目录
- 一、背景
- 二、技术方案
-
- Generative Model设计细节
-
- Rerank Model设计细节
-
- 推理过程:从一级类目生成到精准召回
- 三、实验效果
-
- 核心消费指标显著提升
-
- 多样性指标改善
-
- 未来工程优化方向
- 四、总结与展望
-
- 模型能力升级
-
- 与LLM结合的可能性
-
- 多模态与跨域生成
一、背景
推荐系统在提升用户体验的同时,也面临着信息茧房、兴趣收敛和内容同质化的挑战。随着用户与系统交互的深入,“推荐→用户反馈→再推荐”的闭环会逐渐强化用户的少数主兴趣,导致推荐结果趋同,降低用户的新鲜感与满意度。
生成式AI技术的快速发展为推荐系统带来了新的机遇。与传统的判别式匹配范式不同,生成式召回通过预测用户下一个可能点击的内容,实现从“匹配已知”到“预测潜在”的范式转变。在得物社区这一潮流生活方式平台上,用户对内容多样性和新颖性的需求尤为突出,这为生成式召回的探索提供了天然的场景。
基于此背景,得物启动了生成式召回方向的一期探索,旨在为下一代智能推荐系统的构建积累经验,探索推荐系统的 scaling-law 规律。
传统召回方法的局限性与生成式召回的动机
传统判别式ANN召回的局限性
- 时序信息建模不足: 难以有效捕捉用户行为序列中的长期兴趣、短期偏好及其动态演变过程。
- 兴趣多样性受限: 基于历史行为的匹配范式容易收敛到少数高频兴趣点,难以拓展用户的兴趣广度。
- 匹配范式天花板: 判别式兴趣建模受限于已有历史数据,难以预测用户未来的、潜在的兴趣方向。
- 兴趣融合能力弱: 各兴趣点通常独立建模,缺乏对用户多兴趣间协同关系的端到端建模能力。
生成式召回的核心优势
- Next-Token Prediction 范式: 通过预测用户下一个可能点击的内容,实现端到端的用户兴趣融合建模。
- 引导式召回机制: 为生成式模型提供可控的、结构化的召回条件,确保召回内容的相关性与业务目标一致性。
- 时序依赖建模: 基于 Transformer 架构,自然捕捉用户行为序列中的时序依赖关系。
- 兴趣预测能力: 不仅能匹配已知兴趣,还能基于历史行为模式,预测用户的潜在兴趣方向。
- 端到端优化: 从用户行为序列直接生成召回结果,减少中间环节的信息损失。
- 具有 scaling-law 规律: 随着样本与模型规模的提升,能大幅提高模型的表达能力,提高线上的推荐效果。
二、技术方案
得物生成式召回系统采用 Generative Model 与 Rerank Model 联合训练的端到端设计,实现了生成与排序的协同优化。
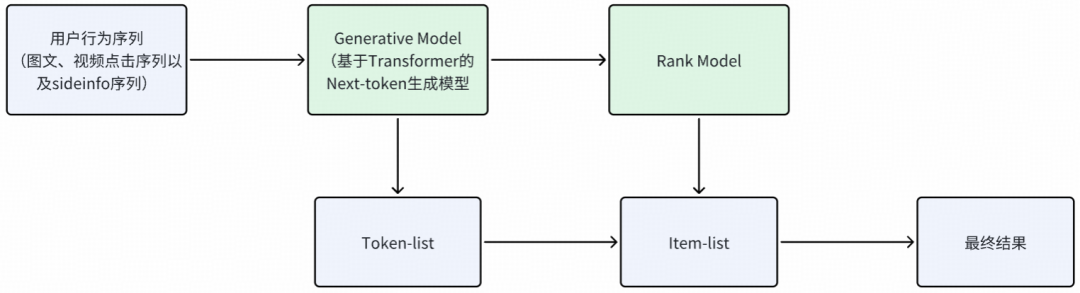
1. Generative Model设计细节
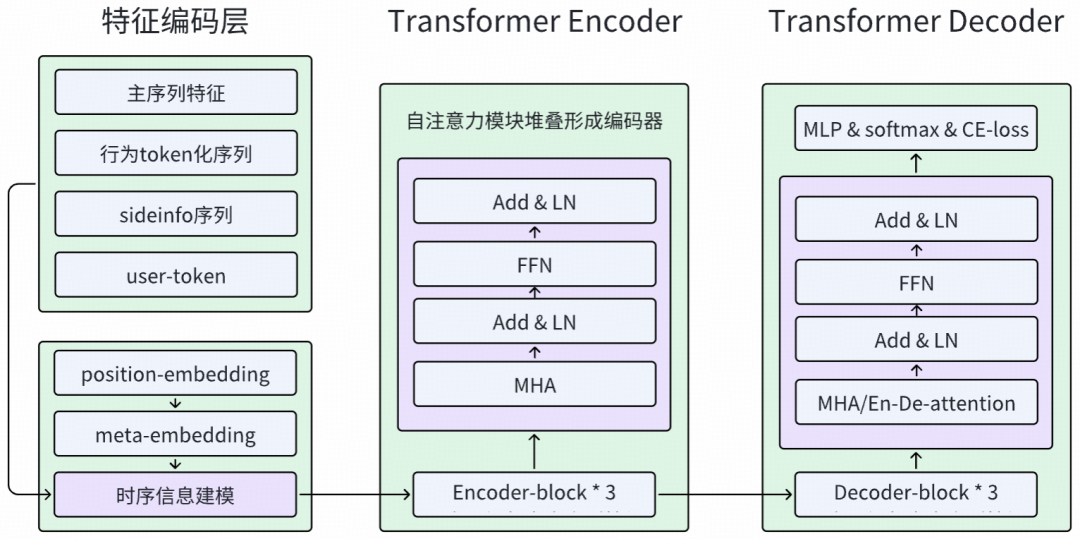
生成式模型基于 Transformer 架构实现 Next-Token 生成任务,主要特征包括:
- 主序列特征: 使用用户图文和视频的有效点击序列,以及对应的一 / 二 / 三级类目序列,截断最近 100 个行为;
- 首位 User Token 生成策略: 联合训练辅助双塔模型产出首位 user_token,通过梯度隔离机制,确保生成任务与双塔任务的独立优化;
- 模型参数配置: 采用当前 DeepRec 框架可承受的最大参数规模,配置为 n_layers=3,n_heads=4,dim=64,并加入 position embedding,增强时序建模能力。
2. Rerank Model设计细节
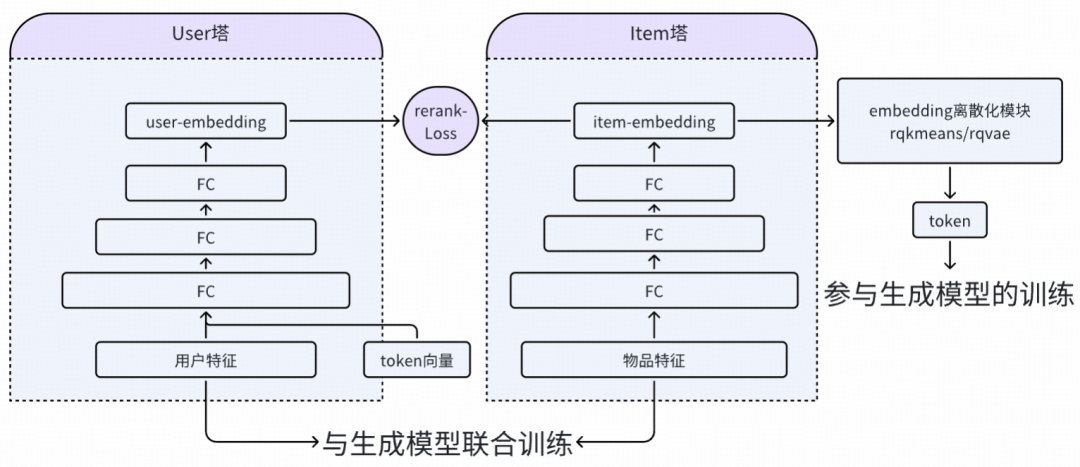
重排模型与生成式模型联合训练,通过多任务学习提升召回精度:
- 联合训练机制: 通过召回目标同时训练 rerank 模型的 item 塔与 user 塔,与 Generative Model 共享底层特征表示;
- 多任务梯度平衡: 设计合理的损失权重分配策略,确保生成任务与重排任务的梯度协同优化。
3. 推理过程:从一级类目生成到精准召回
生成式召回在线上推理时遵循“生成→向量化→检索→重排”的四步流程,兼顾了生成式模型的预测能力与向量检索的效率。
一级类目生成
推理过程首先通过生成式模块的 Decoder 生成 Top-K 一级类目。经过离线 recall@100 参数搜索对比,确定 K=4 为最优配置,在召回效果与计算成本间取得平衡。生成的一级类目作为后续步骤的 “硬条件” 向量,为多兴趣建模提供结构化引导。
多兴趣向量构造
基于生成的 K 个一级类目,通过条件双塔的 user_tower 分别得到图文和视频的 K 个用户兴趣向量。这一设计实现了兴趣解耦,每个兴趣向量专注于特定类目下的用户偏好,避免了传统单向量表示中的兴趣混淆问题。
ANN召回与Rerank排序
各兴趣向量分别进行 ANN 向量检索,从候选池中召回相关 item。召回结果再由 Rerank 模型进行精细化打分排序,最终通过蛇形 Merge 策略将多个兴趣通道的结果融合,作为最终召回列表输出。
三、实验效果
为验证生成式召回的实际效果,我们在得物社区进行了严格的AB测试。结果也带来了社区线上指标的显著提升。验证了生成式算法的在得物落地的可行性,并预示着更大的探索潜力。
1. 核心消费指标显著提升
生成式召回在多个核心消费指标上取得显著正向效果:
| 指标名称 |
相对提升(%) |
显著性 |
| 人均推荐有效VV |
+0.41% |
显著 |
| 社区DAU均时长(秒) |
+0.37% |
显著 |
| 人均推荐总时长(秒) |
+0.45% |
显著 |
| 推荐曝光UV人均内容VV |
+0.39% |
显著 |
2. 多样性指标改善
除了消费深度,生成式召回在兴趣广度拓展上也表现突出:
| 多样性指标 |
相对提升(%) |
显著性 |
| 人均点击一级类目数 |
+0.18% |
显著 |
| 人均点击三级类目数 |
+0.23% |
显著 |
| 人均曝光三级类目数 |
+0.19% |
显著 |
3. 未来工程优化方向
基于一期实践经验,后续工程优化将聚焦于:
- 框架迁移: 从 DeepRec 迁移至 DeepSea-Torch 框架,支持更大参数量与稀疏特征;
- 架构升级: 探索 One-Rec 框架落地,统一生成式与判别式召回范式;
- 推理加速: 研究模型压缩、量化等推理优化技术,进一步降低服务延迟;
- 成本优化: 通过训练策略改进和资源调度优化,降低单位效果的成本。
四、总结与展望
得物生成式召回一期实践表明,通过 “生成预测 + 引导召回” 的技术路径,可以在可控成本下,同时实现用户消费深度与兴趣广度的双重提升,为下一代智能推荐系统的构建提供了重要参考。本次实践成功验证了生成式召回在工业级推荐场景的可行性与有效性。通过 Generative Model 与 Rerank Model 的联合训练架构,实现了从判别式匹配到生成式预测的成功范式迁移。技术方案在保持推荐相关性的同时,显著提升了兴趣探索能力,为打破信息茧房提供了新的技术路径。
当前方案以一级类目作为生成目标,这是考虑到类目体系的稳定性和可解释性。下一步将基于社区样本训练 Item Embedding,并将 Item Token 离散化与用户 Next-Token 生成任务联合训练。这一演进将实现从粗粒度到细粒度的兴趣预测,提升召回的精准度。
1. 模型能力升级
通过框架迁移大幅提升模型参数量,支持大规模稀疏特征,探索更强大的生成式模型架构。具体方向包括:
- 扩展上下文窗口: 从当前的 100 行为扩展到更长序列,更好建模用户长期兴趣;
- 改进注意力机制: 研究稀疏注意力、线性注意力等高效注意力变体,平衡效果与效率。
2. 与LLM结合的可能性
借鉴得物在基于大语言模型的新颖性推荐上的经验,生成式召回可与 LLM 知识增强结合。LLM 的世界知识可以帮助识别用户潜在但未明确表达的兴趣,而生成式模型则负责将这些兴趣转化为可执行的召回策略,形成知识增强的生成式召回新范式。
3. 多模态与跨域生成
探索利用多模态信息生成更丰富的用户兴趣表示,并尝试跨业务域的生成式兴趣迁移。在得物的业务生态中,社区内容与电商商品之间存在天然关联,通过跨域生成式召回,可以实现从内容兴趣到商品需求的自然过渡,提升业务协同价值。
技术分享,重在交流与启发。 在 云栈社区 的技术论坛中,有更多关于智能推荐与算法的深度讨论,欢迎大家一同探讨生成式模型的未来。
 发表于 2026-4-19 04:54:15
|
查看: 149|
回复: 0
发表于 2026-4-19 04:54:15
|
查看: 149|
回复: 0
