1、背景
1.1 为什么要做“拍图识款”?
商品挂接是转转二手商品质检与入仓流程中的关键环节,目标是在海量SKU库中完成商品与标准SKU的匹配。传统流程主要依赖人工判断,难以兼顾效率与一致性。在规模化场景下,引入AI识款能力可快速召回Top相似候选,辅助人工完成最终判定与挂接,在保证准确性的同时显著提升效率。
与此同时,在用户侧,“拍图识款”同样是核心能力之一。用户上传包袋图片后,希望系统能够快速识别出相同或相似款式的商品,从而完成浏览与购买决策。因此,在转转的业务中,“拍图识款”主要同时服务于两个关键链路:
- 供给侧,商品挂接与入库标准化
- 需求侧,以图搜商品(同款)的搜索体验
“拍图识款”并非新问题,早在2014年淘宝推出“拍立淘”,标志着图像检索在电商场景的规模化落地。此后,各大厂均构建了基于深度学习的通用图像检索体系,比如百度的拍照识图、Google Lens等。但是,包袋这个品类中,通用方案仍存在明显局限:
- 复杂场景鲁棒性不足,真实业务中,包袋图片常包含背景干扰、局部遮挡等,导致通用模型易出现特征混淆,效果不佳
- 细粒度区分能力不足,包袋识别关键在于图案 Logo、包型、材质纹理、颜色等细节差异,通用模型在“极似款式”中的区分能力有限
- 缺乏业务闭环能力,识款能力需要全面支持 Badcase 回流、长尾款和新SKU的泛化能力等,通用模型一般难以与业务数据形成深度闭环
基于上述技术与业务约束,转转选择自研“拍图识款”系统,主要原因如下:
- 面向二手场景的专用建模能力,以包袋品类率先示范,提升细粒度表达能力与检索稳定性
- 持续支持业务闭环,支持 Badcase 驱动迭代、SKU 动态更新及效果可观测能力建设,实现模型能力与业务增长的持续演进
除此之外,在转转业务中,“拍图识款”不仅用于SKU检索,也是“拍图验真”的关键前置环节。其输出的品牌与系列信息会直接影响后续鉴定点位的选择及真假判断。一旦识款出现偏差,误差将在AI鉴定链路中逐步放大,最终影响整体准确性。
1.2 “拍图识款”的本质
用户拍摄一张或多张商品图片后,“拍图识款”算法的目标,是在标准 SKU 库中检索出最相似的图片,并基于其已知 SKU 信息,反推出输入图片对应的SKU。这一过程本质上就是典型的以图搜图(Image Retrieval)任务。
从技术角度来看,该问题可以抽象为一个图像相似度学习问题:对于同一SKU 的不同商品图片,其特征向量在特征空间中的相似度应尽可能高,通常使用“余弦相似度”进行度量(值越接近 1 表示越相似);而对于不同 SKU 的商品图片,其特征相似度则应被显著拉开,从而在检索空间中形成清晰的判别边界。围绕这一目标,“拍图识款”系统通常由三个核心模块构成:
- 主体目标检测:从复杂背景中定位并裁剪主体区域,降低背景噪声干扰
- 图像关键特征提取:将视觉信息编码为“高维向量”表示,是决定识别上限的关键模块
- 向量检索系统:基于海量 SKU 向量库进行高效近邻搜索,实现 Top-K 相似SKU召回
其中,图像关键特征提取是整个系统的核心瓶颈与效果上限决定因素,直接影响识款的准确性与稳定性。其本质是为每一张图片构建一套可用于机器理解与比对的“数字指纹”,实现对视觉信息的压缩表达与语义编码。
转转图像算法团队,以包袋品类作为拍图识款示范,我们发现,包袋图片中隐藏的视觉信息并非无序分布,而是呈现出一套由粗到细的多层次特征体系:
- 图案 Logo:决定品牌归属,是快速收敛候选范围的首要信号
- 包型(形状):定义基础款型类别,是识别的“骨架级特征”
- 材质与纹理:反映工艺与版本差异,是重要的细粒度补充信号
- 五金刻印:提供高区分度信息,用于区分同系列的不同款式
- 颜色:用于区分配色或限定版本
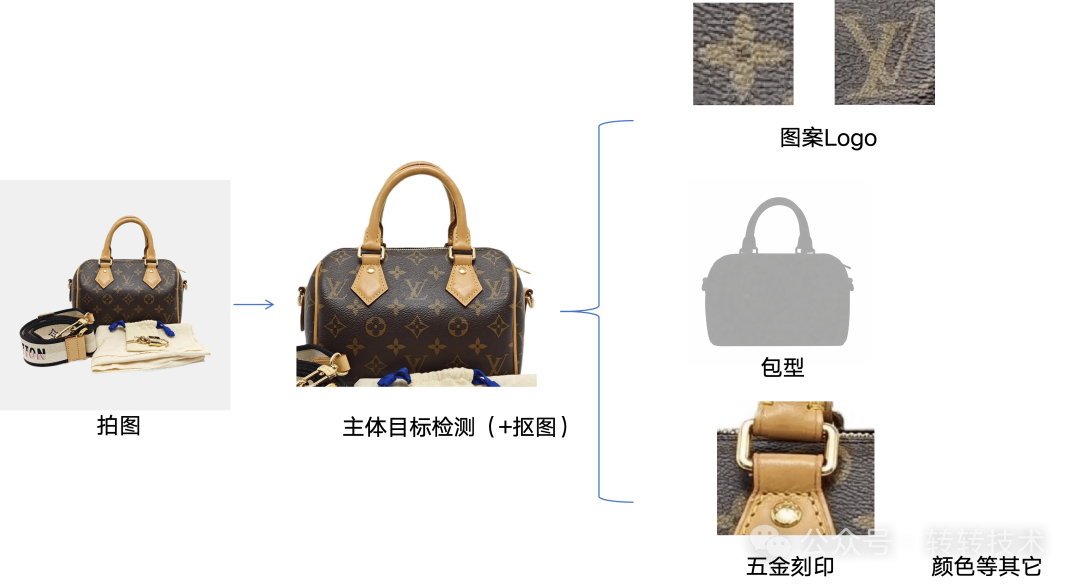
这些信息从整体到局部逐级展开,形成一个稳定的层次化视觉表征体系,共同构成包袋的“数字指纹”。因此,一个高质量的图像特征提取模型,本质上并非单一视觉因素的编码,而是对图案Logo、包型、五金刻印等多种视觉信号进行融合建模后的综合表达结果,其目标是在压缩信息的同时最大化类别可分性与检索稳定性。
2、技术方案选型
2.1 主流技术方案
拍图识款的主流技术路线,主要分为两类:分类模型和检索模型。
由于包袋品类具有明显的“长尾特征”,SKU 规模达到“百万量级”,若采用分类方案,本质上会面临类别空间过大、类别不均衡以及泛化能力不足等问题,因此整体效果很差。当前工业界主流方案,已基本统一为以检索模型为核心的技术架构[1],如下图所示。

从系统角度来看,拍图识款的效果主要受两方面因素影响:一是图像关键特征向量的表达质量,二是大规模向量库的检索效率与召回能力,本篇主要围绕前者展开。
在图像特征向量学习层面,对比学习(Contrastive Learning) 是当前主流技术范式之一。该方法通过拉近同类样本、拉远异类样本,在特征空间中构建具有判别能力的表示。在转转的多个业务场景中,对比学习已得到广泛应用。
- 在风控业务中,采用基于 CLIP[2] 的对比学习模型,结合 Milvus 向量检索系统,实现风险图片样本的高效召回与匹配
- 在搜推业务中,基于双塔(Siamese / Two-Tower)结构的对比学习方法,将商品图片映射为向量表示,用于推荐系统召回模块,在线上带来了超过 10% 的下单提袋率提升
- 在质检业务中,通过引入自监督对比学习思想,数据增强自动构建正负样本对,在弱监督标注的情况下提升多种图像模型的泛化能力与细粒度识别能力
总体来看,对比学习已成为图像表征学习中的基础方法之一,并在转转不同业务线中承担统一的“视觉语义对齐”能力。
2.2 转转技术方案:度量学习
度量学习(Metric Learning) 与对比学习本质上都属于“表示学习”范式,核心目标都是学习一个Embedding(向量表示)空间,使得相似 SKU 在特征空间中距离更近,不相似 SKU 距离更远。但二者在监督信号与优化目标上存在明显差异:
- 对比学习通常以自监督或弱监督为主,通过数据增强等方式构造正负样本对,学习的是通用视觉表征能力,其核心目标是提升表示质量与泛化能力。
- 度量学习则更依赖显式标签监督,通过构造样本间的距离约束,直接优化“类间可分性”与“类内紧致性”,本质上是在 Embedding空间中学习更清晰的判别边界,对细粒度识别任务更为敏感、可靠。
在包袋拍图识款场景中,这种差异显得尤为明显。
对于大量“外观极其相似”的 SKU,仅依赖通用表征学习的对比学习方法,容易出现特征聚合不充分的问题,而基于度量学习的方法则能够通过“强监督信号”,显式拉开细粒度 SKU 间的边界,从而获得更稳定的判别能力。此外,转转在包袋品类中积累了海量的“高质量”、“带SKU标签”的商品图片数据,使得基于监督信号的度量学习具备良好的数据基础。综合业务特性与数据条件,最终我们选择以“度量学习”为主的技术路线,打造转转拍图识款系统。
3、“拍图识款”在转转的进阶实践
3.1 整体架构设计
转转“拍图识款”系统整体采用检索式视觉理解架构,整体架构设计如下:
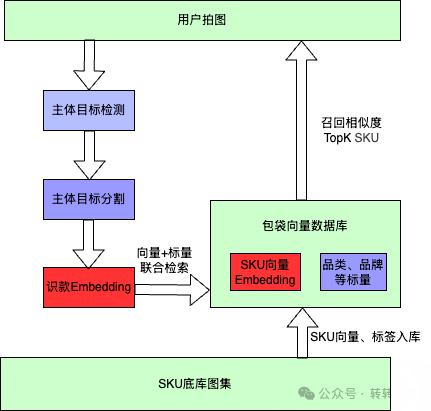
用户上传商品图片后,系统首先通过主体目标检测与分割模块,从复杂背景中提取出包袋主体区域,以降低环境噪声对特征表达的干扰。随后,主体区域进入特征提取模块,通过识款 Embedding 网络将图像编码为“高维向量”表示,完成从“像素空间”到“语义向量空间”的映射。在向量空间中,系统通过与包袋向量数据库进行相似度检索,实现 Top-K 候选 SKU 召回。向量数据库中同时存储SKU Embedding 与 SKU 结构化属性信息,用于后续相似图片匹配与结果约束。最终,实现“以图搜图 → SKU 识别”的完整闭环链路。
在“拍图识款”整体链路中,为了提升复杂真实场景下的检索效果,我们在系统设计上重点做了三点优化:
1)主体目标检测 + 分割增强的双阶段建模
为降低背景干扰,系统首先需要具备对图像中主体目标的定位能力,并提取稳定的主体特征表示。但在实际实验中我们发现,仅依赖目标检测仍不足以应对复杂场景(如背景复杂、遮挡严重等)。因此,在检测模块之后进一步引入一个轻量级目标分割模型(segmentation model),对主体区域进行更精细的边界提取,从而显著提升特征纯度与识别稳定性。
2)依赖大规模 SKU 底库的长尾覆盖能力
拍图识款的效果,在很大程度上由 SKU 底库的规模与质量决定。SKU 种类越丰富、单SKU数量越多,模型在检索阶段的可匹配空间越完整。这一点正是转转在二手奢侈品领域中的核心优势之一,依托长期积累的真实交易数据与商品沉淀,构建了高覆盖度的 SKU 标准数据库,从而提升了整体识别的召回能力与长尾覆盖能力。
3)向量库的“向量 + 标量”联合检索机制
在检索系统设计上,我们不仅依赖图片向量的相似度,同时引入 SKU 结构化属性(标量信息),构建向量 + 标量的联合检索框架。
- 向量检索,负责根据图片相似度召回
- 标量检索,包括品类、品牌、系列等,负责约束检索空间
通过两者结合,可以在保证召回效率的同时,提高结果的业务一致性与可解释性。高效的大规模向量检索是此类系统的关键,实践中我们采用了像 Faiss 这样的高性能库来完成这一任务。
3.2 度量学习训练
基于度量学习的包袋拍图识款,是在百万量级包袋 SKU 中完成高精度检索匹配,主要包括数据构建与挖掘、模型训练及工程优化三个方面。
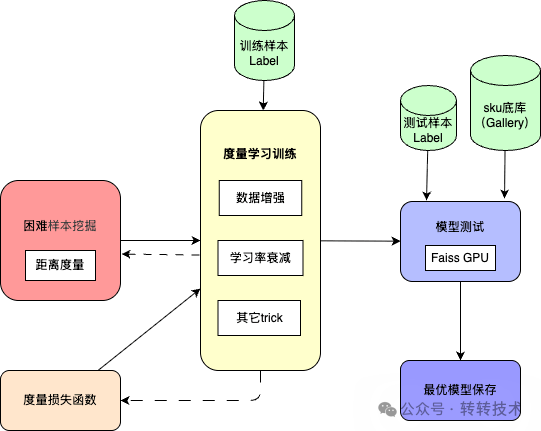
3.2.1 数据构建与挖掘
1)度量学习Scaling Law
实验表明,识款模型性能与度量学习的训练数据规模呈显著正相关关系,构建百万量级 SKU + 单SKU多视角图像的训练集是模型性能的基础。
2)Badcase 驱动的数据增强
与通用数据增强方法不同,本文采用基于误判样本(Badcase)的定向优化策略:
- 收集模型高频误判样本对
- 分析误判原因(遮挡、光照、角度等),构造针对性增强数据
该方法显著提升了模型在复杂场景下的鲁棒性。
3)困难样本挖掘
在每个 batch 内进行在线困难样本挖掘(Online Hard Mining)[3],该策略使模型重点优化最易混淆的样本对,从而提升整体区分能力。
训练过程中采用 Anchor-Positive-Negative(APN)结构,Anchor(当前样本)、Positive(同 SKU 样本)、Negative(不同 SKU 样本)。其中,Negative 样本采用相似样本挖掘策略,以增强模型对细粒度差异的判别能力。
3.2.2 模型训练trick
1)相似度函数选择
采用 Cosine Similarity 作为相似度度量,其优势包括:对特征尺度不敏感、在高维空间中更稳定及向量归一化兼容等
2)学习率调度策略
采用逐步衰减(Learning Rate Decay)策略,初期使用较大学习率,加速收敛;后期使用较小学习率,精细优化 Embedding 空间。该策略有助于提高模型在细粒度区分任务中的性能。
3)度量学习损失函数
采用典型度量学习损失函数(如Triplet Loss[4]/Circle Loss[5]),该类损失直接优化样本之间的距离关系,相较于分类损失函数,更适用于大规模类别场景。
3.2.3 工程优化
1)推理服务优化
采用模型服务框架torchServe进行部署,实现多实例并行推理、批量请求处理,从而满足线上高并发需求。
2)向量检索加速
基于 Faiss 构建离线向量测试库,使用Faiss-GPU 版,在百万量级SKU底库数据下,实现30—50倍检索效率加速,便于快速筛选最优模型
3)索引更新机制
为适应动态数据增长,系统支持增量索引更新。为平衡实时性与系统开销,我们采用“小时级”更新策略。
4)阈值动态调整
在实际应用中需对 Cosine 相似度进行归一化处理,将相似度分数映射到[0,1]之间(原始范围 [-1, 1]),业务可根据需求动态调整相似度阈值。
3.3 落地成果
主要落地场景有转转商品挂接、转转APP拍图识款(回收业务)等
1)转转商品挂接页面
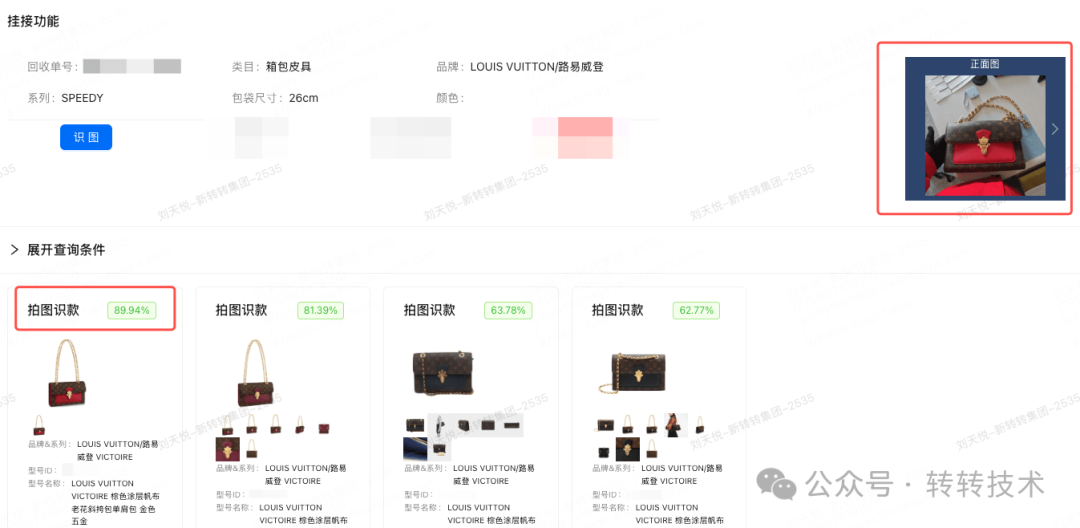
2)转转APP拍图识款页面
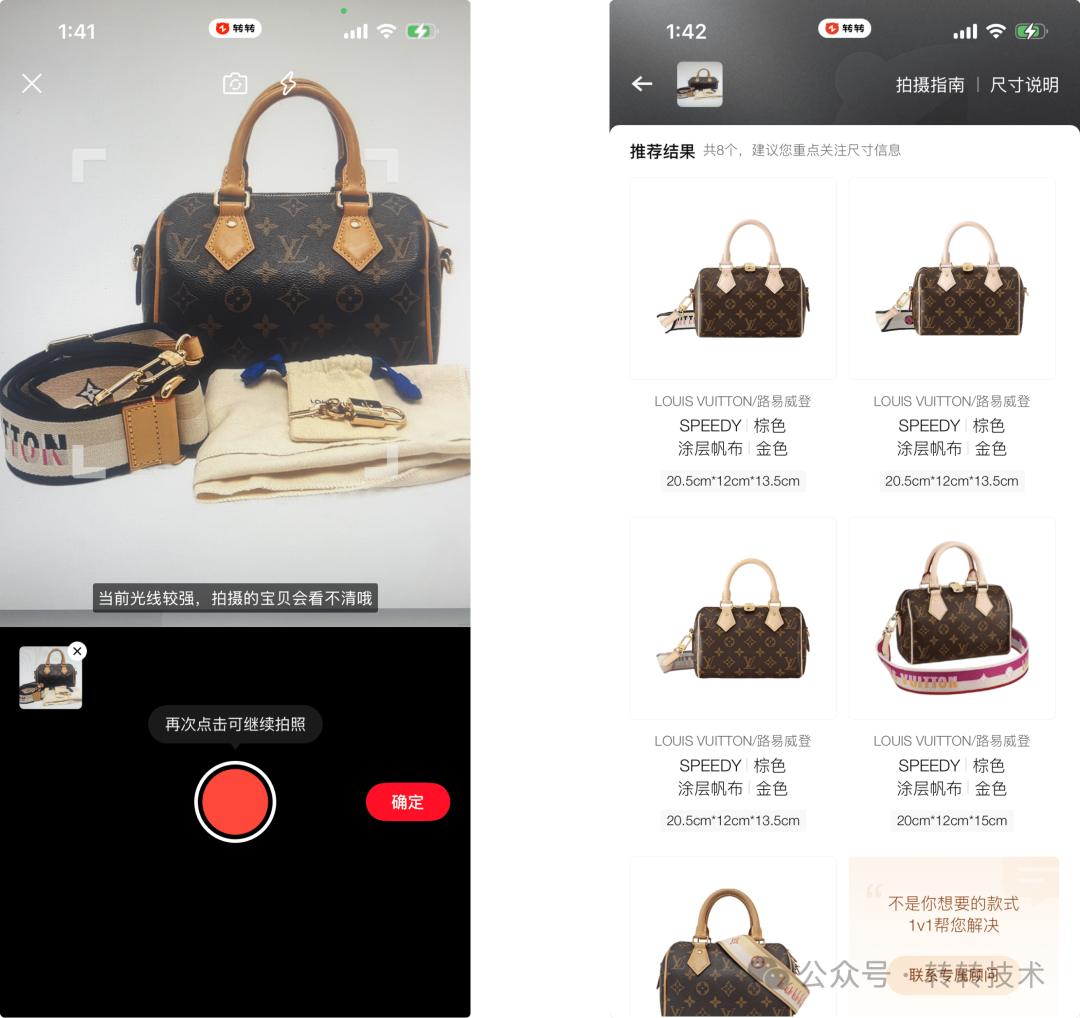
在拍图识款效果评测中,自研模型在Top-4准确率,超过三方8%以上,特别在复杂背景图片上要明显好于三方(一线业务反馈)。
3.4 可改进点
当前包袋拍图识款仍存在“尺度无法识别”问题,由于缺乏参考物,不同拍摄条件下的包袋尺寸(大中小号)难以统一建模,后续可引入标准参照物或显式尺度建模。此外,细粒度差异主要集中在五金、纹理等局部区域,需增强局部特征建模能力,未来可进一步探索多模态识款方法,引入文本与结构化属性信息,实现“图+文”联合检索。关于多模态融合的探索,也是当前人工智能领域的一个重要研究方向。
4、总结
“拍图识款”本质是以图搜图,通过主体检测、特征提取与向量检索,在海量SKU数据库中完成“款式匹配”。其核心在于学习图像Embedding,构建细粒度SKU图片的“数字指纹”。在包袋场景中,需融合图案Logo、包型、材质纹理、颜色与五金等特征,实现多层次表达。相比分类方案,检索方案更适合大规模长尾SKU。转转采用以“度量学习”为核心的技术方案,通过监督学习“类内紧致性”与“类间可分性”,并结合困难样本挖掘,提升细粒度识别能力。在工程层面,结合TorchServe与增量索引更新机制,实现高效线上服务。整体技术方案已在转转商品挂接与C端识款等场景落地,未来将探索多模态融合以提升识别效果。如果你对图像检索或相关技术有更深入的探讨兴趣,欢迎来 云栈社区 交流分享。
参考资料
[1] Deep Ranking for Image Similarity.
[2] Radford A, et al. Contrastive Language–Image Pre-training (CLIP).
[3] Hermans A, et al. In Defense of the Triplet Loss for Person Re-Identification.
[4] Schroff F, et al. FaceNet: A Unified Embedding for Face Recognition and Clustering.
[5] Wang W, et al. Circle Loss: A Unified Perspective of Pair Similarity Optimization.
 发表于 2026-4-19 04:57:34
|
查看: 242|
回复: 0
发表于 2026-4-19 04:57:34
|
查看: 242|
回复: 0
