“2018 到 2023 年间在 EMNLP 会议上发表的那篇论文中,第一作者本科就读于达特茅斯学院、第四作者本科就读于宾夕法尼亚大学的那篇科学论文,题目是什么?”
这并不是一道靠记忆就能解答的题。一个真正的深度搜索Agent必须在多轮环境交互中,不断假设、验证并修正路径,始终保持推理一致性,才能将零散证据整合成自洽链条。
2025年被视为 AI Agent 元年,但真正的自主智能体其核心能力在于「深度搜索」——在长程任务中像人类专家一样维持目标、验证信息并动态调整策略。然而,训练这样的智能体普遍面临三大瓶颈:
- 数据稀缺:高难度长程问答任务极度依赖人工标注,成本高昂。因此,我们需要一条能够自动化合成高难度问题的链路。
- 能力鸿沟:预训练模型虽知识储备丰富,却缺乏与真实环境进行长程交互的能力。这需要通过低成本的中训练(Mid-Training)阶段来弥补鸿沟。
- 环境缺失:在真实环境中训练成本高且不可控。一个功能等价的模拟环境,可以在本地复现搜索过程,从而支持算法的快速迭代。
为突破这些瓶颈,REDSearcher 团队设计了一套低成本、可扩展的训练框架。最终,他们仅使用 30B 参数规格的模型,就在深度搜索任务上取得了开源模型的 SoTA(State-of-the-Art)性能,并且超越了包括 GPT-5 在内的众多闭源模型。
项目资源:
01 什么是「足够难」的深度搜索题目?
什么是困难的搜索题目?很多人会关注推理跳数,但这往往只是表象。我们应该追求的是问题的结构性困难。
1. 拓扑复杂度:用树宽衡量「结构性困难」
在复杂任务中,信息分叉交织,甚至形成回环。智能体需要同时记忆多路推论,时刻验证其一致性,并随时准备进行整体回溯——这才是深度搜索的核心挑战。为此,团队引入了图论中的 TreeWidth(树宽) 概念来刻画这种「结构性困难」。
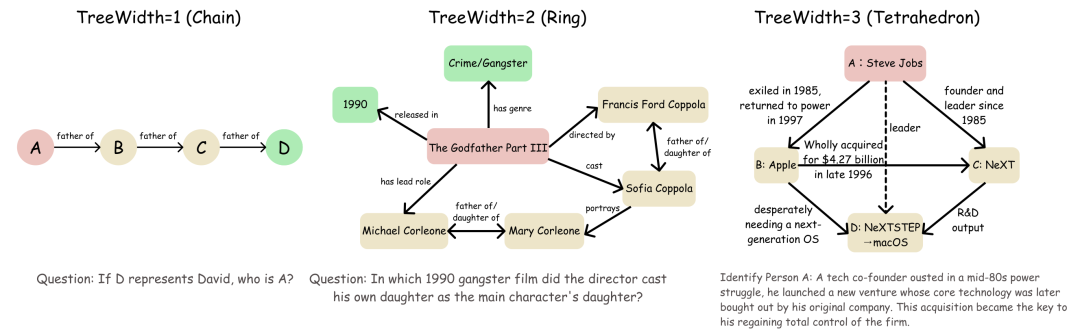
- 线性/树状(树宽=1):典型链式推理,只需按部就班检索便可解答。
- 菱形/回环(树宽=2):出现分叉与重汇合,要求智能体维持多路假设的一致性,并在发现矛盾时进行回溯。
- 强耦合子图(树宽≥3):形成网状约束,需要将零散证据拼合成一致的整体,迫使模型进行全局验证和回溯。
2. 信息分散度:杜绝搜索「捷径」
即使问题的拓扑结构很复杂,如果恰好存在一个网页包含了所有关键事实,模型一次检索就能“抄走”答案。为此,团队引入了「信息分散度」的概念,即覆盖全部关键证据所需的最小来源数。信息分散度越大,表明问题相关的证据片段在互联网上的分布就越零散,这迫使智能体与外部环境进行更多轮次的交互,从而获取更充分的信息。
02 大规模[自动化]合成[高难度]的深度搜索问题
基于上述双重约束(树宽与信息分散度)的复杂度标准,团队采用 graph-to-text 流程来自动合成数据:先生成符合指定树宽与分散度的推理图,再将其“翻译”为自然语言问题,并经过多层校验以确保其「高难度、可解且答案唯一」。
同时,团队设计了基于「结构化信息」(如维基百科)与「网络浏览」的两套图构造流程,以覆盖不同的搜索环境背景。
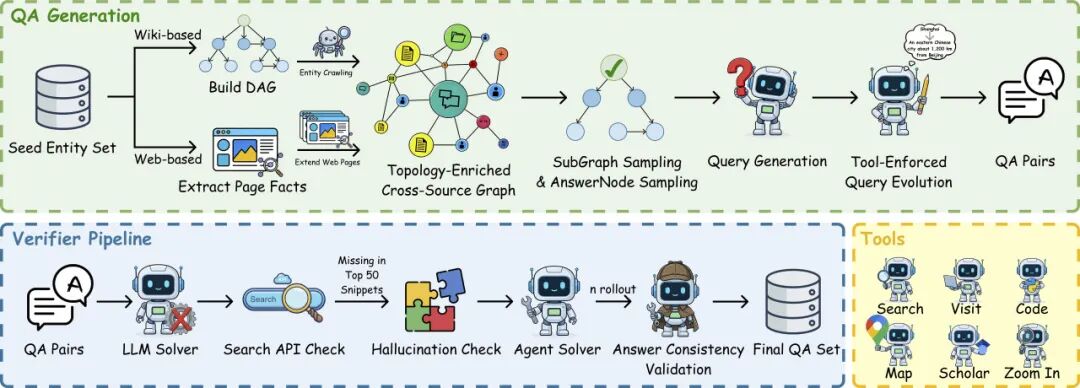
在合成问题中,团队采用了两种关键策略:
- 拓扑结构增强:直接生成高树宽图的成功率较低。为此,他们引入大模型智能体对初始依赖图进行「拓扑加密」,通过添加环状与交错约束,显著提升结构复杂度,从而迭代地提高问题难度。
- 工具增强的问题合成:在问题构造阶段,主动植入工具调用需求。通过将关键实体替换为隐含工具依赖的表达(如将具体地名替换为需要地图服务查询的描述,或将论文引用替换为需要谷歌学术搜索的表达),使得工具调用成为解题的前置条件。
03 多模态扩展:从[文本图]到[多模态图]
在纯文本合成数据的基础上,REDSearcher 通过模态注入,将纯文本推理图转化为跨模态推理图,使部分约束锚定在图像中。

- 视觉属性锚定:用图像描述替换节点的文本属性,迫使模型必须先识别图像内容,再将其与知识库关联。
- 跨模态依赖:设置视觉不可替代的约束,使得图像搜索成为推理的必经之路,而非冗余信息。
- 视觉语义抽象:使用抽象指代(如“图中所示的设备”)替代直接命名(如“iPhone 15”),迫使模型必须识别图像内容后才能进行有效搜索。
- 模态灵活插入:视觉证据可被插入推理链的任意位置,既可在早期设置瓶颈以增加难度,也可在后期引入以进行验证,实现难度的精细控制。
通过这套轻量级的扩展方法,REDSearcher 能够高效地将能力迁移至多模态搜索领域,合成高质量的图文深度搜索问题。
04 [成本可控]Mid-Training 强化智能体能力
预训练模型虽然知识渊博,但普遍缺乏多轮交互的训练,在长程搜索任务中容易出现目标漂移、重复搜索等问题。为此,REDSearcher 采用了一个可扩展的两阶段 Mid-Training 框架,依次强化模型的「原子能力」与「组合能力」,实现从语言模型到智能体的平稳过渡。
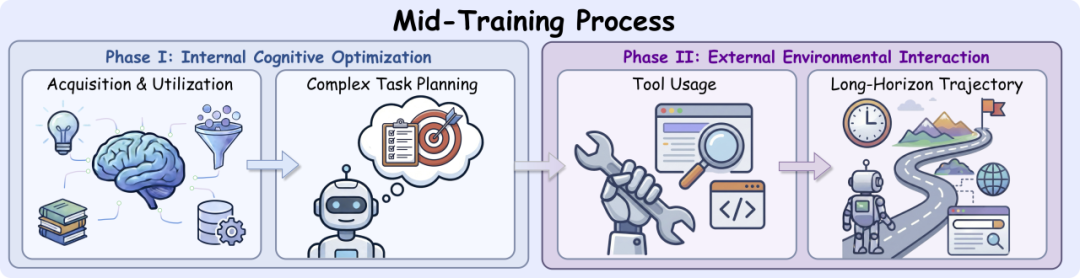
原子能力建设
针对深度搜索至关重要的两个基础能力进行优化:
- 意图锚定:训练模型从含噪的观测信息中精准抓取关键证据,过滤噪声,减少幻觉与推理漂移。
- 层次化规划:教导模型将复杂的顶层目标,拆解为可立即求解的具体子目标与需要逐步消解的不确定目标,确保每一步规划都可落地执行。
组合能力建设
通过模拟环境交互,强化模型在长程任务中的状态维持与目标一致性,全程以计算成本为约束:
- 工具调用能力:通过合成工具协议并在本地模拟环境中进行交互,使模型在 ReACT(Reasoning and Acting)范式下掌握与外界环境交互的基础能力。
- 长程交互能力:在「功能一致」的模拟搜索环境中,让智能体进行长程的、多轮次的交互,从而强化其复杂规划能力与维持目标一致性的能力。
05 后训练持续进化:不只是[搜得多]更要[搜得准]
后训练阶段采取 SFT(监督微调) + Agentic RL(智能体强化学习) 的双阶段策略进行能力增强。

- 首先,在真实搜索环境中交互,通过多重过滤机制获取长程、高质量的行为轨迹,用以教会模型如何进行深度搜索。
- 接着,在真实搜索环境中进一步通过强化学习优化策略。此阶段有两个关键设计:
- 低成本验证:构建一个「功能等价」的本地模拟环境,保持与真实API的一致性,且证据完备并包含噪声,从而大幅加速实验迭代速度。
- 数据质量保障:针对合成数据集中可能存在的答案错误、一题多解等现象,采用“智能体作为验证器(Agent-as-Verifier)”的方法,对用于强化学习的问题集进行严格校验,避免低质数据污染影响训练的稳定性。
一个有趣的发现是,团队观察到了 效率与性能同步提升 的现象。随着训练的进行,模型完成任务的平均交互轮次不断下降,但任务准确率却在持续提升。这表明 REDSearcher 并非简单地学会了“暴力搜索”,而是掌握了更精准的信息获取策略,主动减少了无效调用,形成了一个“越训练越聪明”的良性循环。
06 实验结果
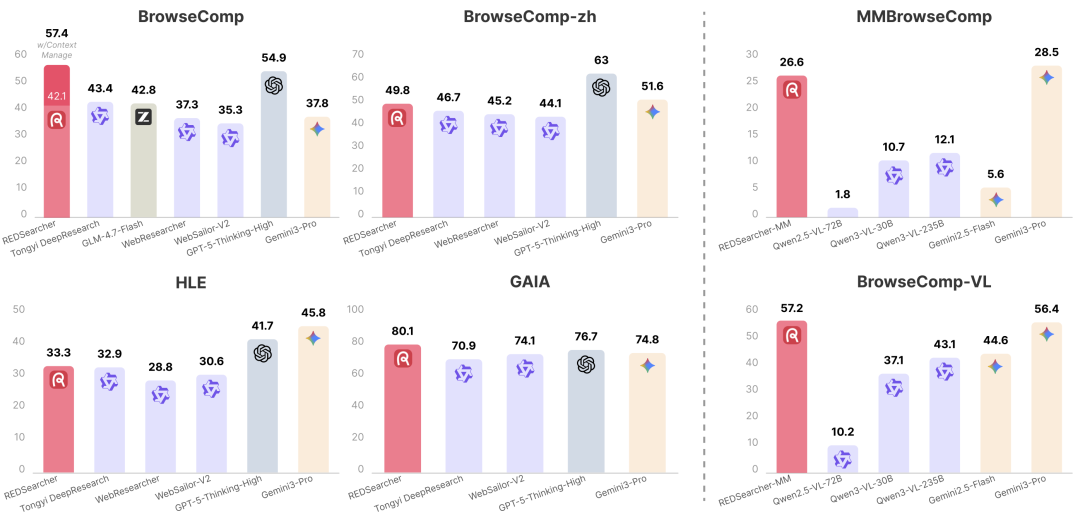
在多项深度搜索的权威基准测试上,REDSearcher 均取得了优异的表现。
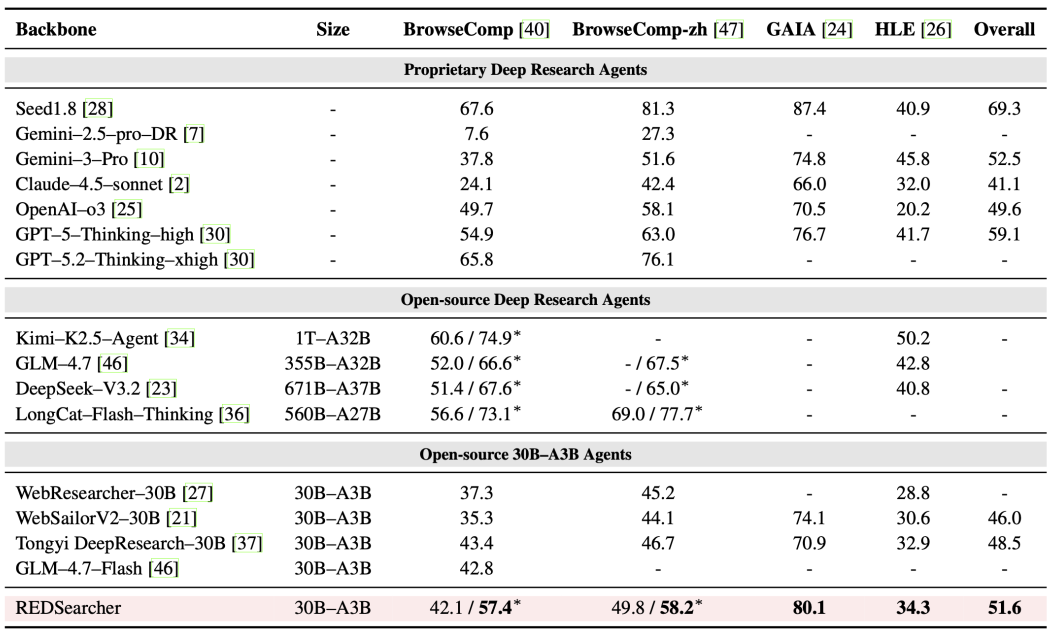
- 文本深度搜索:REDSearcher(30B)在同规模开源模型中达到了 SoTA 水平。更值得注意的是,其性能(带*号为启用上下文管理的性能)超过了 GPT-5-Thinking-high、Gemini-2.5-pro、Claude-4.5-sonnet 等一众先进的闭源模型。
- 具体而言,在 BrowseComp、GAIA 等深度搜索榜单上,REDSearcher 的表现均优于上述闭源模型。
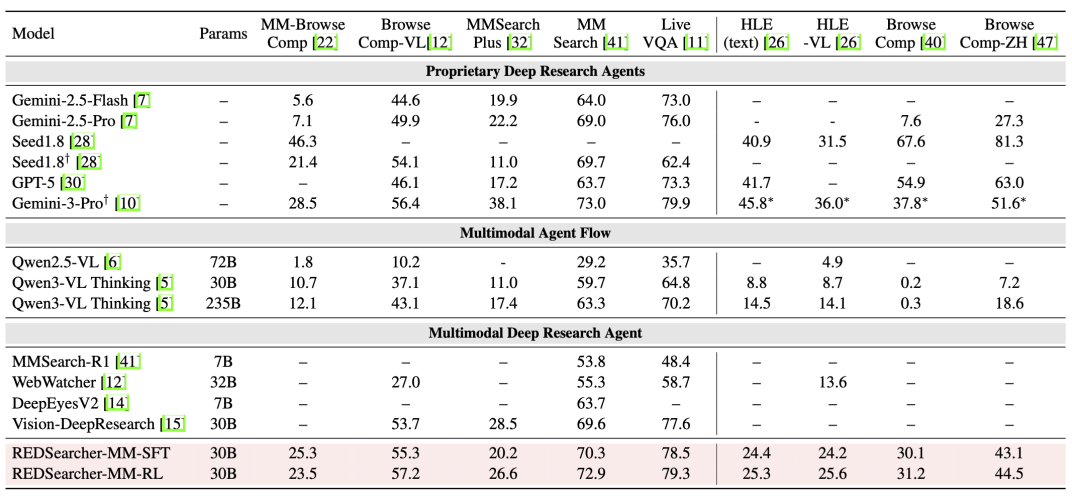
- 多模态深度搜索:REDSearcher-MM 在多模态搜索基准中,相比同参数规格的模型取得了 SoTA 水平,并且性能超过了 Gemini-2.5-pro,在部分基准上达到了接近 Gemini-3-pro 的性能。
- 详细来说,REDSearcher-MM 在五个多模态搜索基准上的性能均超过 Gemini-2.5-pro,展现出强大的多模态推理与搜索能力。
结语

REDSearcher 工作的核心价值在于其系统性设计:从图论角度严谨定义深度搜索任务的复杂度;以双重约束标准实现可扩展的高质量数据合成;通过两阶段中间训练有效降低能力迁移的成本;最后利用高质量轨迹合成结合强化学习实现持续迭代进化。
它为我们提供了一条清晰、可复现且低成本的深度搜索智能体训练路径,推动 AI 系统从静态的知识查询,迈向在开放环境下进行自主探索、验证与信息整合的新阶段。对这类前沿AI技术实践感兴趣的开发者,欢迎在云栈社区交流探讨。
团队介绍

本工作主要作者来源于小红书基础模型后训练组,其中初征是哈工大刘铭和秦兵教授的在读博士生,王枭和 Jack Hong 就职于小红书 Hi Lab。
团队致力于通过先进的后训练技术,提升模型的多元智能水平,让 AI 能够解决真实世界、真实生活中的复杂问题。团队在 Reasoning / Agent / Self-Evolving / Lifelong Learning 等方向持续推进技术边界,探索不同的后训练技术范式,旨在确保训练出的 AI 有用、可信赖、以人类为中心。
 发表于 2026-4-17 00:29:40
|
查看: 178|
回复: 0
发表于 2026-4-17 00:29:40
|
查看: 178|
回复: 0
