好的软件架构,往往不是一开始就被完整设计出来的,而是在需求变化、系统扩展与约束调整中逐步演化出来的。
Martin Fowler - 现代软件工程实践的奠基人之一
就像传统软件架构会随着业务复杂度逐渐演化一样,过度设计是负担,过度优化也被视为问题之源。构建智能体应用时所依赖的 Agent Harness 也遵循这一规律,它并非一次设计成型,而是在人工智能模型能力持续变化的过程中,被不断修剪、重组和重新分工的产物。
本篇内容主要基于 Anthropic 公司的技术博客《Harnessing Claude's Intelligence》。这是 Claude 团队关于 Harness 设计的第二篇分享(上一篇探讨如何设计 Harness,本篇则侧重如何设计“好”的 Harness)。软件工程始终面临变化的挑战,需求、基础设施和技术栈都在变。但不变的是,工程系统始终要解决几类核心问题:如何管理复杂性、如何在约束下权衡、如何定义清晰边界、如何控制风险并建立反馈。
同理,随着 Claude 模型能力提升,原本由外层系统承担的编排、上下文与记忆职责,正逐步交还给模型侧;与此同时,围绕成本、用户体验、安全和可观测性的工程边界,却依然稳固。

一、先看“变”:随着 Claude 变强,职责正在从 harness 回到模型
原文的第一个建议,其实已经预示了这种变化:尽量使用 Claude 已经理解得很好的工具来构建应用,而不要过早为每一种智能体能力设计新的专用抽象。
Anthropic 给出的例子很有启发性。2024 年底,Claude 3.5 Sonnet 仅凭一个 bash 工具和一个用于查看、创建、编辑文件的文本编辑器工具,就在 SWE-bench Verified 上达到了 49%,在当时已是业界最佳水平。Claude Code 也建立在这组工具之上。
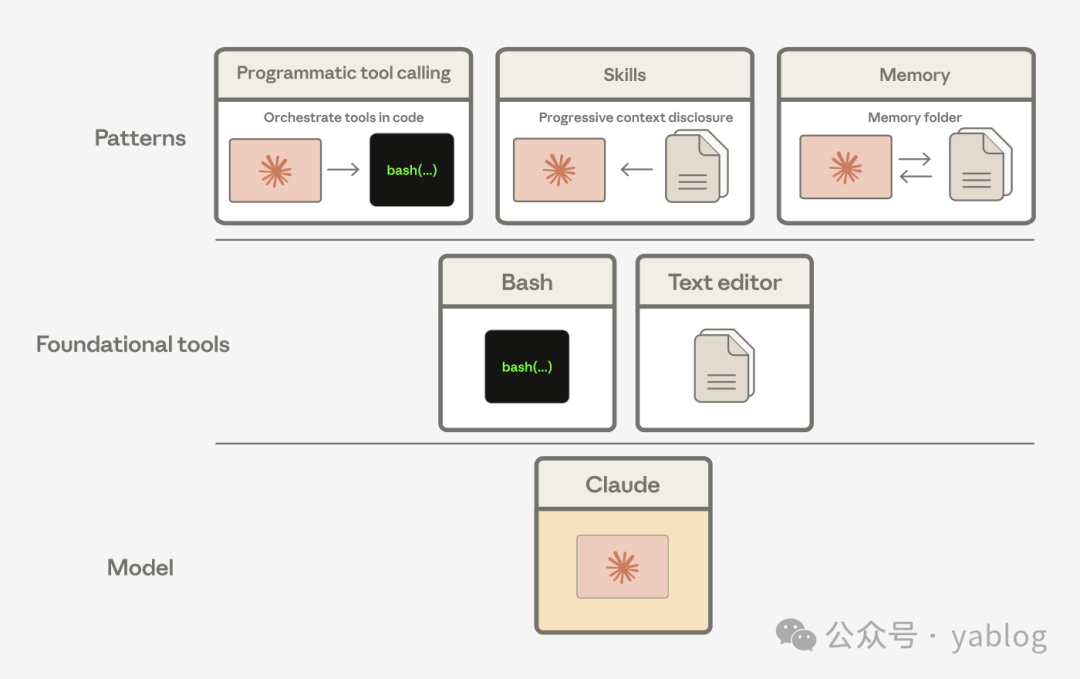
这说明,bash 虽然不是专为构建智能体而设计,却已成为 Claude 熟悉且会持续提升使用的环境。原文进一步指出,Agent Skills、programmatic tool calling 与 memory tool,本质上都可以看作是:基于 bash 与文本编辑器工具组合出来的模式。变化的起点并非发明更多外层 harness 结构,而是先用好模型已经擅长的通用工具。
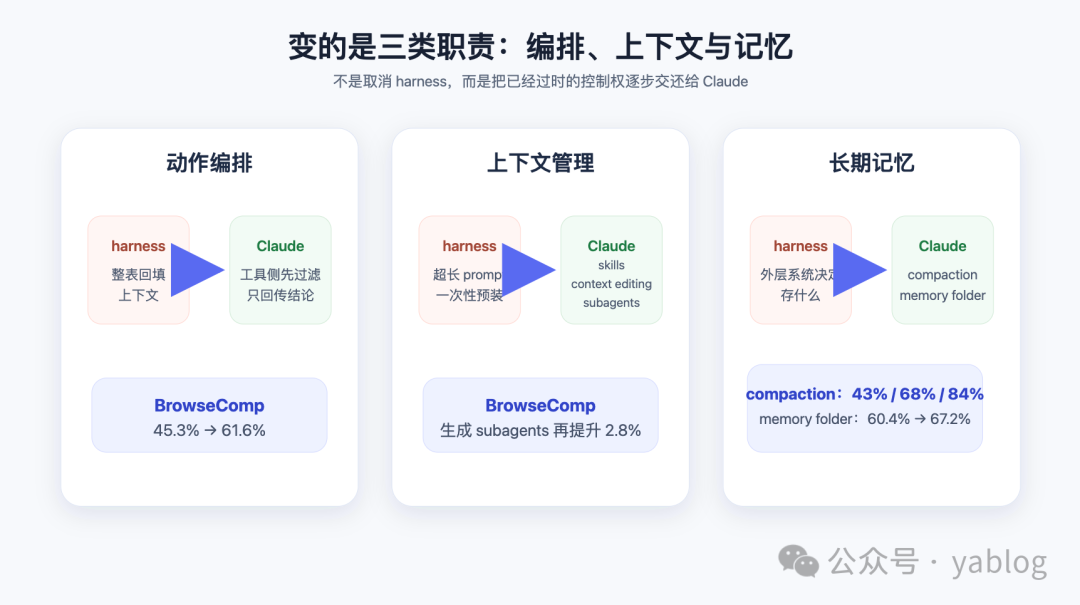
1. 动作编排在变:编排决策从 Harness 回到 LLM
原文第二部分首先讨论编排方式的变化。许多系统默认每一次工具调用的结果都应重新流回上下文窗口,再由模型决定下一步。这种做法直觉上自然,但在大输出场景下会带来延迟与成本问题。
例如,如果 Claude 只需要分析一张大表中的某一列,却必须把整张表都送回上下文,那么它将为大量不需要的信息付出 token 成本。当然可以在工具层加入硬编码过滤器,但更本质的问题在于,此时由 harness 代替模型做出了编排决策——我们需要把决策权还给模型,尤其是当模型有能力决策的时候。
Anthropic 的做法是提供 code execution tool,例如 bash 或某种语言专用的 REPL。这样,Claude 可以自行编写代码来表达工具调用之间的逻辑关系:哪些结果需要透传,哪些需要过滤,哪些可以通过管道传递给下一次调用。最终,只有真正需要的代码执行输出进入上下文窗口。
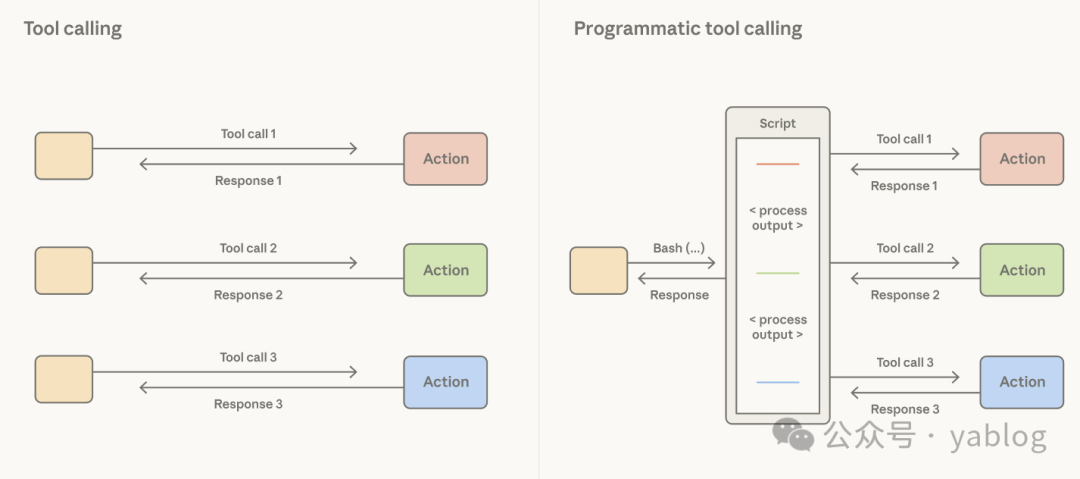
这相当于将编排决策从 harness 回归到模型本身。原文给出的数据显示,在测试智能体网页浏览能力的 BrowseComp 上,让 Opus 4.6 能够过滤自己的工具输出后,准确率从 45.3% 提升到了 61.6%。
2. 上下文管理在变:从全量静态预装转向按需加载与动态裁剪
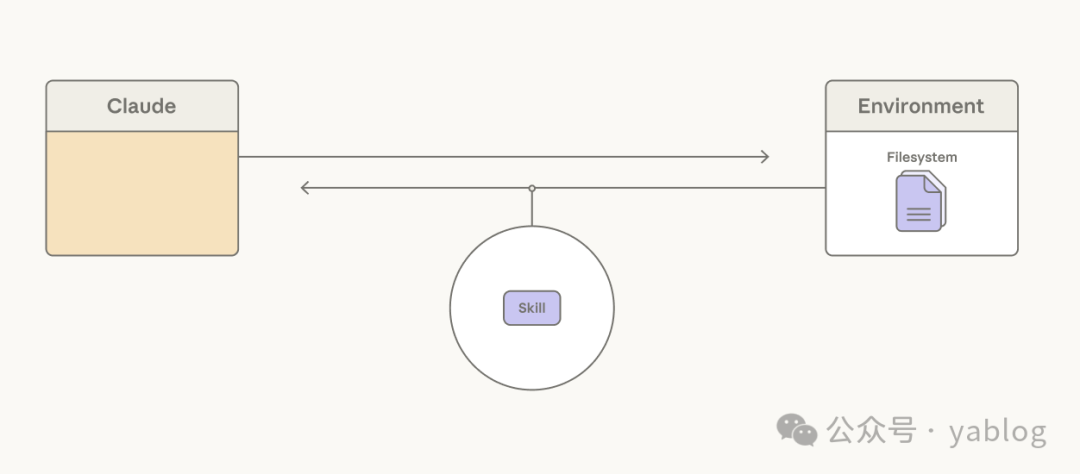
第二个变化体现在上下文管理上。常见做法是让系统提示词预先包含大量任务专属说明,但这种方式扩展性有限:每增加一个 token 都会占用模型的注意力预算,低频使用的信息被长期预装也是一种浪费。
于是,下面三种更轻量的机制出现了:
- skills:通过 YAML frontmatter 先提供简短概览,仅在任务确实需要时再展开完整内容;
- context editing:选择性移除已经过时或不再相关的上下文,例如旧的工具结果或 thinking blocks;
- subagents:在任务适合分支处理时,分叉出新的上下文窗口来隔离具体工作。
这些机制的共同点是不再把上下文视为一次性填满的静态容器,而是将其视为可按需装配、裁剪和分流的工作系统。原文数据也显示,在 Opus 4.6 上,生成 subagents 的能力让 BrowseComp 的结果比最佳单智能体运行又提高了 2.8%。
3. 记忆方式在变:从 Harness 决定“存什么”转向 LLM 判断“什么值得记住”
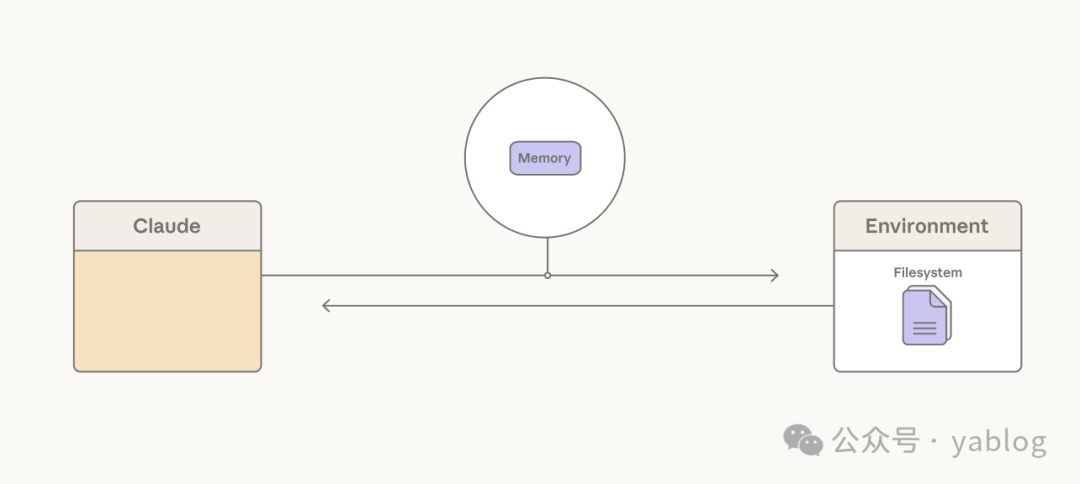
对长时间运行的智能体而言,单个上下文窗口总会遇到上限。常见的工程假设是,记忆系统必须依赖模型外围的一整套检索基础设施。Anthropic 的思路则更偏向于:先给 Claude 提供简单、稳定的持久化手段,再让模型决定什么值得保留。
原文重点提到两种方式:compaction 与 memory folder。
- compaction 允许 Claude 总结此前上下文,以维持长周期任务中的连续性。文章给出的对比显示,在 BrowseComp 这类 agentic search 任务上,无论给 Sonnet 4.5 多大的压缩预算,结果都基本停留在 43%;而在相同设置下,Opus 4.5 可以扩展到 68%,Opus 4.6 则达到 84%。这说明上下文压缩是否有效,不仅与机制本身有关,也取决于模型是否更擅长判断应该保留什么。
- memory folder 则提供了另一种路径:Claude 可以将内容写入文件,并在之后需要时重新读取。在 BrowseComp-Plus 上,为 Sonnet 4.5 增加一个 memory folder 后,准确率从 60.4% 提升到 67.2%。
这里的核心转变是,模型会越来越擅长判断什么应该成为长期记忆。Harness 应辅助模型的判断,而不是替代模型判断。
二、再看“不变”:真正需要外层系统承担的边界并没有消失
原文第三部分提醒我们,随着部分职责被交还给 Claude,Agent Harness 并不会消失。它仍然需要承担那些模型天然不擅长,或不宜完全自行处理的边界问题。

1. 不变的是对智能、延迟与成本的平衡
原文标题中的一句话——“Building applications that balance intelligence, latency, and cost”——其实已经说明,不管模型能力如何演进,这组工程目标始终存在。
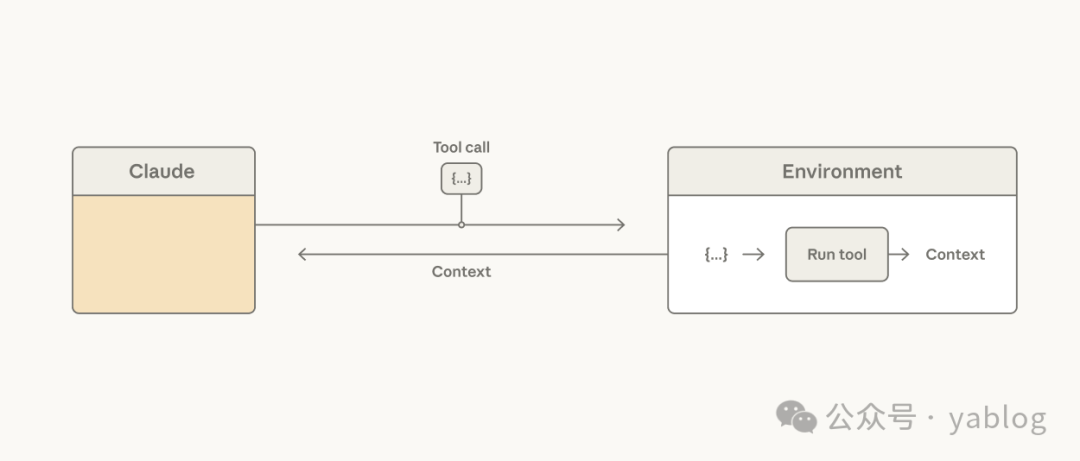
由于 Messages API 是无状态的,Claude 无法直接看到前序轮次的对话历史。因此,在每一轮请求中,agent harness 都需要重新打包新的上下文、此前的行动、工具描述和说明。原文指出,提示词可以基于设定好的 breakpoint 进行缓存,而缓存 token 的成本只有基础输入 token 的 10%。
为了尽可能提高缓存命中率,文章建议遵循以下原则:
| 原则 |
说明 |
| 静态内容在前,动态内容在后 |
将稳定内容,如系统提示词和工具,尽量放在前部。 |
用 messages 做更新 |
通过追加 <system-reminder> 来更新信息,而不是直接改写提示词本体。 |
| 不要切换模型 |
缓存是模型专属的,中途切换模型会使其失效;若需要更便宜的模型,可使用 subagent。 |
| 谨慎管理工具 |
工具位于可缓存前缀中,增删工具会使缓存失效;动态发现可优先使用 tool search。 |
| 更新断点 |
对多轮应用,应及时将断点移动到最新消息处,必要时使用 auto-caching。 |
2. 不变的是对 UX、安全与可观测性的边界管理
Claude 本身并不了解某个应用的安全边界或用户交互界面。它返回的是 tool call,而真正处理这些调用的是 harness。在这种情况下,虽然 bash 工具提供了很强的通用能力,但对于外层系统设计而言,它通常只暴露一条命令字符串,不利于精细拦截、渲染和审计。
因此,原文建议将部分动作提升为 declarative tools 或 dedicated tools。这类工具的价值主要体现在三个方面:
- 安全:对于难以撤销的动作,例如调用外部 API,可以通过用户确认进行把关;
- 用户体验:当某个动作需要清晰呈现给用户时,工具可以被渲染为模态框、选项或结构化表单;
- 可观测性:带类型的工具调用可以提供结构化参数,便于日志记录、链路追踪和回放。
概念解释:
- declarative tools(声明式工具):强调的是如何调用(表达意图),具体实现细节交给外部系统执行。例如模型输出
send_email(to, subject, body) 这种签名,而不是 curl https://api.example.com/send xxxxx 这类具体命令。
- dedicated tools(专用工具):强调的是工具定位,通常是围绕某个业务或系统动作单独设计的,职责非常明确。例如
edit_file, search_code, open_pr 等。
注:一个核心原则是,模型只做决策,永远不直接处理I/O。
三、还有一种“不变”:每次能力跃迁后,都要重新验证架构假设
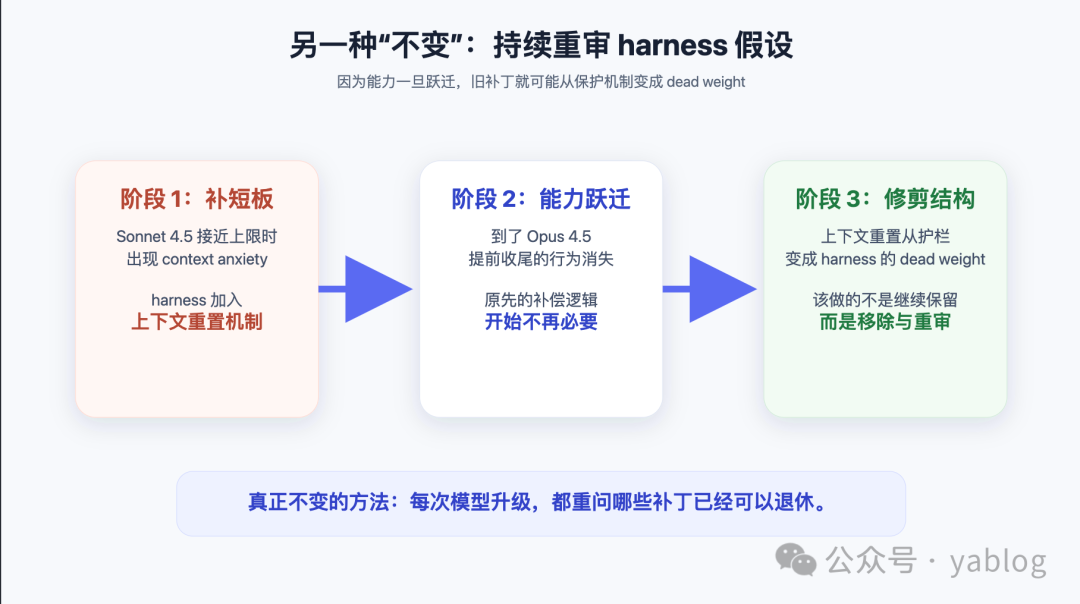
原文最后一部分给出了全文最重要的提醒:agent harness 中的许多结构,最初都是为补偿模型能力不足而引入的。一旦模型能力发生跃迁,这些结构就有可能从保护机制变成“dead weight”。
注:dead weight 指那些曾经有用,但现在已经不再创造价值,反而持续增加系统负担的结构、机制或假设。
Anthropic 提到,在其构建的一个长周期任务智能体中,Sonnet 4.5 会在察觉上下文上限逼近时提前收尾。为了解决这种 context anxiety,团队一度加入了上下文管理重置机制。但到了 Opus 4.5,这种行为已经消失,于是原先为了补偿而加入的上下文重置,反而成为了 agent harness 中的 dead weight。
这给我们的工程启示是:每一层 harness,都在表达某种关于模型能力边界的假设。只要模型发生明显变化,这些假设就应当被重新验证。就像文章所言,随着时间推移,harness 团队需要持续追问——“我还有哪些事可以停止去做?” 即需要持续做减法,这也是DevOps中持续改进思想的体现。
四、结语:Harness 设计的变与不变
- 变的是:harness 与模型之间的职责分工。编排、上下文管理和长期记忆等决策权正随着模型能力增强而回归模型侧。
- 不变的是:围绕约束(成本、延迟)、边界(安全、UX、可观测性)与假设校准所做的工程判断。外层系统仍需在这些领域承担关键职责。
最后,使用模型,相信模型,让“苦涩的教训”不再成为教训。优秀的架构设计总是在动态平衡中演进,关于Agent Harness 的思考,也为我们如何适应快速变化的AI技术栈提供了宝贵视角。欢迎在云栈社区继续探讨相关技术实践。
原文链接:https://claude.com/blog/harnessing-claudes-intelligence
 发表于 2026-4-14 03:25:45
|
查看: 240|
回复: 0
发表于 2026-4-14 03:25:45
|
查看: 240|
回复: 0
