
3D高斯泼溅(3DGS)技术迎来了一次史诗级的能力飞跃。
2026年4月15日,由“AI教母”李飞飞领导的世界模型团队World Labs正式开源了动态3D高斯泼溅渲染器——Spark 2.0。新版核心突破在于,它能让包含超过1亿个高斯泼溅点云的超大3D场景,在网页浏览器中实现秒级加载与流畅交互,覆盖从手机到VR的全平台设备。
李飞飞本人在成果发布后第一时间评论道:“Spark 2.0现在可以在任意设备上流式传输超过1亿个高斯泼溅!能够为基于网页的3DGS渲染开源生态做出贡献,我们感到无比自豪!”
Spark系列最初于2025年发布,是一个专为网页构建的动态3D高斯泼溅渲染器。它与最流行的网页端3D框架Three.js深度集成,并利用WebGL2实现在任意带有浏览器的设备上运行。
此次发布的Spark 2.0,相比前代最关键的新增特性是一套细节层级(LoD)系统。这套系统解决了大规模3DGS场景在资源受限设备上流畅渲染的核心难题。此外,团队还设计了全新的 .RAD文件格式 用于高效压缩与流式传输,并引入了虚拟泼溅分页系统来管理GPU显存,理论上支持对“无限大”3D泼溅世界的访问。


那么,Spark 2.0是如何实现让亿级点云场景在网页上“秒开”的?其背后主要依赖三项核心技术的深度融合:连续式细节层级优化、渐进式流式加载以及虚拟显存管理。
01 采取连续式细节层级,稳定渲染百万级泼溅
在计算机图形学中,处理大型3D场景的经典方法是细节层级系统,它根据物体与观察者的距离动态调整渲染的细节程度,以平衡画质与性能。
传统的离散式细节层级需要为同一物体预先准备多个不同精度的版本,并在距离变化时进行切换。这种方式存在明显缺陷:切换瞬间画面会产生“跳变”感;同时,将场景分块处理时,块与块之间的边界也可能被用户察觉。
Spark 2.0彻底摒弃了离散模式,转而采用一种连续式LoD方法。所有的高斯泼溅都被组织在一个层级树状结构中,即“LoD泼溅树”。
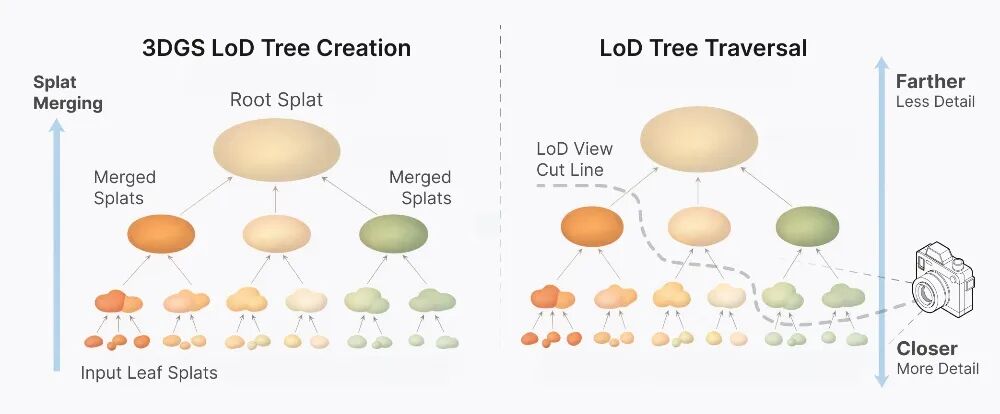
在这棵树中,每个内部节点都是其子节点的一个低分辨率近似表示,通过将多个子泼溅合并成一个新泼溅来实现。这个过程从叶子节点一直向上聚合,直到树的根节点——一个单一的、大的泼溅,它代表了整个物体最概略的形状和颜色。
渲染时,Spark 2.0并非渲染整棵树,而是计算出一个穿过该树的“切割面”,仅为当前视口选取最合适的N个泼溅进行渲染。通过为不同设备设置一个恒定的最大泼溅预算N(通常在50万到250万之间),系统确保了每一帧的渲染负担是稳定可控的,从而维持高帧率。用户只需调整N值,即可在帧率与画面细节之间做出权衡。

Spark 2.0将该算法进一步扩展,使其能同时遍历场景中的多棵LoD泼溅树。算法将每个3DGS物体根据其屏幕尺寸和初始泼溅节点一同加入优先队列,然后统一进行全局最优的细节层级筛选。
这一设计让构建大规模组合世界变得异常简单:开发者只需在场景中任意放置多个3DGS物体,Spark 2.0的引擎便能自动、高效地计算出每一帧需要渲染的全局最优泼溅子集。
02 设计新型.RAD文件格式,实现大场景渐进式加载
为了将庞大的3DGS数据高效地通过网络传输到客户端,并支持边下边播的体验,Spark 2.0团队定义了一种全新的文件格式——.RAD。
此前,常见的3DGS格式如.PLY和.SPZ各有优劣。.PLY采用行式存储,支持渐进式加载,但压缩率低且编码精度浪费。.SPZ采用列式存储,压缩率高,但必须完整下载文件后才能开始解析,无法流式传输。
.RAD格式的目标是兼得二者之长:在获得高压缩率的同时,支持随机访问和渐进式流式传输。其设计核心是编解码简洁、扩展性强、编码精度可调。
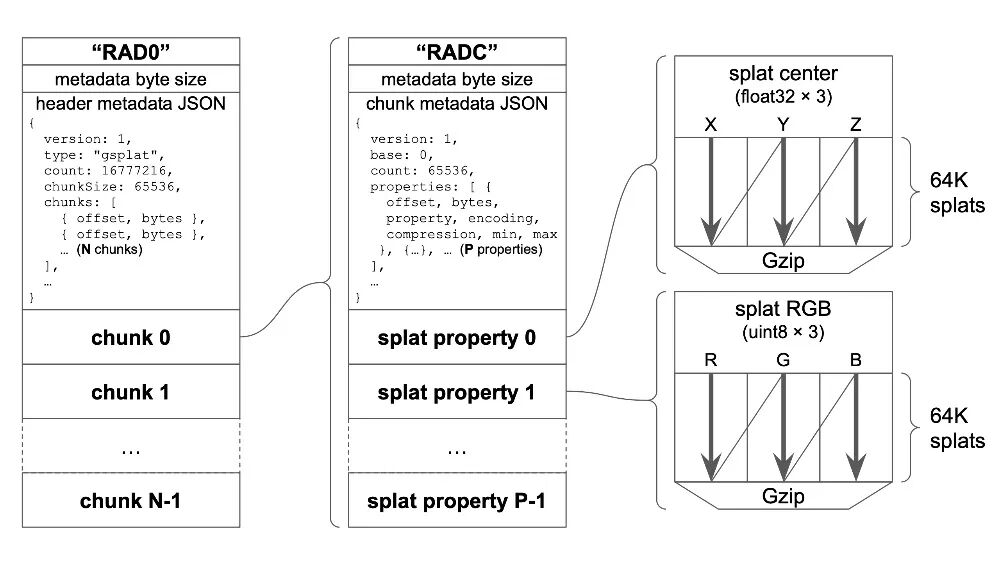
.RAD文件的结构非常清晰:
- 文件以
RAD0 头开始,后面跟着头部元数据的长度和一段JSON元数据。
- JSON元数据中记录了后续所有数据块的偏移地址和字节大小,支持按任意顺序读取。
- 文件主体由一个或多个数据块组成,每个数据块固定包含6.4万个泼溅的数据。
单个数据块的结构与之类似:
- 以
RADC 块头开始,接着是块元数据长度和JSON元数据。
- 最后是这6.4万个泼溅所有属性的压缩数据。关键在于,泼溅的各类属性(如位置、颜色、透明度)是按列分开存储的,每一列都可以独立指定编码方式和压缩算法(例如使用Gzip)。这种同类数据集中压缩的方式能带来极高的压缩比。
整个格式的元数据都使用JSON编码,并包含版本号字段,确保了未来的可扩展性。
03 采用虚拟内存管理,开辟固定GPU显存池
即使有了高效的流式传输,如何在海量数据中管理有限的GPU显存,仍是实现“无限场景”渲染的最后一道关卡。Spark 2.0的解决方案是借鉴操作系统的虚拟内存管理思想。
具体来说,团队在GPU上开辟了一块固定大小的显存池,相当于“物理内存”,假设其可容纳1600万个泼溅的数据。同时,他们将.RAD文件中每个包含6.4万个泼溅的数据块定义为“虚拟内存页”。
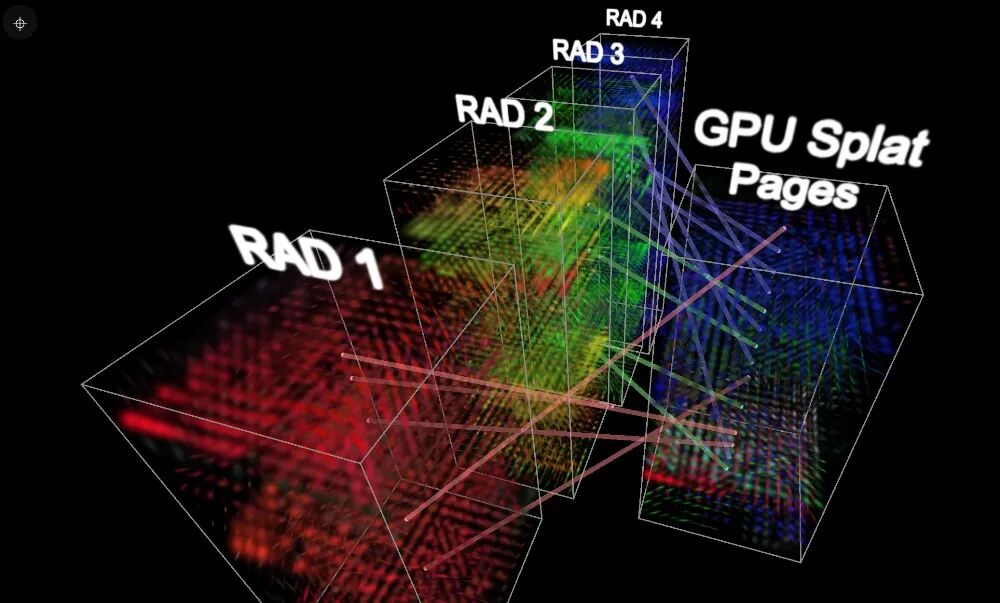
系统自动管理着虚拟数据块(页)与GPU显存池中对应位置(页框)之间的映射关系。当LoD遍历算法确定需要某个数据块时,引擎会尝试将其加载到一个空闲的“显存页”中。如果显存池已满,而新请求的数据块优先级更高,系统则会按照最近最少使用(LRU) 策略淘汰旧页面,为新数据腾出空间。
这套机制支持同时加载多个.RAD文件,并共享同一张全局页表。在遍历多棵LoD树时,引擎会综合记录所有数据块的访问优先级,从而实现对整个场景数据加载与缓存策略的全局统一优化。
04 结语:降低空间智能创作门槛,争夺下一代基础设施定义权
从2025年初次亮相到如今的2.0版本,Spark的进化清晰地展示了3D高斯泼溅技术从实验室走向大规模应用的成熟路径。
长期以来,高质量3D内容在互联网上的传播受制于两大瓶颈:庞大的文件体积让网页加载举步维艰;高昂的渲染算力需求将移动设备拒之门外。Spark 2.0通过连续LoD、.RAD格式、虚拟显存管理这“三板斧”,系统地攻克了这些难题,让沉浸式3D体验能够像流媒体视频一样,在普适的网页平台上即点即看。
李飞飞团队将此项关键技术开源,不仅大幅降低了空间智能内容的创作与分发门槛,更是在积极参与并塑造下一代互联网3D内容基础设施的底层标准。未来,无论是数字孪生、虚拟社交还是沉浸式电商,网页端3D渲染能力的突破都将为其打开全新的想象空间。
 发表于 2026-4-16 16:59:57
|
查看: 329|
回复: 0
发表于 2026-4-16 16:59:57
|
查看: 329|
回复: 0
