
想象一下,你面前有64个A100 GPU组成的算力集群和20万小时的训练时间,你会用来做什么?南加州大学Robin Jia教授团队给出了他们的答案:训练一组完全开源的大语言模型(LLM),让整个研究社区都能借此深入理解模型记忆的底层逻辑。
当前,大语言模型对训练数据的精确记忆带来了诸多安全风险:从《纽约时报》起诉OpenAI侵犯版权,到黑客通过提示词提取训练集中的个人隐私信息,再到数据污染导致模型基准测试分数虚高。然而,由于难以精确控制训练数据,探究大模型记忆的深层因果机制一直面临巨大挑战。
为了量化并解决这一难题,南加州大学(USC)与马克斯·普朗克软件系统研究所(MPI-SWS)等机构的研究人员,借助英伟达捐赠的海量算力资源,构建了一组基于Llama 3架构的全开源、受控大模型,并将其命名为“Hubble”。这项研究成果即将亮相ICLR 2026,所有模型、数据和代码均已完全开源。

从被动观察到主动干预:Hubble,模型记忆研究的“双面镜”
提到Hubble,人们自然会联想到哈勃太空望远镜。这项研究的命名并非偶然。主要贡献者、南加州大学博士生魏天正表示,他们的初衷正是于此:“大模型就像一个深邃复杂的宇宙,我们则是‘仪器科学家’,在Hubble模型中构建并搭载特定的‘探测仪器’,再将它发射升空,以此精确观测各种现象。”
在Hubble之前,学术界研究模型记忆动态的标杆是Pythia模型套件。尽管Pythia开源了训练数据和检查点,成为了可解释性研究的常用工具,但其训练数据来源于天然互联网语料,研究人员无法进行精确的因果推断。例如,当Pythia复述一段文本时,研究者无法确定这是因为文本简单,还是因为它在训练集中出现的频率高。
为了解决缺乏对照组的问题,Hubble团队采用了“受控扰动”的研究方法。他们首先对包含1000亿至5000亿Token的基座语料进行了严格过滤,剔除潜在敏感信息。随后,他们人工合成了三类“诱饵数据”,并将其精确植入扰动模型的训练集:
- 受版权保护的内容:如畅销书片段、冷门书片段及维基百科词条。
- 结构化隐私数据:通过YAGO知识图谱合成的包含姓名、邮箱等属性的个人简历,以及欧洲人权法院的真实案卷。
- 基准测试“小抄”:注入了MMLU、HellaSwag等通用基准测试的原题及答案。
团队还严格控制了这些“诱饵”在训练集中的重复次数,为量化研究创造了条件。

百万美元算力投入,揭示两大关键记忆效应
获取足量算力是高校团队开展大规模预训练的核心瓶颈。Hubble系列包含8个模型(1B和8B参数,分别在100B和500B Token上训练的标准版和扰动版),其训练数据量是Pythia的1.6倍,基本性能与同级模型持平。
魏天正透露,团队通过美国国家科学基金会(NSF)的NAIRR试点项目,获得了英伟达捐赠的20万小时A100 GPU算力,市场价值约100万美元。在正式训练前,团队有一个月在16张GPU上“试用”的机会,用于高频调试超参数和数据插入比例。流程跑通后,他们用了四个月时间,顺利完成了全部模型的训练。
基于严密的受控实验,该研究揭示了大模型记忆机制的两大核心效应:
1. 稀释效应:相对频率决定记忆强度
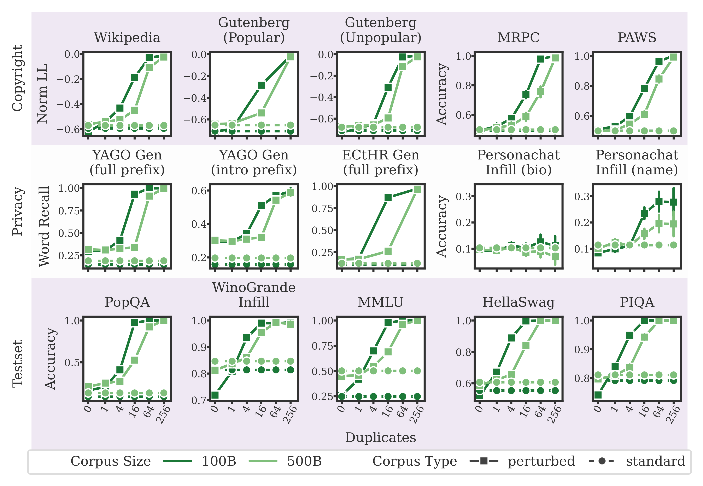
研究表明,模型是否记住某段敏感信息,关键不在于绝对重复次数,而在于其在整个语料库中的相对频率。相同重复次数的信息,在5000亿Token的大语料库中被成功提取的概率,显著低于在1000亿Token的小语料库中。这一发现与Pythia的结论形成了互证。
2. 时序效应:“早出场,早遗忘”
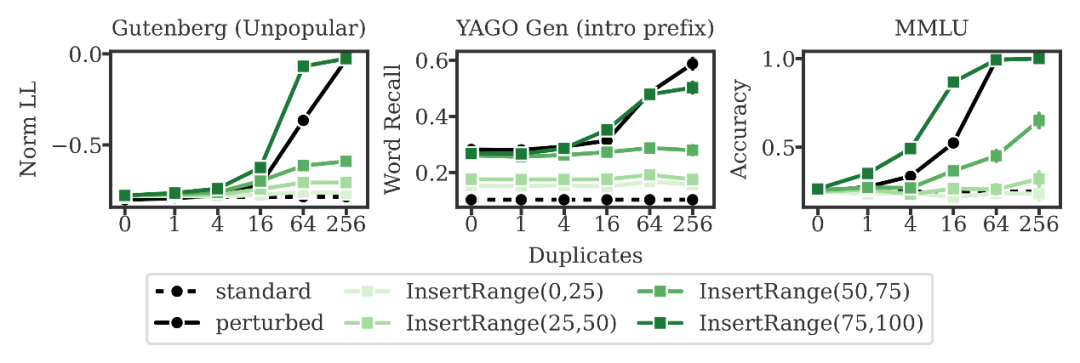
数据暴露的时机对记忆能力有显著影响。团队通过切分训练阶段发现,如果隐私数据仅出现在预训练的前25%阶段,且后续不再出现,模型最终会产生“自然遗忘”,无法准确提取。相反,出现在训练末期的数据则极易被牢固记忆。
此外,团队还利用富余算力探索了模型深度与记忆能力的关系。在总参数量不变的情况下,他们训练了8层、16层和32层三种架构的模型。结果发现,层数更深的模型记忆能力更强。研究人员解释,这可能是因为更深的模型具备更强的表征灵活性,在拟合复杂数据分布时,也附带增强了对特定文本的逐字记忆能力。
评估“机器遗忘”:事后干预存在局限性
面对隐私和版权风险,产业界目前寄希望于“机器遗忘”技术,试图在训练完成后,通过微调等技术将特定数据从模型中“擦除”。当前较前沿的遗忘算法包括表征误导遗忘(RMU)、表征重路由(RR)和饱和-重要性(SatImp)。
利用Hubble,研究人员让这三种算法在包含版权和隐私诱饵的8B扰动模型上同台竞技。测试要求是精确抹除“遗忘集”,同时尽可能保留“保持集”和模型的通用能力。
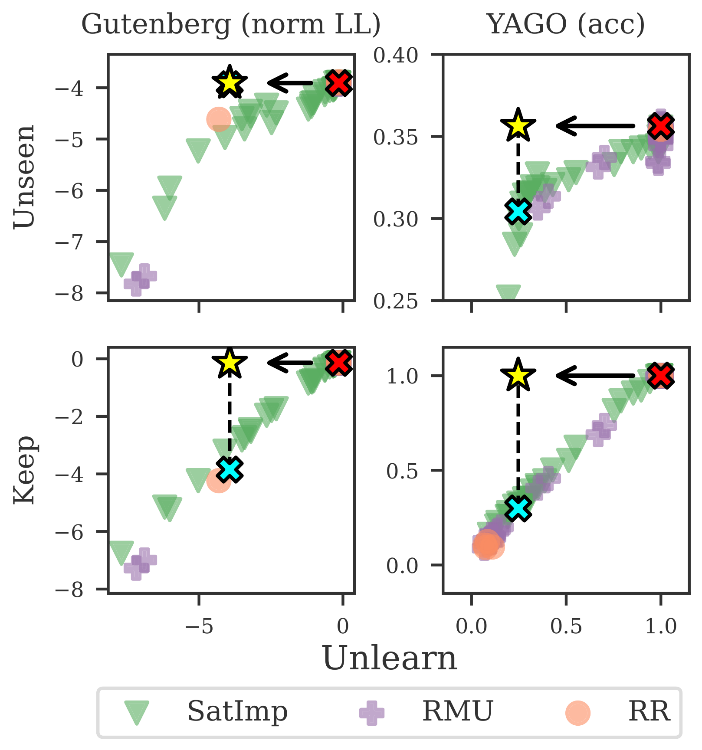
结果显示,尽管SatImp算法表现相对最好,但目前没有任何一种算法能实现完美的“无损记忆擦除”。魏天正指出:“如果模型已经训练完成,想要在后期修改它的底层知识是非常困难的。”实验证实,由于Dense Transformer架构中的知识呈现高度分布式和交织状态,现有算法要么删除不彻底,要么“矫枉过正”,在删除版权内容的同时,也会损害模型正常的语言和推理能力。
这项结论从工程角度提醒业界,对抗数据记忆风险,更有效的策略可能是在预训练阶段就提前规划,例如让敏感数据“早出场”并对其进行充分稀释。
法律应用潜力与未来方向
研究团队的交叉学科背景让他们看到了这项技术对现实法律判决的潜在影响。当前,AI公司因使用受版权保护的数据面临诉讼时,往往对训练数据讳莫如深,因为在美国法律中,数据使用的“合理使用”边界尚不清晰。
Hubble模型提供了一种新的思路。一方面,内容创作者可以在作品中植入特定的“诱饵水印”(如无逻辑字符序列),一旦大模型完整输出这些字符串,便可作为其非法爬取并赋予高权重的证据。另一方面,合规的企业可以利用Hubble的实验模式,向监管机构证明,其数据稀释策略已将特定样本的权重降低至无法被精确提取的水平,从而在“合理使用”抗辩中占据有利地位。
谈及未来计划,魏天正表示,得益于Hubble“标准版”与“扰动版”的对比设计,团队已开始尝试区分模型的“机械记忆”与真正的“泛化推理”能力。他们发现,提前“看过”考题的扰动模型在基准测试上分数虚高,但题目稍加改动就会出错。通过对比两种模型的内部状态,结合探针技术,研究人员有望将受数据污染影响的分数矫正至模型真实的泛化水平。

Hubble从诞生起就不是为了“屠榜”基准测试。构建者希望它能像Pythia一样,成为学界探究模型透明性与可解释性的科学平台,推动训练出更负责任的AI。目前,Hubble的1B、8B模型检查点、诱饵数据集以及高效数据处理管线TokenSmith,均已完全开源。
“我们把Hubble交给整个科研社区,可能会催生出更多意想不到的发现。”研究团队期待,全球研究者能接力使用这套标准化工具,在数据的宇宙中持续解码那些尚未被照亮的“记忆暗物质”。
 发表于 2026-4-16 16:54:01
|
查看: 163|
回复: 0
发表于 2026-4-16 16:54:01
|
查看: 163|
回复: 0
