面试官:来说说什么是 RAG?详细描述一下一个完整 RAG 系统的工作流程。
求职者:RAG 我知道,就是一个搜索 API,用户输入关键词,去数据库里把匹配的文档捞出来返回给用户,就这样。
面试官:……你这是 Elasticsearch 吧?RAG 里的「G」是 Generation,生成呢?LLM 在哪?你把最核心的环节整个漏掉了。
求职者:哦哦,我重新说。RAG 就是把公司文档丢给大模型,让它自己学进去,下次用户问问题它就能直接答了。
面试官:你这说的是微调(Fine-tuning),不是 RAG。RAG 根本不会去改模型的参数,你是怎么把这两个完全不同的东西搞混的?
上述面试场景中的错误理解,在技术交流中并不少见。下面,我们将对 RAG 进行一次系统性解析,厘清其核心思想与完整的工作流程。
什么是 RAG?它解决了什么问题?
RAG 全称为 Retrieval-Augmented Generation,即检索增强生成。它旨在解决大语言模型(LLM)的一个核心困境:知识“冻结”。
一个 LLM 在完成预训练后,其知识库便相对静态,无法获取训练截止日期后的新信息,更无从知晓企业内部的私有数据。这就像一个人高考后不再阅读新闻,自然无法回答今天的股价。
那么,能否通过微调来更新模型知识呢?理论上可行,但成本高、周期长,且每次知识更新都需重新训练,如同为记住一条新闻而重读一遍大学,效率极低。
RAG 选择了另一条路径:不将知识写入模型参数,而是在需要时实时检索。当用户提问时,系统先从外部知识库中查找相关内容,然后将检索结果作为上下文与问题一同交给 LLM,让它基于这些“参考资料”生成答案。简言之,RAG 为 LLM 开启了一场“开卷考试”。
一个完整的 RAG 系统清晰分为 离线构建 与 在线检索 两个阶段。
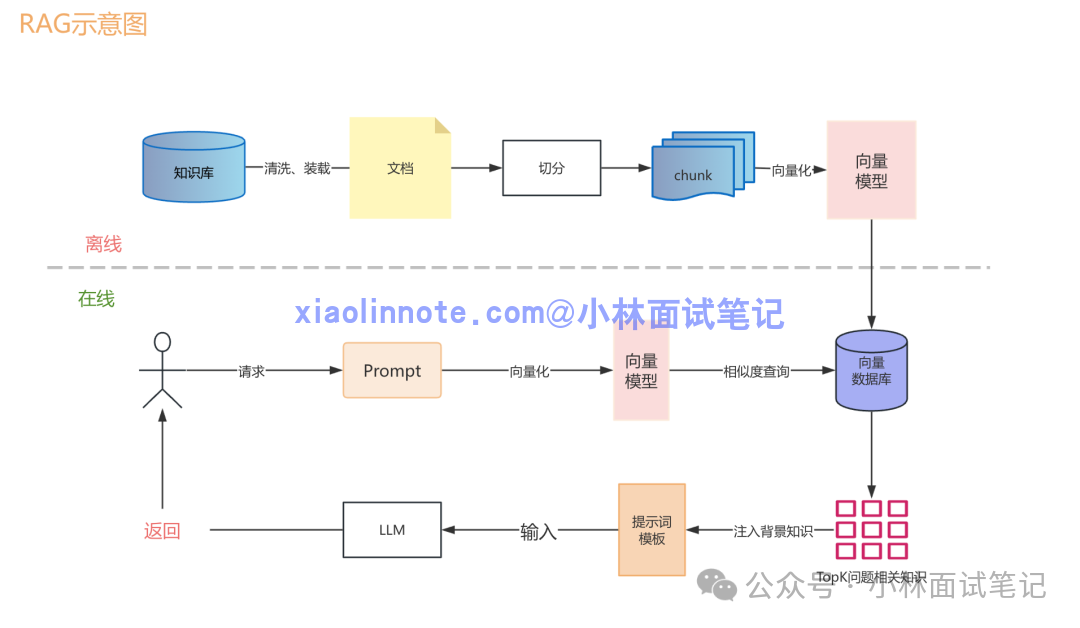
离线阶段:知识库的构建与准备
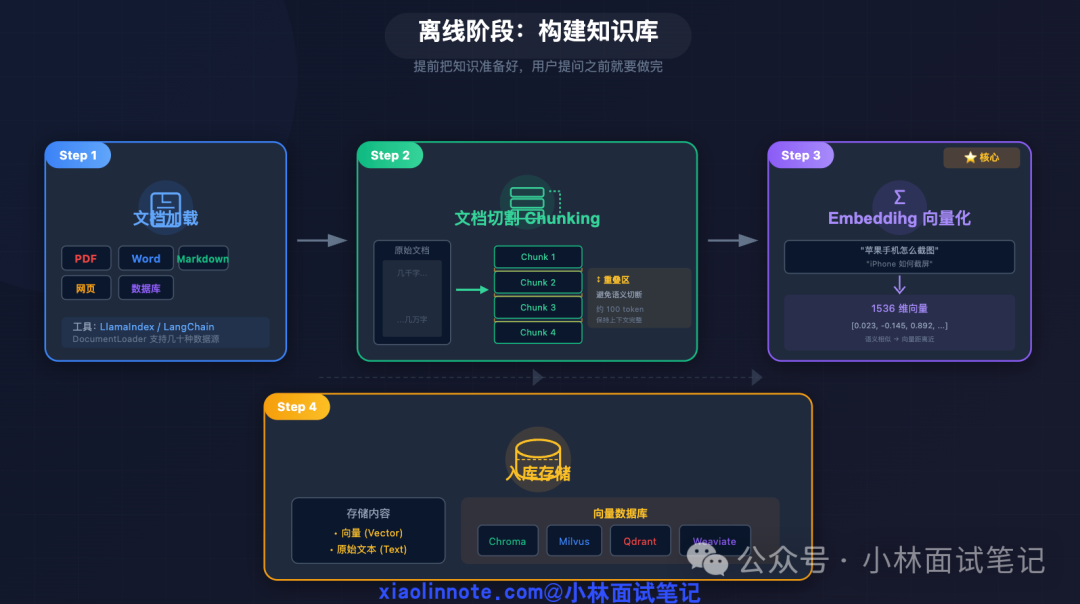
此阶段的目标是在用户提问前,预先将知识库搭建完毕,通常只执行一次。其流程可以概括为四个步骤。
-
文档加载
将各种格式的原始数据(如 PDF、Word、Markdown、网页、数据库记录)读取并转化为结构化文本。常用工具如 LlamaIndex 或 LangChain 的 DocumentLoader,支持数十种数据源。
-
文档切割
为何不直接存储整篇文档?主要原因有二:一是向量模型有输入长度限制(通常数百至数千 token);二是将长文档压缩为单一向量会导致细节信息丢失。因此,需要将文档切分为语义聚焦的小片段,称为 Chunk。
Chunk 的大小需平衡:太大则信息混杂,检索精度下降;太小则语义不完整。实践中,每个 Chunk 通常控制在 500~1000 个 token,并在 Chunk 间设置重叠区(如前/后重叠 100 token),以避免从语义中间切断。
-
向量化
这是离线阶段的核心。Embedding 模型将一段文本转换为一个高维向量(例如 1536 维的浮点数列表)。你可以将其理解为一个“语义坐标系”:语义相近的文本,其向量在空间中的位置也接近。例如,“苹果手机怎么截图”与“iPhone 如何截屏”的向量会非常靠近。这一步将抽象的“语义”编码为可计算的数学表示,是实现语义检索而非关键词匹配的基础。
-
入库存储
将每个 Chunk 对应的向量及其原始文本,一并存入专门的向量数据库。这类数据库(如 Chroma、Milvus、Qdrant、Weaviate)针对高维向量的相似度搜索进行了深度优化,能够在百万甚至千万量级的向量中实现毫秒级检索。
至此,一个可供快速查询的向量化知识库便构建完成。
在线阶段:实时响应用户查询
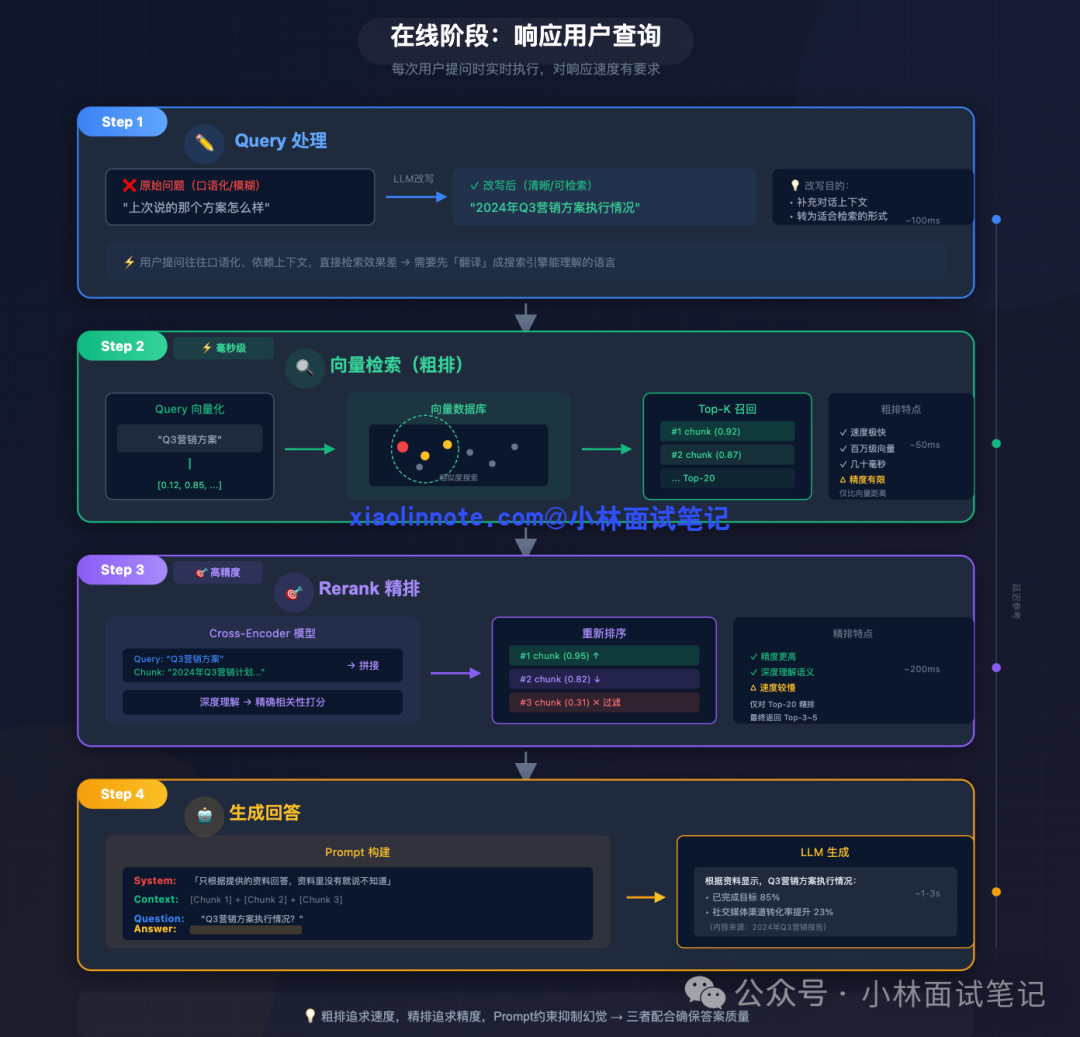
每当用户提出问题时,系统实时执行此阶段流程,对响应延迟有较高要求。
-
查询处理
用户的问题往往是口语化或模糊的(如“上次说的那个方案怎么样?”)。直接检索效果不佳,因此常需先进行 Query 改写。利用 LLM 将原始问题转化为更清晰、更适合检索的形式,或从对话历史中补充缺失的上下文。
-
向量检索
将处理后的查询进行向量化,并在向量数据库中进行相似度搜索,召回与查询向量最接近的 Top-K 个 Chunk。此步骤速度极快(通常几十毫秒),可应对海量数据,因此常被称为“粗排”。但其局限性在于仅比较向量距离,缺乏对查询与文档之间深层语义关联的理解。
-
重排序
为弥补粗排的精度不足,可引入 Rerank(精排)环节。Rerank 模型(如 Cross-Encoder)会将查询与每个候选 Chunk 拼接,深度理解其相关性并重新打分排序,过滤掉不相关的结果。精排精度更高但速度较慢,因此通常只对粗排返回的 Top-20 结果进行精排,最终筛选出 Top-3 至 Top-5 个最相关的 Chunk。
-
生成答案
将用户问题与精排后的相关 Chunk 内容,按照预设模板构建成最终的 Prompt,提交给 LLM 生成答案。Prompt 中通常会加入明确指令,如“仅根据提供的资料回答,资料中没有的信息请回答‘不知道’”,以此有效约束 LLM,减少“幻觉”的产生。
核心价值与总结
将离线和在线阶段串联,便是 RAG 的完整工作流:离线建库,在线检索并生成。其核心价值突出体现在两点:
- 知识可热更新:只需向知识库添加新文档并重新向量化,即可更新系统知识,无需重新训练模型,成本低、效率高。
- 答案可溯源:每一条回答都能追溯到其依据的具体 Chunk 原文,增强了系统的可解释性与可信度。
回到开头的面试问题,一个合格的回答应涵盖:RAG 解决 LLM 知识静态化的问题;阐明其与微调的本质区别(参数更新 vs. 外部检索);并清晰地分阶段描述离线(文档加载→切割→向量化→入库)与在线(查询处理→向量检索→重排序→生成)的完整流程。
希望本文能帮助你透彻理解 RAG。如果你想深入了解其他人工智能技术或向量数据库的选型,或者有更多关于面试求职的问题,欢迎到云栈社区与更多开发者交流探讨。 |  发表于 2026-4-13 07:01:37
|
查看: 170|
回复: 0
发表于 2026-4-13 07:01:37
|
查看: 170|
回复: 0
