在 AI Agent 技术快速演进的今天,选择合适的工具栈是提升开发效率的关键。本文将深入分析 LangChain 生态中 Agent Frameworks(框架)、Agent Runtimes(运行时) 与 Agent Harnesses(整装套件) 的核心差异与应用场景,帮助开发者在复杂的需求中精准选型。本文首发于云栈社区,欢迎交流讨论。
不同层级的框架对比
https://docs.langchain.com/oss/python/concepts/products
在 Agent 开发栈中,三者分别扮演了不同的角色,其核心价值对比如下:
| 维度 |
Agent Frameworks (框架) |
Agent Runtimes (运行时) |
Agent Harnesses (整装套件) |
| 核心价值 |
抽象化、集成能力、标准化 |
持久化执行、流式输出、人机交互 (HITL) |
预置工具、复杂规划、子智能体调度 |
| 典型代表 |
LangChain, CrewAI, LlamaIndex |
LangGraph, Temporal |
Deep Agents SDK, Manus |
| 控制粒度 |
高层抽象,快速上手 |
低层控制,精细编排 |
意见导向 (Opinionated),开箱即用 |
Agent Frameworks(如 LangChain)主要提供高层抽象,旨在简化开发者与大模型(LLM)交互的复杂度。
- 技术特点:提供结构化的内容块、Agent 循环逻辑以及中间件。它屏蔽了底层复杂的逻辑调用,让开发者能够通过标准的接口调用模型和工具。
- 适用场景:
- 快速原型开发:希望在短时间内构建出具备基础能力的自主应用。
- 团队标准化:需要统一团队构建 Agent 的规范和抽象模式。
- 简单任务:处理流程相对线性、不需要复杂状态管理的 Agent 应用。
当 Agent 需要进入生产环境并处理长周期任务时,Agent Runtimes(如 LangGraph)成为了核心支撑。
- 技术特点:
- 持久化执行:支持任务在中途失败后恢复,或在长时间运行中保持状态。
- 人机交互 (HITL):允许在 Agent 执行过程中引入人工审查、修改状态或干预决策。
- 精细控制:相比框架层,运行时提供了对 Agent 编排的底层直接控制,能够处理非确定性的复杂工作流。
- 适用场景:
- 长周期任务:需要跨越数小时甚至数天运行的状态化 Agent。
- 复杂工作流:结合了确定性步骤与 Agent 决策步骤的混合流程。
- 高可靠性要求:需要生产级基础设施支撑的部署场景。
Agent Harnesses(如 Deep Agents SDK)是更具“意见”的套件,它们基于运行时构建,集成了处理极复杂任务所需的各种高级功能。
- 技术特点:
- 规划与分解:内置任务清单和规划能力,能将复杂目标拆解为可执行的子任务。
- 子 Agent 调度:支持衍生子智能体,通过任务委派保持上下文的清晰。
- 上下文工程:内置文件系统访问、Token 管理(如长对话自动摘要)及工具结果清理。
- 适用场景:
- 高度自主性:需要长时间运行并处理多步骤、非结构化任务的 Agent。
- 复杂环境交互:涉及大量文件操作、Bash 执行或复杂搜索结果处理的场景。
针对开发者关注的具体功能,三者的支持侧重点各有不同:
| 特性 |
LangChain (Framework) |
LangGraph (Runtime) |
Deep Agents (Harness) |
| 短期记忆 |
内置短期记忆组件 |
内置短期记忆组件 |
基于 StateBackend 管理 |
| 技能/工具 |
多智能体技能集 |
- |
预置 Skills 库 |
| 子智能体 |
多智能体抽象 |
子图 (Subgraphs) |
专用 Subagents 模块 |
| 人机交互 |
中间件模式 |
中断 (Interrupts) |
interrupt_on 参数化控制 |
LangGraph 安装
https://docs.langchain.com/oss/python/langgraph/install
LangGraph 的核心包可以通过 pip 或 uv 进行安装。为了确保获取最新功能,建议使用 -U 参数进行升级安装。
pip install -U langgraph
- 环境要求: 运行 LangGraph 必须使用 Python 3.10 或更高版本。
在实际开发中,LangGraph 通常需要配合 LLM 编排框架使用。官方推荐配合 LangChain 共同使用,以简化工具定义和模型调用流程。
pip install -U langchain
- 操作建议:
- 确定所需的 LLM 供应商。
- 访问官方的 集成页面 获取特定的安装指令。
- 单独安装驱动包(例如
pip install langchain-openai)。
LangGraph Graph API
https://docs.langchain.com/oss/python/langgraph/quickstart
本指南将演示如何使用 LangGraph Graph API 构建一个具备加法、乘法和除法功能的计算器智能体(Agent)。该过程分为定义工具、管理状态、构建逻辑节点以及编译工作流四个核心阶段。
LangGraph 的核心在于状态持久化。通过定义 MessagesState,可以确保 Agent 在多次执行或循环中保留上下文信息。
- 消息叠加逻辑:使用
Annotated[list[AnyMessage], operator.add] 确保新生成的消息是追加到现有列表,而非覆盖。
- 计数器:定义
llm_calls 字段用于追踪 LLM 的调用次数。
工作流由相互连接的节点组成,本示例包含两个关键节点:
- 模型节点 (
llm_call) :
- 职责:接收当前状态,调用绑定了工具的 LLM。
- 行为:LLM 根据上下文决定是直接回复用户,还是发起工具调用请求。
- 工具节点 (
tool_node) :
- 职责:解析 LLM 产生的
tool_calls。
- 行为:执行具体的计算函数,并将结果作为
ToolMessage 返回给状态。
通过 条件边(Conditional Edges) 控制 Agent 的执行流向。
- 终止逻辑:
should_continue 函数会检查最后一条消息。如果包含 tool_calls,则路由至 tool_node;否则,流程进入 END。
- 构建图(Graph Building):
- 使用
StateGraph(MessagesState) 初始化。
- 添加节点并建立连接:
START -> llm_call <-> tool_node。
- 编译与运行:
- 调用
agent_builder.compile() 生成可执行对象。
- 通过
agent.invoke({"messages": [HumanMessage(content="Add 3 and 4.")]}) 发起任务。
LangGraph 设计哲学
https://docs.langchain.com/oss/python/langgraph/thinking-in-langgraph
在 LangGraph 中构建智能体(Agent)并非简单的代码堆叠,而是一种将复杂业务逻辑解构为可控、可复用工作流的设计思维。以下是基于 LangGraph 核心设计哲学构建高效 Agent 的五个关键阶段。
构建的第一步是将自动化目标分解为节点(Nodes)。每个节点应是一个执行特定任务的独立函数,随后通过边(Edges) 描述节点间的决策和转换。
- 节点定义:例如在一个客户支持邮件 Agent 中,节点可分为:读取邮件、分类意图、搜索文档、处理 Bug、草拟回复、人工审核及发送回复。
- 连接逻辑:有些节点是固定流转的(如“读取”必然指向“分类”),而有些则包含分支逻辑(如“分类”根据紧急程度指向不同操作)。
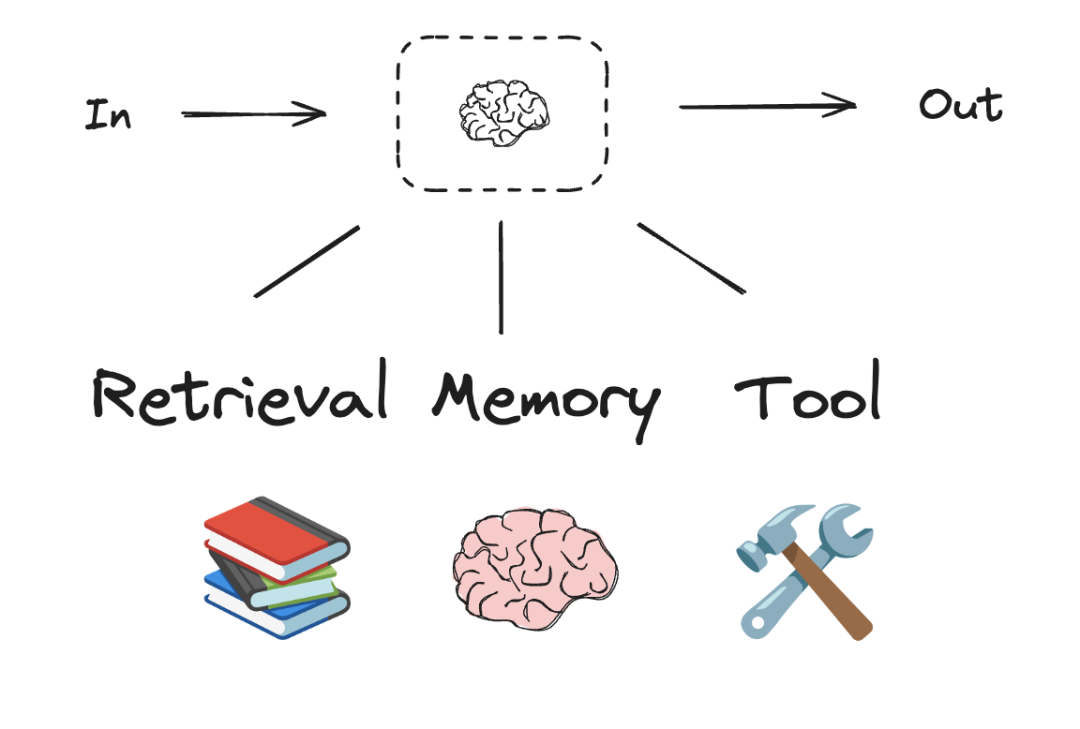
明确每个节点代表的操作类型,这决定了技术实现的选型:
- LLM 节点:用于理解、分析、生成文本或进行推理决策(如意图分类)。
- 数据节点:从外部来源(知识库、CRM)检索信息。
- 动作节点:执行外部操作(如在追踪系统中创建 Issue)。
- 用户输入节点:需要人工干预的环节(如高风险操作前的审核)。
状态是 Agent 的共享内存,所有节点均可对其进行读写。
- 存储原则:
- 持久性存储:存入需要在步骤间传递的数据(如原始邮件、分类结果、搜索到的原始文档、执行元数据)。
- 按需计算:如果数据可以从其他数据推导出来,则不应存储在状态中。
- 核心准则:存储原始数据,按需格式化状态应仅保留原始、未经格式化的数据(Raw Data),而非格式化后的 Prompt 文本。这能确保不同节点可以按需处理相同数据,且在不破坏状态架构的前提下演进 Prompt。
节点是接收当前状态并返回更新后的状态的 Python 函数。在实现过程中,必须考虑四种错误处理策略:
| 错误类型 |
修复主体 |
处理策略 |
适用场景 |
| 瞬时错误 |
系统 |
重试策略(Retry Policy) |
网络抖动、API 速率限制 |
| LLM 可恢复错误 |
LLM |
存入状态并循环 |
解析失败、工具调用参数错误 |
| 用户可修复错误 |
人类 |
中断(interrupt()) |
缺少必要信息、指令模糊 |
| 非预期错误 |
开发者 |
异常抛出 |
需要调试的代码缺陷 |
最后一步是将节点连接成图。LangGraph 的优势在于其对“人机协同(Human-in-the-loop)”的原生支持。
- 状态持久化:使用
checkpointer(如 MemorySaver)编译图。这允许 Agent 在执行 interrupt() 后暂停,保存所有状态,并在人工干预后从中断点恢复。
- 显式流转:通过在节点中使用
Command 对象,让节点自行声明状态更新和下一个跳转目标,使控制流清晰、可追踪。
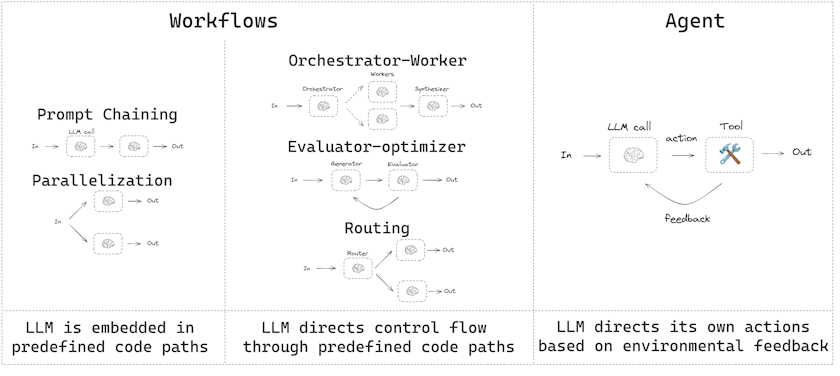
工作流(Workflows)与 智能体(Agents)
https://docs.langchain.com/oss/python/langgraph/workflows-agents
在构建基于 LLM 的应用时,理解 工作流(Workflows) 与 智能体(Agents) 的区别并选择合适的架构模式是确保系统稳定性和高效性的关键。以下是基于 LangGraph 核心理念的深度解析。
在 LangGraph 框架下,开发者需要根据任务的预测性和复杂度在两种模式间做出选择:
- 工作流 (Workflows):具有预定义的代码路径。其执行顺序在编译时已经确定,适用于逻辑固定、步骤明确的业务场景。
- 智能体 (Agents):具有动态性。LLM 自行决定处理流程和工具调用,适用于问题和解决方案无法预估、需要高度自主决策的场景。
根据任务的分解方式和交互逻辑,LangGraph 提供了六种核心设计模式:
1. 提示词链 (Prompt Chaining)
将任务分解为一系列连续的步骤,上一步的输出作为下一步的输入。
- 应用场景:文档翻译、内容一致性验证。
- 特点:每一步都可验证,降低了单次 LLM 调用的复杂性。
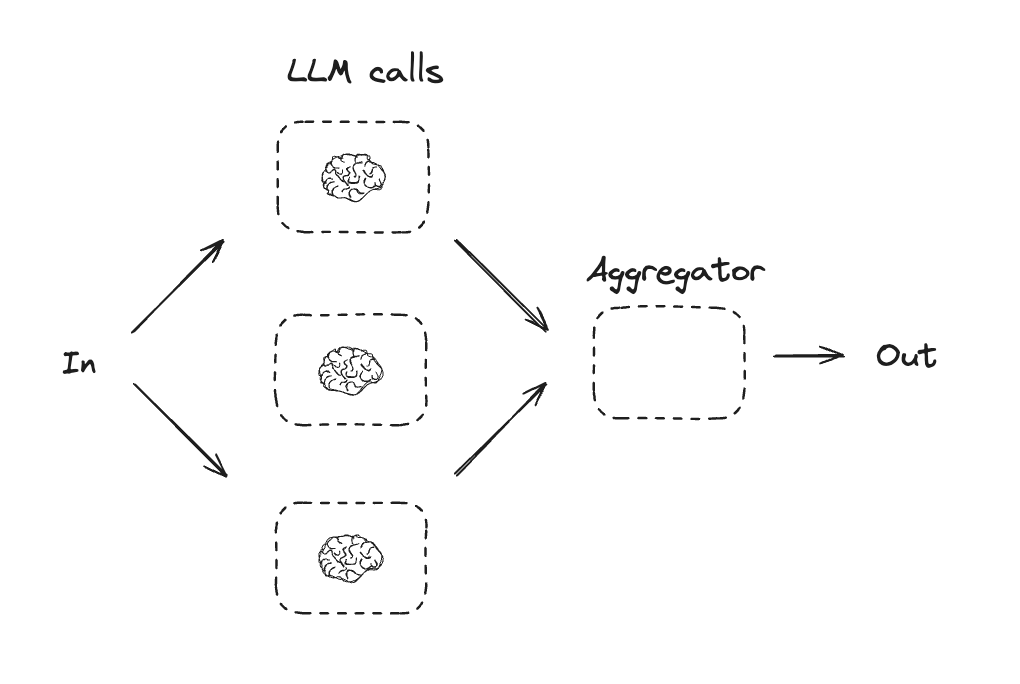
2. 并行化 (Parallelization)
同时运行多个 LLM 任务,分为两种形式:
- 分段并行:将子任务拆分同步执行以提高速度。
- 冗余并行:对同一任务运行多次以通过对比提高结果置信度。
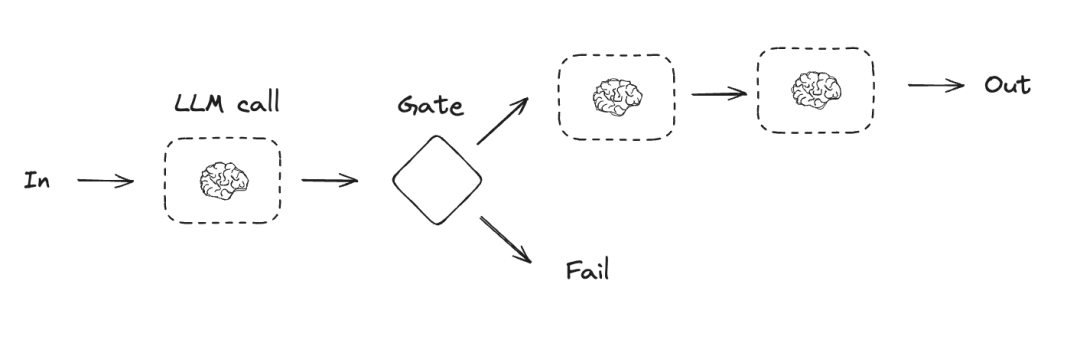
3. 路由 (Routing)
根据输入内容的类型,将其引导至特定的后续任务。
- 应用场景:客户服务系统(根据用户意图路由至“退款处理”或“技术支持”)。
- 实现:利用 LLM 的 结构化输出 (Structured Output) 功能作为路由决策器。
4. 编排者-执行者 (Orchestrator-Worker)
由编排者分解任务、分配给执行者,并最后汇总结果。
- 应用场景:编写涉及多个文件的代码、生成多章节报告。
- 关键技术:使用 LangGraph 的
Send API 动态创建执行者节点并并行处理。
5. 评估者-优化者 (Evaluator-Optimizer)
一个节点生成响应,另一个节点进行评估。如果评估未通过,则带回反馈进行循环迭代。
- 应用场景:文学创作、高质量翻译、代码重构。
- 特点:通过循环反馈机制确保输出符合特定成功标准。
6. 自主智能体 (Autonomous Agents)
智能体在连续的反馈循环中运行,自主调用工具。
- 实现结构:通常包含一个 LLM 决策节点 和一个 工具执行节点 (Tool Node)。
- 逻辑:LLM 决定是否调用工具,执行后将结果返回 LLM,直至任务完成(返回
END)。
在 LangGraph 中实现上述模式,需关注以下技术环节:
| 环节 |
核心组件 / 方法 |
说明 |
| 基础配置 |
ChatAnthropic, init_chat_model |
初始化支持工具调用和结构化输出的模型。 |
| 状态管理 |
TypedDict, MessagesState |
定义节点间共享的数据结构,确保信息流转一致性。 |
| 模型增强 |
.bind_tools(), .with_structured_output() |
赋予 LLM 使用工具或输出特定格式数据的能力。 |
| 流程控制 |
add_conditional_edges |
基于 LLM 的判断或预设逻辑控制图的流转方向。 |
LangGraph 持久化
https://docs.langchain.com/oss/python/langgraph/persistence
LangGraph 的持久化(Persistence)层是构建可靠、可交互 AI 智能体的核心机制。它通过在执行的每个步骤保存图状态的快照(Checkpoints),赋予了系统记忆、容错及人工干预的能力。
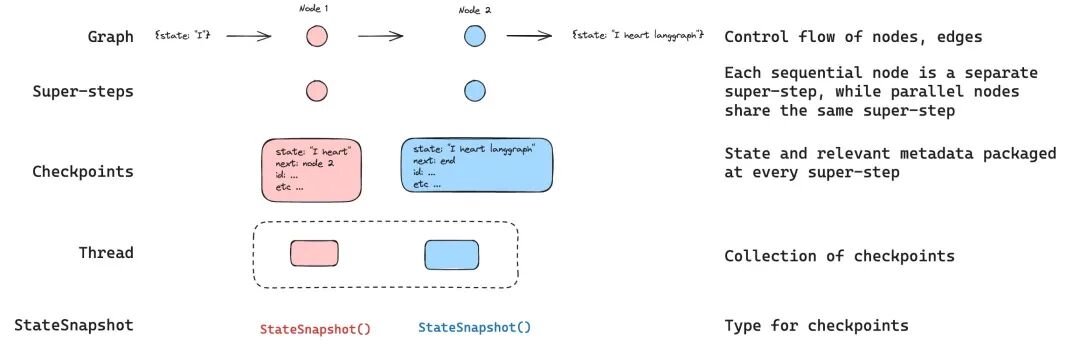
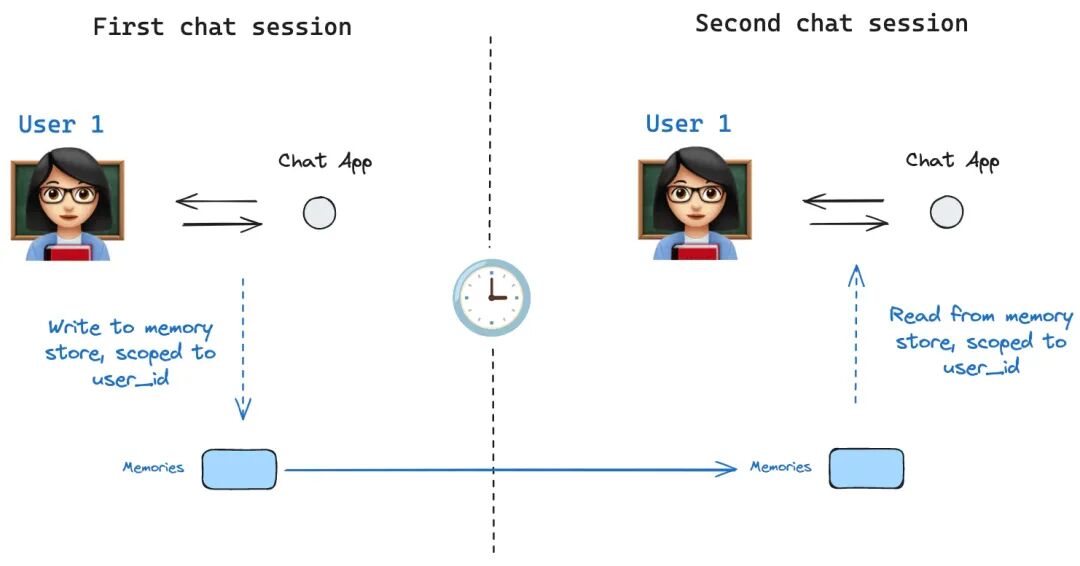
持久化层不仅仅是数据的简单存储,它是实现以下高级功能的基石:
- 人工在环(Human-in-the-loop):允许人类检查、中断或批准图的执行步骤。由于状态已被持久化,人类可以在任何时间点查看状态并在更新后恢复执行。
- 会话记忆(Memory):使智能体能够在多次交互之间保持上下文。后续消息可以发送到同一个线程(Thread),从而保留历史对话信息。
- 时间旅行(Time Travel):支持重放先前的执行过程以进行调试,或者在任意检查点分叉(Fork)状态以探索不同的执行路径。
- 容错与恢复(Fault-tolerance):如果某个节点执行失败,系统可以从最后一个成功的检查点重新启动,而无需从头开始。
- 待处理写入(Pending writes):当某一步骤中有节点失败时,LangGraph 会存储同一步骤中其他成功节点的写入结果,恢复时不会重复运行成功节点。
理解持久化需要掌握三个关键维度:
| 维度 |
定义与作用 |
| 线程 (Threads) |
分配给每个保存状态的唯一标识符(thread_id)。它包含了一系列运行过程中的累计状态。 |
| 检查点 (Checkpoints) |
线程在特定时间点的状态快照。在每个超步(Super-step) 边界自动创建。 |
| 超步 (Super-steps) |
图执行的一个最小单元(一次“滴答”)。所有计划在该步骤执行的节点都会运行并产生一个新的检查点。 |
开发者可以通过以下 API 对持久化的状态进行精细化控制:
- 获取状态:使用
graph.get_state(config) 获取最新状态或指定 checkpoint_id 的历史状态。
- 查看历史:调用
graph.get_state_history(config) 获取按时间倒序排列的状态快照列表。
- 更新状态:利用
update_state 编辑图状态。这会创建一个新的检查点,而不会修改原始数据。
- 重放(Replay):通过指定先前的
checkpoint_id 调用图,跳过已完成的步骤,仅重新执行之后的步骤。
虽然检查点可以将状态保存在单个线程内,但 Store 接口解决了跨线程共享信息的需求(例如跨会话记住用户的饮食偏好):
- 命名空间管理:使用如
(user_id, "memories") 的元组进行隔离。
- 语义搜索:支持配置嵌入模型(Embedding),通过自然语言查询相关记忆。
- 实施建议:开发阶段可用
InMemoryStore,生产环境建议使用 PostgresStore 或 RedisStore。
LangGraph 提供了多种持久化后端的集成支持:
- 官方库:
langgraph-checkpoint-sqlite(本地实验)、langgraph-checkpoint-postgres(生产级)、langgraph-checkpoint-cosmosdb(Azure 集成)。
- 序列化:默认使用
JsonPlusSerializer。对于无法 JSON 序列化的对象(如 Pandas Dataframes),可开启 pickle_fallback。
- 加密保护:通过
EncryptedSerializer 结合环境变量 LANGGRAPH_AES_KEY 实现持久化状态的自动加密。
LangGraph 流式处理
https://docs.langchain.com/oss/python/langgraph/streaming
LangGraph 的流式处理(Streaming)系统旨在提供实时更新,通过在完整响应准备就绪前逐步显示输出,显著提升基于 LLM 应用程序的响应速度和用户体验(UX)。
LangGraph 提供了多种 stream_mode,开发者可以根据需求选择单一模式或组合使用:
| 模式 (Mode) |
返回类型 |
描述 |
| values |
ValuesStreamPart |
每一步执行后返回图的完整状态。 |
| updates |
UpdatesStreamPart |
每一步执行后仅返回状态的更新部分(包含节点名称)。 |
| messages |
MessagesStreamPart |
实时返回 LLM 调用产生的 Token 元组(message_chunk, metadata)。 |
| custom |
CustomStreamPart |
返回通过 get_stream_writer 在节点内部自定义发送的数据。 |
| checkpoints |
CheckpointStreamPart |
返回检查点事件,格式与 get_state() 相同(需配置 checkpointer)。 |
| tasks |
TasksStreamPart |
返回任务开始/完成事件,包含结果或错误信息。 |
| debug |
DebugStreamPart |
提供最全的调试信息,结合了检查点、任务及额外元组。 |
为了优化展示效果或处理内部逻辑,LangGraph 提供了多种过滤机制:
- 按标签过滤 (Tags) :
- 特定模型流式输出:通过为 LLM 绑定标签(如
tags=['joke']),在解析 messages 流时根据 metadata["tags"] 进行筛选。
- 禁止流式输出 (nostream):为模型添加
nostream 标签,该模型仍会运行并产生结果,但其 Token 不会出现在流式输出中。适用于处理内部结构化数据。
- 按节点过滤 (Node) :
- 通过检查
metadata["langgraph_node"],可以仅流式传输特定节点(如 write_answer)产生的 Token。
- 自定义数据传输 :
- 在节点内部调用
get_stream_writer() 获取写入器,随后发送自定义键值对(如进度条:writer({"progress": 50}))。调用 stream 时需包含 stream_mode="custom"。
LangGraph 中断
https://docs.langchain.com/oss/python/langgraph/interrupts
在 LangGraph 框架中,中断(Interrupts) 是实现人工在环(Human-in-the-loop, HITL) 模式的核心机制。它允许图执行在特定点暂停,挂起当前状态并等待外部输入,直到接收到明确指令后再恢复运行。这种能力对于需要人类审批、数据纠错或关键决策的业务场景至关重要。
中断的设计理念是基于状态持久化的动态暂停,其执行逻辑如下:
- 触发暂停:在节点函数内部调用
interrupt()。此时,LangGraph 会抛出一个特殊的异常,通知运行时环境暂停执行。
- 状态保存:运行时捕获异常后,利用检查点(Checkpointer) 将当前图的完整状态(Snapshot)持久化到存储介质中。
- 等待响应:图进入等待状态,直到用户通过相同的
thread_id 重新调用并提供 Command(resume=...)。
- 重新执行:恢复执行时,程序会从触发中断的节点起始位置重新运行,并将
resume 携带的值作为 interrupt() 函数的返回值。
要成功实施中断机制,必须满足以下技术条件:
- 检查点支持:必须配置
checkpointer(如 InMemorySaver 或生产环境的数据库后端)以存储状态。
- 线程标识:通过
config={"configurable": {"thread_id": "..."}} 确保恢复执行时能指向正确的历史状态。
- 数据序列化:传递给
interrupt() 的负载以及 resume 的返回值必须是 JSON 可序列化的。
from langgraph.types import interrupt, Command
def approval_node(state: State):
# 发送中断请求并暂停
user_input = interrupt("是否批准此操作?")
# 恢复执行后,user_input 将获得 resume 的值
return {"approved": user_input}
由于 LangGraph 在恢复时会重新运行整个节点,开发者必须遵循以下开发规范以避免逻辑错误:
- 副作用幂等性:在
interrupt() 之前的任何副作用操作(如数据库写入、API 调用)应具备幂等性,或将其放置在中断之后,以防重复执行产生冗余数据。
- 禁止捕获特定异常:不要在
try/except 块中包裹 interrupt(),否则会截断其抛出的暂停信号。
- 执行顺序一致性:不要在一个节点内根据非确定性逻辑调整多个
interrupt() 的调用顺序,LangGraph 依赖索引匹配恢复值。
- 优先使用动态中断:相比于编译时定义的静态断点(
interrupt_before/after),使用 interrupt() 函数可以根据业务逻辑动态触发,灵活性更高。
中断机制为复杂 AI 工作流提供了多种安全与交互保障:
- 审批流:在涉及财务交易或敏感数据更改前,暂停并等待管理员授权。
- 状态审查与编辑:允许人类审查 LLM 生成的草稿,修改内容后再反馈给 Agent。
- 工具调用干预:在工具(如发送邮件)实际执行前,拦截参数供人类校验。
- 多轮验证循环:通过循环调用
interrupt(),直到用户提供符合规则的有效输入(如年龄验证)。
LangGraph 时间回溯
https://docs.langchain.com/oss/python/langgraph/use-time-travel
LangGraph 的时间旅行(Time-Travel) 功能通过检查点(Checkpoints)机制,为开发者提供了强大的流程控制能力。该功能主要包含两种模式:重放(Replay) 和分支(Fork),能够在不影响原始执行历史的前提下,实现流程的重新执行或状态修改后的分支探索。
1. 重放操作
# 获取历史检查点
history = list(graph.get_state_history(config))
before_joke = next(s for s in history if s.next == ("write_joke",))
# 从指定检查点重放
replay_result = graph.invoke(None, before_joke.config)
2. 分支操作
# 修改状态创建分支
fork_config = graph.update_state(
before_joke.config,
values={"topic": "chickens"},
)
# 从分支继续执行
fork_result = graph.invoke(None, fork_config)
LangGraph 内存管理
https://docs.langchain.com/oss/python/langgraph/add-memory
LangGraph 的内存管理(Memory) 系统是构建高效、可扩展 AI 应用的核心机制。它通过短期记忆(Short-term Memory) 和长期记忆(Long-term Memory) 的协同工作,实现了跨会话的上下文共享和复杂业务场景的数据持久化。
短期记忆用于跟踪多轮对话的上下文,通过检查点(Checkpoints) 机制实现线程级持久化。
1. 基础配置
from langgraph.checkpoint.memory import InMemorySaver
from langgraph.graph import StateGraph
# 创建内存检查点
checkpointer = InMemorySaver()
# 编译图时注入检查点
builder = StateGraph(...)
graph = builder.compile(checkpointer=checkpointer)
# 调用时指定线程ID
graph.invoke(
{"messages": [{"role": "user", "content": "hi! i am Bob"}]},
{"configurable": {"thread_id": "1"}},
)
2. 生产级配置
from langgraph.checkpoint.postgres import PostgresSaver
# 使用 PostgreSQL 作为检查点存储
DB_URI = "postgresql://postgres:postgres@localhost:5442/postgres?sslmode=disable"
with PostgresSaver.from_conn_string(DB_URI) as checkpointer:
graph = builder.compile(checkpointer=checkpointer)
3. 子图检查点
# 子图无需单独配置检查点
subgraph_builder = StateGraph(State)
subgraph_builder.add_node(subgraph_node_1)
subgraph = subgraph_builder.compile()
# 父图配置检查点后自动传播
builder = StateGraph(State)
builder.add_node("node_1", subgraph)
graph = builder.compile(checkpointer=checkpointer)
长期记忆用于存储跨会话的用户或应用级数据,支持语义搜索等高级功能。
1. 基础配置
from langgraph.store.memory import InMemoryStore
# 创建内存存储
store = InMemoryStore()
graph = builder.compile(store=store)
2. 节点内访问
async def call_model(state: MessagesState, runtime: Runtime[Context]):
# 获取用户上下文
user_id = runtime.context.user_id
namespace = (user_id, "memories")
# 语义搜索
memories = await runtime.store.asearch(
namespace, query=state["messages"][-1].content, limit=3
)
# 存储新记忆
await runtime.store.aput(namespace, "key", "value")
LangGraph 子图
https://docs.langchain.com/oss/python/langgraph/use-subgraphs
LangGraph 的子图(Subgraphs) 功能允许将子图作为节点嵌入到父图中,实现模块化开发与多智能体协作。以下是关键设计模式与最佳实践:
1. 封装式调用(Call a subgraph inside a node)
- 适用场景:父图与子图状态模式不同(无共享键),或需状态转换
- 实现方式:
- 通过包装函数转换状态:父状态 → 子图输入 → 子图输出 → 父状态
- 示例:
def call_subgraph(state: State):
subgraph_output = subgraph.invoke({"bar": state["foo"]})
return {"foo": subgraph_output["bar"]}
2. 直接嵌入(Add a subgraph as a node)
- 适用场景:父图与子图共享状态键(如多智能体共享
messages 通道)
- 实现方式:
builder.add_node("node_1", subgraph)
通过 checkpointer 参数控制子图状态保留方式:
| 模式 |
checkpointer= |
行为 |
| 按调用隔离 |
None(默认) |
每次调用从初始状态开始,支持中断与单次调用内的持久化 |
| 按线程保留 |
True |
同一线程内跨调用保留状态,适合需长期记忆的场景(如研究助手) |
| 无状态 |
False |
无持久化,类似普通函数调用 |
典型场景:
- 多智能体系统:推荐使用按调用隔离,确保子智能体处理独立请求
- 长期对话记忆:使用按线程保留,需配合
ToolCallLimitMiddleware 防止并行调用冲突
1. 中断(Interrupts)
- 在子图工具函数中调用
interrupt() 暂停执行,等待外部输入后恢复:
@tool
def fruit_info(fruit_name: str) -> str:
interrupt("continue?")
return f"Info about {fruit_name}"
2. 状态查看(State Inspection)
- 通过
get_state(config, subgraphs=True) 查看子图状态,需确保子图可静态发现
3. 流式输出(Streaming)
- 设置
subgraphs=True 在流式输出中包含子图事件:
for chunk in graph.stream(inputs, subgraphs=True, stream_mode="updates"):
print(chunk["ns"], chunk["data"]) # ns 标识来源图
LangGraph 代码架构
https://docs.langchain.com/oss/python/langgraph/application-structure
典型目录结构如下:
my-app/
├── my_agent/ # 核心代码目录
│ ├── utils/ # 工具函数
│ │ ├── tools.py # 工具定义
│ │ ├── nodes.py # 节点函数
│ │ └── state.py # 状态定义
│ ├── __init__.py
│ └── agent.py # 主图构建文件
├── .env # 环境变量
├── requirements.txt # Python 依赖
└── langgraph.json # 部署配置
LangGraph 测试指南
https://docs.langchain.com/oss/python/langgraph/test
- 全流程测试 通过
compile() 方法编译图并执行完整流程
def test_basic_agent_execution():
checkpointer = MemorySaver()
graph = create_graph()
compiled_graph = graph.compile(checkpointer=checkpointer)
result = compiled_graph.invoke(
{"my_key": "initial_value"},
config={"configurable": {"thread_id": "1"}}
)
assert result["my_key"] == "hello from node2"
- 单节点测试 通过
compiled_graph.nodes["node_name"] 直接调用特定节点
def test_individual_node_execution():
compiled_graph = create_graph().compile()
result = compiled_graph.nodes["node1"].invoke(
{"my_key": "initial_value"}
)
assert result["my_key"] == "hello from node1"
LangGraph Graph API vs Functional API
https://docs.langchain.com/oss/python/langgraph/choosing-apis
LangGraph 提供了两种 API 来构建智能体工作流:Graph API 和 Functional API。以下是两者的对比与选择建议:
- 选择 Graph API 的场景:
- 需要复杂的工作流可视化(用于调试和文档)
- 需要显式状态管理(跨节点共享数据)
- 存在多条件分支和并行执行路径
- 团队协作需要直观的图形化表示
- 选择 Functional API 的场景:
- 对现有代码进行最小化改造
- 使用标准控制流(如
if/else、循环)
- 状态管理在函数作用域内完成
- 快速原型开发或简单线性工作流
Graph API 适用场景
- 复杂分支逻辑
通过显式定义节点、边和状态,Graph API 能清晰展示多条件分支路径:
workflow = StateGraph(AgentState)
workflow.add_node("call_llm", call_llm_node)
workflow.add_conditional_edges("call_llm", should_continue)
- 跨组件状态管理
支持多节点共享和修改全局状态:
class WorkflowState(TypedDict):
user_input: str
search_results: list
- 并行处理与同步
天然支持并行执行路径的合并:
workflow.add_edge(START, "fetch_news")
workflow.add_edge(START, "fetch_weather")
workflow.add_edge("fetch_news", "combine_data")
- 团队协作与文档化
图形化结构便于团队分工和文档维护。
Functional API 适用场景
- 现有代码集成
通过 @task 和 @entrypoint 装饰器快速改造现有代码:
@entrypoint(checkpointer=checkpointer)
def workflow(user_input: str) -> str:
processed = process_user_input(user_input).result()
if "urgent" in processed:
return handle_urgent_request(processed).result()
- 简单线性工作流
适用于顺序执行和简单分支:
@entrypoint(checkpointer=checkpointer)
def essay_workflow(topic: str) -> dict:
outline = create_outline(topic).result()
if len(outline["points"]) < 3:
outline = expand_outline(outline).result()
- 快速原型开发
无需定义状态模式,快速验证逻辑:
@entrypoint(checkpointer=checkpointer)
def quick_prototype(data: dict) -> dict:
step1_result = process_step1(data).result()
return process_step2(step1_result).result()
LangGraph Graph API
https://docs.langchain.com/oss/python/langgraph/graph-api
LangGraph 的 Graph API 是构建复杂智能体工作流的核心工具,通过状态(State)、节点(Nodes) 和边(Edges) 的协同工作,实现灵活的控制流与数据流管理。以下是其核心机制与设计模式的系统解析:
一、核心组件
1. 状态(State)
- 定义:共享数据结构,表示应用的当前快照,支持
TypedDict、dataclass 或 Pydantic Model。
- 多模式支持:
- 私有状态:通过
PrivateState 实现节点间私有通信。
- 输入/输出状态:通过
input_schema 和 output_schema 约束图的输入输出。
- Reducer 机制:
- 默认覆盖:未指定 Reducer 时,状态更新直接覆盖。
- 自定义 Reducer:通过
Annotated 指定操作(如 operator.add 实现列表追加)。
2. 节点(Nodes)
- 功能:执行具体逻辑的 Python 函数,支持同步/异步。
- 参数:
state:当前状态。config:包含线程 ID、标签等配置信息。runtime:提供上下文信息(如存储、流写入器)。
- 缓存策略:通过
CachePolicy 实现节点级缓存,支持 TTL 和自定义 Key 生成。
3. 边(Edges)
- 类型:
- 普通边:固定路由(
add_edge)。
- 条件边:动态路由(
add_conditional_edges),支持多分支并行。
- 入口/出口:
START 和 END 节点控制流程起止。
- 动态路由:通过
Send 对象实现 Map-Reduce 模式,支持未知数量的子任务分发。
二、高级控制流
1. Command 模式
- 功能:结合状态更新与路由控制,支持动态跳转。
- 参数:
update:更新状态。goto:跳转至指定节点。graph:跨子图跳转(Command.PARENT)。resume:中断后恢复执行。
- 应用场景:
- 节点返回时同时更新状态和路由。
- 子图与父图间的跨层级跳转。
- 中断后恢复执行(如人工审核场景)。
2. 递归控制
- 递归限制:默认 1000 步,可通过
recursion_limit 配置。
- 主动监控:通过
RemainingSteps 跟踪剩余步数,实现优雅降级。
- 元数据访问:
config["metadata"] 提供当前步数、节点名等运行时信息。
三、架构设计模式
1. 模块化设计
- 子图(Subgraphs):将子图作为节点嵌入父图,支持:
- 封装调用:父图与子图状态隔离。
- 状态透传:通过共享键或 Reducer 实现状态同步。
2. 消息管理
- 消息状态:通过
MessagesState 预定义消息列表,支持 add_messages Reducer。
- 序列化:自动将字典转换为
Message 对象,支持跨会话持久化。
3. 可视化与调试
- 图可视化:内置工具生成流程图,辅助复杂逻辑调试。
- LangSmith 集成:提供全链路追踪与性能分析。
四、最佳实践
- 状态设计:
- 使用
TypedDict 提升性能,Pydantic 用于复杂验证。
- 通过
Annotated 显式定义 Reducer,避免隐式覆盖。
- 节点优化:
- 对计算密集型节点启用缓存(如
CachePolicy(ttl=300))。
- 使用
Command 替代条件边,减少冗余状态传递。
- 错误处理:
- 主动监控
RemainingSteps,避免递归超时。
- 通过
interrupt 实现人工干预流程。
LangGraph Functional API
https://docs.langchain.com/oss/python/langgraph/functional-api
在构建 AI Agent 或复杂的 LLM 工作流时,我们习惯了将逻辑拆解为节点(Nodes)和边(Edges),并拼凑成一个有向无环图(DAG)。虽然这种“图模式”在可视化和复杂状态管理上表现出色,但对于很多开发者来说,这种强制的代码结构转换往往显得过于沉重。
LangChain 最近推出的 LangGraph Functional API 改变了游戏规则。它允许你直接使用 Python 的原生控制流(if/else, for loops)来构建具备持久化、记忆和人机交互能力的 Agent 流程。
Functional API 的核心价值在于:侵入性极小。你不需要重新构思程序的拓扑结构,只需通过两个简单的装饰器,就能为现有的 Python 函数注入 LangGraph 的生产级特性:
@entrypoint:标记流程的起点。它负责管理执行流、处理中断和持久化检查点。@task:标记执行单元。它可以是 API 调用或数据处理,支持异步执行并能自动缓存结果。
为什么选择 Functional API?
与传统的 Graph API 相比,Functional API 在灵活性上更胜一筹:
- 原生控制流:你可以像写普通脚本一样写 AI 逻辑。想根据条件跳转?直接用
if,不需要定义 conditional_edges。
- 状态自动托管:不需要显式声明
TypedDict 类型的 State 或编写复杂的 reducers。状态被限制在函数作用域内,自然且直观。
- 极致精简:去掉了繁琐的图定义步骤(如
add_node, add_edge, compile),代码量通常能减少 30% 以上。
让我们通过一个经典的 人机领航 (Human-in-the-loop) 场景,看看 Functional API 是如何运作的。
from langgraph.checkpoint.memory import InMemorySaver
from langgraph.func import entrypoint, task
from langgraph.types import interrupt
@task
def generate_draft(topic: str) -> str:
# 模拟耗时的 LLM 调用
return f"这是一篇关于 {topic} 的深度研究报告..."
@entrypoint(checkpointer=InMemorySaver())
def essay_workflow(topic: str) -> dict:
# 第一步:异步执行任务,并获取结果
draft = generate_draft(topic).result()
# 第二步:暂停执行,等待人工审核
# interrupt 会自动将当前状态保存到检查点
is_approved = interrupt({
"content": draft,
"action": "请审核并决定是否发布"
})
return {
"final_output": draft,
"review_status": is_approved,
}
虽然 Functional API 让开发变得简单,但为了确保工作流在中断和恢复后依然稳定,你需要遵循以下原则:
1. 封装副作用 (Side Effects)
永远不要在 @entrypoint 函数中直接进行诸如“写文件”或“发邮件”的操作。如果工作流因为中断而重新运行,这些操作会被触发多次。
正确做法:将所有副作用逻辑放入 @task 中。Task 的结果会被缓存,第二次执行时会直接跳过函数体返回缓存值。
2. 保证控制流的确定性
避免在控制流逻辑中使用 time.time() 或 random.random() 这种每次运行都不同的值。
避坑指南:如果你必须使用这些值,请把它们封装在 @task 里。这样在恢复执行时,工作流拿到的是上一次生成的“确定值”。
什么时候该选哪种 API?
| 特性 |
Graph API (声明式) |
Functional API (函数式) |
| 适用场景 |
极其复杂的循环、状态频繁共享、需要可视化拓扑 |
快速原型、线性逻辑、简单分支、现有代码重构 |
| 学习曲线 |
较陡(需理解 Graph 范式) |
极低(Python 原生感) |
| 可视化支持 |
完美(可生成图结构) |
暂不支持(动态生成) |
| 状态管理 |
全局 State + Reducers |
局部作用域 + 自动序列化 |
LangGraph案例:RAG Agent
https://docs.langchain.com/oss/python/langgraph/agentic-rag
这个 Agent 的工作流程不再是单向的,而是一个循环的控制流,主要包含以下四个关键环节:
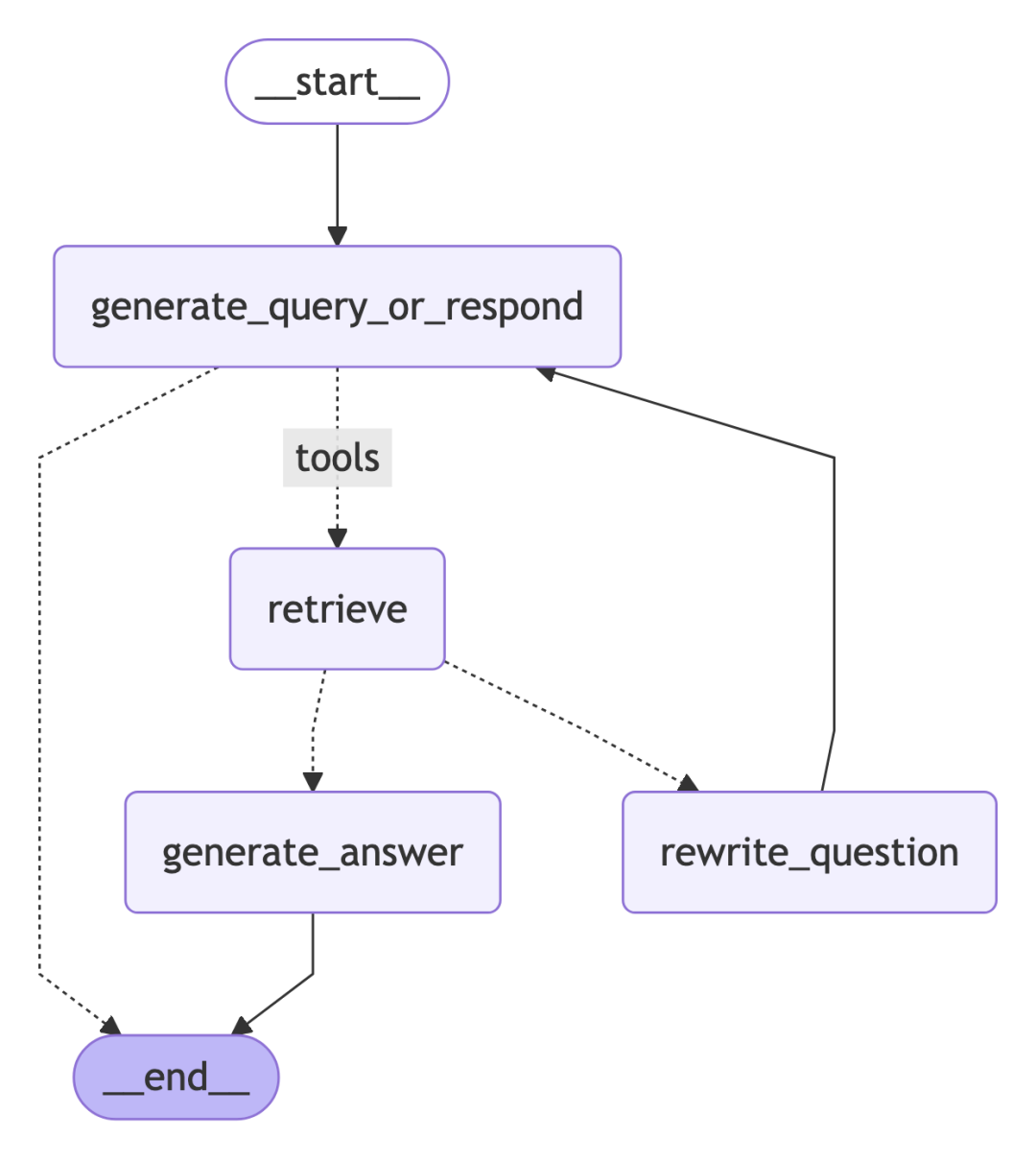
1. 动态决策 (Routing)
在 generate_query_or_respond 节点中,LLM 不仅仅是生成器,它还是“路由”。通过绑定 retriever_tool,LLM 会根据用户意图决定:
- 直接回复:如“你好”,无需检索。
- 工具调用:涉及专业知识时,生成检索查询词。
2. 质量评估 (Self-Grading)
这是提升系统鲁棒性的关键。grade_documents 节点扮演了“裁判”角色:
- 它使用 结构化输出 (Structured Output) 迫使 LLM 返回
yes 或 no。
- 逻辑分流:如果评分不合格,Agent 不会强行回答,而是转入问题重写逻辑。
3. 问题重写 (Query Rewriting)
当初始检索失败时,通常是因为用户的原始问题与向量数据库中的内容“语义跨度”太大。
rewrite_question 节点通过分析原始问题的潜在意图,生成更适合向量检索的新查询词。
4. 状态管理 (MessagesState)
整个 Graph 共享一个 MessagesState。
- 所有的交互记录(User Message, AI Tool Call, Tool Message, Final Answer)都按顺序追加。
- 这种基于消息流的设计让系统非常容易扩展为多轮对话模式。
LangGraph案例:SQL Agent
https://docs.langchain.com/oss/python/langgraph/sql-agent
传统的 SQL Agent(如 create_sql_agent)往往是一个黑盒,而使用 LangGraph 构建的自定义 Agent 实现了逻辑透明化和环节可控性。
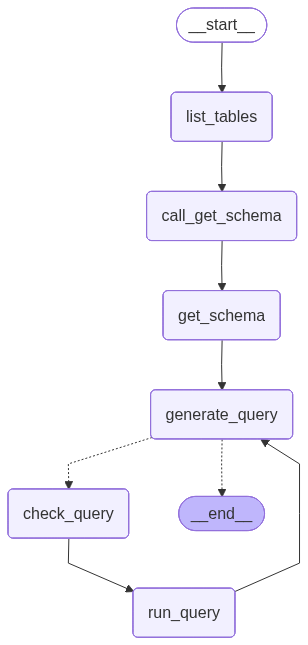
1. 强制性的确定性节点 (Deterministic Nodes)
在教程第 4 步中,作者没有让 LLM 自己去猜该用什么工具,而是通过 list_tables 函数定义了一个确定的起始节点。
- 逻辑强制化:无论用户问什么,第一步永远是获取数据库表清单。
- 效率优化:避免 LLM 在不知道表名的情况下瞎猜,减少了 Token 浪费和错误尝试。
2. 多级校验机制 (Multi-stage Validation)
教程展示了两种校验 SQL 安全性的方式:
A. 自动化校验 (Check Query Node)
在 check_query 节点中,使用了一个专门的 System Prompt 来让 LLM 扮演“SQL 审计员”。
- 关注点:
NOT IN 处理、NULL 值、连接(Join)条件。
- 这种“生成-校验-执行”的模式能过滤掉 80% 以上的常见语法错误。
B. 人机交互校验 (Human-in-the-loop)
这是针对生产环境最核心的功能。通过 interrupt 函数,Agent 会在执行 SELECT 以外或高成本查询前“暂停”:
- 状态持久化:使用
InMemorySaver 保存当前线程。
- 人工介入:人类可以 批准 (accept)、修改 (edit) SQL 语句,或者 反馈 (response) 错误信息让 AI 重新生成。
3. 工具调用的精准绑定
教程使用了 SQLDatabaseToolkit 提供的标准工具集,但通过 model.bind_tools 进行了节点级别的限制:
- 在
call_get_schema 阶段,强制 LLM 只能调用 sql_db_schema 工具。
- 在
generate_query 阶段,则允许其灵活选择。
 发表于 2026-4-16 03:23:28
|
查看: 312|
回复: 0
发表于 2026-4-16 03:23:28
|
查看: 312|
回复: 0
