你好,我是花海。
我想先抛出一个核心观点:构建知识库这件事,就不该由人来主导。我坚信,在整理归档这件事上,AI 比人做得更好、更持久。人的时间和精力应该聚焦于价值更高的“判断”,而不是消耗在无穷无尽的“归档”上。
你可能会质疑:只有亲手整理过,知识才能记得牢,才能建立有效的连接。但根据我的实践,这很可能是一种错觉。

为什么你亲手搭建的笔记系统,总会陷入混乱?
我观察过太多人陷入同一个困境:收藏夹满了就开始加标签,标签乱了就创建子文件夹,文件夹层级越来越深,直到使用时根本找不到,最终无奈地再次收藏一篇新文章。
这就形成了一个死循环:收集 → 整理 → 混乱 → 放弃整理 → 知识断层。
问题真的无解吗?并非如此。问题的根源在于,我们试图用“人的逻辑”去管理信息,而人的逻辑天然不适合处理海量、无序增长的知识。每一次“整理”都是一次对抗信息熵增的努力,短期内或许有效,但长期来看,这种持续的认知消耗终将导致系统崩溃。
症结不在于工具不够强大,而在于“整理”这个行为本身就在持续消耗你的宝贵认知资源,并且其成果随时可能因信息过载而瓦解。
Karpathy 的启示:将整理工作完全交给 LLM

这个问题的颠覆性解法,可以参考 AI 领域的大神 Andrej Karpathy 分享的 LLM 知识库系统。他的分享获得了超过 4100 万浏览和 4.1 万收藏,这充分说明了需求的普遍性,绝非极客们的自娱自乐。
他的核心原则异常简洁有力:“You rarely ever write or edit the wiki manually, it's the domain of the LLM.”(你几乎从不手动编写或编辑wiki,那是LLM的领域)。
简单来说,就是人几乎不直接干预 wiki 的构建与维护,全部委托给大型语言模型。

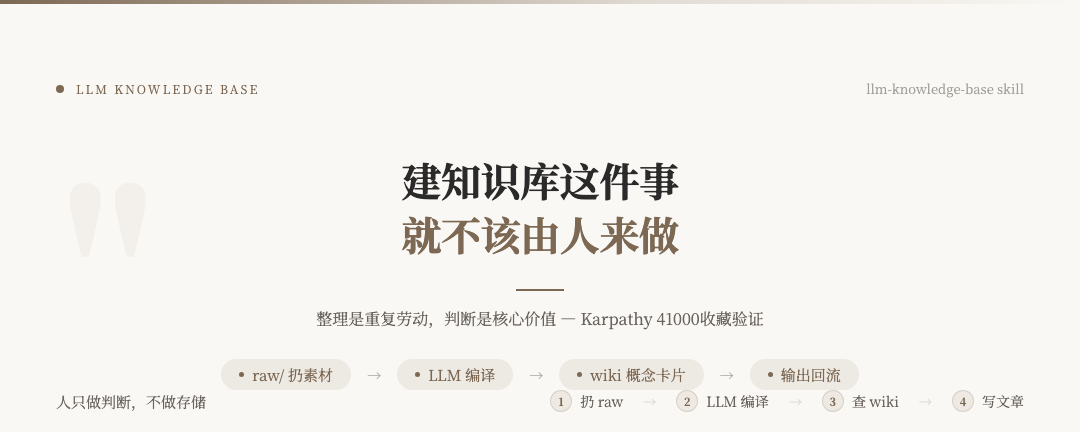
其数据流非常清晰:
- 将原始素材(文章、帖子、截图)扔进一个名为
raw/ 的目录。
- LLM 自动编译这些原始素材,生成结构化的 wiki(概念卡片)。
- 当你需要时,直接查询这个 wiki 获取答案。
- 你的输出(如写的文章)又可以作为新素材回流到
raw/ 目录,让 wiki 越来越聪明。
在这个过程中,人只需要做三件事:扔素材、查答案、基于答案创作。问题的关键从“我该如何整理”转变成了“应该由谁来负责整理”。答案是将整理的主体从人置换为 AI。
知识库存储的不是文章,而是你的判断力
可能你还有顾虑:不亲手整理,我怎么记得住?
但仔细想想,你通过整理记住的,往往是“这篇文章被我放在了哪个文件夹里”,而非知识本身。真正的记忆和学习,发生在你“使用”这个知识的时候。
例如,你读了一篇关于“内容漏斗”的文章并存入知识库。之后当你需要写相关主题时,你向知识库提问:“内容漏斗的核心逻辑是什么?”知识库会立刻为你调出相关内容。这个“调用-思考-应用”的过程,才是真正的学习,远比你当初花时间打标签、分类更有价值。
判断力生长于调用之时,而非存储之际。 一个优秀的 AI知识库 存储的并非冰冷的文章,而是你通过一次次调用和筛选所沉淀下来的判断力网络。未来讨论任何话题,你都可以有据可查,而非依赖模糊的临场回忆。
如何从0到1,快速搭建你的AI知识库?
不要追求一开始就搭建一个完美无缺的系统。Karpathy 的建议是:先跑通最小闭环,再逐步优化。在规模较小(例如少于100篇素材)时,一个维护良好的索引文件加上 LLM 的直接读取能力就足够了,不必一开始就搭建复杂的 RAG(检索增强生成)系统。
今天你就可以开始,只需四步:
第一步:建立一个 raw/ 目录
这只是一个普通的文件夹。你的任务是把所有觉得可能有用的文章、帖子、截图都扔进去。关键是:不要整理,随心所欲地扔。
第二步:选择一个 LLM 工具来管理它
例如,在 Claude Code 中有一个名为 llm-knowledge-base 的 skill。你只需给它一个主题,它就能帮你搭建好目录结构,甚至初始化一些基础内容。大约20分钟就能完成第一轮设置。
第三步:将你的历史素材“倾倒”进去
打开你的浏览器收藏夹、笔记软件,把那些标记为“以后再看”、“可能有用”的内容,全部移动到 raw/ 目录里。记住,依然不需要整理。
第四步:在需要创作时,触发自动编译
当你产生创作需求时,比如你想“我要写一篇关于XX的文章”,直接向你的 LLM 助手说出这个需求。它会自动读取 raw/ 目录中的所有新素材,将其编译成结构化的概念卡片,并更新知识索引。
看,在整个过程中,你只做了两件事:扔素材和说需求。其余繁琐的整理、归类、关联工作,全部由 AI 代劳。
最关键的思维转变:采集时不做判断
许多人无法迈出第一步,是因为他们坚信“不整理就等于没学”。这依然是一种错觉。整理是一个存储动作,而非学习动作。
把你宝贵的时间从建立复杂的文件夹结构中解放出来,投入到对知识本身的思考和判断上——判断一篇文章的核心观点是什么,它与你的其他知识如何关联,你未来可能在什么场景下用到它。这种“判断”的价值,比任何形式的“归档”都要高出百倍。
请记住这个原则:只管扔,判断留到用的时候。
希望这套基于 LLM 的知识管理理念和简单的方法,能帮助你摆脱信息整理的泥潭,更高效地构建属于你的“第二大脑”。如果你对具体的实现技巧和工具选型有更多兴趣,可以到 云栈社区 的技术讨论版块看看,那里有更多开发者分享的实战经验。
 发表于 2026-4-18 20:51:17
|
查看: 238|
回复: 0
发表于 2026-4-18 20:51:17
|
查看: 238|
回复: 0
