要说最近硬件圈备受关注的话题,除了内存涨价,英特尔似乎在另一个领域开始发力了。不知道大家是否注意到,曾经股价表现低迷的英特尔,其市值正逐步回升,与老对手AMD的差距也在缩小。
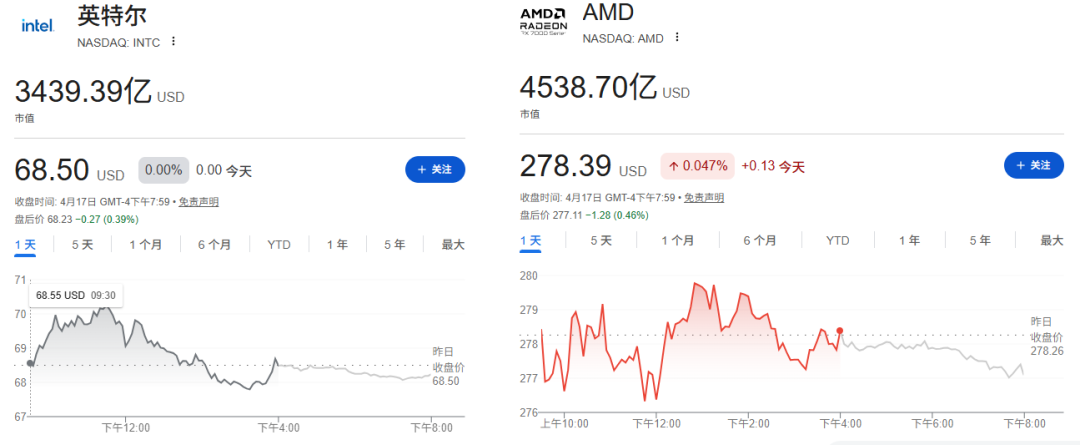
这背后一方面是AI热潮带动了服务器CPU需求,另一方面也得益于其晶圆代工业务(IFS)的发展。重整旗鼓后的英特尔显然不满足于单一领域,而是寻求全面突破。就在Arrow Lake Refresh发布后不久,关于下一代Nova Lake(即酷睿Ultra 400系列)的完整SKU信息已被曝光。
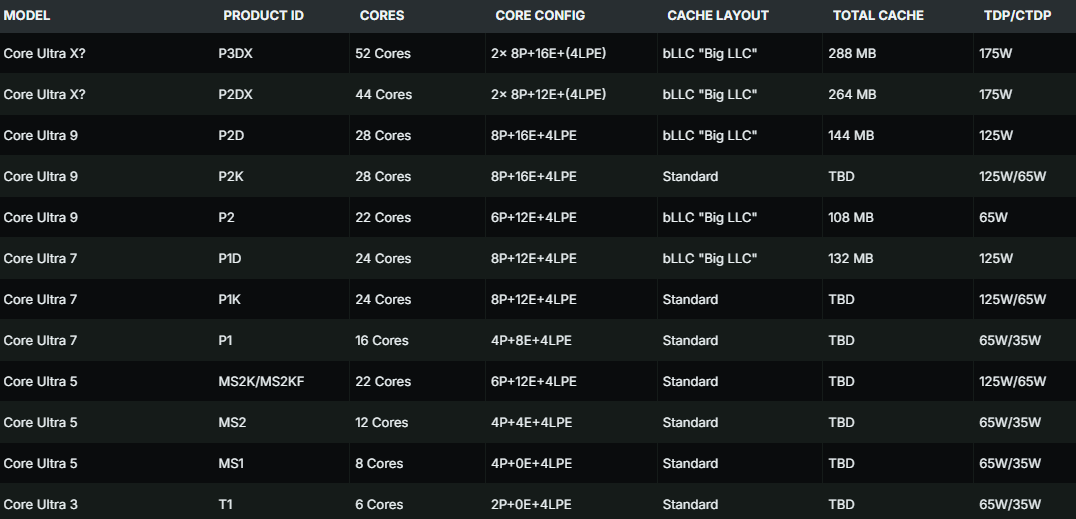
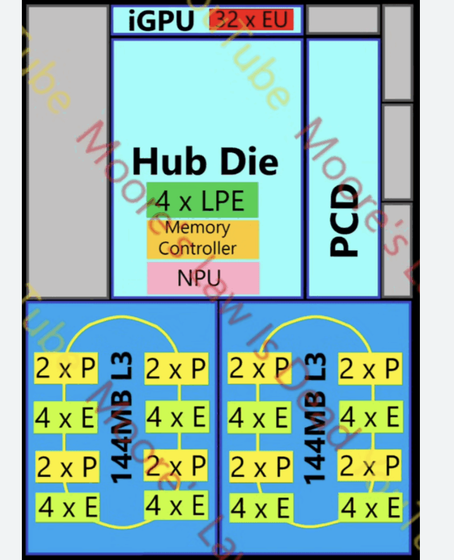
与此前的爆料一致,Nova Lake是英特尔在混合CPU架构路线上的一次激进演进,首次引入了大(P核)、中(E核)、小(LPE核)三种不同定位的计算核心。

这使得其核心总数达到了惊人的52核,并一次性规划了12款SKU。如此规模是通过双CPU Tile组合实现的,单个CPU Tile的最大配置为8个P核、16个E核外加4个LPE核。

看到这里,可能有游戏玩家会问:这么多核心,对游戏性能提升有用吗?别急,重点来了。
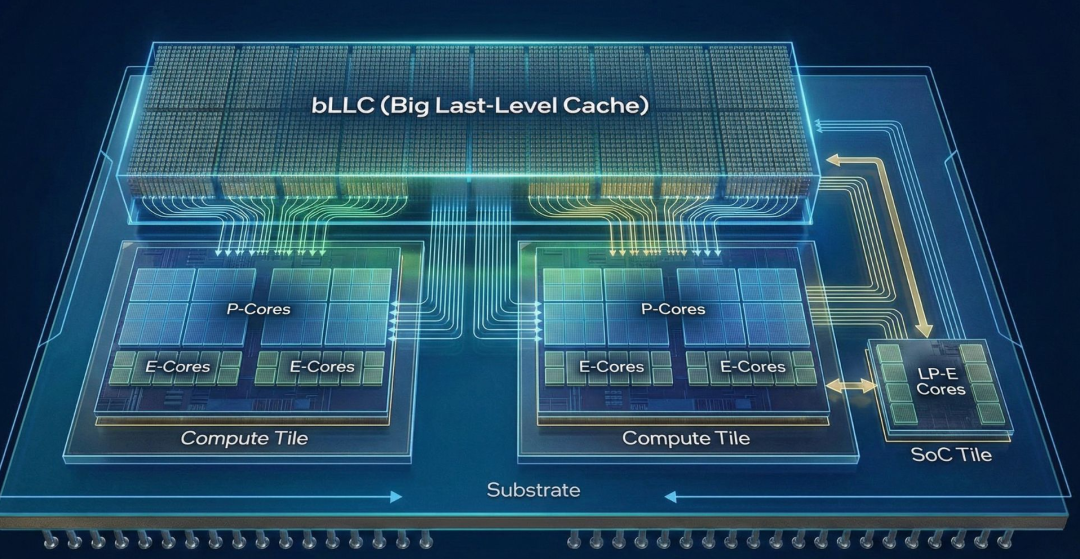
大家知道,自从AMD祭出R7-5800X3D这款大杀器后,凭借3D V-Cache缓存技术,其游戏性能表现一直备受赞誉。这让英特尔感到压力。于是,秉承“打不过就加入”的原则,Nova Lake也引入了“大缓存”技术,并且缓存容量给得极为慷慨,最高达到288MB。
这个数字比刚刚发布的、采用双CCD 3D V-Cache的R9-9950X3D2的208MB还要大。不过,两家公司走了完全不同的技术路径。
AMD采用3D V-Cache垂直堆叠在计算核心(CCD)之上,优点是延迟极低,但像给核心盖了层厚被子,影响了散热。英特尔Nova Lake的BLLC(大型末级缓存)则采用独立的Tile(芯片块)形式存在。据悉,带BLLC的计算芯片面积会比普通版大出约36%。这种解耦设计的好处是让核心能继续冲击高频率,同时缓存容量也更容易扩展。
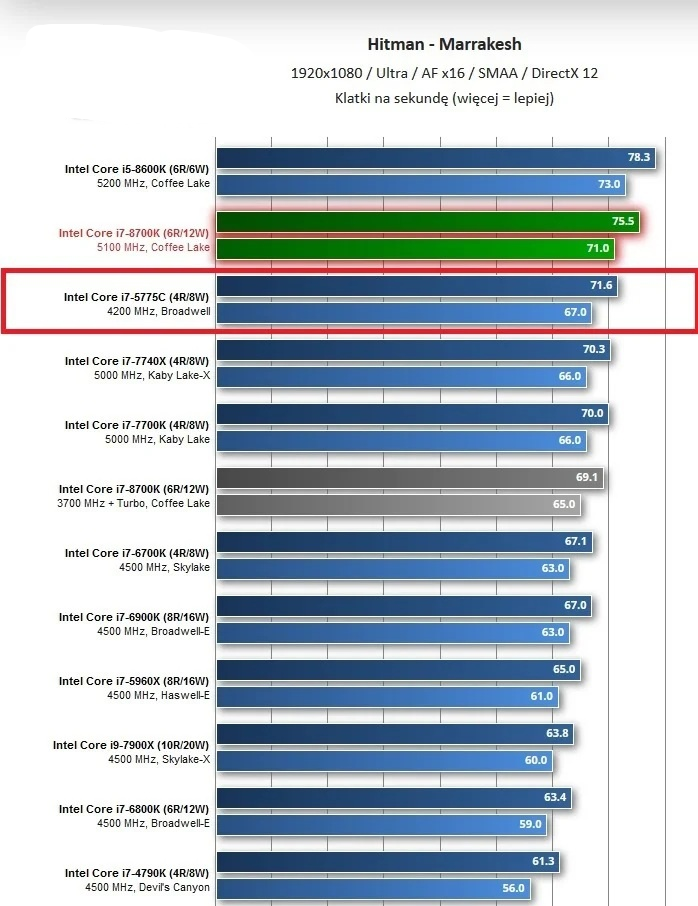
可能有人会好奇,这是什么新技术?其实英特尔玩大缓存的历史比AMD更早。例如2015年发布的酷睿i7-5775C,就集成了128MB的eDRAM,当时被称为L4缓存。

不过受当时技术限制,这块缓存是通过OPIO总线在基板上连接的,带宽上限仅为51.2GB/s。即便如此,也让它能在核心IPC和频率都落后的情况下,游戏表现与后来的i7-8700K掰掰手腕。
而这次的Nova Lake彻底鸟枪换炮,用上了英特尔探索多年的Foveros 3D封装技术,通过Base Tile进行连接。这意味着BLLC缓存与计算核心之间的带宽将从GB级别跃升至TB级别,有望彻底告别低效延迟。

当然,具体表现如何,还得等年底发布后的实测。
另一个随之而来的问题是:芯片面积增大了36%,是不是意味着主板布局又要改动?没错,不出所料,Nova Lake将再次更换接口,采用全新的LGA 1954。
但在“人情世故”上,英特尔似乎准备向AMD学习。近日,英特尔副总裁Robert Hallock在接受Club386采访时给出了一个让老玩家感慨的正面回应。当被问及“英特尔是否会像AMD坚持AM4/AM5接口那样提供长寿插槽”时,他明确表示:会的。
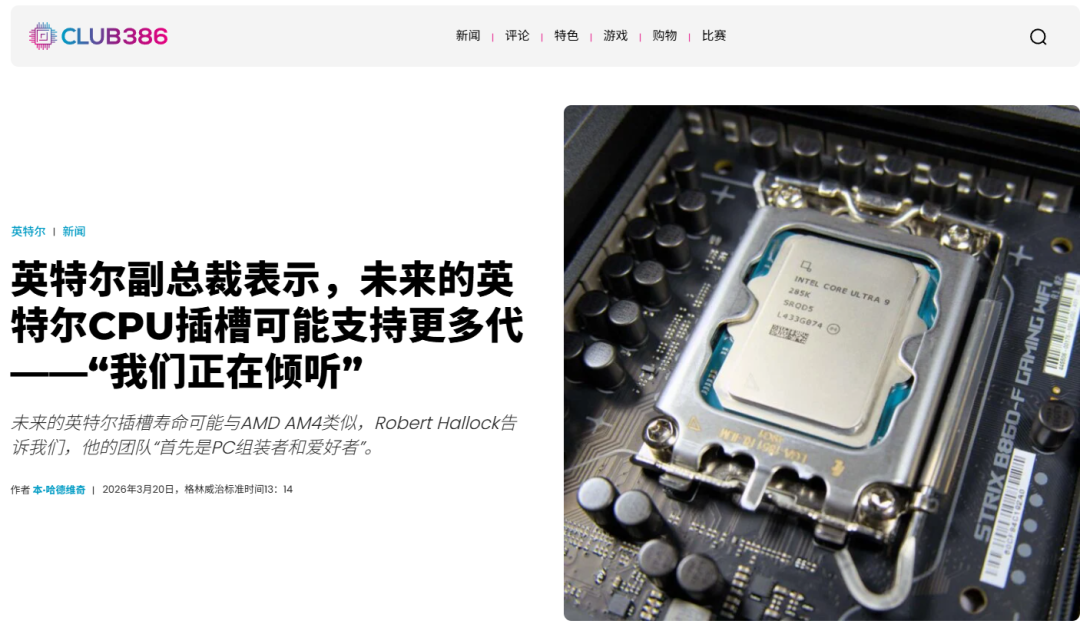
有趣的是,这位副总裁曾在AMD工作了12年,离职前担任技术营销总监。目前传闻称,LGA 1954接口将打破英特尔接口“短命”的魔咒,支持包括Nova Lake、Razor Lake、Titan Lake和Hammer Lake在内的连续四代处理器。
如果传闻属实,对英特尔平台用户来说,这无疑是个好消息。当然,AMD的Zen 6架构也绝非等闲之辈。总的来说,对于普通消费者而言,这样的竞争越激烈越好。究竟英特尔能否凭借Nova Lake的大缓存和长寿接口重夺“游戏CPU之王”的称号,我们拭目以待。
*本文爆料信息仅供参考,一切以厂商实际发布为准。
数据来源:微博@数码闲聊站、videocardz、wccftech、club386、Thermaltake,图源网络。欢迎在云栈社区交流讨论更多硬件资讯。
 发表于 2026-4-20 07:14:31
|
查看: 132|
回复: 0
发表于 2026-4-20 07:14:31
|
查看: 132|
回复: 0
