大家在啃 Linux 内核源码的时候,有没有注意到一个细节:很多链表、指针后面都带着一个 __rcu 后缀?比如 struct list_head __rcu *next; 或者 rcu_dereference() 这类 API。
今天,我们就来把 RCU(Read-Copy Update)这个机制彻底讲明白。
RCU 到底是什么?
RCU 全称 Read-Copy Update,直译过来就是 “读-拷贝-更新”。
它的核心思想非常简单:读者可以随意读取数据,开销几乎为零;写者想要修改数据时,先拷贝一份副本,在副本上修改完成,再一次性将指针指向新数据。
为什么要这样设计?因为在 Linux 内核中,存在大量 读多写少 的场景。例如:
- 文件系统里频繁的目录查找(读);
- 路由表查询(读);
- 系统调用审计、SELinux AVC、dcache 等等。
传统的读写锁(rwlock)在读操作频繁时,会让所有读者排队等待,性能很差。RCU 则完全消除了读端的锁竞争,允许多个读者同时读取,甚至允许读者和写者并发执行(写者只需自己处理好同步即可)。
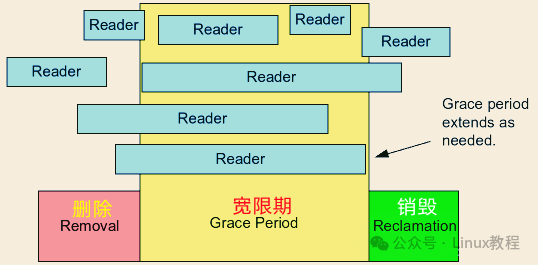
读到这里,你可能会有很多疑问:RCU 怎么做到的这么高效?写数据的时候读数据真的不用等吗?有了读写锁为什么还需要 RCU?别急,下面这张图能帮你直观理解它的核心流程。
内核的官方文档在 Documentation/RCU/ 目录下非常齐全,其主要实现者 Paul E. McKenney 也撰写了大量文章。想要深入研究的同学可以直接去查阅内核源码。
RCU 解决了哪些难题?
RCU 在设计时重点解决了三个关键问题:
-
读者正在读的时候,写者删除了节点
写者可以将节点从链表中移除,但不能立刻释放其内存。必须等到所有读者都读完(即度过宽限期 Grace Period)后才能安全销毁。这就是 RCU 的“延迟释放”机制。
-
读者正在读的时候,写者插入了新节点
需要保证读者看到的节点是完整初始化的。这里利用了发布-订阅机制(Publish-Subscribe),依靠内存屏障来保证写入的可见性。
-
链表遍历不能因为增删而断链
RCU 保证遍历过程不会从中间断开,但不保证一定能读到最新的节点(这也是它与普通锁的一个重要区别)。
用一句话总结就是:RCU 让读者几乎无感知,而将所有的复杂性交给了写者来处理。
RCU 原理剖析
你可以将 RCU 看作读写锁的升级版,但更为激进:
- 读者:开销极低。无需加锁、无需原子指令(除了 Alpha 架构外甚至不需要内存屏障),也不会导致死锁。
- 写者:需要拷贝副本 -> 修改副本 -> 注册回调 -> 等待宽限期 -> 最终完成替换或释放。
Grace Period(宽限期) 是 RCU 的灵魂。它指的是 “所有 CPU 都至少经历了一次上下文切换(即进入 Quiescent State,安静状态)” 的一段时间。
为什么用上下文切换来判断?因为 RCU 的读端要求 读者在临界区内不能被调度(rcu_read_lock 期间会关闭抢占)。一旦发生了上下文切换,就说明该 CPU 上的读者已经安全退出了临界区。
内核会维护每个 CPU 的变量来标记它们是否经历过一次安静状态。写者挂起回调后:
- 重置所有 CPU 的标记为 0;
- 每个 CPU 经历一次上下文切换后,将自己的标记设为 1;
- 当所有 CPU 的标记都变为 1 后,唤醒写者,执行其回调(如释放内存)。
一个简单的例子看穿本质
我们先来看内核文档 whatisRCU.txt 中的一个经典例子(保护一个全局指针):
struct foo {
int a;
char b;
long c;
};
DEFINE_SPINLOCK(foo_mutex);
struct foo *gbl_foo;
void foo_read(void)
{
struct foo *fp = gbl_foo; // 普通读(后续会改成 rcu 版)
if (fp != NULL)
dosomething(fp->a, fp->b, fp->c);
}
void foo_update(struct foo *new_fp)
{
spin_lock(&foo_mutex);
struct foo *old_fp = gbl_foo;
gbl_foo = new_fp; // 指针切换
spin_unlock(&foo_mutex);
kfree(old_fp); // 危险!读者可能还在使用 old_fp
}
如果去掉自旋锁,直接并发更新,就会出现 释放后使用(use-after-free) 的严重 Bug。用 RCU 改造后如下(注意关键变化):
void foo_read(void)
{
rcu_read_lock(); // 声明进入读临界区
struct foo *fp = gbl_foo;
if (fp != NULL)
dosomething(fp->a, fp->b, fp->c);
rcu_read_unlock(); // 声明退出读临界区
}
void foo_update(struct foo *new_fp)
{
spin_lock(&foo_mutex);
struct foo *old_fp = gbl_foo;
gbl_foo = new_fp;
spin_unlock(&foo_mutex);
synchronize_rcu(); // 等待所有读者退出!
kfree(old_fp);
}
RCU 允许多个读者并发,也允许读者和写者并发,但多个写者之间仍然需要锁来同步(这里使用了 spin_lock)。这正是在复杂后端 & 架构中常见的设计权衡。
RCU 核心 API
rcu_read_lock(); // 进入读临界区(关闭抢占)
rcu_read_unlock(); // 退出读临界区
synchronize_rcu(); // 写者等待宽限期(核心阻塞点)
rcu_assign_pointer(); // 写者安全发布新指针(带内存屏障)
rcu_dereference(); // 读者安全解引用(带内存屏障)
接下来我们看看它们在链表操作中的实际应用。
链表上的实战示例
6.1 增加链表项
内核中增加 RCU 链表项的典型代码如下:
#define list_next_rcu(list) (*((struct list_head __rcu **)(&(list)->next)))
static inline void __list_add_rcu(struct list_head *new,
struct list_head *prev, struct list_head *next)
{
new->next = next;
new->prev = prev;
rcu_assign_pointer(list_next_rcu(prev), new); // 关键发布操作
next->prev = new;
}
这里的 __rcu 后缀是给 Sparse 静态分析工具使用的标注,它强制开发者必须使用 rcu_dereference() 来访问这些被标记的指针。
重点看 rcu_assign_pointer():
#define __rcu_assign_pointer(p, v, space) \
({ \
smp_wmb(); // 写内存屏障
(p) = (typeof(*v) __force space *)(v); \
})
为什么需要内存屏障?
CPU 的乱序执行可能导致:新节点的 next 和 prev 指针还没初始化完,这个新节点就被读者看到了!内存屏障确保了 new->next、new->prev 的写入先完成,然后再将新节点的指针“发布”出去。
注意:如果多个线程同时执行添加操作,仍然需要额外的自旋锁(如 spin_lock)进行保护。
6.2 访问链表项
标准的读取模式:
rcu_read_lock();
list_for_each_entry_rcu(pos, head, member) {
// 对 pos 进行操作
}
rcu_read_unlock();
list_for_each_entry_rcu 内部最终会调用 rcu_dereference():
#define __rcu_dereference_check(p, c, space) \
({ \
typeof(*p) *_________p1 = (typeof(*p)*__force )ACCESS_ONCE(p); \
rcu_lockdep_assert(c, "suspicious rcu_dereference_check() usage"); \
rcu_dereference_sparse(p, space); \
smp_read_barrier_depends(); // 读依赖屏障
((typeof(*p) __force __kernel *)(_________p1)); \
})
在 Alpha 这类弱内存序架构上,这条屏障防止编译器或 CPU 的推测优化导致乱序;在 x86/ARM 等强内存序架构上,它通常是空实现(无性能损耗)。
读临界区的全局可见性:只要系统中还有一个读者处于 rcu_read_lock() 保护区内,synchronize_rcu() 调用就会阻塞,直到所有读者退出。这就是宽限期最直观的体现。
6.3 删除链表项
p = search_the_entry_to_delete();
list_del_rcu(p->list); // 仅从链表逻辑上移除,不释放内存
synchronize_rcu(); // 等待宽限期结束
kfree(p);
list_del_rcu() 的源码很简单:
static inline void list_del_rcu(struct list_head *entry)
{
__list_del(entry->prev, entry->next);
entry->prev = LIST_POISON2; // “毒化”指针,防止后续误用
}
6.4 更新链表项
p = search_the_entry_to_update();
q = kmalloc(sizeof(*p), GFP_KERNEL);
*q = *p; // 完整拷贝原数据
q->field = new_value; // 在副本上修改
list_replace_rcu(&p->list, &q->list); // 安全替换
synchronize_rcu();
kfree(p); // 延迟释放旧版本
list_replace_rcu() 内部同样使用 rcu_assign_pointer() 进行安全的指针替换。
实战:RCU 在系统调用审计中的应用
场景一:只有增加/删除(最常见、最容易转换)
原来使用读写锁的读端:
read_lock(&auditsc_lock);
list_for_each_entry(e, &audit_tsklist, list) { ... }
read_unlock(&auditsc_lock);
改成 RCU 后:
rcu_read_lock();
list_for_each_entry_rcu(e, &audit_tsklist, list) { ... }
rcu_read_unlock();
写端原来用 write_lock,现在只需把 list_add/list_del 换成 _rcu 版本(如 list_add_rcu),并使用 call_rcu() 进行异步内存释放(这比 synchronize_rcu() 更高效,不会阻塞写者)。
场景二:需要修改链表条目内容
必须遵循“拷贝-修改-替换”流程:先拷贝 -> 修改副本 -> list_replace_rcu() -> 最后用 call_rcu() 释放旧条目。
场景三:不能容忍旧数据(要求立即可见)
可以在每个链表条目中增加一个 deleted 标志位,并配合条目自己的自旋锁:
- 读端在遍历时检查
if (e->deleted),如果为真则立即跳过。
- 写端删除时,先标记
deleted = 1,然后再执行 list_del_rcu() + call_rcu()。
总结
RCU 是 Linux 2.6 内核引入的重量级同步机制,用好它,内核性能能上一个大台阶。
优点:
- 读端开销极低,完美契合“读多写少”的经典场景。
- 在路由表、dcache、SELinux AVC、IPC 等关键路径上已大规模替换传统的读写锁,带来了显著的性能提升。
缺点:
- 写端的延迟释放机制会导致内存被短暂地多占用一段时间(在嵌入式等内存敏感系统中需谨慎评估)。
- 当写者非常多,或者应用场景完全无法容忍读到旧数据时,仍需引入额外的锁机制,其带来的收益会打折扣。
理解 RCU 机制,不仅有助于我们深入理解Linux内核的并发设计哲学,也是进行高性能、低延迟多线程编程的重要知识储备。希望这篇解析能对你有所帮助。如果你想与其他开发者交流更多内核或底层技术,欢迎来 云栈社区 一起探讨。
 发表于 2026-4-20 07:17:19
|
查看: 194|
回复: 0
发表于 2026-4-20 07:17:19
|
查看: 194|
回复: 0
