
现有的多模态大模型评测分数日趋饱和,但其表现与人类真实的理解体验之间,依然存在显著差距。为了更精准地衡量这一差距,南京大学傅朝友团队在 Google Gemini 评测团队的邀约下,推出了全新的视频理解评测基准 Video-MME-v2。
该基准通过创新的分层能力体系与组级非线性评分方法,结合超过 3300 人工时的高质量标注,揭示了当前最先进模型与人类专家之间巨大的能力鸿沟(49分 vs 90分),并指出传统准确率(Acc)指标的“虚高”现象,以及“思考”(Thinking)增强并非总是有效等重要发现。

论文:https://arxiv.org/pdf/2604.05015
主页:https://video-mme-v2.netlify.app/
MME-Survey:https://arxiv.org/pdf/2411.15296
Video-MME-v2 是一个面向下一代视频理解能力的评测基准。其构建历时近一年,由 12 名标注人员和 50 位独立审核人员共同完成,累计投入超过 3300 人工时。与传统的评测基准不同,它核心设计了一个逐层递进的三层能力体系,并采用了分组非线性评分方法。
评测结果显示:人类专家的组级非线性得分(Non-Lin Score)为 90.7(传统平均准确率 Avg Acc 为 94.9),而当前表现最强的商业模型 Gemini-3-Pro 的得分仅为 49.4。在开源模型中,Qwen3.5-397B-A17B-Think(512 frames) 取得了最佳结果,分数为 39.1。

Video-MME-v2 在测什么?
Video-MME-v2 的第一个核心设计,是将视频理解能力拆解为一个 逐层递进的三层能力体系。
- 第一层:信息检索与聚合(Perception & Aggregation)。这是最基础的一层,关注模型能否从跨帧、跨模态的信息中,准确识别并提取关键事实。
- 第二层:时序理解(Temporal Understanding)。基于第一层,考察模型是否真正理解了时间维度。要求模型不仅能看懂静态画面,更要抓住动作的先后关系、状态变化及事件因果。
- 第三层:复杂推理(Complex Reasoning)。基于前两层,这一层要求模型在更开放、复杂的场景中进行综合推理,最接近人类的“理解”方式:不仅要看懂,还要能推断、解释和综合。
下图直观展示了这三层能力结构及部分模型的性能排行。
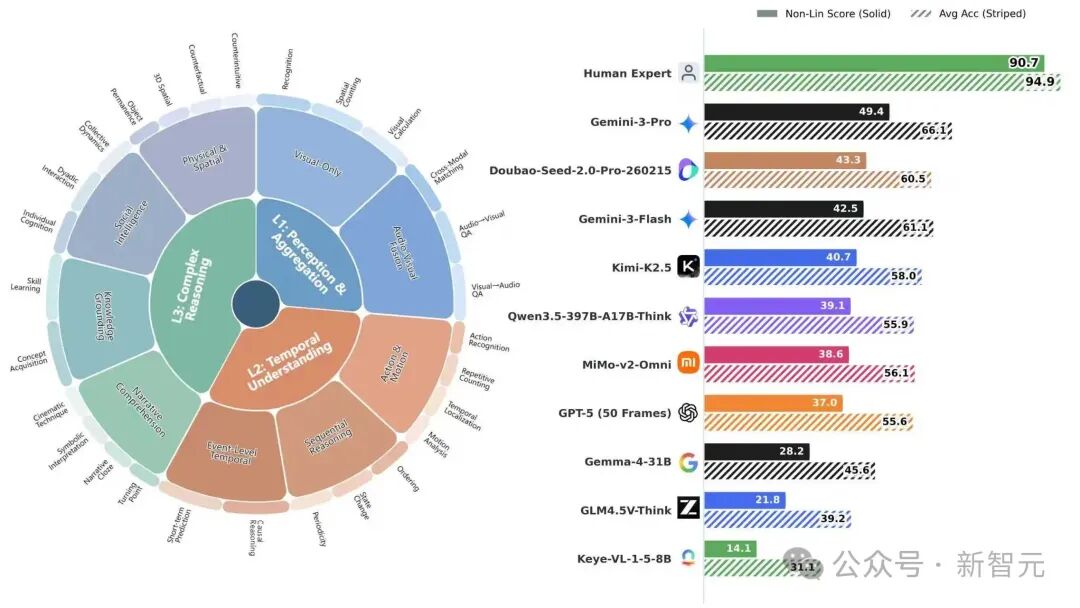
Video-MME-v2 不只是「多出题」,而是换了一种新测法
Video-MME-v2 的第二个关键创新在于评测方法。它没有沿用传统的“每题独立计分”方式,而是引入了 组级评测。即,评估重点不再单看某一道题的对错,而是看模型在一组相互关联的问题上是否表现出 一致性 和 连贯性。
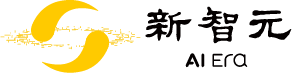
能力一致性组:看模型是不是「真的会」
它关注同一种能力下,模型在不同问法、不同粒度、不同侧面能否保持稳定表现。例如,一个真正具备空间理解能力的模型,应该既能回答“物体在哪里”,也能回答“它与另一物体的相对位置如何变化”。
推理连贯性组:看模型是不是「真正在推理」
它关注复杂多步推理任务中,模型能否沿着合理的逻辑链条一步步得出结论。如果中间某一环出错,即使最终答案“碰巧”正确,这种正确也不被视作可信的推理。
为了配合组级评测,团队采用了 非线性评分机制。
- 对于能力一致性组,采用 激励计分:一个组内答对的问题越多,获得的奖励分数也越高。这意味着零散答对几题无法拿到高分,只有保持组内稳定表现才能获得理想分数。
- 对于推理连贯性组,采用 首错截断 机制:一旦推理链中某一步做错,后续步骤即使答对也不再计分。
评测结果如何?
在主榜结果中,人类专家的优势极为明显。而当前最强的商业模型 Gemini-3-Pro,其组级非线性得分(49.4)尚不足人类专家(90.7)的 55%。这清晰地表明,在更强调一致性与连贯性的严格评测下,当前最先进的视频理解模型与人类水平之间仍存在巨大鸿沟。
论文特别指出,模型从 Level 1 到 Level 3 呈现出明显的性能递减。这 说明高层复杂推理的薄弱,往往根源在于前面的信息聚合和时序建模环节已经出了问题,问题层层累积,最终拖垮了复杂理解能力。
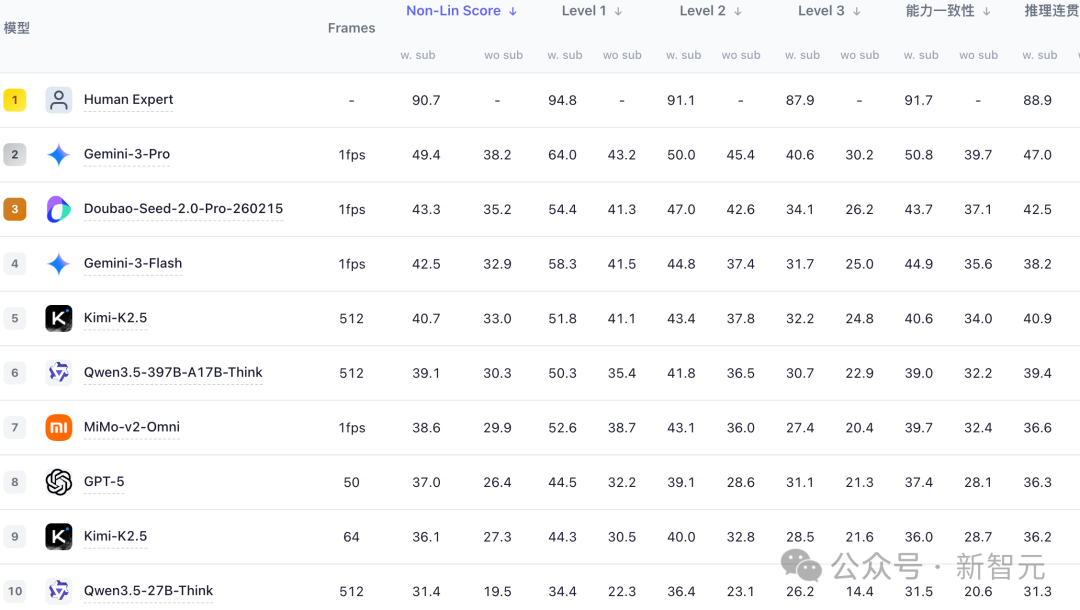
非线性评分的优势:揭示模型稳定性短板
在传统评测中,平均准确率(Avg Acc)是最常用指标,但它本质是逐题独立统计,容易受到“零散命中”的影响。相比之下,组级非线性评分(Non-Lin Score)通过对问题间的结构关系建模,更能反映模型在特定能力维度下的整体稳定表现。
非线性评分还揭示了一个关键现象:从“单题正确”到“组内稳定正确”之间存在 显著的能力折损。团队引入 Non-Lin Score / Avg Acc 比值 来衡量这一折损程度。
实验结果显示,当前最强模型 Gemini-3-Pro 的比值约为 75%;Doubao-Seed-2.0-Pro 的比值约为 72%;而部分中小模型(如 LLaVA-Video-7B)的比值甚至低至约 40%。比值越低,说明模型的稳定性与鲁棒性越弱,越容易出现“组内只能答对部分题”的情况。这凸显了非线性评分在真实刻画能力水平方面的优势。
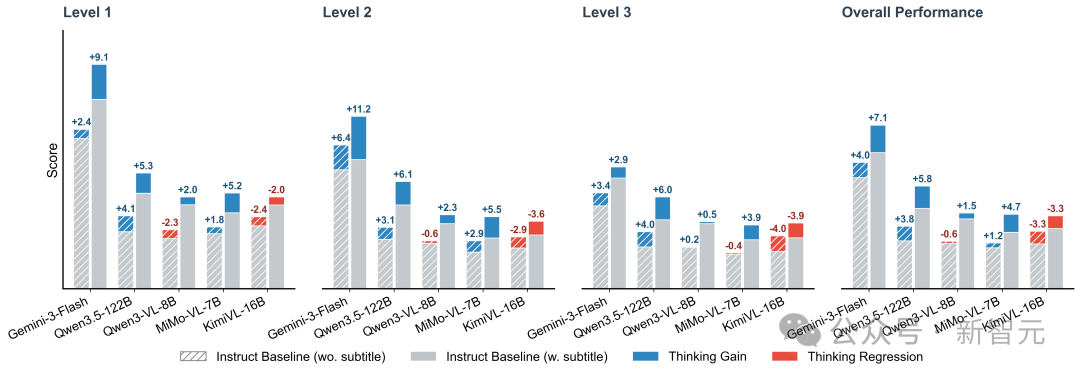
一个值得关注的发现:Thinking,并不总是有效
在当前大模型应用中,“思考”(Thinking)几乎被默认为性能增强选项。但 Video-MME-v2 的一个重要发现是:Thinking 的收益并非无条件成立,它高度依赖文本线索(如字幕)。
论文实验显示,开启 Thinking 后,模型在“有字幕”设定下通常比“纯视觉”设定下获得更明显的提升。这说明,显式的文本语义仍是许多模型进行多步推理时的重要“锚点”。
但另一方面,Thinking 也可能带来性能退化。例如,Qwen3-VL-8B 在无字幕设定下出现了 -0.6 的下降,而 KimiVL-16B 甚至在整体上出现了 -3.3 的性能回落,在 Level 3 复杂推理任务上的退化达到 -4.0。
这揭示了一个事实:当前一些模型的“推理增强”,本质上可能更擅长利用语言线索,而非稳定地从视觉、音频中抽取证据。一旦文本锚点不足,Thinking 不但未必增益,反而可能引入噪声。
小结
Video-MME-v2 旨在推动视频理解评测理念的转变。它强调,下一阶段的竞争不在于谁能在孤立问题上答对,而在于谁能像人一样,在连续、动态、多模态的信息流中,真正理解事件的发生与发展。这项工作为更严谨地评估 多模态大模型 的核心能力提供了新的标尺,也指明了当前模型在鲁棒性与 模型训练 的深层环节上仍面临巨大挑战。
更多技术细节和完整榜单,请查看项目主页与技术报告。对多模态AI前沿技术及评测方法感兴趣的开发者,欢迎在 云栈社区 进行更深度的交流与探讨。
 发表于 2026-4-14 03:47:56
|
查看: 182|
回复: 0
发表于 2026-4-14 03:47:56
|
查看: 182|
回复: 0
