相信不少玩家都曾被 NVIDIA 显卡相对“抠门”的显存配置困扰过。
例如 30 系的 RTX 3060Ti,尤其是 G6X 版本,核心性能几乎触及 RTX 3070,但这两款显卡的显存都仅有 8GB,甚至不如定位更低的 RTX 3060 12GB。
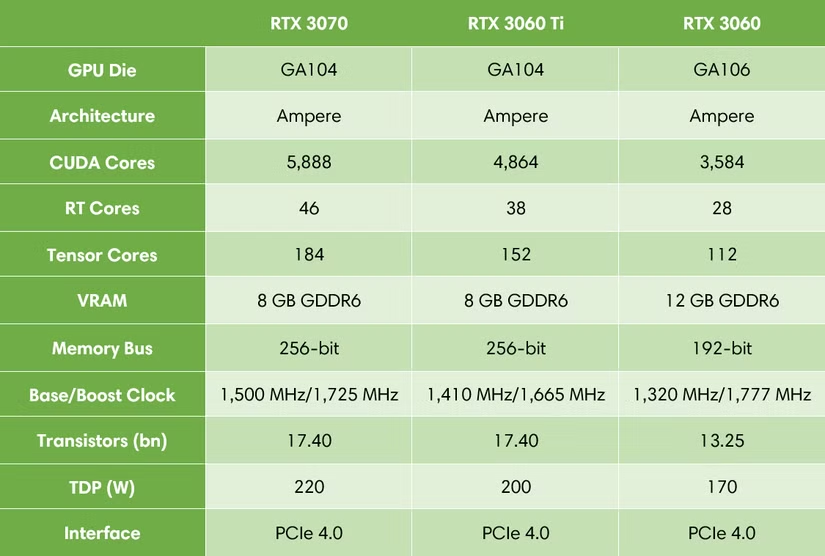
40 系的情况也类似。RTX 4070Ti 本应是一张面向 4K 游戏的显卡,但 12GB 的显存容量成了明显的瓶颈。很多时候,性能足够,但显存容量不足,一旦开启高画质特效,显存便不堪重负。
玩家想要性能和显存都满足?那结果往往是…

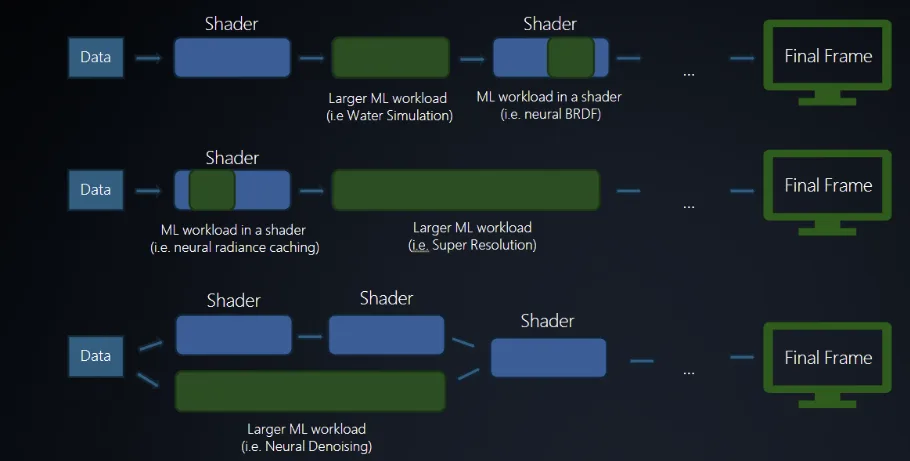
尽管玩家抱怨不断,但多年来,NVIDIA 在显存容量上依然“精打细算”。不过,他们也拿出了另一项技术作为应对方案:Neural Texture Compression,简称 NTC(神经纹理压缩)。这项技术旨在大幅降低游戏纹理贴图对显存的占用。

但熟悉 NVIDIA 策略的朋友知道,他们向来注重“专卡专用”。NTC 技术高度依赖 NVIDIA 的 Tensor Core 算力,因此老旧显卡基本无法享受这项技术带来的红利。

然而,Intel 对此表示不服,在 GDC 2026 大会上,他们从口袋里掏出了自己的解决方案:Texture Set Neural Compression(纹理集神经压缩),简称 TSNC。

TSNC 的目标与 NVIDIA 的 NTC 一致,都是为了降低显存占用。先上结论:根据 Intel 官方介绍,在 Variant A(高质量模式)下,相比未压缩的纹理,TSNC 能提供约 9 倍 的压缩率。
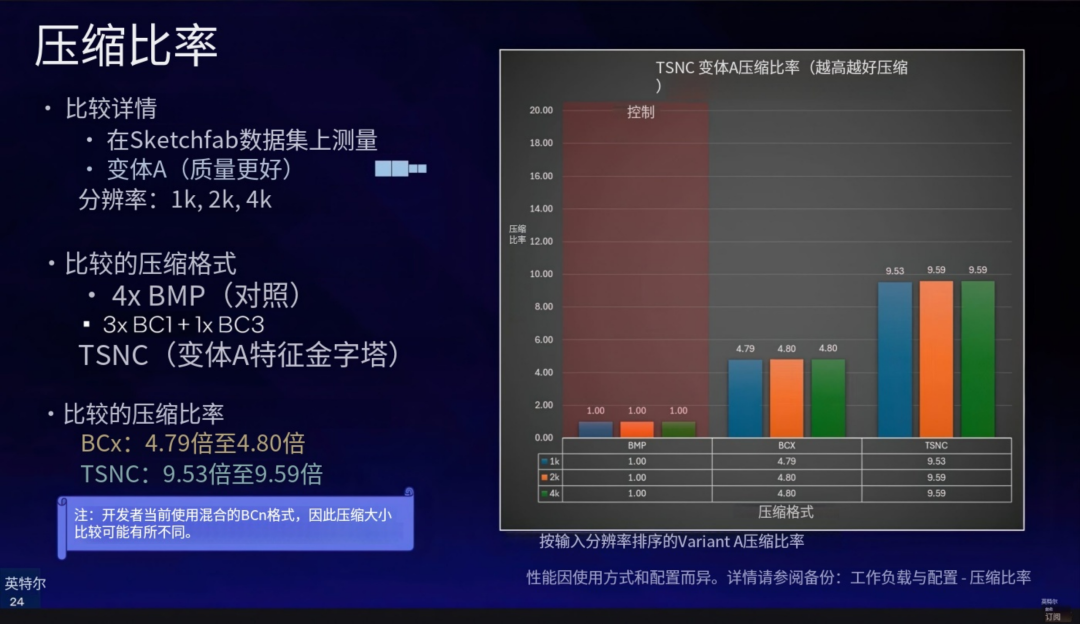
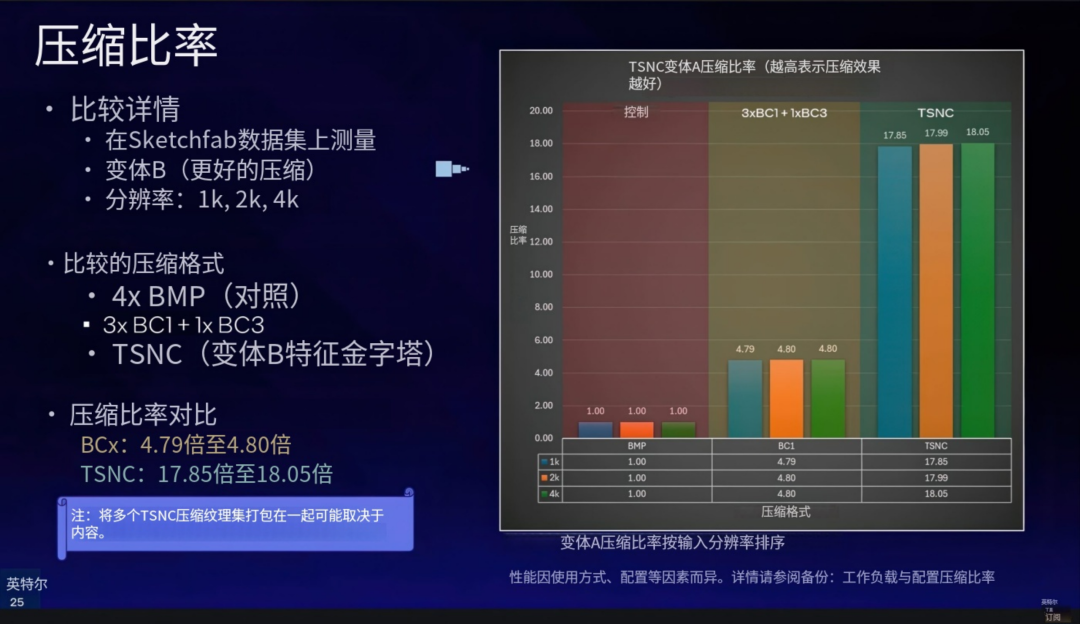
而在 Variant B(高压缩模式)下,压缩率更是高达 18 倍。作为对比,NVIDIA 的 NTC 技术最高压缩率折算下来约为 15 倍。
技术原理有何不同?
两者的技术路径存在显著差异。NVIDIA 的 NTC 几乎是将传统的“纹理采样”过程转变为了“神经网络推断”。它将纹理数据转化为一种高度抽象的“学习型潜变量”,不依赖传统的 BC1-BC7 块压缩格式,更像是一种由 AI 定义的全新格式。
Intel 的 TSNC 则采用了另一种思路。它首先将纹理中最关键的信息以极低分辨率的 BC1 格式存储起来,然后利用一个小型神经网络(3 层 MLP)去预测并填充丢失的细节。
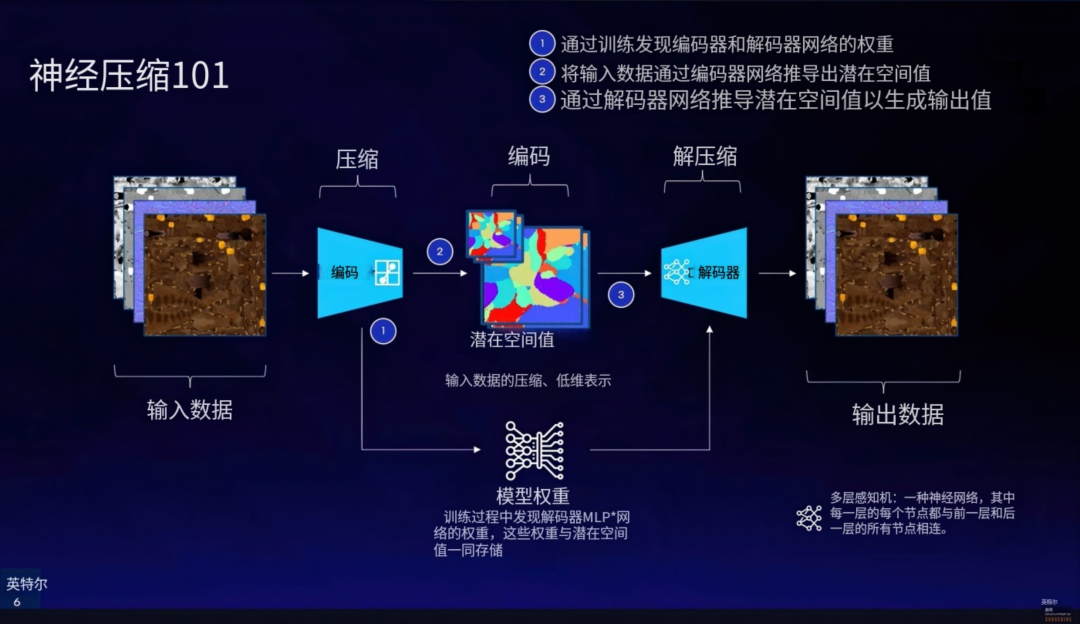
通俗点说,NVIDIA 的 NTC 更像是“无中生有”,直接通过 AI 生成纹理细节;而 Intel 的 TSNC 玩的是“低清补全”,基于一个低保真底图进行 AI 增强。

画质损失与兼容性
不同的原理带来了不同的效果。通过 NVIDIA 的 FLIP 分析工具测量,在 Variant A(高质量模式)下,TSNC 带来的画质损失大约为 5%,视觉上基本难以察觉。
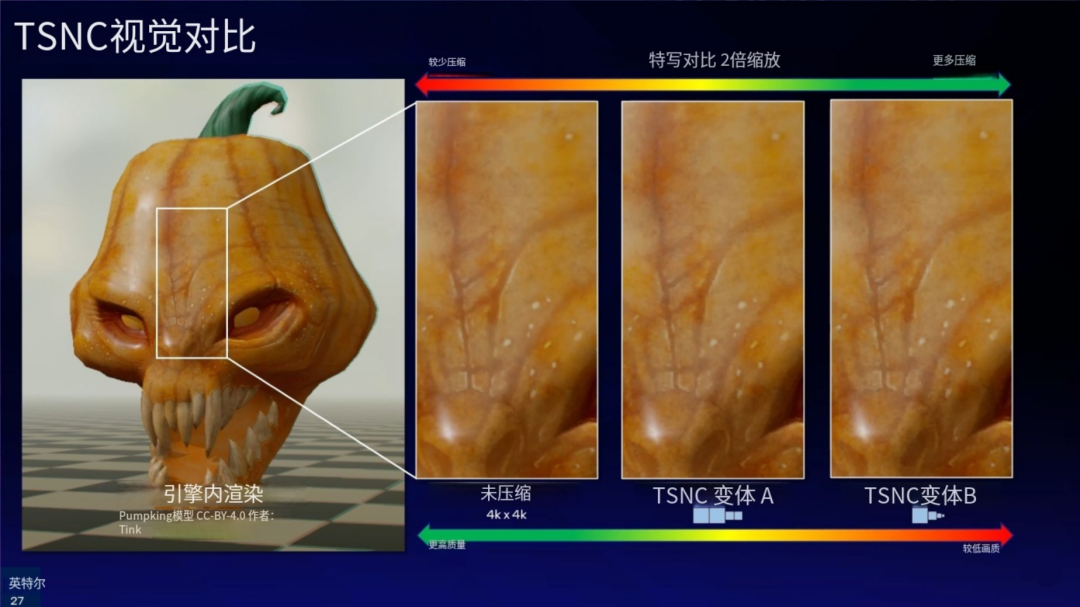
而在 Variant B(高压缩模式)下,画质损失大致在 7% 左右。Intel 承认,在此模式下画质变化是可能被用户察觉到的,因为可能会出现 BC1 块压缩固有的伪影。

但 Intel 这次带来了一个极具“良心”的特性:广泛的兼容性。TSNC 采用解耦式开发,拥有独立的 SDK,并未集成在 XeSS 中。它提供 C++/HLSL 接口,并支持 DX12 Cooperative Vectors API。
这意味着,无论你用的是新显卡还是老显卡(GTX 10 系及以后),也无论显卡品牌是 NVIDIA、AMD 还是 Intel,甚至是集成显卡,理论上都能受益于 TSNC 技术。

性能路径与未来
看到这里,你可能会想,Intel 这不是在给竞争对手做嫁衣吗?并非完全如此。纹理压缩后,自然需要解压才能呈现最终画面。Intel 为此提供了两条解压路径:
- FMA 路径(Fused Multiply-Add):通用回退路径,在通用着色器单元上运行。兼容性极强,所有支持的硬件都能使用。
- XMX 路径(Xe Matrix Extensions):硬件加速路径,可调用 Intel 显卡中专为 AI 矩阵运算设计的 XMX 单元(类似 NVIDIA 的 Tensor Core),性能更高。
性能差距体现在延迟上。Intel 使用其 Pantherlake 架构的 B390 核显在 1080p 分辨率下测试,FMA 路径的解码延迟为每像素 0.661 ns,而 XMX 路径仅为每像素 0.194 ns。
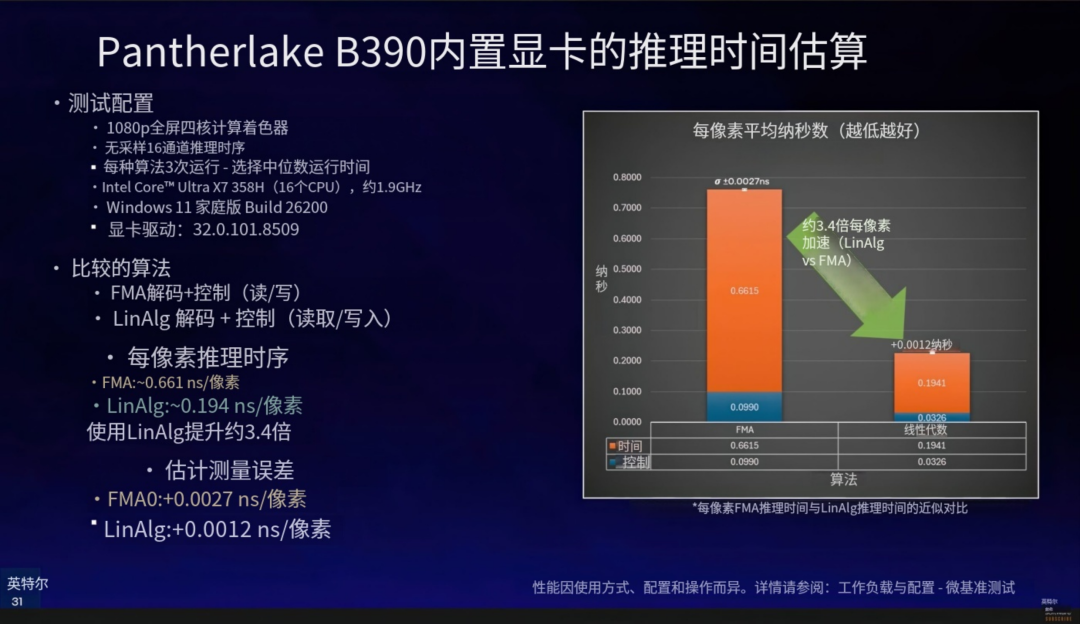
也就是说,使用专用硬件加速,速度比通用路径快了约 3.4 倍,并且性能开销也更低。TSNC 的测试版本预计将在今年下半年发布。
AMD 与行业动态
A 卡用户可能会问,那 AMD 呢?AMD 也有动作,但进展相对较慢。早在 2024 年,AMD 就发布了关于神经块纹理压缩(Neural Block Texture Compression, NBTC)的研究论文。
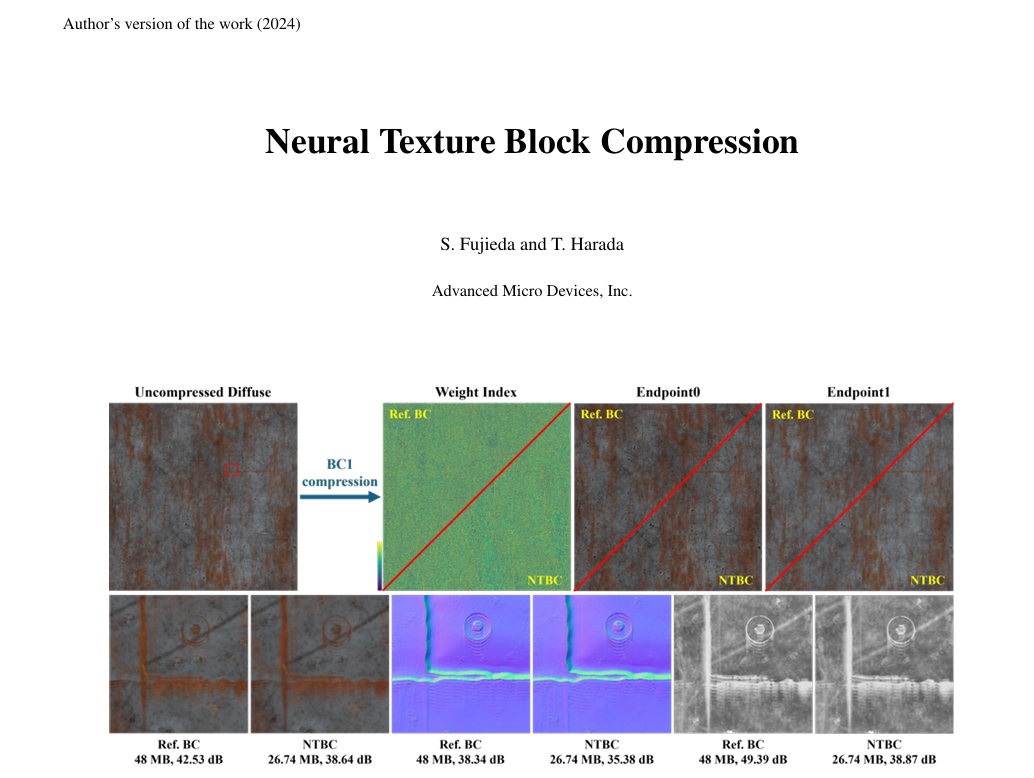
据 AMD 介绍,NBTC 同样使用神经网络对 PBR 纹理集进行编码,可将纹理文件体积减少约 70%,相当于 3.3 倍 的压缩率。这个数字与 Intel 和 NVIDIA 的方案相比还有一定差距,且目前尚未形成成熟的落地方案。

不过,AMD 用户也无需过于灰心。微软在 GDC 2026 上推出了 DirectX Linear Algebra (DXLA) API。这个 API 旨在为 人工智能 纹理压缩等应用提供标准的矩阵计算接口,从而降低神经渲染的延迟。
如果把 NVIDIA 的 NTC 和 Intel 的 TSNC 比作行驶中的车辆,那么 DXLA 就是为它们铺设的标准化高速公路。路已经铺好,AMD 造出自己的“车”也只是时间问题。

但一个更根本的问题或许更值得担忧:当纹理压缩技术越来越强大,显存占用得以大幅降低后,入门级显卡那“祖传”的 8GB 显存容量,究竟还要持续到什么时候呢?这或许是整个 计算机基础 硬件生态需要思考的下一个议题。
数据素材来源:Intel、NVIDIA、AMD,图源网络。
对于这类前沿的图形技术与硬件动态,云栈社区 的 开发者广场 常有不少深度的解读和热烈的讨论,值得开发者们关注。
 发表于 2026-4-14 04:45:17
|
查看: 191|
回复: 0
发表于 2026-4-14 04:45:17
|
查看: 191|
回复: 0
