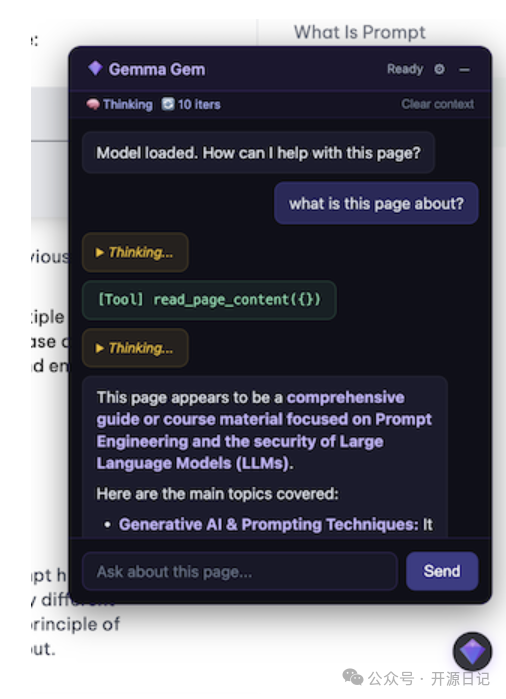
更关键的是,它不仅仅是一个简单的聊天机器人。项目为模型内置了六个强大的浏览器操作工具,使其能够真正“阅读”并“操作”你正在浏览的网页。
你可以这样理解它:一个完全在本地运行的AI助手,既能与你对话,也能替你操作眼前的网页。
目前该项目在GitHub上获得了超过600颗星,虽然数字不算惊人,但其技术路线和应用潜力值得开发者们关注。
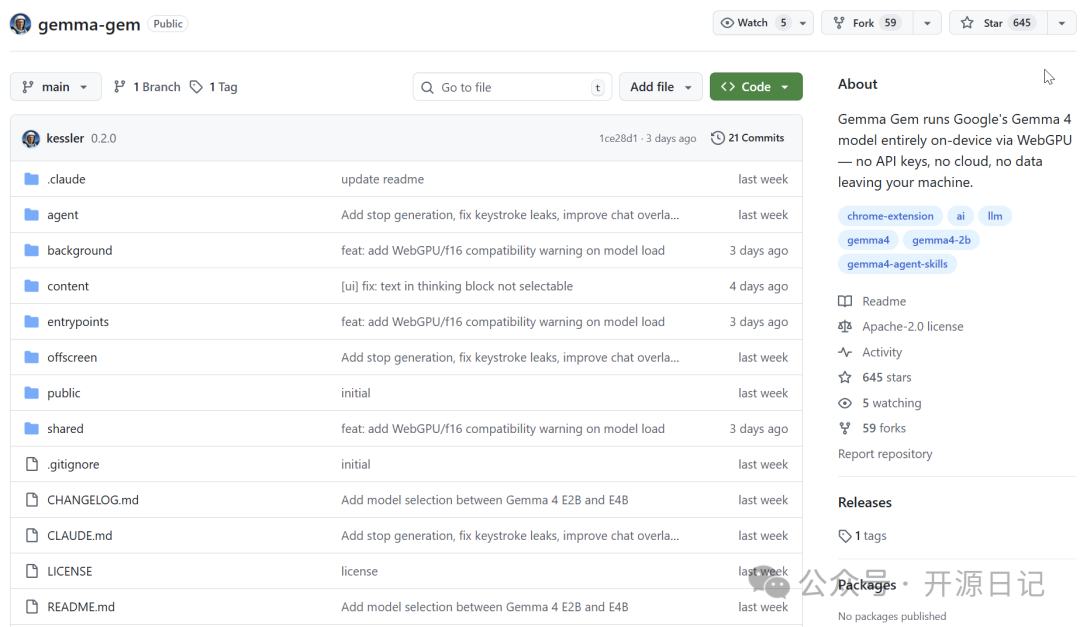
项目的开发者Yaniv Kessler是Unity的一名员工。在谷歌于4月2日发布Gemma 4模型后,他仅用一周时间就实现了这个创意。在过去,想在浏览器里流畅运行一个十亿参数级别的大模型几乎是天方夜谭。
而Gemma 4正是谷歌为边缘设备(Edge Devices)专门优化的模型系列。其中,E2B版本仅有23亿参数,量化后体积约500MB;稍大的E4B版本体积约1.5GB。配合现代浏览器对WebGPU的硬件加速支持,我们第一次得以在浏览器中以接近原生的速度运行此类模型。

这并非一个简单的技术演示,它具备实际可用性。模型只需在首次使用时下载并缓存到本地,之后便可完全离线运行。 这意味着没有API调用费用,没有配额和速率限制。在处理公司内部文档、个人笔记或其他敏感数据时,这一特性显得尤为友好——所有计算都在你的机器上完成,数据不会离开你的设备半步。
核心功能:不只是聊天,更是浏览器操作助手
项目为AI模型集成了六个实用的浏览器自动化工具:
- 读取页面内容:提取当前页面的文本、链接和结构化数据。
- 页面截图:捕获网站的全页或特定区域截图。
- 点击指定元素:通过选择器模拟对特定按钮、链接或元素的点击。
- 在输入框输入文本:自动在搜索框、表单等输入字段中填入指定文本。
- 滚动页面:垂直滚动浏览长页面以查看更多内容。
- 执行JavaScript:运行自定义脚本以操作DOM、触发事件或提取数据。

使用起来非常直观自然。你可以直接对它说:“这个页面主要讲了什么?” 模型会自动调用“读取页面内容”工具,分析后给你总结。你还可以命令它:“帮我在顶部的搜索框里输入‘WebGPU教程’。” 它便会定位到输入框并完成填写。整个过程就像有一个懂得网页结构的智能副驾在帮你操作。
此外,Gemma 4模型原生支持“思维链”(Chain of Thought)推理模式,该项目已完整集成这一特性。 在每次回答前,你可以看到模型详细的思考过程,了解它是如何拆解任务、分析页面状态并决定调用哪个工具的,透明度很高。
项目在v0.2.0版本中还新增了E2B和E4B模型自由切换的功能。E2B模式轻量快速,适合简单任务;E4B模式则推理能力更强,适合处理复杂的多步操作。切换结果会被保存,下次启动扩展时会沿用之前的设置。
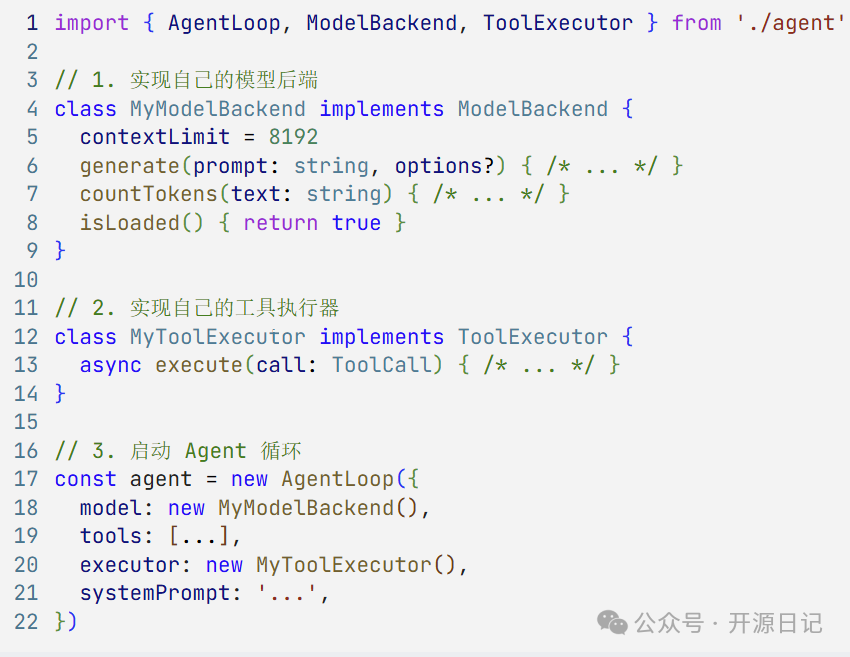
高度模块化的设计,便于二次开发
该项目的Agent(智能体)核心循环逻辑被清晰地抽离在 agent/ 目录中,并且做到了零外部依赖。它明确定义了 ModelBackend 和 ToolExecutor 接口。这意味着,如果你希望在自己的项目中复用这套成熟的AI与工具交互的架构,可以直接将整个 agent/ 目录拿走,稍作适配即可集成,扩展性很强。
如何安装与使用?
安装过程并不复杂,主要分为三步:克隆项目、安装依赖并构建、将构建产物加载到浏览器中。
请注意,你需要提前在电脑上安装好 git、Node.js、npm 以及 pnpm。
1. 克隆项目
打开终端,执行以下命令将项目代码拉取到本地:
git clone https://github.com/kessler/gemma-gem.git
2. 安装依赖并构建
进入项目目录,安装所有依赖包(这可能需要一两分钟):
cd gemma-gem
pnpm install
依赖安装成功后,执行构建命令:
pnpm build
构建完成后,项目根目录下会生成一个 .output/chrome-mv3-dev/ 文件夹,这就是我们接下来要加载的浏览器扩展。
3. 加载到Chrome浏览器
- 打开Chrome浏览器,在地址栏输入
chrome://extensions 并访问。
- 打开页面右上角的 “开发者模式” 开关。
- 点击页面左上角的 “加载已解压的扩展程序” 按钮。
- 在弹出的文件选择器中,定位并选中刚才生成的
.output/chrome-mv3-dev/ 文件夹。
完成以上步骤后,扩展就安装成功了。
开始使用
现在,随意打开任何一个网页,你会发现在浏览器窗口的右下角出现一个宝石状的图标。点击它,会弹出一个聊天窗口。首次使用时,它会提示你下载模型文件(E2B版本约500MB)。
下载完成后(后续使用会直接读取缓存),你就可以与这个本地AI助手对话了。尝试问它“这个页面讲了什么?”,或者给它更具体的指令,如“帮我点击页面上的‘同意’按钮”。
已知限制与适用场景
当然,我们需要客观地看待其能力边界。
- 模型能力:E2B是一个23亿参数的小模型,复杂推理和多步骤任务规划能力有限。开发者本人在Hacker News上也坦诚表示,处理简单页面问题和执行JavaScript没问题,但复杂的多工具链协作有时会失败,模型偶尔也会忽略工具指令直接给出回答。
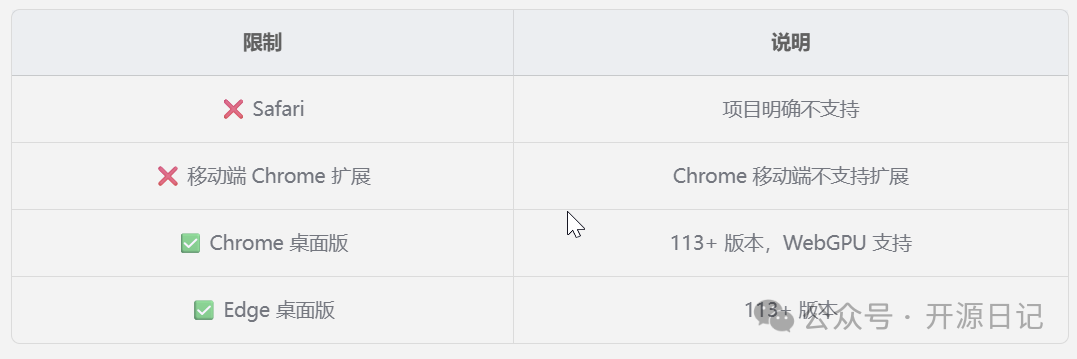
- 环境要求:其核心依赖于WebGPU,这要求你的设备(特别是显卡)和浏览器版本较新(Chrome 113+或Edge 113+)。Safari浏览器明确不支持,移动端的Chrome也不支持扩展安装。
那么,谁最适合使用它呢?
- 隐私敏感型用户:处理内部文档、机密信息时,要求数据绝对不出本地。
- 想零成本尝鲜的开发者:希望低成本体验本地大模型和AI智能体工作流,又不想搭建复杂环境。
- 有轻度网页自动化需求的人:需要完成一些简单的、重复性的网页操作任务。
如果你追求的是极致的对话体验和强大的复杂任务处理能力,云端大模型仍是更好的选择。但如果你高度重视数据隐私、希望零成本使用、且需要离线可用的AI助手来辅助网页浏览与操作,那么 gemma-gem 这个开源项目绝对值得你花时间试一试。对于关注Transformer模型在边缘端应用的开发者来说,这也是一个极佳的学习范本。你可以在云栈社区的人工智能板块找到更多类似的开源项目讨论与实战分享。
 发表于 2026-4-13 04:33:26
|
查看: 193|
回复: 0
发表于 2026-4-13 04:33:26
|
查看: 193|
回复: 0
