今天看到很多人讨论 Linux 终于要接受 AI 提交的代码了,许多人第一反应可能是“真的吗?”。作为软件开发领域的一个重要风向标,Linux 内核社区对这件事的真实态度究竟如何?
乍一看,似乎社区终于松口,允许 AI 生成的内容进入主线。相关的讨论文件确实已经公布:
https://github.com/torvalds/linux/blob/master/Documentation/process/coding-assistants.rst
然而,仔细梳理后会发现,实际情况并非如此简单。社区真正接受的,并非“AI 的输出天然可信”,而是一套更务实、更强调责任的逻辑:
你可以使用 AI 工具,但你必须像对待自己亲笔写下的代码和文档一样,对它的一切后果承担全部责任。
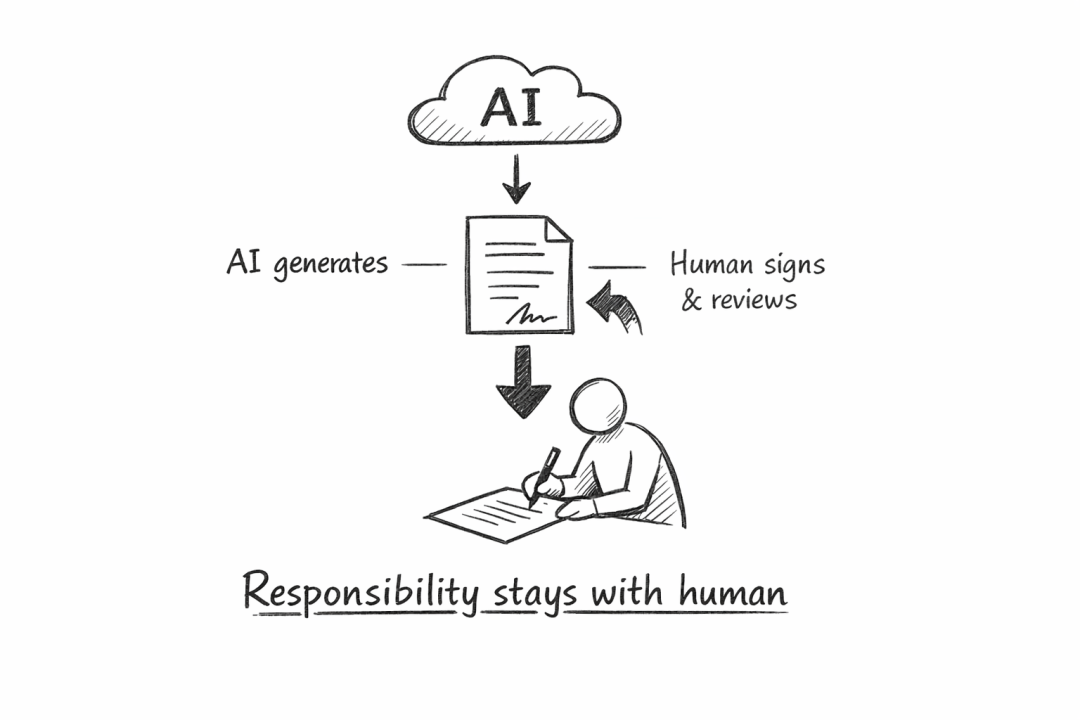
换句话说,被“招安”的不是 AI 本身,而是“将 AI 作为生产力工具”这一行为。社区从未将责任转移给模型,责任始终被牢牢地钉在人类提交者身上。
因此,如果你问“Linux 内核能否接受由 AI 辅助生成的文档、补丁说明甚至代码片段?”,答案已经相当明确:
可以。
但前提条件非常清晰且不容含糊:
提交者必须亲自审查过、彻底理解、并最终签字为其负责。
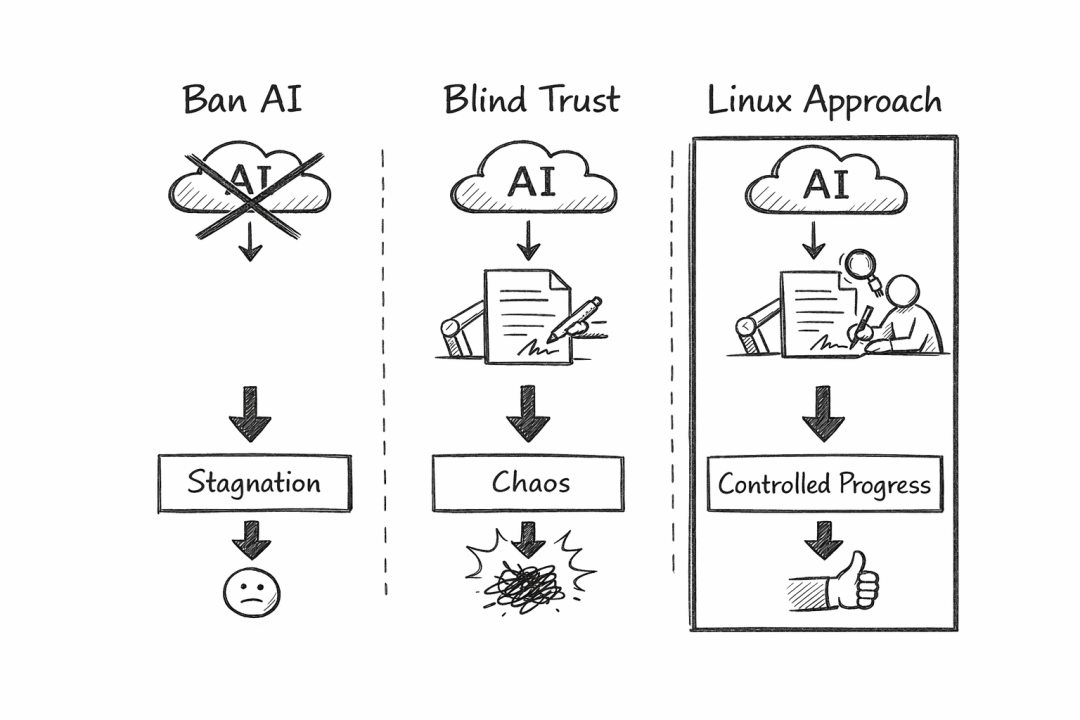
这种态度看似保守,实则非常先进。它巧妙地避开了两种常见的极端误区:
- 将 AI 视为洪水猛兽,试图彻底封杀。
- 将 AI 当作免责工具,认为“这不是我写的,是模型生成的”就能撇清关系。
Linux 社区选择了第三条道路:允许使用,但责任自负。
为什么“文档也能接受”并不意味着门槛降低
不少人存在误解,认为文档的风险低于代码,因此 AI 撰写文档更容易被放行。
这种看法有一定道理,但需要明确的是,在像 Linux 内核这样的高门槛工程社区中,文档的作用远不止“语句通顺”。它至少承担着三层核心作用:
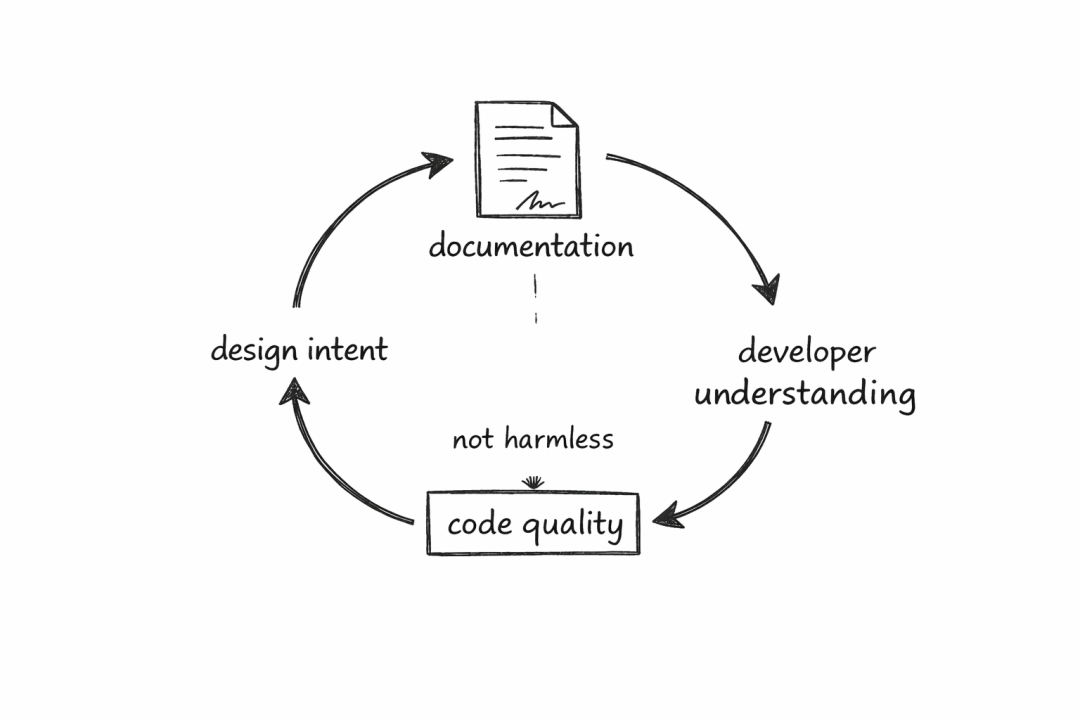
- 解释设计意图。
- 约束后续维护者的理解边界。
- 反过来影响代码审查和社区协作的效率。
这意味着,一份低质量的文档或许不会像一段坏代码那样立即导致系统崩溃,但它完全可能将技术讨论引入歧途,并逐渐抬高长期的维护成本。
因此,从治理逻辑上看,AI 撰写文档与 AI 编写代码并非两个截然不同的问题。它们共享着同一条底线:
只要内容会进入正式的社区协作流程,就必须有一个明确的人类责任主体。
这才是 Linux 社区此次态度转变中最值得玩味的地方。
社区真正关心的,从来不是“是不是 AI 写的”
如果只停留在表面,你可能会觉得争论焦点在于“是否应该标注 AI 生成内容”。
但更深层的矛盾,其实根本不在于标注本身。Linus Torvalds 的态度已经非常直白:仅靠文档规定,无法约束那些原本就不打算遵守规则的人。
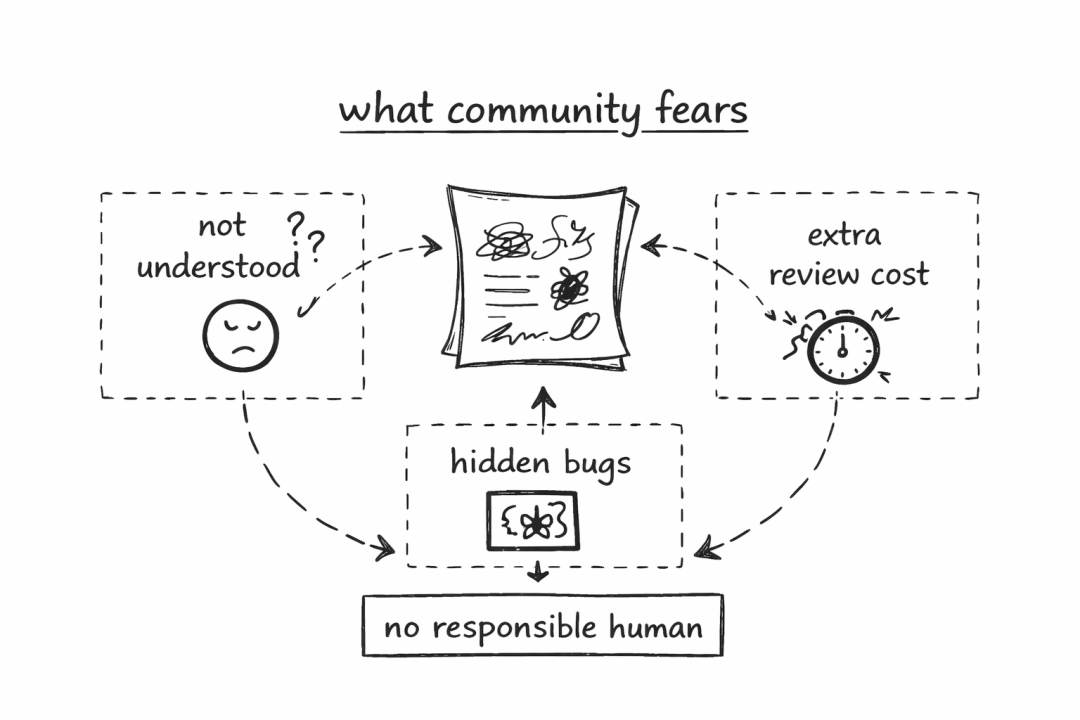
这句话的分量很重。因为一个健康的开源社区真正恐惧的,从来不是“有人使用了 AI”。社区担忧的是以下几件事:
- 提交者自己都没有理解内容就提交上来。
- AI 将旧的缺陷、错误模式甚至许可证风险重新包装后输出。
- 维护者需要额外消耗大量精力,去甄别哪些补丁和说明只是“看起来正确”。
所以,不要将这个问题简单理解为“AI 生成的文档能否被接受”。更准确的说法是:
Linux 正在接纳 AI 作为贡献流程中的参与者,但坚决拒绝任何无人负责的 AI 产出。
2021 年的恶意提交事件,为何影响至今
讨论这个问题时,无法绕开明尼苏达大学在 2021 年发生的那次恶意代码提交事件。
当时最令社区愤怒的,并非“补丁存在 bug”,而是有人故意将有漏洞的提交伪装成正常修复,并试图将这种行为包装成学术研究成果。
这件事留下了非常深远的后遗症:
- 它让社区意识到,审查机制本身也可能被利用和攻击。
- 它证明了“表面上说得通”的提交,并不代表其内在安全。
- 它使得维护者对“我本意是好的”这类解释产生了天然的不信任。
这也是为什么在今天讨论 AI 时,Linux 社区几乎本能地将责任重新锚定在“人”身上。历史已经证明:
真正危险的,往往不是工具本身,而是使用者试图借工具之名逃避本应承担的责任。
Linux 给出的治理答案,其实颇具现代性
在许多组织里,面对 AI 浪潮的冲击,第一反应往往是两个极端:要么全面禁止,要么完全放开,最终将问题甩给一线团队去解决。
Linux 没有采取这两种简单的策略。它的做法更像一套成熟工程组织的治理模型:
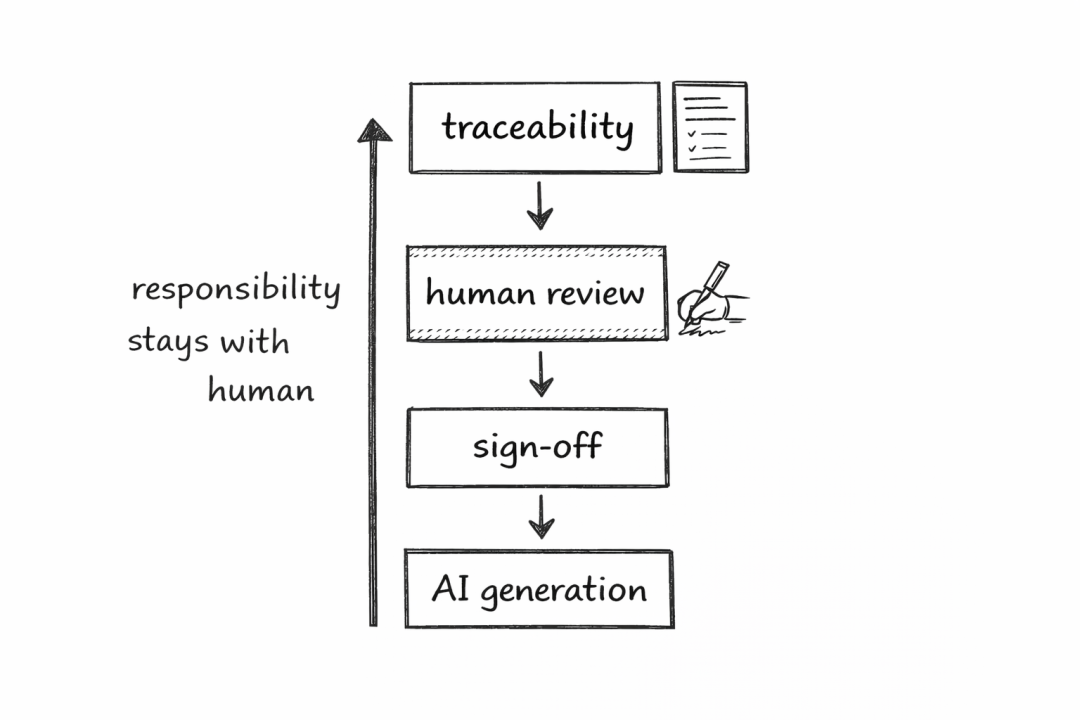
- 承认 AI 工具已经融入现实工作流这一事实。
- 不将“是否使用 AI”作为评判提交的唯一或首要标准。
- 将责任归属、签署确认、人工审查和可追溯性机制,继续牢固地落实在人类开发者肩上。
这套机制为何重要?因为它成功地将问题的焦点,从充满争议的“工具伦理”拉回到了更本质的“工程责任分配”上。而这,正是一个大型开源项目持续健康发展所必须关注的核心。
真正值得注意的变化:AI 不只在“写”,也开始在“审”
如果 AI 的角色仅停留在“帮助人类撰写补丁、说明和文档”,那这还不算真正的范式转变。
更关键的趋势在于,AI 正开始进入另一个角色:
它不再仅仅是内容生成器,也正在成为自动化审查流程中的一层。
Google 工程师开源的 Sashiko 项目就是一个典型例子。它并非用于自动提交代码,而是辅助对 Linux 内核补丁进行多阶段审查,帮助识别架构、安全、并发等方面的潜在风险。
这释放出一个重要信号:未来真正可持续的协作工作流,很可能不是“AI 写,人类被动兜底”,而是:
AI 生成一层,AI 辅助审查一层,最后由人类做出最终判断。
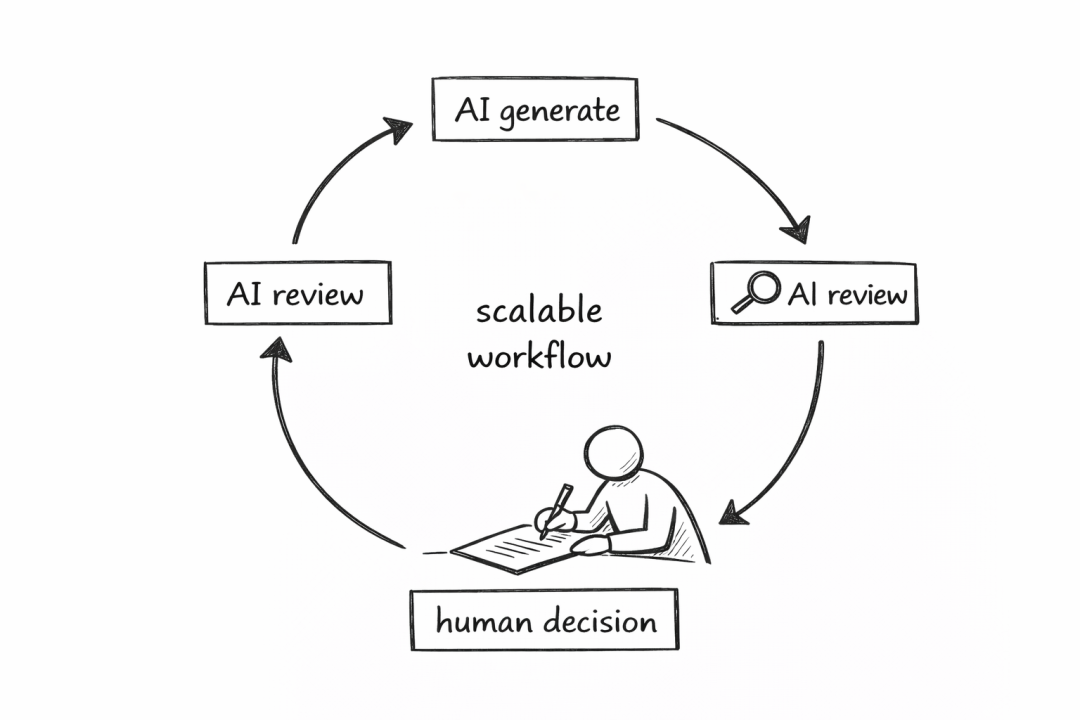
这才像一个能够规模化运行、兼顾效率与质量的现代生产体系。
对开发者而言,最现实的启示是什么?
如果你是日常使用 AI 工具的开发者,这件事实际上提供了一个非常清晰的判断标准。
未来在团队中使用 AI 辅助编写代码、注释或文档时,关键不在于“有没有用 AI”,而在于以下三点:
- 你是否亲自、彻底地审查过其产出?
- 你能否清晰解释它为何如此编写(背后的逻辑和意图)?
- 当出现问题时,这份内容是否是你愿意署名并为之负责的?
如果这三关无法通过,那么 AI 参与得越多,带来的潜在风险反而越大。
反之,如果你能严格做到以上三点,那么 AI 生成的究竟是代码、提交说明还是设计文档,其实已经不那么重要了。因为此时,它的身份就是一个纯粹的效率工具,而非内容的“作者”。
结论
所以,对于“Linux 是否可以接受 AI 生成的代码或文档?”这个问题,最准确的回答应当是:
Linux 可以接受由 AI 参与生成的内容,但绝不会接受没有明确责任主体的内容。
这句话听起来并不激进,却蕴含着巨大的工程管理智慧。它标志着一个成熟的社区不再纠缠于“AI 该不该来”的意识形态之争,而是开始认真思考并设计“AI 到来之后,责任如何划分、风险如何控制、质量如何保障”的务实方案。
这比单纯的支持或反对都更有价值。
因此,AI 进入开源社区,早已不是一个关于趋势的判断题,而是一道关乎社区治理能力的应用题。真正的分水岭,不在于谁最先用上 AI,而在于谁能率先建立起一套 人能负责、流程可追溯、风险能被有效拦截 的新型协作方式。
Linux 内核社区目前给出的,正是这样一个立足于责任与可控性的答案。
 发表于 2026-4-19 03:55:44
|
查看: 187|
回复: 0
发表于 2026-4-19 03:55:44
|
查看: 187|
回复: 0
