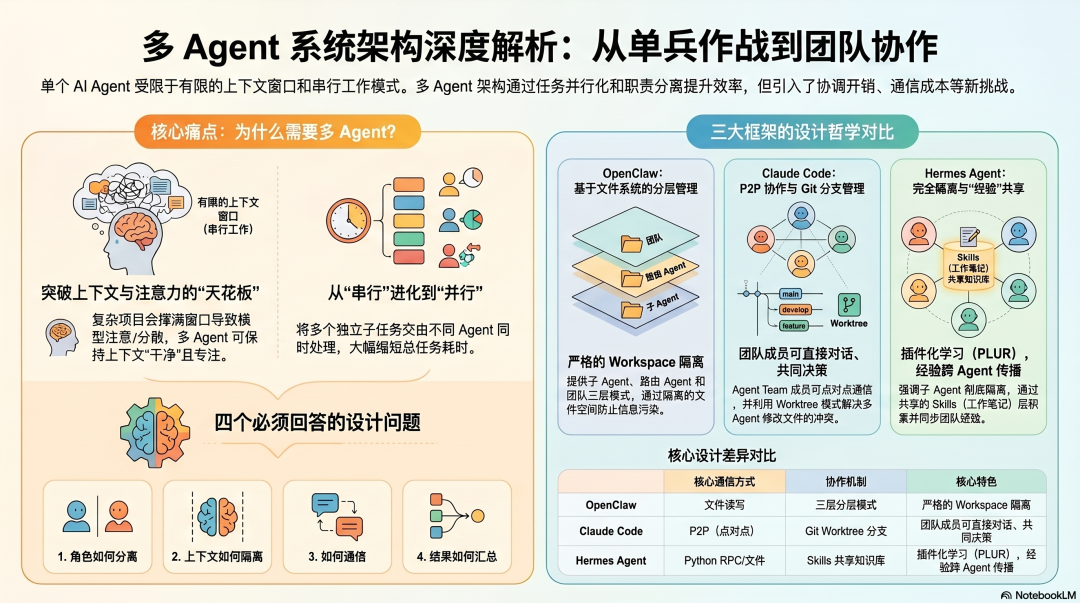
为什么单个 AI Agent 的能力存在天花板?当复杂项目的各种信息塞满上下文窗口,模型的注意力就会分散,输出质量随之下降。更重要的是,单个 Agent 只能串行工作,一个包含多个独立子任务的项目,总耗时将是各个子任务耗时的简单叠加。
引入多 AI Agent 架构的核心价值,就在于让子任务并行执行,同时让每个 Agent 都专注于自己“干净”的职责上下文。但这并非没有代价,协调开销、通信成本、一致性问题都是多 Agent 系统必须面对的工程挑战。设计不当,并行带来的收益可能被内耗完全抵消。
在深入具体框架前,我们需要先明确任何一个多 Agent 系统都必须回答的四个核心架构设计问题:
- 角色如何分离? 如何定义每个 Agent 的职责边界,避免重叠或遗漏。
- 上下文如何隔离? 如何防止一个 Agent 的思维过程“污染”另一个 Agent 的判断。
- 如何通信? 任务结果如何传递,协调是靠语言对话还是预设结构。
- 结果如何汇总? 多个输出如何合并,冲突如何解决,最终给用户一个一致的交付物。
下面,我们将通过 OpenClaw、Claude Code 和 Hermes Agent 这三个框架,看看它们对上述问题给出了怎样不同的答案。
OpenClaw:基于文件系统的分层管理
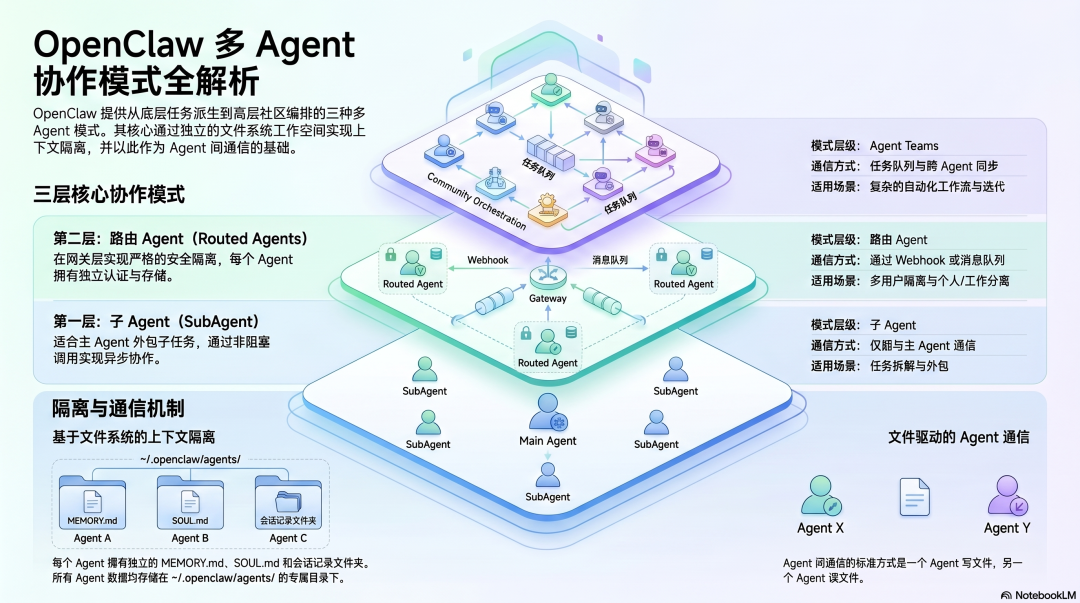
OpenClaw 提供了两个层次的多 Agent 模式,它们解决的是不同场景的问题,常被混淆。
第一层:子 Agent (SubAgent)
主 Agent 可以通过 sessions_spawn 工具或 /subagents spawn 命令派生子 Agent。这是一个非阻塞调用——主 Agent 下达指令后无需等待,可以继续自己的工作。子 Agent 完成后,将结果发回主 Agent 或指定渠道。
这种模式非常适合“主 Agent 将某个子任务外包出去,自己同时推进其他工作”的场景。其关键限制在于:子 Agent 只能向主 Agent 单向汇报,不能与其他子 Agent 直接通信,所有协调必须经由主 Agent 这个中间层。
第二层:路由 Agent (Routed Agents)
这是在 Gateway 层面实现的多 Agent。每个 Agent 拥有独立的工作空间 (workspace)、会话存储和认证配置。通过 bindings 配置,可以将不同渠道或不同用户的请求路由到不同的 Agent 实例。
这适用于需要严格安全隔离的场景,比如将工作与个人的 Agent 分离,或者为不同用户提供专属的 Agent 服务。这一层的 Agent 之间完全独立,不共享任何记忆或上下文,如需通信,必须通过 webhook 或消息队列进行显式转发。
上下文隔离与通信机制
OpenClaw 多 Agent 协作的核心是文件系统隔离。每个 Agent 拥有自己独立的 workspace,其专属的 MEMORY.md、SOUL.md 和会话记录都存储在 ~/.openclaw/agents/<agentId>/ 目录下。
Agent 之间通信的标准方式非常直接:一个 Agent 将结果写入某个文件,另一个 Agent 通过读取该文件来获取信息。这种基于文件的异步通信,构成了其协调层的基础。
Claude Code:P2P 团队与 Git 分支协作
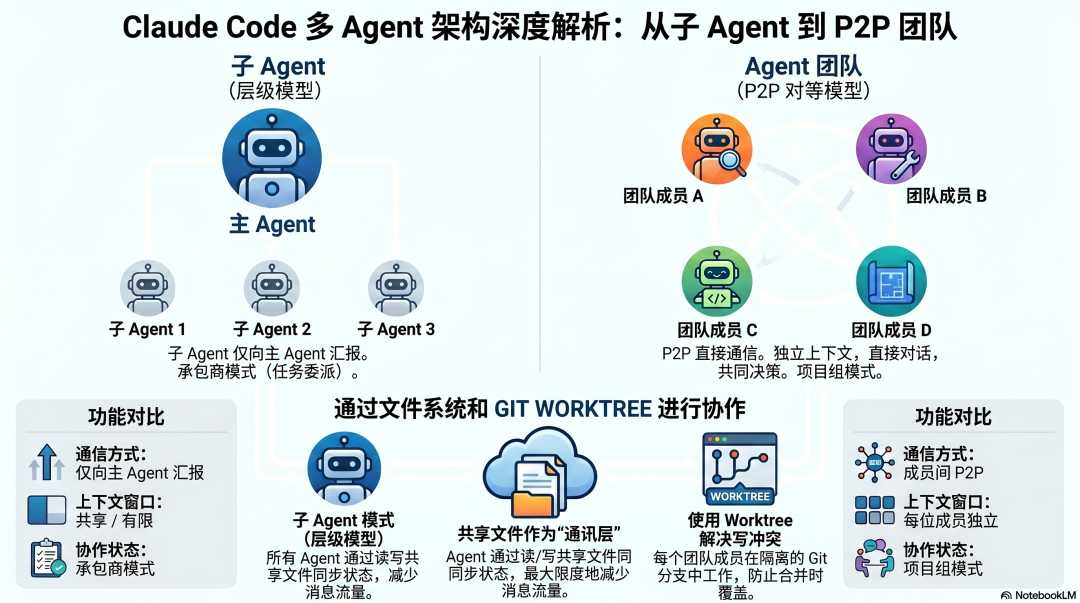
Claude Code 明确区分了两种多 Agent 模式,其官方文档清晰地阐述了它们的本质区别。
子 Agent (Subagents)
在单个会话内派发,只能向主 Agent 汇报结果,无法与其他子 Agent 直接通信。这适合那些快速、聚焦、完成后只需向上汇报的简单任务。
Agent Teams (实验性功能)
由多个完全独立的 Claude Code 实例组成团队。每个成员拥有自己独立的上下文窗口,并且最关键的是,它们可以绕过 Team Lead,直接进行点对点 (P2P) 通信。
这个 P2P 能力是 Agent Teams 与子 Agent 模式最核心的架构差异。子 Agent 像是一组分别向项目经理汇报的承包商,而 Agent Teams 则像一个围坐在一起的项目组,成员之间可以直接对话、互相质疑、共同决策。
文件系统作为协调层,Worktree 解决冲突
Claude Code 的多 Agent 协调不依赖于互发消息,而是通过共享文件状态来实现。可以类比为团队协作编辑在线文档:每个人都能实时看到他人的修改,无需口头转述。
具体实现上,每个 Teammate 都是一个独立运行的 Agent 实例。协调的逻辑是:一个 Teammate 完成了某个模块并写入文件,依赖该模块的另一个 Teammate 通过读取文件就能获知进展,无需通知。
但这就引出一个问题:如果多个 Teammate 同时修改同一个文件怎么办?Claude Code 的解决方案是 Git Worktree 模式。每个 Teammate 在独立的 Git 分支中工作,就像各自在草稿纸上书写,完成后再提交合并,从而避免了同时修改同一行代码导致的覆盖冲突。
如何选择模式?
官方给出了明确的指南:
- 使用 Subagents:任务快速、聚焦、无需相互通信、仅需汇报结果。
- 使用 Agent Teams:任务需要跨前端、后端、测试等多层面协调,需要成员间直接共享发现并挑战彼此方案,且任务可真正并行、相互依赖少。
- 使用单 Session:任务顺序执行、需要修改同一文件、任务间依赖性极强。
Hermes Agent:彻底隔离与共享“经验”库
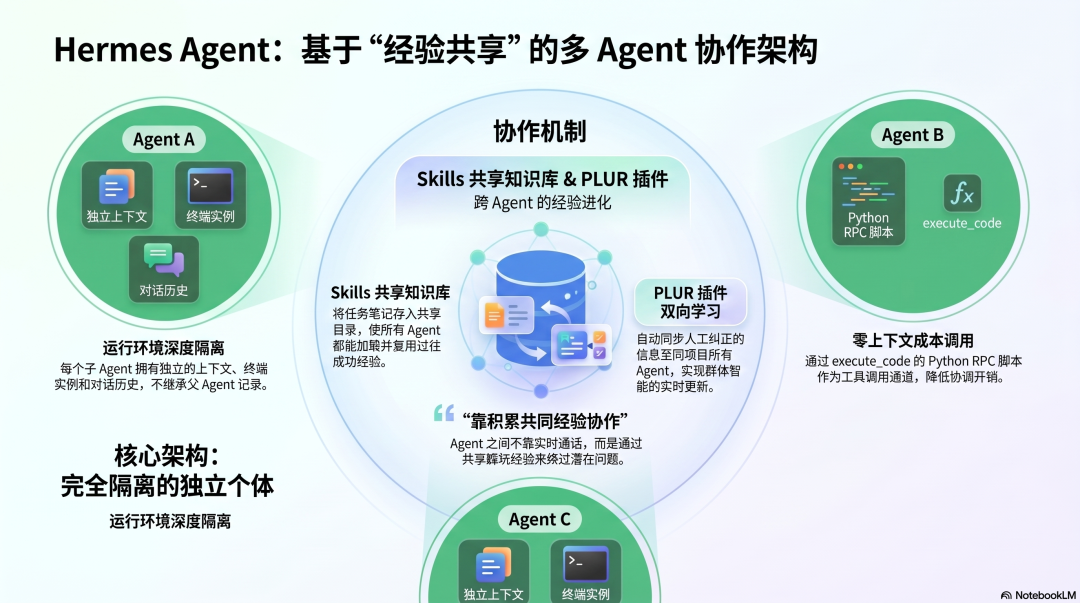
Hermes Agent 的设计哲学非常鲜明:追求子 Agent 的完全隔离,并通过文件系统和共享的 Skills 层来实现协调。
其每个子 Agent 都运行在深度隔离的环境中:
- 独立的对话线程(不继承父 Agent 的任何历史上下文)。
- 独立的终端实例。
- 通过
execute_code 的 Python RPC 脚本作为零上下文成本的工具调用通道。
Skills:跨 Agent 的共享知识层
多 Agent 协作中一个常见痛点是:一个 Agent 摸索出的高效方法,无法被其他 Agent 复用。Hermes 的解决方案不是让 Agent 实时通话,而是构建一个名为 Skills 的共享知识库。
Skills 本质上是 Agent 完成任务后自动写下的“工作笔记”,以 Markdown 格式记录操作流程、踩过的坑和注意事项。默认情况下,笔记各自保存。但如果将一份 Skill 放入 ~/.hermes/skills/ 这个共享目录,那么所有新启动的 Agent 都会自动加载它。
例如,一个 Agent 研究竞品后总结出一套高效分析流程并保存为 Skill。此后,任何执行类似任务的 Agent 都能直接加载这份经验,无需从头摸索。
更进一步,PLUR 插件实现了经验的双向传播。当你人工纠正了某个 Agent 的行为,这个修正可以通过插件自动同步给同项目下的其他所有 Agent,实现群体智能的实时更新。
这是 Hermes 最独特的思想:Agent 之间不依赖于实时通话来协调,而是依靠积累和复用共同的经验。今天一个 Agent 踩过的坑,变成了明天所有 Agent 都能绕过的捷径。
多 Agent 系统设计的核心工程取舍
设计或选用多 Agent 架构时,面临着一些根本性的取舍:
取舍一:让 AI 自主分工,还是由你制定规则?
你可以告诉 AI “帮我做竞品分析”,让它自由发挥。这很省事,但做法不可预测,出问题时难以定位。你也可以明确规定“第一步搜资料,第二步整理对比,第三步写报告”。这更可控,但灵活性差。
结论:任务越固定、容错率越低,越应由你定规则;任务越开放、需要随机应变,越应让 AI 自主判断。
取舍二:Agent 间实时通信,还是通过文件异步协调?
这好比两个同事协作:一种是坐在一起实时同步,响应快但要求双方同时在线;另一种是将成果存入共享文件夹,对方随时可取,但无法感知对方何时查看。
结论:需要频繁确认、快速响应的任务,适合实时通信;仅需传递结果、无需即时反馈的任务,用文件异步协调更高效。
取舍三:子 Agent 应继承上下文,还是完全“无知”?
让同事审查你的方案:如果他全程旁听了你的思考过程,审查时容易顺着你的逻辑走,难以发现初始错误;如果他只看到最终结论,反而更容易独立地发现问题。
结论:需要子 Agent 帮你执行任务时,背景信息越多越好(继承上下文);需要子 Agent 提供独立审查或创意时,让它“从零开始”可能更有效(隔离上下文)。
每种框架的设计都代表了在这些取舍之间的一种权衡。理解这些权衡,而不仅仅是功能列表,才能帮助我们在云栈社区这样的开发者社区中,更好地评估并选择适合自己场景的 Agent 协作方案。
 发表于 2026-4-16 03:26:31
|
查看: 277|
回复: 0
发表于 2026-4-16 03:26:31
|
查看: 277|
回复: 0
